Recognition: 2 theorem links
· Lean TheoremFrom Schema to Signal: Retrieval-Augmented Modeling for Relational Data Analytics
Pith reviewed 2026-05-15 01:55 UTC · model grok-4.3
The pith
RAM improves predictions on relational databases by augmenting schema graphs with semantic signals from tuple attributes via random walks and retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
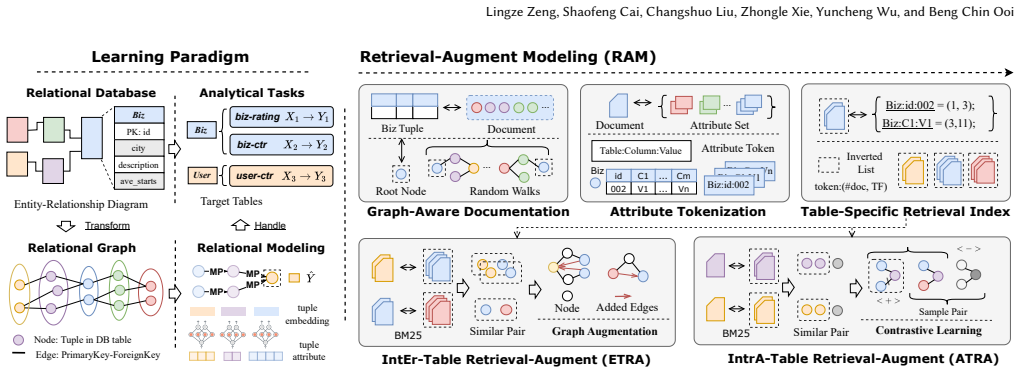
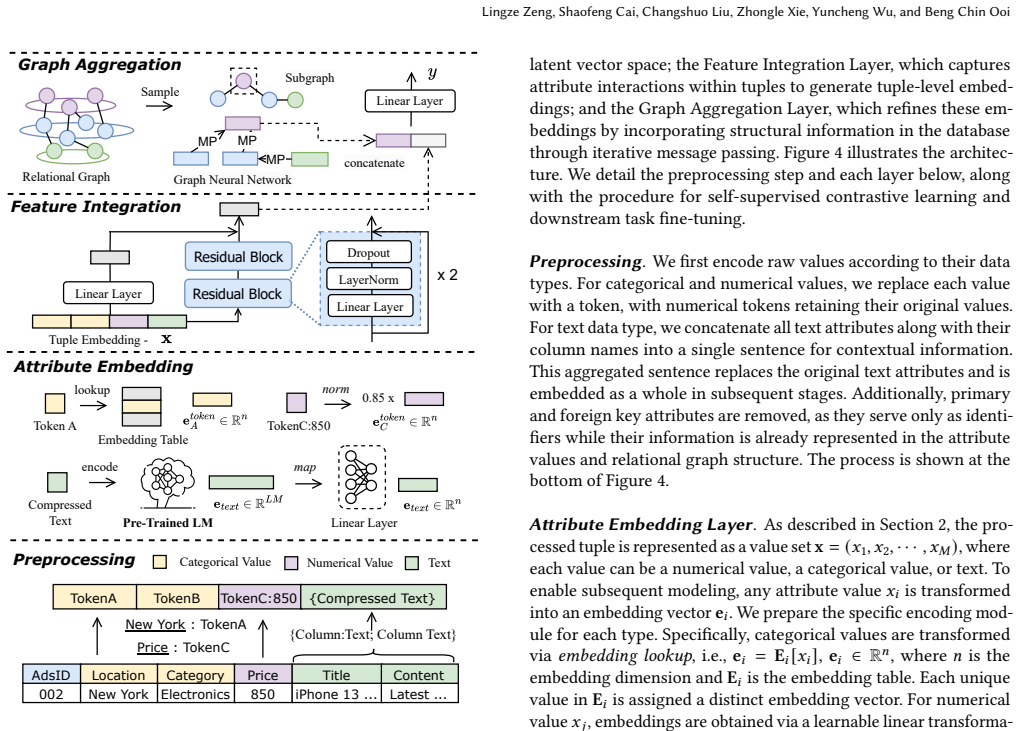
Retrieval-Augmented Modeling treats tuple attributes as tokens and constructs contextual documents through random walks so that information retrieval techniques can estimate semantic relevance between tuples; this enables ATRA for intra-table contrastive learning and ETRA for semantically guided inter-table links, which together feed a layer-wise architecture of attribute embedding, feature integration, and graph aggregation to produce more expressive representations for downstream analytics.
What carries the argument
Random-walk documents built from tuple attributes, scored by information retrieval relevance to augment schema graphs with semantic intra- and inter-table connections.
If this is right
- Intra-table contrastive learning becomes possible using relevance scores computed from attribute documents.
- Graph connectivity expands beyond schema edges by adding links between semantically related tuples across tables.
- Representation learning gains flexibility through the combination of attribute-level embeddings and graph aggregation layers.
- Performance gains appear consistently across classification, regression, and other analytics tasks on real multi-table data.
Where Pith is reading between the lines
- The same document-construction and retrieval step could be applied to other structured data sources that mix explicit relations with rich attribute text.
- Off-the-shelf retrieval tools may serve as a lightweight bridge between rigid database schemas and the semantic flexibility needed by modern neural models.
- Periodic recomputation of the relevance scores could support incremental updates when new tuples arrive in the database.
Load-bearing premise
Random walks over tuple attributes combined with standard retrieval scoring will surface genuine semantic connections between rows without injecting enough noise or spurious links to harm the downstream model.
What would settle it
On a fresh relational database, if the full RAM pipeline produces equal or lower accuracy than a schema-only graph baseline on the same prediction tasks, the semantic augmentation step has not delivered the claimed benefit.
Figures




read the original abstract
Relational data stored in RDBMS is foundational to many real-world applications across domains such as e-commerce, finance, and sociality. While deep neural networks (DNNs) have achieved strong performance on tabular data with a single table, extending these models to relational databases is challenging due to the normalized multi-table structure and complex inter-table relationships. Existing approaches often rely strictly on schema-defined graphs, which overlook implicit semantic signals embedded in tuple attributes and suffer from rigid connectivity. In this work, we propose Retrieval-Augmented Modeling (RAM), a novel framework that combines graph structure with attribute semantics for relational data analytics. RAM treats tuple attributes as tokens and uses random walks to construct contextual documents, enabling the use of information retrieval techniques to estimate semantic relevance between tuples. Building on these documents, we introduce two retrieval-based augmentations: ATRA, which leverages intra-table relevance for contrastive learning, and ETRA, which links semantically related tuples across tables to enhance graph connectivity. Then, we propose a layer-wise model architecture tailored for relational data, which involves attribute embedding, feature integration, and graph aggregation layers to enable expressive and flexible representation learning. Extensive experiments on five real-world relational databases demonstrate that RAM consistently outperforms existing baselines in diverse prediction tasks, establishing a state-of-the-art for relational data analytics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Retrieval-Augmented Modeling (RAM) for relational databases, which augments schema graphs with semantic signals derived from tuple attributes via random walks and off-the-shelf IR relevance scoring. It introduces ATRA (intra-table contrastive learning) and ETRA (cross-table edge augmentation), followed by a layer-wise architecture (attribute embedding, feature integration, graph aggregation), and reports consistent outperformance over baselines on prediction tasks across five real-world databases.
Significance. If the empirical gains are shown to be robust, RAM could meaningfully advance relational analytics by bridging rigid schema connectivity with implicit attribute semantics, offering a practical path beyond purely graph-based or single-table DNN approaches in domains such as e-commerce and finance.
major comments (2)
- [Abstract] Abstract: the central claim of 'consistent outperformance' and 'state-of-the-art' on five databases provides no quantitative details on effect sizes, statistical significance, ablation controls, error bars, or baseline definitions, rendering the empirical assertion unverifiable from the reported evidence.
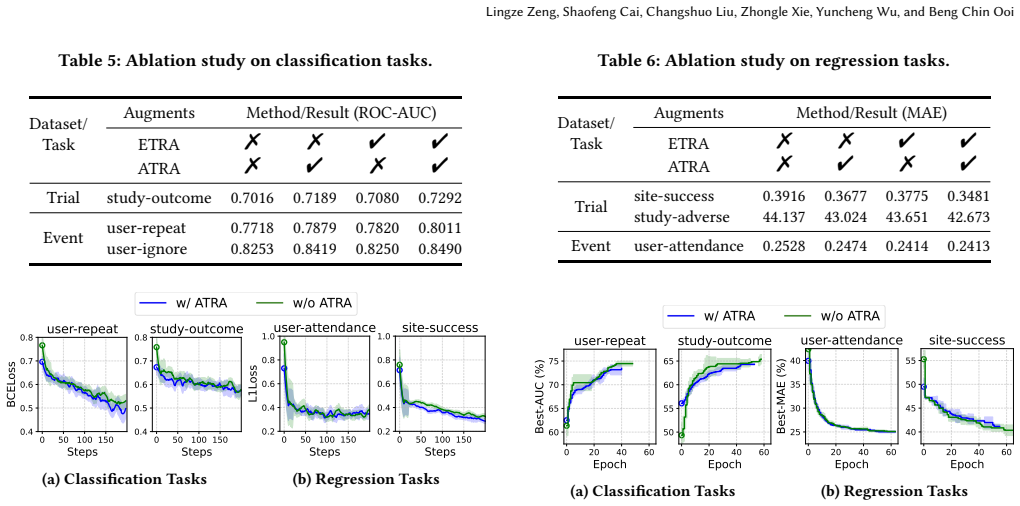
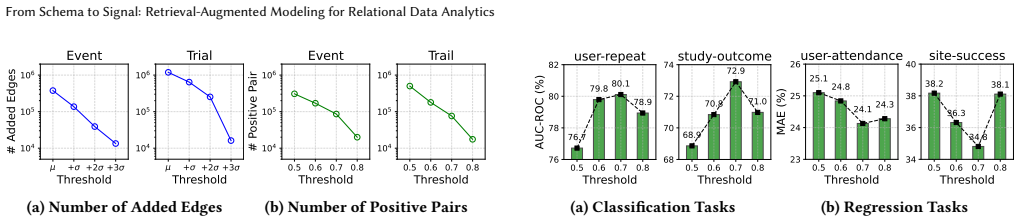
- [Method (ATRA/ETRA)] Method description of random-walk document construction and IR scoring (ATRA/ETRA): the assumption that these steps surface semantically coherent intra- and inter-table links is load-bearing for the claimed gains, yet no ablation isolating retrieval precision (e.g., against human-labeled semantic relevance) or noise analysis is described; spurious structural or lexical matches could propagate through the subsequent contrastive and aggregation layers.
minor comments (1)
- [Abstract] Abstract: consider naming the five databases and the specific prediction tasks to allow readers to assess domain coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, providing clarifications and indicating revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'consistent outperformance' and 'state-of-the-art' on five databases provides no quantitative details on effect sizes, statistical significance, ablation controls, error bars, or baseline definitions, rendering the empirical assertion unverifiable from the reported evidence.
Authors: We agree that the abstract would be strengthened by including concrete quantitative support for the performance claims. In the revised version, we have updated the abstract to report average relative improvements (e.g., 8-12% over the strongest baselines across tasks), mention that all results include standard deviations from repeated runs with 5-fold cross-validation, and reference the statistical significance tests and ablation controls detailed in Section 5. This keeps the abstract concise while making the central claims directly verifiable from the reported evidence. revision: yes
-
Referee: [Method (ATRA/ETRA)] Method description of random-walk document construction and IR scoring (ATRA/ETRA): the assumption that these steps surface semantically coherent intra- and inter-table links is load-bearing for the claimed gains, yet no ablation isolating retrieval precision (e.g., against human-labeled semantic relevance) or noise analysis is described; spurious structural or lexical matches could propagate through the subsequent contrastive and aggregation layers.
Authors: We acknowledge that a direct ablation against human-labeled semantic relevance for the retrieval step is not present in the original submission. The effectiveness of the random-walk documents and IR scoring is supported indirectly by the component ablations for ATRA and ETRA (Section 4.3), which show consistent performance drops when these augmentations are removed, and by the overall gains across five diverse databases. To directly address concerns about noise from spurious matches, we have added an analysis in the revised appendix that quantifies retrieval quality via lexical precision metrics on sampled links and correlates it with downstream gains; the contrastive objectives in ATRA/ETRA demonstrably mitigate propagation of low-quality links. We therefore view the assumption as empirically grounded rather than purely load-bearing. revision: partial
Circularity Check
No circularity in derivation chain; empirical framework with external validation
full rationale
The paper introduces RAM as an engineering framework: random walks over tuple attributes to build documents, off-the-shelf IR for relevance, ATRA contrastive intra-table augmentation, ETRA cross-table edges, and a three-stage layer-wise architecture (attribute embedding, feature integration, graph aggregation). All central claims rest on empirical outperformance versus external baselines across five real-world databases. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The derivation chain is self-contained against independent benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RAM treats tuple attributes as tokens and uses random walks to construct contextual documents, enabling the use of information retrieval techniques to estimate semantic relevance between tuples... ATRA... contrastive learning... ETRA... adds inter-table shortcuts
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
layer-wise model architecture... attribute embedding, feature integration, and graph aggregation layers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Event Recommendation Engine Challenge
2013. Event Recommendation Engine Challenge. https://www.kaggle.com/c/ event-recommendation-engine-challenge. Accessed: 2025-04-16
work page 2013
-
[2]
2014. Stack Exchange Data Dump. https://archive.org/details/stackexchange. Accessed: 2025-04-16
work page 2014
-
[3]
2015. Avito Context Ad Clicks. https://www.kaggle.com/c/avito-context-ad- clicks. Accessed: 2025-04-16
work page 2015
-
[4]
2016. AACT Clinical Trials.gove. https://aact.ctti-clinicaltrials.org/. Accessed: 2025-04-16
work page 2016
-
[5]
Sercan Ö Arik and Tomas Pfister. 2021. Tabnet: Attentive interpretable tabular learning. InProceedings of the AAAI conference on artificial intelligence. AAAI Press, Palo Alto, California USA, 6679–6687
work page 2021
-
[6]
Jinze Bai, Jialin Wang, Zhao Li, Donghui Ding, Ji Zhang, and Jun Gao. 2021. ATJ- Net: Auto-Table-Join Network for Automatic Learning on Relational Databases. InProceedings of the Web Conference 2021(Ljubljana, Slovenia)(WWW ’21). Association for Computing Machinery, New York, NY, USA, 1540–1551. doi:10. 1145/3442381.3449980
-
[7]
Shaofeng Cai, Kaiping Zheng, Gang Chen, H. V. Jagadish, Beng Chin Ooi, and Meihui Zhang. 2021. ARM-Net: Adaptive Relation Modeling Network for Struc- tured Data. InProceedings of the 2021 International Conference on Management of Data(Virtual Event, China)(SIGMOD ’21). Association for Computing Machinery, New York, NY, USA, 207–220. doi:10.1145/3448016.3457321
-
[8]
Wenming Cao, Canta Zheng, Zhiyue Yan, Zhihai He, and Weixin Xie. 2022. Geometric machine learning: research and applications.Multimedia Tools Appl. 81, 21 (Sept. 2022), 30545–30597. doi:10.1007/s11042-022-12683-9
- [9]
-
[10]
E. F. Codd. 1982. Relational database: a practical foundation for productivity. Commun. ACM25, 2 (Feb. 1982), 109–117. doi:10.1145/358396.358400
-
[11]
Alexis Cvetkov-Iliev, Alexandre Allauzen, and Gaël Varoquaux. 2023. Relational data embeddings for feature enrichment with background information.Machine Learning112, 2 (2023), 687–720
work page 2023
- [12]
-
[13]
Matthias Fey, Weihua Hu, Kexin Huang, Jan Eric Lenssen, Rishabh Ranjan, Joshua Robinson, Rex Ying, Jiaxuan You, and Jure Leskovec. 2024. Position: relational deep learning - graph representation learning on relational databases. InProceedings of the 41st International Conference on Machine Learning (ICML’24). JMLR.org, Vienna, Austria, Article 544, 16 pages
work page 2024
-
[14]
Quan Gan, Minjie Wang, David Wipf, and Christos Faloutsos. 2024. Graph Machine Learning Meets Multi-Table Relational Data. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 6502–6512. doi:10.1145/3637528.3671471
-
[15]
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. 2021. Revisiting deep learning models for tabular data. InProceedings of the 35th International Conference on Neural Information Processing Systems (NIPS ’21). Curran Associates Inc., Red Hook, NY, USA, Article 1447, 12 pages
work page 2021
-
[16]
Burton Grad. 2013. Relational Database Management Systems: The Business Explosion [Guest editor’s introduction].IEEE Annals of the History of Computing 35, 2 (2013), 8–9
work page 2013
-
[17]
Maarten Grootendorst. 2020. KeyBERT: Minimal keyword extraction with BERT. doi:10.5281/zenodo.4461265
-
[18]
Aditya Grover and Jure Leskovec. 2016. node2vec: Scalable Feature Learning for Networks. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(San Francisco, California, USA)(KDD ’16). Association for Computing Machinery, New York, NY, USA, 855–864. doi:10. 1145/2939672.2939754
-
[19]
Hamilton, Rex Ying, and Jure Leskovec
William L. Hamilton, Rex Ying, and Jure Leskovec. 2017. Inductive representation learning on large graphs. InProceedings of the 31st International Conference on Neural Information Processing Systems(Long Beach, California, USA)(NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 1025–1035
work page 2017
-
[20]
Ziniu Hu, Yuxiao Dong, Kuansan Wang, and Yizhou Sun. 2020. Heterogeneous Graph Transformer. InProceedings of The Web Conference 2020(Taipei, Tai- wan)(WWW ’20). Association for Computing Machinery, New York, NY, USA, 2704–2710. doi:10.1145/3366423.3380027
- [21]
-
[22]
Peng Jia, Shaofeng Cai, Beng Chin Ooi, Pinghui Wang, and Yiyuan Xiong. 2023. Robust and Transferable Log-based Anomaly Detection.Proc. ACM Manag. Data 1, 1, Article 64 (May 2023), 26 pages. doi:10.1145/3588918
-
[23]
Dawei Jiang, Qingchao Cai, Gang Chen, H. V. Jagadish, Beng Chin Ooi, Kian-Lee Tan, and Anthony K. H. Tung. 2016. Cohort query processing.Proc. VLDB Endow. 10, 1 (Sept. 2016), 1–12. doi:10.14778/3015270.3015271
-
[24]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. InAdvances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc. https...
work page 2017
-
[25]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. arXiv:1609.02907 [cs.LG] https://arxiv.org/abs/ 1609.02907
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
Hoang Thanh Lam, Beat Buesser, Hong Min, Tran Ngoc Minh, Martin Wistuba, Udayan Khurana, Gregory Bramble, Theodoros Salonidis, Dakuo Wang, and Horst Samulowitz. 2021. Automated Data Science for Relational Data . In2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE Computer Society, Los Alamitos, CA, USA, 2689–2692. doi:10.1109/ICDE51...
-
[27]
Hoang Thanh Lam, Tran Ngoc Minh, Mathieu Sinn, Beat Buesser, and Mar- tin Wistuba. 2019. Neural Feature Learning From Relational Database. arXiv:1801.05372 [cs.AI] https://arxiv.org/abs/1801.05372
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[28]
Hoang Thanh Lam, Johann-Michael Thiebaut, Mathieu Sinn, Bei Chen, Tiep Mai, and Oznur Alkan. 2017. One button machine for automating feature engineering in relational databases. arXiv:1706.00327 [cs.DB] https://arxiv.org/abs/1706. 00327
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Changshuo Liu, Lingze Zeng, Kaiping Zheng, Shaofeng Cai, Beng Chin Ooi, and James Wei Luen Yip. [n. d.]. NeuralCohort: Cohort-aware Neural Representation Learning for Healthcare Analytics. InForty-second International Conference on Machine Learning
-
[30]
Julian John McAuley and Jure Leskovec. 2013. From amateurs to connoisseurs: modeling the evolution of user expertise through online reviews. InProceedings of the 22nd international conference on World Wide Web. 897–908
work page 2013
-
[31]
Andriy Mnih and Koray Kavukcuoglu. 2013. Learning word embeddings effi- ciently with noise-contrastive estimation. InAdvances in Neural Information Processing Systems, C.J. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K.Q. Weinberger (Eds.), Vol. 26. Curran Associates, Inc. https://proceedings.neurips. cc/paper_files/paper/2013/file/db2b4182156b2f1f8...
work page 2013
-
[32]
Boris Motik, Ian Horrocks, and Ulrike Sattler. 2007. Bridging the gap between OWL and relational databases. InProceedings of the 16th International Conference on World Wide Web(Banff, Alberta, Canada)(WWW ’07). Association for Com- puting Machinery, New York, NY, USA, 807–816. doi:10.1145/1242572.1242681
-
[33]
Lakshmi Nivas Nalla and Vijay Mallik Reddy. 2020. Comparative Analysis of Modern Database Technologies in Ecommerce Applications.International Journal of Advanced Engineering Technologies and Innovations1, 2 (2020), 21–39
work page 2020
- [34]
-
[35]
Liudmila Prokhorenkova, Gleb Gusev, Aleksandr Vorobev, Anna Veronika Doro- gush, and Andrey Gulin. 2018. CatBoost: unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems, S. Bengio, H. Wal- lach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.), Vol. 31. Curran Associates, Inc. https://proceedings...
work page 2018
- [36]
- [37]
-
[38]
Kipf, Peter Bloem, Rianne van nbsp;den Berg, Ivan Titov, and Max Welling
Michael Schlichtkrull, Thomas N. Kipf, Peter Bloem, Rianne van nbsp;den Berg, Ivan Titov, and Max Welling. 2018. Modeling Relational Data with Graph Con- volutional Networks. InThe Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, June 3–7, 2018, Proceedings(Heraklion, Greece). Springer-Verlag, Berlin, Heidelberg, 593–607. ...
-
[39]
Ravid Shwartz-Ziv and Amitai Armon. 2022. Tabular data: Deep learning is not all you need.Information Fusion81 (2022), 84–90
work page 2022
-
[40]
Dyer, Rémi Munos, Petar Veličković, and Michal Valko
Shantanu Thakoor, Corentin Tallec, Mohammad Gheshlaghi Azar, Mehdi Azabou, Eva L. Dyer, Rémi Munos, Petar Veličković, and Michal Valko. 2023. Large-Scale Representation Learning on Graphs via Bootstrapping. arXiv:2102.06514 [cs.LG] https://arxiv.org/abs/2102.06514
-
[41]
Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. 2018. Graph Attention Networks. InInternational Confer- ence on Learning Representations. https://openreview.net/forum?id=rJXMpikCZ
work page 2018
-
[42]
Petar Veličković, William Fedus, William L. Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. 2018. Deep Graph Infomax. arXiv:1809.10341 [stat.ML] https://arxiv.org/abs/1809.10341
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Minjie Wang, Quan Gan, David Wipf, Zhenkun Cai, Ning Li, Jianheng Tang, Yan- lin Zhang, Zizhao Zhang, Zunyao Mao, Yakun Song, Yanbo Wang, Jiahang Li, Han Zhang, Guang Yang, Xiao Qin, Chuan Lei, Muhan Zhang, Weinan Zhang, Chris- tos Faloutsos, and Zheng Zhang. 2024. 4DBInfer: A 4D Benchmarking Toolbox for Graph-Centric Predictive Modeling on Relational DBs...
-
[44]
Fei Xiao, Shaofeng Cai, Gang Chen, H. V. Jagadish, Beng Chin Ooi, and Meihui Zhang. 2024. VecAug: Unveiling Camouflaged Frauds with Cohort Augmentation for Enhanced Detection. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining(Barcelona, Spain)(KDD ’24). Association for Computing Machinery, New York, NY, USA, 6025–6036....
-
[45]
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph Contrastive Learning with Augmentations. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ran- zato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 5812–5823. https://proceedings.neurips.cc/paper_files/paper/2...
work page 2020
- [46]
-
[47]
Kaiping Zheng, Shaofeng Cai, Horng Ruey Chua, Wei Wang, Kee Yuan Ngiam, and Beng Chin Ooi. 2020. TRACER: A Framework for Facilitating Accurate and Interpretable Analytics for High Stakes Applications. InProceedings of the 2020 ACM SIGMOD International Conference on Management of Data(Portland, OR, USA)(SIGMOD ’20). Association for Computing Machinery, New...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.