Recognition: 2 theorem links
· Lean TheoremPrompt Segmentation and Annotation Optimisation: Controlling LLM Behaviour via Optimised Segment-Level Annotations
Pith reviewed 2026-05-15 01:25 UTC · model grok-4.3
The pith
Optimised segment-level annotations on decomposed prompts improve LLM responses while preserving the original to avoid degradation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Optimised segment-level annotations can lead to improved LLM responses, with the original prompt retained as a candidate in the optimisation space to prevent performance degradation. Empirical evaluations indicate that PSAO benefits from annotations in terms of improved reasoning accuracy and self-consistency.
What carries the argument
Prompt Segmentation and Annotation Optimisation (PSAO), which decomposes a prompt into interpretable segments and augments each with human-readable annotations to guide focus allocation.
If this is right
- Improved reasoning accuracy in LLM outputs for tasks requiring step-by-step thinking.
- Greater self-consistency across multiple generations from the same prompt.
- More efficient optimisation by narrowing the search to segment-annotation combinations.
- Controllable guidance without altering the core intent of the original prompt.
- Foundation for future methods to automatically find optimal segmentations and annotations.
Where Pith is reading between the lines
- This could lower the computational expense of prompt tuning by making the space more interpretable and smaller.
- Applications might extend to other areas like code generation or creative writing where focus on key parts matters.
- Testing on diverse domains could reveal if certain annotation types work better for specific tasks.
- Integration with existing prompt optimizers might create hybrid systems that combine segmentation with gradient-based methods.
Load-bearing premise
Human-readable annotations like {important} or {not important} can reliably direct LLMs to allocate focus and resolve confusion without changing the original prompt's meaning.
What would settle it
Running the method on a reasoning benchmark such as arithmetic word problems and observing that accuracy or consistency does not increase compared to using the unmodified original prompt.
Figures




read the original abstract
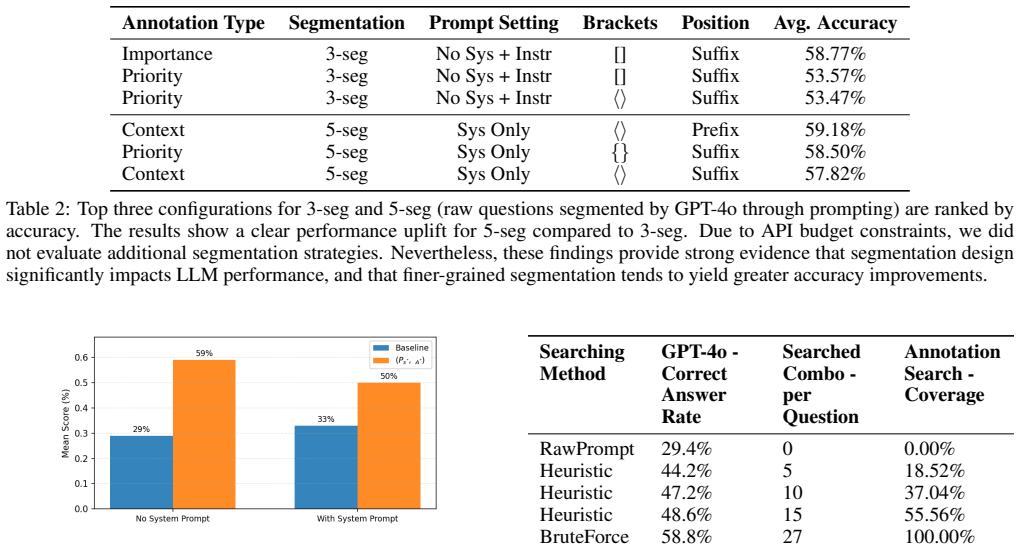
Prompt engineering is crucial for effective interaction with generative artificial intelligence systems, yet existing optimisation methods often operate over an unstructured and vast prompt space, leading to high computational costs and potential distortions of the original intent. We introduce Prompt Segmentation and Annotation Optimisation (PSAO), a structured prompt optimisation framework designed to improve prompt optimisation controllability and efficiency. PSAO decomposes a prompt into interpretable segments (e.g., sentences) and augments each with human-readable annotations (e.g., {not important}, {important}, {very important}). These annotations guide large language models (LLMs) in allocating focus and clarifying confusion during response generation. We formally define the segmentations and annotations and demonstrate that optimised segment-level annotations can lead to improved LLM responses, with the original prompt retained as a candidate in the optimisation space to prevent performance degradation. Empirical evaluations indicate that PSAO benefits from annotations in terms of improved reasoning accuracy and self-consistency. However, developing efficient methods for identifying optimal segmentations and annotations remains challenging and is reserved for future investigation. This work is intended as a proof of concept, demonstrating the feasibility and potential of segment-level annotation optimisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Prompt Segmentation and Annotation Optimisation (PSAO), a framework that decomposes input prompts into interpretable segments (e.g., sentences) and augments each with human-readable annotations such as {important}, {not important}, or {very important}. These annotations are intended to guide LLMs in focus allocation and confusion resolution during generation. The manuscript formally defines segments and annotations, claims that optimised segment-level annotations improve LLM responses (with the original prompt retained as a candidate to avoid degradation), and reports that empirical evaluations show gains in reasoning accuracy and self-consistency. It explicitly positions the work as a proof of concept and defers development of efficient methods for identifying optimal segmentations and annotations to future work.
Significance. If the empirical benefits can be shown to arise from a genuine optimisation procedure rather than manual annotation choices, PSAO would provide a more controllable and lower-cost alternative to unstructured prompt search, with the explicit retention of the original prompt as a safeguard against intent distortion. The conceptual separation of segmentation from annotation is a clear strength and could support future reproducible experiments once an optimisation algorithm is supplied.
major comments (2)
- [Abstract] Abstract: the central claim that 'optimised segment-level annotations can lead to improved LLM responses' and that 'empirical evaluations indicate that PSAO benefits from annotations' is unsupported. The manuscript states that 'developing efficient methods for identifying optimal segmentations and annotations remains challenging and is reserved for future investigation' and labels the contribution a proof of concept. No objective function, search procedure, gradient, or even heuristic for choosing annotations is defined or executed, so any reported gains cannot be attributed to optimisation.
- [Abstract] Abstract: the soundness of the empirical claims cannot be assessed because no methods, datasets, baselines, quantitative results, or experimental protocol are supplied. The reader is left unable to verify the asserted improvements in reasoning accuracy and self-consistency.
minor comments (1)
- [Abstract] The abstract would benefit from an explicit statement that the current results rely on manually chosen annotations rather than an automated optimisation loop.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We agree that the abstract's wording implies a completed optimization procedure and provides insufficient experimental detail for a proof-of-concept paper. We will revise the abstract to accurately describe the scope and add a full experiments section with methods, datasets, and results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'optimised segment-level annotations can lead to improved LLM responses' and that 'empirical evaluations indicate that PSAO benefits from annotations' is unsupported. The manuscript states that 'developing efficient methods for identifying optimal segmentations and annotations remains challenging and is reserved for future investigation' and labels the contribution a proof of concept. No objective function, search procedure, gradient, or even heuristic for choosing annotations is defined or executed, so any reported gains cannot be attributed to optimisation.
Authors: We agree that the abstract overstates the optimization aspect. The current work is explicitly a proof of concept that illustrates the potential of segment-level annotations using illustrative examples; no search procedure or objective function is defined or executed. We will revise the abstract to state that we demonstrate feasibility and potential benefits of segment-level annotations in selected cases, while clarifying that systematic identification of optimal segmentations and annotations is reserved for future work. This removes any implication that reported gains result from an optimization procedure. revision: yes
-
Referee: [Abstract] Abstract: the soundness of the empirical claims cannot be assessed because no methods, datasets, baselines, quantitative results, or experimental protocol are supplied. The reader is left unable to verify the asserted improvements in reasoning accuracy and self-consistency.
Authors: We acknowledge that the abstract provides no experimental details, making verification impossible. Although the manuscript is positioned as a proof of concept, we will add a dedicated Experiments section that specifies the datasets, baselines, quantitative metrics, evaluation protocol, and results for reasoning accuracy and self-consistency. This will allow readers to assess the claims directly. revision: yes
Circularity Check
No significant circularity; PSAO framework is an independent conceptual proposal without derived predictions or self-referential reductions
full rationale
The manuscript introduces Prompt Segmentation and Annotation Optimisation (PSAO) as a new structured framework, formally defines segments and human-readable annotations, and presents empirical evaluations on manually selected annotations as a proof of concept. No equations, objective functions, search procedures, or fitted parameters appear in the provided text. The central claim that 'optimised segment-level annotations can lead to improved LLM responses' is not derived from any internal construction or prior self-citation chain; instead, the paper explicitly defers development of methods for identifying optimal segmentations and annotations to future work. All load-bearing elements remain external to any self-referential loop, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human-readable importance annotations can guide LLMs in allocating focus without distorting original prompt intent
invented entities (1)
-
Segment-level annotations
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PSAO decomposes a prompt into interpretable segments ... and augments each with human-readable annotations (e.g., {not important}, {important}, {very important}).
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3 (Improvement with Finer Segmentation): ... max Q(M(P_S2,A2)) ≥ max Q(M(P_S1,A1))
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
[Agrawalet al., 2025 ] Lakshya A. Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl- Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexan- dros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. GEPA: Reflective prompt evolution can outperform reinforcement lear...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
[Bieet al., 2024 ] Yequan Bie, Luyang Luo, Zhixuan Chen, and Hao Chen. Xcoop: Explainable prompt learning for computer-aided diagnosis via concept-guided context optimization. InProceedings of the 27th International Conference on Medical Image Computing and Computer- Assisted Intervention (MICCAI), pages 773–783,
work page 2024
-
[3]
Evoprompting: Language models for code-level neu- ral architecture search
[Chenet al., 2023 ] Angelica Chen, David Dohan, and David So. Evoprompting: Language models for code-level neu- ral architecture search. InAdvances in Neural Information Processing Systems 37,
work page 2023
-
[4]
Instructzero: Effi- cient instruction optimization for black-box large language models
[Chenet al., 2024 ] Lichang Chen, Jiuhai Chen, Tom Gold- stein, Heng Huang, and Tianyi Zhou. Instructzero: Effi- cient instruction optimization for black-box large language models. InProceedings of the 41st International Confer- ence on Machine Learning,
work page 2024
-
[5]
Training Verifiers to Solve Math Word Problems
[Cobbeet al., 2021 ] Karl Cobbe, Vineet Kosaraju, Moham- mad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Train- ing verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Rlprompt: Optimizing discrete text prompts with reinforcement learning
[Denget al., 2022 ] Mingkai Deng, Jianyu Wang, Cheng- Ping Hsieh, Yihan Wang, Han Guo, Tianmin Shu, Meng Song, Eric Xing, and Zhiting Hu. Rlprompt: Optimizing discrete text prompts with reinforcement learning. InPro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 3369–3391. Associ- ation for Computational Linguistics,
work page 2022
-
[7]
Promptbreeder: Self-referential self- improvement via prompt evolution
[Fernandoet al., 2024 ] Chrisantha Fernando, Dylan Sunil Banarse, Henryk Michalewski, Simon Osindero, and Tim Rockt ¨aschel. Promptbreeder: Self-referential self- improvement via prompt evolution. InProceedings of the 41st International Conference on Machine Learning,
work page 2024
-
[8]
Crispo: Multi-aspect critique-suggestion- guided automatic prompt optimization for text generation
[Heet al., 2025 ] Han He, Qianchu Liu, Lei Xu, Chaitanya Shivade, Yi Zhang, Sundararajan Srinivasan, and Ka- trin Kirchhoff. Crispo: Multi-aspect critique-suggestion- guided automatic prompt optimization for text generation. InProceedings of the 2025 AAAI Conference on Artificial Intelligence, pages 24014–24022, April
work page 2025
-
[9]
Measuring massive multitask lan- guage understanding
[Hendryckset al., 2021 ] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask lan- guage understanding. InProceedings of the 9th Interna- tional Conference on Learning Representations,
work page 2021
-
[10]
[Huanget al., 2025 ] Guang Huang, Yanan Xiao, Lu Jiang, Minghao Yin, and Pengyang Wang. Beyond prompt engineering: A reinforced token-level input refinement for large language models.Proceedings of the 2025 AAAI Conference on Artificial Intelligence, 39(22):24113– 24121,
work page 2025
-
[11]
[Hugheset al., 2024 ] John Hughes, Sara Price, Aengus Lynch, Rylan Schaeffer, Fazl Barez, Sanmi Koyejo, Henry Sleight, Erik Jones, Ethan Perez, and Mrinank Sharma. Best-of-n jailbreaking,
work page 2024
-
[12]
[Jain and Chowdhary, 2025] Yash Jain and Vishal Chowd- hary. Local prompt optimization. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 75–81. Association for Computational Linguistics,
work page 2025
-
[13]
Decomposed prompting: A modular approach for solving complex tasks
[Khotet al., 2023 ] Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. Decomposed prompting: A modular approach for solving complex tasks. InProceedings of the 11th International Conference on Learning Represen- tations,
work page 2023
-
[14]
The power of scale for parameter-efficient prompt tuning
[Lesteret al., 2021 ] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059. Association for Computational Linguis- tics,
work page 2021
-
[15]
Prefix- tuning: Optimizing continuous prompts for generation
[Li and Liang, 2021] Xiang Lisa Li and Percy Liang. Prefix- tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Vol- ume 1: Long Papers), pages 4582–4597. Association for Computational Lin...
work page 2021
-
[16]
Program induction by rationale gener- ation: Learning to solve and explain algebraic word prob- lems
[Linget al., 2017 ] Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale gener- ation: Learning to solve and explain algebraic word prob- lems. InProceedings of the 55th Annual Meeting of the As- sociation for Computational Linguistics (Volume 1: Long Papers), pages 158–167. Association for Computational Linguistics,
work page 2017
-
[17]
Optimizing instruc- tions and demonstrations for multi-stage language model programs
[Opsahl-Onget al., 2024 ] Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instruc- tions and demonstrations for multi-stage language model programs. InProceedings of the 2024 Conference on Em- pirical Methods in Natural Language Processing, pages 9340–9366. Association for Compu...
work page 2024
-
[18]
[Pryzantet al., 2023 ] Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic Prompt Optimization with “Gradient Descent” and Beam Search. InProceedings of the 2023 Conference on Em- pirical Methods in Natural Language Processing, pages 7957–7968. Association for Computational Linguistics,
work page 2023
-
[19]
Solving General Arithmetic Word Problems
[Roy and Roth, 2015] Subhro Roy and Dan Roth. Solving General Arithmetic Word Problems. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1743–1752. Association for Computational Linguistics,
work page 2015
-
[20]
Prompt Optimization in Large Language Mod- els.Mathematics, 12(6),
[Sabbatellaet al., 2024 ] Antonio Sabbatella, Andrea Ponti, Ilaria Giordani, Antonio Candelieri, and Francesco Archetti. Prompt Optimization in Large Language Mod- els.Mathematics, 12(6),
work page 2024
-
[21]
[Sarmahet al., 2024 ] Bhaskarjit Sarmah, Kriti Dutta, Anna Grigoryan, Sachin Tiwari, Stefano Pasquali, and Dha- gash Mehta. A Comparative Study of DSPy Teleprompter Algorithms for Aligning Large Language Models Eval- uation Metrics to Human Evaluation.arXiv preprint arXiv:2412.06570,
-
[22]
Logan IV , Eric Wallace, and Sameer Singh
[Shinet al., 2020 ] Taylor Shin, Yasaman Razeghi, Robert L. Logan IV , Eric Wallace, and Sameer Singh. AutoPrompt: Eliciting knowledge from language models with automati- cally generated prompts. InProceedings of the 2020 Con- ference on Empirical Methods in Natural Language Pro- cessing, pages 4222–4235. Association for Computational Linguistics,
work page 2020
-
[23]
Reflex- ion: Language Agents with Verbal Reinforcement Learn- ing
[Shinnet al., 2023 ] Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflex- ion: Language Agents with Verbal Reinforcement Learn- ing. InAdvances in Neural Information Processing Sys- tems 36,
work page 2023
-
[24]
Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them
[Suzgunet al., 2023 ] Mirac Suzgun, Nathan Scales, Nathanael Sch ¨arli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, and Jason Wei. Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them. InFindings of the 2023 Association for Com- putational Linguistics, pages 13003–13051. Association for...
work page 2023
-
[25]
[Tanget al., 2025 ] Xinyu Tang, Xiaolei Wang, Wayne Xin Zhao, Siyuan Lu, Yaliang Li, and Ji-Rong Wen. Unleash- ing the Potential of Large Language Models as Prompt Op- timizers: Analogical Analysis with Gradient-based Model Optimizers.Proceedings of the 2025 AAAI Conference on Artificial Intelligence, 39(24):25264–25272,
work page 2025
-
[26]
PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Op- timization
[Wanget al., 2024 ] Xinyuan Wang, Chenxi Li, Zhen Wang, Fan Bai, Haotian Luo, Jiayou Zhang, Nebojsa Jojic, Eric P Xing, and Zhiting Hu. PromptAgent: Strategic Planning with Language Models Enables Expert-level Prompt Op- timization. InProceedings of the 12th International Con- ference on Learning Representations,
work page 2024
-
[27]
Hard Prompts Made Easy: Gradient-Based Dis- crete Optimization for Prompt Tuning and Discovery
[Wenet al., 2023 ] Yuxin Wen, Neel Jain, John Kirchen- bauer, Micah Goldblum, Jonas Geiping, and Tom Gold- stein. Hard Prompts Made Easy: Gradient-Based Dis- crete Optimization for Prompt Tuning and Discovery. In Advances in Neural Information Processing Systems, vol- ume 36, pages 51008–51025,
work page 2023
-
[28]
StraGo: Harnessing Strategic Guidance for Prompt Optimization
[Wuet al., 2024 ] Yurong Wu, Yan Gao, Bin Zhu, Zineng Zhou, Xiaodi Sun, Sheng Yang, Jian-Guang Lou, Zhim- ing Ding, and Linjun Yang. StraGo: Harnessing Strategic Guidance for Prompt Optimization. InFindings of the As- sociation for Computational Linguistics: EMNLP 2024, pages 10043–10061,
work page 2024
-
[29]
Large Language Models as Optimizers
[Yanget al., 2024 ] Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large Language Models as Optimizers. InPro- ceedings of the 12th International Conference on Learning Representations,
work page 2024
-
[30]
Unveiling the lexical sensitivity of llms: Combinatorial optimization for prompt enhancement
[Zhanet al., 2024 ] Pengwei Zhan, Zhen Xu, Qian Tan, Jie Song, and Ru Xie. Unveiling the lexical sensitivity of llms: Combinatorial optimization for prompt enhancement. In Proceedings of the 2024 Conference on Empirical Meth- ods in Natural Language Processing, pages 5128–5154. Association for Computational Linguistics,
work page 2024
-
[31]
Causal prompting: Debi- asing large language model prompting based on front-door adjustment
[Zhanget al., 2025 ] Congzhi Zhang, Linhai Zhang, Jialong Wu, Yulan He, and Deyu Zhou. Causal prompting: Debi- asing large language model prompting based on front-door adjustment. InProceedings of the 2025 AAAI Conference on Artificial Intelligence, pages 25842–25850,
work page 2025
-
[32]
Genetic Prompt Search via Exploiting Language Model Probabilities
[Zhaoet al., 2023 ] Jiangjiang Zhao, Zhuoran Wang, and Fangchun Yang. Genetic Prompt Search via Exploiting Language Model Probabilities. In Edith Elkind, editor, Proceedings of the Thirty-Second International Joint Con- ference on Artificial Intelligence, IJCAI-23, pages 5296–
work page 2023
-
[33]
Large language models are human-level prompt engineers
[Zhouet al., 2023 ] Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InProceedings of the 11th International Conference on Learning Representations,
work page 2023
-
[34]
Riot: Efficient prompt refinement with residual optimization tree
[Zhouet al., 2025 ] Chenyi Zhou, Zhengyan Shi, Yuan Yao, Lei Liang, Huajun Chen, and Qiang Zhang. Riot: Efficient prompt refinement with residual optimization tree. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22307–22323,
work page 2025
-
[35]
Sampled 50 questions from benchmark datasets selected based on low baseline performance. ID Question Answer Dataset Q13 How would a typical person answer each of the following questions about causation? Tom has a huge garden and loves flowers. He employed two gardeners who take care of the plants on his 30 flower beds: Alex and Benni. Both can independent...
work page 2000
-
[36]
ID Question Answer Dataset Q26 Jim decides to go to college to earn some more money
Sampled 50 questions from benchmark datasets selected based on low baseline performance. ID Question Answer Dataset Q26 Jim decides to go to college to earn some more money. It takes him 4 years to finish and he gets $50,000 in loans per year. If he had a 25k a year job before college and his college degree tripled his income, how long would it take to ea...
work page 1972
-
[37]
McClellan won only New Jersey, Delaware, and Kentucky. Re- publicans drew support from native-born farmers, skilled and professional workers, those of New England descent, younger voters, and military personnel. Democrats were strongest in the cities and among Irish- and German-Americans (the most populous immigrant groups). It has been estimated that Lin...
work page 1944
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.