Recognition: unknown
Large Dimensional Kernel Ridge Regression: Extending to Product Kernels
Pith reviewed 2026-05-15 01:40 UTC · model grok-4.3
The pith
A broad family of large-dimensional product kernels recovers the same saturation effects, minimax rates, and multiple-descent behavior previously known only for inner-product kernels on the sphere.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
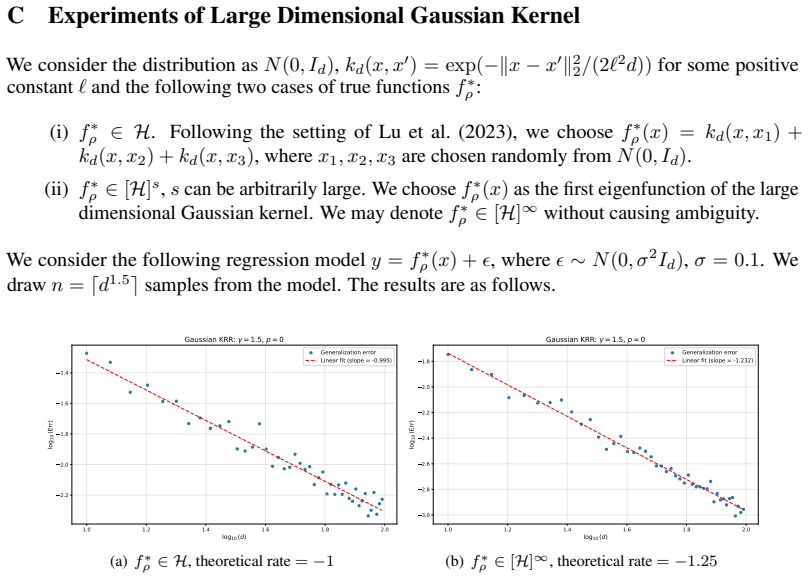
We establish a broad, new family of large dimensional kernels and derive the corresponding convergence rates of the generalization error. As a result, we recover key phenomena previously associated with inner product kernels on sphere, including: i) the minimax optimality when the source condition s≤1; ii) the saturation effect when s>1; iii) a periodic plateau phenomenon in the convergence rate and a multiple-descent behavior with respect to the sample size n.
What carries the argument
The broad family of large-dimensional product kernels, which admit explicit eigenfunction expansions and source-condition analysis that yield the stated generalization rates.
If this is right
- For source condition s ≤ 1 the kernels achieve the minimax optimal rate for generalization error.
- For source condition s > 1 the kernels exhibit the saturation effect in the convergence rate.
- The convergence rate displays a periodic plateau pattern with respect to dimension or other parameters.
- The generalization error shows a multiple-descent curve as the sample size n increases.
Where Pith is reading between the lines
- Product kernels can replace spherical inner-product kernels in theoretical analyses of high-dimensional kernel methods without losing the key rate guarantees.
- The same saturation and multiple-descent patterns may appear in other kernel families once the high-dimensional eigenstructure conditions are met.
- Practitioners could design product kernels to control the locations of the descent peaks and plateaus for a given data dimension.
Load-bearing premise
The kernels must belong to the defined broad family and obey the high-dimensional regime conditions that make the eigenfunction and source-condition analysis valid.
What would settle it
Compute the generalization error curve for a concrete product kernel in the high-dimensional regime with s>1 and check whether the rate saturates or continues to improve without bound.
Figures


read the original abstract
Recent studies have reported $\textit{saturation effects}$ and $\textit{multiple descent behavior}$ in large dimensional kernel ridge regression (KRR). However, these findings are predominantly derived under restrictive settings, such as inner product kernels on sphere or strong eigenfunction assumptions like hypercontractivity. Whether such behaviors hold for other kernels remains an open question. In this paper, we establish a broad, new family of large dimensional kernels and derive the corresponding convergence rates of the generalization error. As a result, we recover key phenomena previously associated with inner product kernels on sphere, including: $i)$ the $\textit{minimax optimality}$ when the source condition $s\le 1$; $ii)$ the $\textit{saturation effect}$ when $s>1$; $iii)$ a $\textit{periodic plateau phenomenon}$ in the convergence rate and a $\textit {multiple-descent behavior}$ with respect to the sample size $n$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a broad family of large-dimensional product kernels for kernel ridge regression and derives the corresponding convergence rates of the generalization error. It recovers minimax optimality when the source condition parameter s ≤ 1, saturation effects when s > 1, a periodic plateau phenomenon in the rates, and multiple-descent behavior with respect to sample size n, extending prior results that were limited to inner-product kernels on the sphere.
Significance. If the central derivations hold, the work is significant because it moves the analysis of saturation and multiple-descent phenomena in high-dimensional KRR beyond the restrictive spherical inner-product setting to a wider class of product kernels. The explicit rate derivations under the new family provide a more general theoretical framework for understanding these behaviors in practical high-dimensional kernel methods.
major comments (1)
- [Theorems 3.2–4.3 and Corollaries 4.1–4.2] Theorems 3.2–4.3: the tensor-product factorization of the kernel operator yields eigenvalues that are products of marginal spectra. The subsequent rate derivations in Corollaries 4.1–4.2 rely on the ordered combined spectrum obeying the same power-law decay bounds (λ_k ≳ k^{-α} with α tied to s) used for spherical kernels. For generic product kernels this ordering can produce eigenvalue clusters or slower effective decay once d grows with n, which would invalidate the claimed saturation and multiple-descent rates. The manuscript must either impose explicit conditions on the marginal kernels that guarantee preservation of the decay or demonstrate that the rates remain valid under the weaker spectrum that arises from products.
minor comments (2)
- [Section 2] Define the precise membership conditions for the 'broad family' of product kernels (including any restrictions on the marginal kernels or high-dimensional regime assumptions) at the beginning of Section 2 before the main theorems are stated.
- [Abstract] The abstract refers to the 'periodic plateau phenomenon' without a one-sentence gloss; adding a brief parenthetical explanation would improve accessibility for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for the careful reading of our manuscript and the constructive feedback. The major comment raises a valid point about the eigenvalue spectrum under tensor-product kernels, which we address below by agreeing to strengthen the assumptions and proofs in the revised version.
read point-by-point responses
-
Referee: [Theorems 3.2–4.3 and Corollaries 4.1–4.2] Theorems 3.2–4.3: the tensor-product factorization of the kernel operator yields eigenvalues that are products of marginal spectra. The subsequent rate derivations in Corollaries 4.1–4.2 rely on the ordered combined spectrum obeying the same power-law decay bounds (λ_k ≳ k^{-α} with α tied to s) used for spherical kernels. For generic product kernels this ordering can produce eigenvalue clusters or slower effective decay once d grows with n, which would invalidate the claimed saturation and multiple-descent rates. The manuscript must either impose explicit conditions on the marginal kernels that guarantee preservation of the decay or demonstrate that the rates remain valid under the weaker spectrum that arises from products.
Authors: We appreciate the referee's observation on the potential complications arising from eigenvalue multiplicities in the product spectrum. The current derivations in Theorems 3.2–4.3 rely on the factorization into marginal operators and assume the ordered combined eigenvalues satisfy the requisite power-law bounds to recover the stated rates. However, we agree that without further restrictions, generic marginal spectra can induce clusters that alter the effective decay rate as d scales with n, potentially affecting the saturation and multiple-descent claims in Corollaries 4.1–4.2. In the revised manuscript we will introduce an explicit assumption (new Assumption 3.1) requiring each marginal kernel to have eigenvalues satisfying λ_j^{(m)} ≳ j^{-α} uniformly in the dimension index m. Under this condition we will add a lemma showing that the sorted product eigenvalues continue to obey λ_k ≳ k^{-α} (up to constants independent of d and n), thereby preserving the minimax optimality for s ≤ 1, saturation for s > 1, and the multiple-descent behavior. These changes will be reflected in updated statements of Theorems 3.2–4.3 and Corollaries 4.1–4.2, with additional discussion in Section 4. revision: yes
Circularity Check
No significant circularity; derivation extends standard spectral analysis to product kernels without reducing to fitted inputs or self-referential definitions.
full rationale
The paper defines a broad family of large-dimensional product kernels via tensor-product factorization of the kernel operator, then applies standard eigenfunction and source-condition analysis to obtain generalization error rates under high-dimensional regime assumptions. The recovered phenomena (minimax optimality for s≤1, saturation for s>1, periodic plateaus, and multiple descent) are direct consequences of the derived power-law eigenvalue bounds on the combined spectrum, which are not obtained by fitting to the target rates or by renaming prior results. No load-bearing self-citation, ansatz smuggling, or self-definitional steps appear; the central claims remain mathematically independent of the phenomena they recover once the family and regime conditions are stated.
Axiom & Free-Parameter Ledger
free parameters (1)
- source condition parameter s
axioms (2)
- domain assumption Kernels belong to the newly defined broad family of large-dimensional product kernels
- domain assumption High-dimensional regime with appropriate eigenfunction decay
Reference graph
Works this paper leans on
-
[1]
IEEE Trans
Nonparametric regression estimation using penalized least squares , author=. IEEE Trans. Inf. Theory , year=
-
[2]
Bulletin of the American Mathematical Society , year=
On the mathematical foundations of learning , author=. Bulletin of the American Mathematical Society , year=
-
[3]
Annual Conference Computational Learning Theory , year=
Optimal Rates for Regularized Least Squares Regression , author=. Annual Conference Computational Learning Theory , year=
-
[4]
2020 , journal =
Sobolev Norm Learning Rates for Regularized Least-Squares Algorithms , author =. 2020 , journal =
2020
-
[5]
2017 , journal =
Optimal Rates for the Regularized Learning Algorithms under General Source Condition , author =. 2017 , journal =
2017
-
[6]
2005 , journal =
Spectral Methods for Regularization in Learning Theory , author =. 2005 , journal =
2005
-
[7]
2007 , journal =
On Regularization Algorithms in Learning Theory , author =. 2007 , journal =
2007
-
[8]
2008 , journal =
Spectral Algorithms for Supervised Learning , author =. 2008 , journal =
2008
-
[9]
2010 , month = feb, journal =
Regularization in Kernel Learning , author =. 2010 , month = feb, journal =
2010
-
[10]
2006 , institution=
Optimal rates for regularization operators in learning theory , author=. 2006 , institution=
2006
-
[11]
2018 , journal =
Optimal Rates for Regularization of Statistical Inverse Learning Problems , author =. 2018 , journal =
2018
-
[12]
and Foster, Dean Phillips and Hsu, Daniel J
Dicker, L. and Foster, Dean Phillips and Hsu, Daniel J. , year =. Kernel Ridge vs. Principal Component Regression:. Electronic Journal of Statistics , volume =
-
[13]
and Cevher, V
Lin, Junhong and Rudi, Alessandro and Rosasco, L. and Cevher, V. , year =. Optimal Rates for Spectral Algorithms with Least-Squares Regression over. Applied and Computational Harmonic Analysis , volume =
-
[14]
, author =
Optimal Convergence for Distributed Learning with Stochastic Gradient Methods and Spectral Algorithms. , author =. 2020 , journal =
2020
-
[15]
and Scovel, C
Steinwart, Ingo and Hush, D. and Scovel, C. , year =. Optimal Rates for Regularized Least Squares Regression , booktitle =
-
[16]
Advances in Neural Information Processing Systems , volume=
Statistical optimality of stochastic gradient descent on hard learning problems through multiple passes , author=. Advances in Neural Information Processing Systems , volume=
-
[17]
Analyzing the discrepancy principle for kernelized spectral filter learning algorithms , author=. J. Mach. Learn. Res. , year=
-
[18]
ArXiv , year=
Statistical Optimality of Divide and Conquer Kernel-based Functional Linear Regression , author=. ArXiv , year=
-
[19]
, year =
Steinwart, Ingo and Scovel, C. , year =. Mercer's Theorem on General Domains:. Constructive Approximation , volume =
-
[20]
Advances in Neural Information Processing Systems , volume=
Generalization error rates in kernel regression: The crossover from the noiseless to noisy regime , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
International Conference on Machine Learning , pages=
Spectrum dependent learning curves in kernel regression and wide neural networks , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[22]
Journal of Statistical Mechanics: Theory and Experiment , year=
Asymptotic learning curves of kernel methods: empirical data versus teacher–student paradigm , author=. Journal of Statistical Mechanics: Theory and Experiment , year=
-
[23]
ArXiv , year=
Kernel Truncated Randomized Ridge Regression: Optimal Rates and Low Noise Acceleration , author=. ArXiv , year=
-
[24]
2003 , publisher =
Sobolev Spaces , author =. 2003 , publisher =
2003
-
[25]
2018 , publisher =
Theory of Besov spaces , author =. 2018 , publisher =
2018
-
[26]
Adams , author=
Sobolev Spaces. Adams , author=. 1975 , publisher=
1975
-
[27]
Native spaces , DOI=
Wendland, Holger , year=. Native spaces , DOI=. Scattered Data Approximation , publisher=
-
[28]
Constructive Approximation , year=
Learning Theory Estimates via Integral Operators and Their Approximations , author=. Constructive Approximation , year=
-
[29]
2009 , series =
Introduction to Nonparametric Estimation , author =. 2009 , series =
2009
-
[30]
Neural networks : the official journal of the International Neural Network Society , year=
Distributed learning for sketched kernel regression , author=. Neural networks : the official journal of the International Neural Network Society , year=
-
[31]
Inverse Problems , year=
Learning theory of distributed spectral algorithms , author=. Inverse Problems , year=
-
[32]
Optimal Learning Rates for Regularized Least-Squares with a Fourier Capacity Condition , author=
-
[33]
Advances in Neural Information Processing Systems , volume=
Optimal rates for regularized conditional mean embedding learning , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
, year =
Wainwright, Martin J. , year =. High-Dimensional Statistics:
-
[35]
Numerical Algorithms , year=
Computing a family of reproducing kernels for statistical applications , author=. Numerical Algorithms , year=
-
[36]
ArXiv , year=
Minimax Optimal Kernel Operator Learning via Multilevel Training , author=. ArXiv , year=
-
[37]
On the Saturation Effect of Kernel Ridge Regression , booktitle =
Li, Yicheng and Zhang, Haobo and Lin, Qian , year =. On the Saturation Effect of Kernel Ridge Regression , booktitle =
-
[38]
2007 , publisher=
An introduction to Sobolev spaces and interpolation spaces , author=. 2007 , publisher=
2007
-
[39]
THE ANNALS , volume=
NONPARAMETRIC STOCHASTIC APPROXIMATION WITH LARGE STEP-SIZES1 , author=. THE ANNALS , volume=
-
[40]
Parallelizing Spectrally Regularized Kernel Algorithms , author=. J. Mach. Learn. Res. , year=
-
[41]
Divide and conquer kernel ridge regression: a distributed algorithm with minimax optimal rates , author=. J. Mach. Learn. Res. , year=
-
[42]
Journal of Machine Learning Research , volume=
Distributed learning with regularized least squares , author=. Journal of Machine Learning Research , volume=
-
[43]
2000 , journal =
Regularization with Dot-Product Kernels , author =. 2000 , journal =
2000
-
[44]
2013 , series =
Approximation Theory and Harmonic Analysis on Spheres and Balls , author =. 2013 , series =
2013
-
[45]
Kernel Methods for Deep Learning , booktitle =
Cho, Youngmin and Saul, Lawrence , editor =. Kernel Methods for Deep Learning , booktitle =. 2009 , volume =
2009
-
[46]
Advances in Neural Information Processing Systems , author =
Neural Tangent Kernel:. Advances in Neural Information Processing Systems , author =. 2018 , volume =
2018
-
[47]
2017 , journal =
Breaking the Curse of Dimensionality with Convex Neural Networks , author =. 2017 , journal =
2017
-
[48]
Constructive Approximation , year=
On Early Stopping in Gradient Descent Learning , author=. Constructive Approximation , year=
-
[49]
SIAM Journal on Mathematics of Data Science , volume=
On the inconsistency of kernel ridgeless regression in fixed dimensions , author=. SIAM Journal on Mathematics of Data Science , volume=. 2023 , publisher=
2023
-
[50]
Journal of Machine Learning Research , year =
Wenjia Wang and Bing-Yi Jing , title =. Journal of Machine Learning Research , year =
-
[51]
Edmunds, D. E. and Triebel, H. , year =. Function Spaces, Entropy Numbers, Differential Operators , DOI =
-
[52]
The Annals of Statistics , number =
Behrooz Ghorbani and Song Mei and Theodor Misiakiewicz and Andrea Montanari , title =. The Annals of Statistics , number =
-
[53]
I. J. Schoenberg , title =. Duke Mathematical Journal , number =
-
[54]
arXiv preprint arXiv:2303.15809 , year=
Kernel interpolation generalizes poorly , author=. arXiv preprint arXiv:2303.15809 , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
On the inductive bias of neural tangent kernels , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Differential Geometry and Lie Groups: A Second Course , pages=
Spherical Harmonics and Linear Representations of Lie Groups , author=. Differential Geometry and Lie Groups: A Second Course , pages=. 2020 , publisher=
2020
-
[57]
arXiv preprint arXiv:2303.14942 , year=
On the optimality of misspecified spectral algorithms , author=. arXiv preprint arXiv:2303.14942 , year=
-
[58]
The Annals of Statistics , number =
Yuhong Yang and Andrew Barron , title =. The Annals of Statistics , number =
-
[59]
Nonlinear Theory and Its Applications, IEICE , volume=
On the embedding constant of the Sobolev type inequality for fractional derivatives , author=. Nonlinear Theory and Its Applications, IEICE , volume=. 2016 , publisher=
2016
-
[60]
Analysis and Applications , volume=
Reproducing kernels of Sobolev spaces on R d and applications to embedding constants and tractability , author=. Analysis and Applications , volume=. 2018 , publisher=
2018
-
[61]
International Conference on Machine Learning , pages=
On the optimality of misspecified kernel ridge regression , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[62]
ArXiv , year=
Learning curves for Gaussian process regression with power-law priors and targets , author=. ArXiv , year=
-
[63]
International Conference on Artificial Intelligence and Statistics , pages=
Kernel regression in high dimensions: Refined analysis beyond double descent , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
2021
-
[64]
Conference on Learning Theory , pages=
On the multiple descent of minimum-norm interpolants and restricted lower isometry of kernels , author=. Conference on Learning Theory , pages=. 2020 , organization=
2020
-
[65]
Analysis and Applications , volume=
Cross-validation based adaptation for regularization operators in learning theory , author=. Analysis and Applications , volume=. 2010 , publisher=
2010
-
[66]
Nature communications , volume=
Spectral bias and task-model alignment explain generalization in kernel regression and infinitely wide neural networks , author=. Nature communications , volume=. 2021 , publisher=
2021
-
[67]
The Eleventh International Conference on Learning Representations , year=
Strong inductive biases provably prevent harmless interpolation , author=. The Eleventh International Conference on Learning Representations , year=
-
[68]
Advances in Neural Information Processing Systems , volume=
When do neural networks outperform kernel methods? , author=. Advances in Neural Information Processing Systems , volume=
-
[69]
International Conference on Learning Representations , year=
The Three Stages of Learning Dynamics in High-dimensional Kernel Methods , author=. International Conference on Learning Representations , year=
-
[70]
Applied and Computational Harmonic Analysis , volume=
Generalization error of random feature and kernel methods: Hypercontractivity and kernel matrix concentration , author=. Applied and Computational Harmonic Analysis , volume=. 2022 , publisher=
2022
-
[71]
arXiv preprint arXiv:2204.10425 , year=
Spectrum of inner-product kernel matrices in the polynomial regime and multiple descent phenomenon in kernel ridge regression , author=. arXiv preprint arXiv:2204.10425 , year=
-
[72]
International Conference on Machine Learning , pages=
How rotational invariance of common kernels prevents generalization in high dimensions , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[73]
arXiv preprint arXiv:2205.06798 , year=
Sharp asymptotics of kernel ridge regression beyond the linear regime , author=. arXiv preprint arXiv:2205.06798 , year=
-
[74]
The Annals of Statistics , number =
Tengyuan Liang and Alexander Rakhlin , title =. The Annals of Statistics , number =
-
[75]
Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS) , year=
Precise Learning Curves and Higher-Order Scaling Limits for Dot Product Kernel Regression , author=. Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS) , year=
-
[76]
Thirty-seventh Conference on Neural Information Processing Systems , year=
On the Asymptotic Learning Curves of Kernel Ridge Regression under Power-law Decay , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[77]
Conference on Learning Theory , pages=
Consistency of interpolation with Laplace kernels is a high-dimensional phenomenon , author=. Conference on Learning Theory , pages=. 2019 , organization=
2019
-
[78]
Proceedings of Thirty Fifth Conference on Learning Theory , author =
Kernel Interpolation in. Proceedings of Thirty Fifth Conference on Learning Theory , author =. 2022 , month = jul, series =
2022
-
[79]
Communications on Pure and Applied Mathematics , volume=
The generalization error of random features regression: Precise asymptotics and the double descent curve , author=. Communications on Pure and Applied Mathematics , volume=. 2022 , publisher=
2022
-
[80]
Conference on Learning Theory , pages=
Learning with invariances in random features and kernel models , author=. Conference on Learning Theory , pages=. 2021 , organization=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.