Recognition: unknown
From Sparse to Dense: Spatio-Temporal Fusion for Multi-View 3D Human Pose Estimation with DenseWarper
Pith reviewed 2026-05-15 02:16 UTC · model grok-4.3
The pith
Sparse interleaved multi-view inputs with DenseWarper outperform traditional dense simultaneous multi-view methods for 3D human pose estimation on Human3.6M and MPI-INF-3DHP datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Results demonstrate that our method, utilizing only sparse interleaved images as input, outperforms traditional dense multi-view input approaches and achieves state-of-the-art performance.
Load-bearing premise
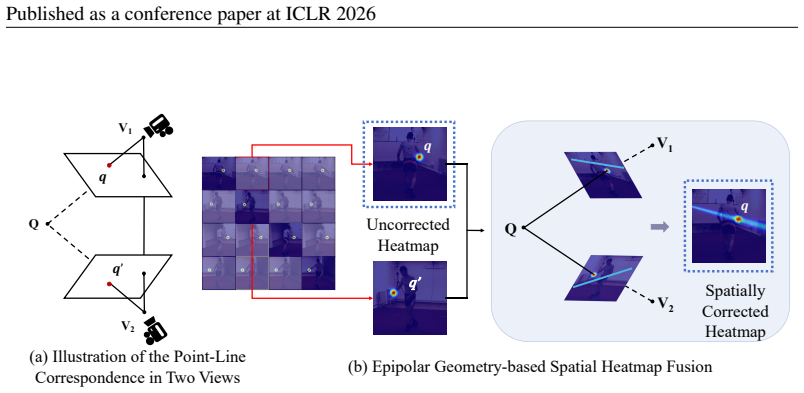
That temporal offsets in the interleaved views can be reliably bridged by epipolar-geometry-based heatmap exchange without introducing motion-induced errors or losing spatial precision.
Figures







read the original abstract
In multi-view 3D human pose estimation, models typically rely on images captured simultaneously from different camera views to predict a pose at a specific moment. While providing accurate spatial information, this traditional approach often overlooks the rich temporal dependencies between adjacent frames. We propose a novel 3D human pose estimation input method: the sparse interleaved input to address this. This method leverages images captured from different camera views at various time points (e.g., View 1 at time $t$ and View 2 at time $t+\delta$), allowing our model to capture rich spatio-temporal information and effectively boost performance. More importantly, this approach offers two key advantages: First, it can theoretically increase the output pose frame rate by N times with N cameras, thereby breaking through single-view frame rate limitations and enhancing the temporal resolution of the production. Second, using a sparse subset of available frames, our method can reduce data redundancy and simultaneously achieve better performance. We introduce the DenseWarper model, which leverages epipolar geometry for efficient spatio-temporal heatmap exchange. We conducted extensive experiments on the Human3.6M and MPI-INF-3DHP datasets. Results demonstrate that our method, utilizing only sparse interleaved images as input, outperforms traditional dense multi-view input approaches and achieves state-of-the-art performance. The source code for this work is available at: https://github.com/lingli1724/DenseWarper-ICLR2026
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DenseWarper, a spatio-temporal fusion model for multi-view 3D human pose estimation that accepts sparse interleaved inputs (e.g., View 1 at time t and View 2 at t+δ) instead of simultaneous dense multi-view frames. It uses epipolar geometry to exchange heatmaps across views and time, claiming this captures richer temporal information, outperforms traditional dense simultaneous inputs, achieves SOTA on Human3.6M and MPI-INF-3DHP, reduces data redundancy, and can theoretically increase output frame rate by a factor of N with N cameras.
Significance. If the central claim holds under rigorous validation, the work would enable higher temporal resolution in 3D pose estimation without requiring perfectly synchronized dense captures, which could benefit applications with bandwidth or synchronization constraints while also reducing input redundancy. The release of source code at the cited GitHub link is a positive factor for reproducibility.
major comments (2)
- [Abstract, §4] Abstract and experimental section: the claim that sparse interleaved inputs outperform dense simultaneous multi-view baselines is load-bearing for the paper's contribution, yet no ablations isolate the effect of temporal offset δ, no quantitative bound on acceptable δ is given, and no error analysis versus motion speed is reported; this leaves the outperformance dependent on the untested assumption that epipolar exchange fully compensates for joint displacements without injecting spatial error.
- [§3] Method description: the DenseWarper heatmap exchange step projects epipolar lines between time-offset views, but the manuscript provides no explicit comparison or metric quantifying motion-induced misalignment against a simultaneous dense baseline, which is required to substantiate that the fused features preserve or improve 3D accuracy.
minor comments (1)
- [Abstract] The abstract states results on two benchmarks but does not specify the exact train/test splits, camera configurations, or evaluation protocol used; adding these details would improve clarity without altering the core claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, clarifying the support for our claims while committing to targeted revisions that strengthen the experimental validation without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and experimental section: the claim that sparse interleaved inputs outperform dense simultaneous multi-view baselines is load-bearing for the paper's contribution, yet no ablations isolate the effect of temporal offset δ, no quantitative bound on acceptable δ is given, and no error analysis versus motion speed is reported; this leaves the outperformance dependent on the untested assumption that epipolar exchange fully compensates for joint displacements without injecting spatial error.
Authors: We agree that isolating the effect of δ and providing motion-speed analysis would strengthen the evidence. The current results on Human3.6M and MPI-INF-3DHP demonstrate consistent outperformance of sparse interleaved inputs over dense simultaneous baselines, with the epipolar-line projection in DenseWarper designed to maintain 3D geometric consistency across small temporal offsets. To directly address the concern, we will add an ablation varying δ, report performance as a function of joint velocity derived from ground truth, and include a practical bound on acceptable δ in the revised manuscript. revision: yes
-
Referee: [§3] Method description: the DenseWarper heatmap exchange step projects epipolar lines between time-offset views, but the manuscript provides no explicit comparison or metric quantifying motion-induced misalignment against a simultaneous dense baseline, which is required to substantiate that the fused features preserve or improve 3D accuracy.
Authors: Section 3 describes the epipolar projection for heatmap exchange to enable spatio-temporal fusion. While an explicit misalignment metric is not currently reported, the superior 3D accuracy in the experimental tables indicates effective compensation. We will add a quantitative comparison in the revised method section, computing average joint displacement between time-offset frames using ground-truth poses and contrasting it against the simultaneous dense case to explicitly quantify any residual misalignment. revision: yes
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[2]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
- [3]
-
[4]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Rhodin, Helge and Sp. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[5]
Baumgartner, Tobias and Klatt, Stefanie , booktitle=
-
[6]
Jiang, Boyuan and Hu, Lei and Xia, Shihong , booktitle=
-
[7]
Qiu, Haibo and Wang, Chunyu and Wang, Jingdong and Wang, Naiyan and Zeng, Wenjun , booktitle=
-
[8]
Wu, Size and Jin, Sheng and Liu, Wentao and Bai, Lei and Qian, Chen and Liu, Dong and Ouyang, Wanli , booktitle=
-
[9]
Chen, Long and Ai, Haizhou and Chen, Rui and Zhuang, Zijie and Liu, Shuang , booktitle=
-
[10]
He, Yihui and Yan, Rui and Fragkiadaki, Katerina and Yu, Shoou-I , booktitle=
-
[11]
Hyla, Pawel , journal=
-
[12]
Ionescu, Catalin and Papava, Dragos and Olaru, Vlad and Sminchisescu, Cristian , journal=
-
[13]
Li, Sijin and Chan, Antoni B , booktitle=
-
[14]
Martinez, Julieta and Hossain, Rayat and Romero, Javier and Little, James J , booktitle=
-
[15]
Zhao, Long and Peng, Xi and Tian, Yu and Kapadia, Mubbasir and Metaxas, Dimitris N , booktitle=
-
[16]
Pavlakos, Georgios and Zhu, Luyang and Zhou, Xiaowei and Daniilidis, Kostas , booktitle=
-
[17]
Hartley, Richard and Zisserman, Andrew , journal=
-
[18]
Remelli, Edoardo and Han, Shangchen and Honari, Sina and Fua, Pascal and Wang, Robert , booktitle=
-
[19]
Hossain, Mir Rayat Imtiaz and Little, James J , booktitle=
-
[20]
Pavllo, Dario and Feichtenhofer, Christoph and Grangier, David and Auli, Michael , booktitle=
-
[21]
Graham, Benjamin and Engelcke, Martin and van der Maaten, Laurens , booktitle=
-
[22]
Zhu, Xizhou and Su, Weijie and Lu, Lewei and Li, Bin and Wang, Xiaogang and Dai, Jifeng , booktitle=
-
[23]
Zhang, Kaihao and Luo, Wenhan and Zhong, Yiran and Ma, Lin and Liu, Wei and Li, Hongdong , journal=
-
[24]
Dai, Jifeng and Qi, Haozhi and Xiong, Yuwen and Li, Yi and Zhang, Guodong and Hu, Han and Wei, Yichen , booktitle=
-
[25]
Zheng, Ce and Zhu, Shiwei and Mendieta, Matias and Yang, Taojiannan and Chen, Chen and Ding, Zhengming , booktitle=
-
[26]
Sun, Xiao and Xiao, Bin and Wei, Fang and Liang, Shuang and Wei, Yichen , booktitle=
-
[27]
Zheng, Ce and Wu, Wentao and Yang, Tianyu and Zhu, Shiwei and Chen, Chen and Liu, Ronggang and Shen, Jianfei and Kehtarnavaz, Nasser and Shah, Mubarak , journal=
-
[28]
Zou, Zhe and Huang, Yanyu and Lu, Yang and Liu, Feng , booktitle=
-
[29]
Mehta, Dushyant and Rhodin, Helge and Casas, Dan and Fua, Pascal and Sotnychenko, Oleksandr and Xu, Weipeng and Theobalt, Christian , booktitle=
-
[30]
Yu, Fisher and Koltun, Vladlen and Funkhouser, Thomas , booktitle=
-
[31]
Chen, Ziyi and Sugimoto, Akihiro and Lai, Shang-Hong , booktitle=
-
[32]
Su, Yukun and Lin, Guosheng and Wu, Qingyao , booktitle=
-
[33]
Yu, Bruce XB and Zhang, Zhi and Liu, Yongxu and Zhong, Sheng-hua and Liu, Yan and Chen, Chang Wen , booktitle=
-
[34]
Peng, Jihua and Zhou, Yanghong and Mok, PY , booktitle=
-
[35]
Ma, Haoyu and Wang, Zhe and Chen, Yifei and Kong, Deying and Chen, Liangjian and Liu, Xingwei and Yan, Xiangyi and Tang, Hao and Xie, Xiaohui , booktitle=
-
[36]
Chen, Yilun and Wang, Zhicheng and Peng, Yuxiang and Zhang, Zhiqiang and Yu, Gang and Sun, Jian , booktitle=
-
[37]
Xiao, Bin and Wu, Haiping and Wei, Yichen , booktitle=
-
[38]
Bridgeman, Lewis and Volino, Marco and Guillemaut, Jean-Yves and Hilton, Adrian , booktitle=
-
[39]
Chu, Hau and Lee, Jia-Hong and Lee, Yao-Chih and Hsu, Ching-Hsien and Li, Jia-Da and Chen, Chu-Song , booktitle=
-
[40]
Hindle, Benjamin R and Keogh, Justin WL and Lorimer, Anna V , journal=
-
[41]
Menolotto, Matteo and Komaris, Dimitrios-Sokratis and Tedesco, Salvatore and O’Flynn, Brendan and Walsh, Michael , journal=
-
[42]
Jiang, Wenjie and Yin, Yongkai and Jiao, Junpeng and Zhao, Xian and Sun, Baoqing , journal=
-
[43]
Construction and Building Materials , volume=
Mei, Qipei and G. Construction and Building Materials , volume=
-
[44]
Lee, Chunggi and Kim, Yeonjun and Jin, Seungmin and Kim, Dongmin and Maciejewski, Ross and Ebert, David and Ko, Sungahn , journal=
-
[45]
Yang, Ming and Wang, Shige and Bakita, Joshua and Vu, Thanh and Smith, F Donelson and Anderson, James H and Frahm, Jan-Michael , booktitle=
-
[46]
Zhou, Kangkang and Zhang, Lijun and Lu, Feng and Zhou, Xiang-Dong and Shi, Yu , booktitle=
-
[47]
Sturm, Peter , booktitle=
-
[48]
Moon, Gyeongsik and Chang, Ju Yong and Lee, Kyoung Mu , booktitle=
-
[49]
Park, Sungheon and Hwang, Jihye and Kwak, Nojun , booktitle=
-
[50]
Pavlakos, Georgios and Zhou, Xiaowei and Daniilidis, Kostas , booktitle=
-
[51]
Tekin, Bugra and Rozantsev, Artem and Lepetit, Vincent and Fua, Pascal , booktitle=
-
[52]
Wehrbein, Tom and Rudolph, Marco and Rosenhahn, Bodo and Wandt, Bastian , booktitle=
-
[53]
Chen, Tianlang and Fang, Chen and Shen, Xiaohui and Zhu, Yiheng and Chen, Zhili and Luo, Jiebo , journal=
-
[54]
Liu, Ruixu and Shen, Ju and Wang, He and Chen, Chen and Cheung, Sen-ching and Asari, Vijayan , booktitle=
-
[55]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Zheng, Ce and Zhu, Sijie and Mendieta, Matias and Yang, Taojiannan and Chen, Chen and Ding, Zhengming , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[56]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Zhao, Qitao and Zheng, Ce and Liu, Mengyuan and Wang, Pichao and Chen, Chen , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[57]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Li, Wenhao and Liu, Hong and Tang, Hao and Wang, Pichao and Van Gool, Luc , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[58]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Zhang, Jinlu and Tu, Zhigang and Yang, Jianyu and Chen, Yujin and Yuan, Junsong , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[59]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Tang, Zhenhua and Qiu, Zhaofan and Hao, Yanbin and Hong, Richang and Yao, Ting , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[60]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Shan, Wenkang and Liu, Zhenhua and Zhang, Xinfeng and Wang, Zhao and Han, Kai and Wang, Shanshe and Ma, Siwei and Gao, Wen , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[61]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Cai, Yujun and Ge, Liuhao and Liu, Jun and Cai, Jianfei and Cham, Tat-Jen and Yuan, Junsong and Thalmann, Nadia Magnenat , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[62]
Hu, Wenbo and Zhang, Changgong and Zhan, Fangneng and Zhang, Lei and Wong, Tien-Tsin , booktitle=
-
[63]
Liu, Kenkun and Ding, Rongqi and Zou, Zhiming and Wang, Le and Tang, Wei , booktitle=
-
[64]
Wang, Jingbo and Yan, Sijie and Xiong, Yuanjun and Lin, Dahua , booktitle=
-
[65]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Xu, Tianhan and Takano, Wataru , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[66]
and Zhang, Zhi and Liu, Yongxu and Zhong, Sheng-hua and Liu, Yan and Chen, Chang Wen , title =
Yu, Bruce X.B. and Zhang, Zhi and Liu, Yongxu and Zhong, Sheng-hua and Liu, Yan and Chen, Chang Wen , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
- [67]
-
[68]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Zou, Zhiming and Tang, Wei , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[69]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Gong, Jia and Foo, Lin Geng and Fan, Zhipeng and Ke, Qiuhong and Rahmani, Hossein and Liu, Jun , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[70]
Li, Han and Shi, Bowen and Dai, Wenrui and Zheng, Hongwei and Wang, Botao and Sun, Yu and Guo, Min and Li, Chenglin and Zou, Junni and Xiong, Hongkai , booktitle=
-
[71]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Zhao, Weixi and Wang, Weiqiang and Tian, Yunjie , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[72]
Zhu, Yiran and Xu, Xing and Shen, Fumin and Ji, Yanli and Gao, Lianli and Shen, Heng Tao , booktitle=
-
[73]
and Picard, David and Tabia, Hedi , title =
Luvizon, Diogo C. and Picard, David and Tabia, Hedi , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[74]
Luvizon, Diogo C and Tabia, Hedi and Picard, David , journal=
-
[75]
Moon, Gyeongsik and Lee, Kyoung Mu , booktitle=
-
[76]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
- [77]
-
[78]
Han, Xiao and Ren, Yiming and Yao, Yichen and Sun, Yujing and Ma, Yuexin , booktitle=
-
[79]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Li, Jialian and Zhang, Jingyi and Wang, Zhiyong and Shen, Siqi and Wen, Chenglu and Ma, Yuexin and Xu, Lan and Yu, Jingyi and Wang, Cheng , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[80]
Ren, Yiming and Zhao, Chengfeng and He, Yannan and Cong, Peishan and Liang, Han and Yu, Jingyi and Xu, Lan and Ma, Yuexin , journal=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.