Recognition: no theorem link
ROAD: Adaptive Data Mixing for Offline-to-Online Reinforcement Learning via Bi-Level Optimization
Pith reviewed 2026-05-15 01:29 UTC · model grok-4.3
The pith
ROAD frames data mixing in offline-to-online reinforcement learning as a bi-level optimization problem solved by a multi-armed bandit to automate replay ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that casting the data-mixing strategy as the outer level of a bi-level program—where the outer objective measures downstream policy return and the inner level runs ordinary Q-learning—permits an automated, adaptive replay process. This outer decision is made practical by a multi-armed bandit whose arms are candidate mixing weights and whose reward signal comes from a surrogate that approximates the true bi-level gradient while guarding against overestimation.
What carries the argument
Bi-level optimization in which the outer level selects data-mixing weights to maximize eventual policy performance and the inner level performs standard Q-learning updates, made tractable by a multi-armed bandit driven by a surrogate gradient.
If this is right
- Mixing ratios adapt automatically to changing training dynamics without manual retuning.
- Offline priors are retained while value overestimation is limited during online updates.
- Stability improves and asymptotic performance rises relative to static or heuristic baselines.
- The same framework can be dropped into existing offline-to-online pipelines as a plug-in module.
Where Pith is reading between the lines
- The same outer-inner split could be applied to other non-stationary RL problems such as continual learning or sim-to-real transfer.
- If the surrogate proves reliable, similar bi-level formulations might automate other meta-decisions like network architecture or reward shaping inside RL training loops.
- Practical deployments in robotics or recommendation systems might see reduced hyper-parameter search time once the bandit overhead is amortized.
Load-bearing premise
The surrogate objective inside the multi-armed bandit approximates the true bi-level gradient well enough that optimizing the surrogate actually improves final policy performance.
What would settle it
In a controlled environment, replacing the bandit-driven mixing with a well-tuned static ratio yields strictly higher final returns than ROAD; this single reversal would falsify the claim of consistent outperformance.
Figures








read the original abstract
Offline-to-online reinforcement learning harnesses the stability of offline pretraining and the flexibility of online fine-tuning. A key challenge lies in the non-stationary distribution shift between offline datasets and the evolving online policy. Common approaches often rely on static mixing ratios or heuristic-based replay strategies, which lack adaptability to different environments and varying training dynamics, resulting in suboptimal tradeoff between stability and asymptotic performance. In this work, we propose Reinforcement Learning with Optimized Adaptive Data-mixing (ROAD), a dynamic plug-and-play framework that automates the data replay process. We identify a fundamental objective misalignment in existing approaches. To tackle this, we formulate the data selection problem as a bi-level optimization process, interpreting the data mixing strategy as a meta-decision governing the policy performance (outer-level) during online fine-tuning, while the conventional Q-learning updates operate at the inner level. To make it tractable, we propose a practical algorithm using a multi-armed bandit mechanism. This is guided by a surrogate objective approximating the bi-level gradient, which simultaneously maintains offline priors and prevents value overestimation. Our empirical results demonstrate that this approach consistently outperforms existing data replay methods across various datasets, eliminating the need for manual, context-specific adjustments while achieving superior stability and asymptotic performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ROAD, a plug-and-play framework for offline-to-online RL that formulates data mixing as a bi-level optimization problem: the outer level selects mixing ratios via a multi-armed bandit guided by a surrogate objective approximating the bi-level gradient, while the inner level performs standard Q-learning. The surrogate is claimed to maintain offline priors and prevent overestimation; empirical results assert consistent outperformance over existing replay methods across datasets without manual tuning, yielding better stability and asymptotic performance.
Significance. If the surrogate reliably tracks the true outer objective under non-stationary shifts, the method would automate a key hyperparameter in offline-to-online RL and reduce reliance on environment-specific heuristics, providing a principled alternative to static mixing ratios.
major comments (2)
- [Abstract / §3] Abstract and §3 (bi-level formulation): the surrogate objective is described only at a high level as 'approximating the bi-level gradient' while 'maintaining offline priors and preventing value overestimation'; without the explicit functional form or derivation showing how the MAB reward is computed from inner-level trajectories, it is impossible to verify whether the outer decisions actually improve final policy return rather than merely stabilizing early training.
- [Experiments] Empirical evaluation: no error bars, no description of how the multi-armed bandit exploration parameters (listed as free parameters) are chosen or tuned across environments, and no ablation isolating the surrogate's contribution; this leaves the claim of 'eliminating the need for manual, context-specific adjustments' unsupported and raises reproducibility concerns.
minor comments (1)
- [§2] Notation for the outer-level objective and inner-level Q-update should be introduced with explicit equations rather than prose descriptions to clarify the claimed misalignment in existing methods.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and reproducibility of our work. We address each major point below and commit to revisions that strengthen the presentation of the surrogate objective and experimental details without altering the core claims.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (bi-level formulation): the surrogate objective is described only at a high level as 'approximating the bi-level gradient' while 'maintaining offline priors and preventing value overestimation'; without the explicit functional form or derivation showing how the MAB reward is computed from inner-level trajectories, it is impossible to verify whether the outer decisions actually improve final policy return rather than merely stabilizing early training.
Authors: We agree that the current description of the surrogate in the abstract and §3 is at a high level and would benefit from an explicit functional form. In the revised manuscript we will add a dedicated subsection (new §3.3) that derives the surrogate reward explicitly: the MAB reward at step t is defined as r_t = Q_outer(π_{t+1}; D_val) - Q_outer(π_t; D_val), where Q_outer is a first-order approximation of the bi-level gradient obtained by unrolling one inner-level Q-learning step on a held-out validation split of the offline dataset. This derivation shows how the surrogate penalizes value overestimation while preserving offline priors. The added equations and a short proof sketch will allow direct verification that outer-level decisions target final policy return. revision: yes
-
Referee: [Experiments] Empirical evaluation: no error bars, no description of how the multi-armed bandit exploration parameters (listed as free parameters) are chosen or tuned across environments, and no ablation isolating the surrogate's contribution; this leaves the claim of 'eliminating the need for manual, context-specific adjustments' unsupported and raises reproducibility concerns.
Authors: We acknowledge these gaps in the current experimental section. In the revision we will (i) report mean and standard deviation over five independent random seeds for all curves and tables, (ii) add a new paragraph in §4.1 that fixes the MAB parameters to standard values (ε=0.1, α=0.5) chosen once on a single environment and held constant across all others, together with a sensitivity plot, and (iii) include an ablation that replaces the surrogate reward with uniform random mixing while keeping the rest of the algorithm identical. These additions will directly support the claim of reduced manual tuning and address reproducibility. revision: yes
Circularity Check
No circularity: bi-level formulation and surrogate MAB remain independent of fitted inputs
full rationale
The paper formulates data mixing as an outer-level meta-decision and Q-learning as the inner level, then introduces a multi-armed bandit guided by a surrogate that approximates the bi-level gradient while preserving offline priors. No equations or definitions are provided in which the surrogate objective is constructed directly from the same data quantities that the inner loop optimizes, nor does any step rename a fitted parameter as a prediction. The central claim rests on the empirical superiority of the resulting adaptive mixing rather than on any self-referential reduction or self-citation chain that would force the outcome by construction. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- multi-armed bandit exploration parameters
axioms (1)
- domain assumption The surrogate objective approximates the bi-level gradient sufficiently well to preserve offline priors and prevent value overestimation
Reference graph
Works this paper leans on
-
[1]
Efficient online reinforcement learning with offline data
[Ballet al., 2023 ] Philip J Ball, Laura Smith, Ilya Kostrikov, and Sergey Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR,
2023
-
[2]
MOORL: A frame- work for integrating offline-online reinforcement learning
[Chaudharyet al., 2025 ] Gaurav Chaudhary, Washim Uddin Mondal, and Laxmidhar Behera. MOORL: A frame- work for integrating offline-online reinforcement learning. Transactions on Machine Learning Research,
2025
-
[3]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
[Fuet al., 2020 ] Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219,
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learn- ing with a stochastic actor
[Haarnojaet al., 2018 ] Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learn- ing with a stochastic actor. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 ofProceed- ings of Machine Learning Research,...
2018
-
[5]
Modem: Accelerating visual model-based reinforcement learning with demonstrations
[Hansenet al., 2023 ] Nicklas Hansen, Yixin Lin, Hao Su, Xiaolong Wang, Vikash Kumar, and Aravind Rajeswaran. Modem: Accelerating visual model-based reinforcement learning with demonstrations. InThe Eleventh Interna- tional Conference on Learning Representations,
2023
-
[6]
Deep q-learning from demonstrations
[Hesteret al., 2018 ] Todd Hester, Matej Vecerik, Olivier Pietquin, Marc Lanctot, Tom Schaul, Bilal Piot, Dan Hor- gan, John Quan, Andrew Sendonaris, Ian Osband, et al. Deep q-learning from demonstrations. InProceedings of the AAAI conference on artificial intelligence, volume 32,
2018
-
[7]
Kakade and John Langford
[Kakade and Langford, 2002] Sham M. Kakade and John Langford. Approximately optimal approximate reinforce- ment learning. InInternational Conference on Machine Learning,
2002
-
[8]
Scalable deep reinforcement learn- ing for vision-based robotic manipulation
[Kalashnikovet al., 2018 ] Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vin- cent Vanhoucke, et al. Scalable deep reinforcement learn- ing for vision-based robotic manipulation. InConference on robot learning, pages 651–673. PMLR,
2018
-
[9]
Offline reinforcement learning with im- plicit q-learning
[Kostrikovet al., 2022 ] Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with im- plicit q-learning. InInternational Conference on Learning Representations,
2022
-
[10]
Conservative q-learning for offline reinforcement learning
[Kumaret al., 2020 ] Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning. In H. Larochelle, M. Ran- zato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Ad- vances in Neural Information Processing Systems, vol- ume 33, pages 1179–1191. Curran Associates, Inc.,
2020
-
[11]
On the sample complexity of actor-critic method for reinforcement learning with function approxi- mation.Machine Learning, 112(7):2433–2467,
[Kumaret al., 2023 ] Harshat Kumar, Alec Koppel, and Ale- jandro Ribeiro. On the sample complexity of actor-critic method for reinforcement learning with function approxi- mation.Machine Learning, 112(7):2433–2467,
2023
-
[12]
Exploration in deep reinforce- ment learning: A survey.Information Fusion, 85:1–22,
[Ladoszet al., 2022 ] Pawel Ladosz, Lilian Weng, Minwoo Kim, and Hyondong Oh. Exploration in deep reinforce- ment learning: A survey.Information Fusion, 85:1–22,
2022
-
[13]
Offline-to-online re- inforcement learning via balanced replay and pessimistic q-ensemble
[Leeet al., 2022 ] Seunghyun Lee, Younggyo Seo, Kimin Lee, Pieter Abbeel, and Jinwoo Shin. Offline-to-online re- inforcement learning via balanced replay and pessimistic q-ensemble. InConference on Robot Learning, pages 1702–1712. PMLR,
2022
-
[14]
Offline reinforcement learning: Tu- torial, review, and perspectives on open problems,
[Levineet al., 2020 ] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tu- torial, review, and perspectives on open problems,
2020
-
[15]
[Liet al., 2023 ] Jianxiong Li, Xiao Hu, Haoran Xu, Jingjing Liu, Xianyuan Zhan, and Ya-Qin Zhang. Proto: Iterative policy regularized offline-to-online reinforcement learn- ing.arXiv preprint arXiv:2305.15669,
-
[16]
The three regimes of offline-to-online re- inforcement learning.arXiv preprint arXiv:2510.01460,
[Liet al., 2025a ] Lu Li, Tianwei Ni, Yihao Sun, and Pierre- Luc Bacon. The three regimes of offline-to-online re- inforcement learning.arXiv preprint arXiv:2510.01460,
-
[17]
[Liuet al., 2025 ] Xuefeng Liu, Hung T. C. Le, Siyu Chen, Rick Stevens, Zhuoran Yang, Matthew Walter, and Yuxin Chen. Active advantage-aligned online reinforcement learning with offline data. InThe Exploration in AI To- day Workshop at ICML 2025,
2025
-
[18]
Reinforcement learning for combinatorial optimization: A survey.Com- puters & Operations Research, 134:105400,
[Mazyavkinaet al., 2021 ] Nina Mazyavkina, Sergey Sviri- dov, Sergei Ivanov, and Evgeny Burnaev. Reinforcement learning for combinatorial optimization: A survey.Com- puters & Operations Research, 134:105400,
2021
-
[19]
AWAC: Accelerating Online Reinforcement Learning with Offline Datasets
[Nairet al., 2020 ] Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. Awac: Accelerating online re- inforcement learning with offline datasets.arXiv preprint arXiv:2006.09359,
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[20]
Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning
[Nakamotoet al., 2023 ] Mitsuhiko Nakamoto, Simon Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, and Sergey Levine. Cal-ql: Calibrated offline rl pre-training for efficient online fine-tuning. Advances in Neural Information Processing Systems, 36:62244–62269,
2023
-
[21]
Functional bilevel optimization for machine learning
[Petrulionyt˙eet al., 2024 ] Ieva Petrulionyt ˙e, Julien Mairal, and Michael Arbel. Functional bilevel optimization for machine learning. InThe Thirty-eighth Annual Confer- ence on Neural Information Processing Systems,
2024
-
[22]
Trust region policy optimization
[Schulmanet al., 2015 ] John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR,
2015
-
[23]
arXiv preprint arXiv:2210.06718 , year=
[Songet al., 2022 ] Yuda Song, Yifei Zhou, Ayush Sekhari, J Andrew Bagnell, Akshay Krishnamurthy, and Wen Sun. Hybrid rl: Using both offline and online data can make rl efficient.arXiv preprint arXiv:2210.06718,
-
[24]
Adaptive Replay Buffer for Offline-to-Online Reinforcement Learning
[Songet al., 2025 ] Chihyeon Song, Jaewoo Lee, and Jinkyoo Park. Adaptive replay buffer for offline-to-online reinforcement learning.arXiv preprint arXiv:2512.10510,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Mujoco: A physics engine for model-based con- trol
[Todorovet al., 2012 ] Emanuel Todorov, Tom Erez, and Yu- val Tassa. Mujoco: A physics engine for model-based con- trol. In2012 IEEE/RSJ international conference on intel- ligent robots and systems, pages 5026–5033. IEEE,
2012
-
[26]
Leveraging Demonstrations for Deep Reinforcement Learning on Robotics Problems with Sparse Rewards
[Veceriket al., 2017 ] Mel Vecerik, Todd Hester, Jonathan Scholz, Fumin Wang, Olivier Pietquin, Bilal Piot, Nicolas Heess, Thomas Roth¨orl, Thomas Lampe, and Martin Ried- miller. Leveraging demonstrations for deep reinforcement learning on robotics problems with sparse rewards.arXiv preprint arXiv:1707.08817,
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Leveraging offline data in online reinforcement learning
[Wagenmaker and Pacchiano, 2023] Andrew Wagenmaker and Aldo Pacchiano. Leveraging offline data in online reinforcement learning. InInternational Conference on Machine Learning, pages 35300–35338. PMLR,
2023
-
[28]
Deep reinforcement learning: A survey.IEEE Trans
[Wanget al., 2024 ] Xu Wang, Sen Wang, Xingxing Liang, Dawei Zhao, Jincai Huang, Xin Xu, Bin Dai, and Qiguang Miao. Deep reinforcement learning: A survey.IEEE Trans. Neural Networks Learn. Syst., 35(4):5064–5078, April
2024
-
[29]
Simlauncher: Launching sample-efficient real- world robotic reinforcement learning via simulation pre- training,
[Wuet al., 2025 ] Mingdong Wu, Lehong Wu, Yizhuo Wu, Weiyao Huang, Hongwei Fan, Zheyuan Hu, Haoran Geng, Jinzhou Li, Jiahe Ying, Long Yang, Yuanpei Chen, and Hao Dong. Simlauncher: Launching sample-efficient real- world robotic reinforcement learning via simulation pre- training,
2025
-
[30]
Policy finetuning: Bridging sample-efficient offline and online reinforcement learn- ing.Advances in neural information processing systems, 34:27395–27407,
[Xieet al., 2021 ] Tengyang Xie, Nan Jiang, Huan Wang, Caiming Xiong, and Yu Bai. Policy finetuning: Bridging sample-efficient offline and online reinforcement learn- ing.Advances in neural information processing systems, 34:27395–27407,
2021
-
[31]
Reinforcement learning in healthcare: A survey.ACM Comput
[Yuet al., 2021 ] Chao Yu, Jiming Liu, Shamim Nemati, and Guosheng Yin. Reinforcement learning in healthcare: A survey.ACM Comput. Surv., 55(1), November
2021
-
[32]
Policy expansion for bridging offline-to-online rein- forcement learning
[Zhanget al., 2023 ] Haichao Zhang, Wei Xu, and Haonan Yu. Policy expansion for bridging offline-to-online rein- forcement learning. InThe Eleventh International Confer- ence on Learning Representations,
2023
-
[33]
[Zhaoet al., 2022 ] Yi Zhao, Rinu Boney, Alexander Ilin, Juho Kannala, and Joni Pajarinen. Adaptive behav- ior cloning regularization for stable offline-to-online re- inforcement learning.arXiv preprint arXiv:2210.13846,
-
[34]
A survey of au- tonomous driving from a deep learning perspective.ACM Computing Surveys, 57(10):1–60,
[Zhaoet al., 2025 ] Jingyuan Zhao, Yuyan Wu, Rui Deng, Susu Xu, Jinpeng Gao, and Andrew Burke. A survey of au- tonomous driving from a deep learning perspective.ACM Computing Surveys, 57(10):1–60,
2025
-
[35]
Adaptive pol- icy learning for offline-to-online reinforcement learning
[Zhenget al., 2023 ] Han Zheng, Xufang Luo, Pengfei Wei, Xuan Song, Dongsheng Li, and Jing Jiang. Adaptive pol- icy learning for offline-to-online reinforcement learning. InProceedings of the AAAI Conference on Artificial Intel- ligence, volume 37, pages 11372–11380,
2023
-
[36]
Efficient online rein- forcement learning fine-tuning need not retain offline data
[Zhouet al., 2025 ] Zhiyuan Zhou, Andy Peng, Qiyang Li, Sergey Levine, and Aviral Kumar. Efficient online rein- forcement learning fine-tuning need not retain offline data. InThe Thirteenth International Conference on Learning Representations,
2025
-
[37]
Following the bi-level optimization theory [Petrulionyt˙eet al., 2024 ], we compute the gradient of the outer-level objective for a theoretical gradient ascent algorithm
A Solution to the Bi-Level Optimization As is demonstrated in Equation (3), we solve a bi-level optimization problem that selects an optimal data mixing strategy. Following the bi-level optimization theory [Petrulionyt˙eet al., 2024 ], we compute the gradient of the outer-level objective for a theoretical gradient ascent algorithm. Although we are solving...
2024
-
[38]
The second assumption conveys the critical intuition that the data mixing strategy is a tradeoff between utilizing offline and online data
The first assumption holds for most of the practical online RL algorithms like max-entropy RL [Haarnojaet al., 2018 ] and trust region methods [Schulmanet al., 2015 ]. The second assumption conveys the critical intuition that the data mixing strategy is a tradeoff between utilizing offline and online data. With these assumptions, we simplify the gradient ...
2018
-
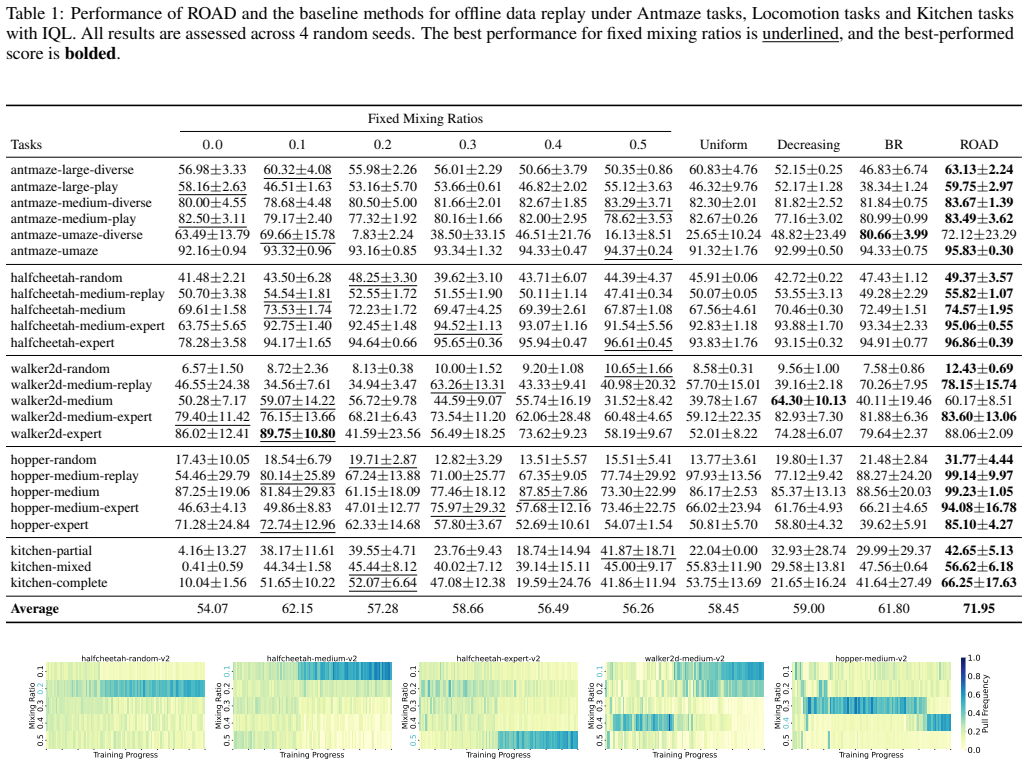
[39]
Z A πf(a) + Z A δπf(a) δ ˆf(a ′) ϵ(a′)da′ ! f(a)da−E πk [f] # = Eπf [f]−E πk [f] +E ϵ
The task is to compare the overestimation bias term and the true advantage term. We approximate the true advantage term by a first-order Taylor expansion on the online policyπ. (In fact, the former approximation of the bias term is also equivalent to a first-order policy expansion.) This expansion eliminates the stochastic term within the true advantage, ...
-
[40]
For instance, a mixing ratio fixed at 0.3 shows promising overall results with Cal-QL across both types of environments, yet the same setting performs significantly weaker with CQL
It was observed that fixed mixing ratios exhibit a certain level of instability in these cases. For instance, a mixing ratio fixed at 0.3 shows promising overall results with Cal-QL across both types of environments, yet the same setting performs significantly weaker with CQL. Similarly, strategies such as decreasing mixing ratios and uniform selection am...
2023
-
[41]
This observation highlights the importance of adaptive methods in offline-to-online reinforcement learning
Reflecting on the empirical results discussed in our paper, we observed that the effectiveness of various mixing ratios can be influenced by the quality of the offline data. This observation highlights the importance of adaptive methods in offline-to-online reinforcement learning. Integrating ROAD with the Proto algorithm, we found that it improves upon t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.