Recognition: 2 theorem links
· Lean TheoremUncertainty Quantification for Large Language Diffusion Models
Pith reviewed 2026-05-15 01:33 UTC · model grok-4.3
The pith
Expected trajectory dissimilarity from the denoising process lower-bounds the masked diffusion training objective and serves as a lightweight uncertainty score for large language diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
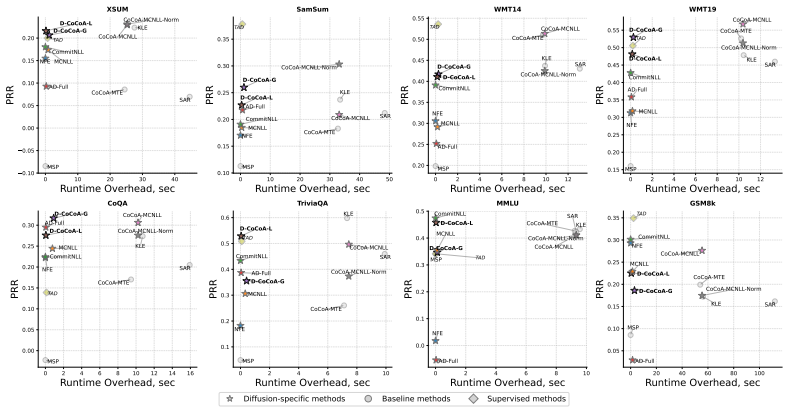
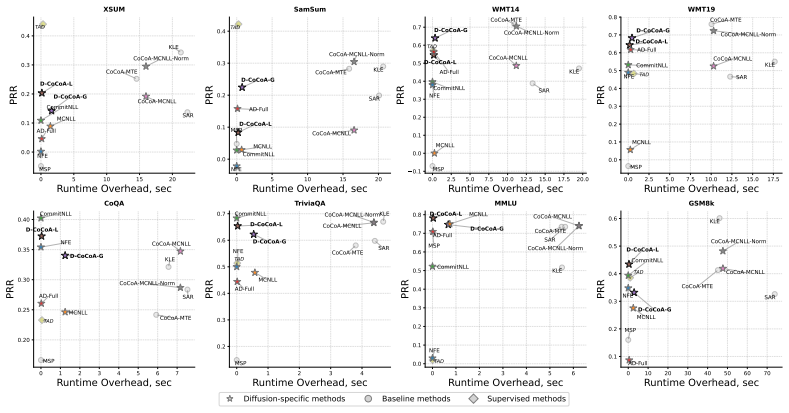
We prove that expected trajectory dissimilarity lower bounds the masked diffusion training objective, which motivates its usage as an uncertainty score. By combining masked diffusion likelihoods with trajectory-based semantic dissimilarity we obtain lightweight zero-shot signals from intermediate generations, token remasking dynamics, and denoising complexity that achieve strong cost-performance trade-offs on multiple tasks and models.
What carries the argument
Expected trajectory dissimilarity along the denoising path, which lower-bounds the masked diffusion training objective and functions as a zero-shot uncertainty score when combined with diffusion likelihoods.
If this is right
- Uncertainty scores become available in a single denoising pass rather than multiple independent generations.
- Hallucination detection approaches the performance of sampling-based methods at up to 100x lower compute.
- Large language diffusion models can be deployed with both faster inference and built-in reliability checks.
- The same trajectory signals apply across generation, classification, and other sequence tasks.
Where Pith is reading between the lines
- The lower-bound relation might allow uncertainty signals to be folded back into the training objective itself for more robust models.
- Similar trajectory-based measures could be tested on image or audio diffusion models to check for broader applicability.
- If the correlation holds, these scores could be used to trigger selective abstention or human review in real-time applications.
Load-bearing premise
Signals extracted from the denoising trajectory correlate with actual hallucination risk on the tasks and models tested.
What would settle it
A dataset or model where expected trajectory dissimilarity shows near-zero correlation with human-judged hallucination rates while sampling-based baselines remain predictive would falsify the claim.
Figures





read the original abstract
Large Language Diffusion Models (LLDMs) are emerging as an alternative to autoregressive models, offering faster inference through higher parallelism. Similar to autoregressive LLMs, they remain prone to hallucinations, making reliable uncertainty quantification (UQ) crucial for safe deployment. However, existing UQ methods are fundamentally misaligned with this new paradigm: they assume autoregressive factorization or use expensive repeated sampling, negating the efficiency of LLDMs. In this work, we present the first systematic study of UQ for LLDMs and propose lightweight, zero-shot uncertainty signals derived from the iterative denoising process, leveraging intermediate generations, token remasking dynamics, and denoising complexity. We further adapt a state-of-the-art UQ method to LLDMs by combining masked diffusion likelihoods with trajectory-based semantic dissimilarity. We prove that expected trajectory dissimilarity lower bounds the masked diffusion training objective, which motivates its usage as an uncertainty score. Comprehensive experiments across three tasks, eight datasets, and two models show that our method achieves a great cost-performance trade-off: it approaches the strongest sampling-based baselines while incurring up to 100x lower computational overhead. Our work demonstrates that LLDMs can deliver both fast inference and reliable hallucination detection simultaneously.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first systematic study of uncertainty quantification (UQ) for Large Language Diffusion Models (LLDMs). It proposes lightweight zero-shot signals derived from the iterative denoising process (intermediate generations, token remasking dynamics, and denoising complexity), adapts a state-of-the-art UQ method by combining masked diffusion likelihoods with trajectory-based semantic dissimilarity, and proves that expected trajectory dissimilarity lower-bounds the masked diffusion training objective. Experiments across three tasks, eight datasets, and two models demonstrate that the proposed methods achieve competitive hallucination detection performance relative to sampling-based baselines while incurring up to 100x lower computational overhead.
Significance. If the central theoretical link and empirical results hold, the work is significant because it aligns UQ methods with the parallel inference advantages of LLDMs rather than forcing autoregressive assumptions or expensive sampling. The proof supplies an independent mathematical grounding for the dissimilarity score, and the scale of the evaluation (eight datasets, multiple tasks and models) provides a reproducible basis for the claimed cost-performance trade-off.
major comments (1)
- [§4] §4 (theoretical motivation and proof): The inequality showing that expected trajectory dissimilarity lower-bounds the masked diffusion objective is mathematically independent, yet the manuscript does not demonstrate via ablation that the dissimilarity term supplies predictive power for hallucination risk beyond the scalar denoising loss alone. Because the training objective quantifies expected denoising error under the forward process, an additional assumption is required that trajectory dissimilarity reliably tracks semantic hallucination rather than low-loss but factually incorrect outputs; this assumption is load-bearing for the UQ claim but is not directly tested.
minor comments (2)
- [Experiments] Experiments section: error bars, confidence intervals, and explicit data-exclusion criteria for the eight datasets are not reported, which limits verification of the claimed performance margins.
- [Notation] Notation: the precise definition of 'trajectory dissimilarity' (e.g., the distance metric over intermediate generations) should be given its own numbered equation for clarity when referenced in the proof and experiments.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential significance of our work on uncertainty quantification for Large Language Diffusion Models. We address the major comment below and plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (theoretical motivation and proof): The inequality showing that expected trajectory dissimilarity lower-bounds the masked diffusion objective is mathematically independent, yet the manuscript does not demonstrate via ablation that the dissimilarity term supplies predictive power for hallucination risk beyond the scalar denoising loss alone. Because the training objective quantifies expected denoising error under the forward process, an additional assumption is required that trajectory dissimilarity reliably tracks semantic hallucination rather than low-loss but factually incorrect outputs; this assumption is load-bearing for the UQ claim but is not directly tested.
Authors: We thank the referee for highlighting this important point. The proof establishes that the expected trajectory dissimilarity lower-bounds the masked diffusion training objective, providing theoretical motivation for using dissimilarity as part of the uncertainty signal. However, we acknowledge that the current manuscript does not include an explicit ablation study isolating the contribution of the dissimilarity term beyond the scalar denoising loss. Our experiments demonstrate the effectiveness of the combined approach (likelihoods + dissimilarity) in achieving near sampling-based performance at much lower cost, but a direct comparison to denoising loss alone is indeed missing. In the revised manuscript, we will add such an ablation across the eight datasets to quantify the additional predictive power. Regarding the assumption that dissimilarity tracks semantic hallucination, the empirical results on hallucination detection tasks support this, as the method outperforms or matches baselines. We will also add a discussion on potential limitations, including cases where low-loss but incorrect outputs might occur, to address this concern. revision: yes
Circularity Check
No circularity: mathematical bound provides independent grounding for uncertainty score
full rationale
The paper's central derivation is a proof that expected trajectory dissimilarity lower-bounds the masked diffusion training objective. This is presented as a direct mathematical result motivating the uncertainty score, without reducing to fitted parameters, self-definitional loops, or load-bearing self-citations. Experiments across tasks and datasets provide separate empirical validation. No steps in the provided abstract or claims exhibit the enumerated circular patterns; the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLDMs follow an iterative masked diffusion denoising process whose intermediate states can be observed and compared
Reference graph
Works this paper leans on
-
[1]
Association for Computational Linguistics. K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. J. Duan, H. Cheng, S. Wang, A. Zavalny, C. Wang, R. Xu, B. Kailkhura, and K. Xu. Shifting atten- tion...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Y es] Justification: Y es, the claims made in the abstract and introduction are precisely supported by the description of the method in Section 3 and by the experimental evaluations in Sec- tion 4. Guidelines: • The answ...
-
[3]
Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer: [Y es] Justification: Y es, the limitations of the work are discussed in Appendix E. Guidelines: • The answer [N/A] means that the paper has no limitation while the answer [No] means that the paper has limitations, but those are not discussed in the p...
-
[4]
Guidelines: • The answer [N/A] means that the paper does not include theoretical results
Theory assumptions and proofs Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof? 27 Answer: [Y es] Justification: Y es, the paper provides theoretical results in Theorem 1, with the full set of assumptions in Section 3.3 and complete proof in Appendix A. Guidelines: • The answer [N/...
-
[5]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experimental result reproducibility Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclu- sions of the paper (regardless of whether the code and data are provided or not)? Answer: [Y es] Justification: All necessary details for ...
-
[6]
Guidelines: • The answer [N/A] means that paper does not include experiments requiring code
Open access to data and code Question: Does the paper provide open access to the data and code, with sufficient instruc- tions to faithfully reproduce the main experimental results, as described in supplemental material? Answer: [Y es] Justification: The implementation code will be anonymously included in the supplementary materials to ensure transparency a...
-
[7]
No model training is performed in this work
Experimental setting/details Question: Does the paper specify all the training and test details (e.g., data splits, hyperpa- rameters, how they were chosen, type of optimizer) necessary to understand the results? Answer: [Y es] Justification: All relevant details of the testing experiments are provided in Section 4 and Appendix D. No model training is perf...
-
[8]
Experiment statistical significance Question: Does the paper report error bars suitably and correctly defined or other appropri- ate information about the statistical significance of the experiments? Answer: [Y es] Justification: Reliability of the results is ensured by fixing random seeds and using greedy decoding, which leads to deterministic generation. To ...
-
[9]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experiments compute resources Question: For each experiment, does the paper provide sufficient information on the com- puter resources (type of compute workers, memory, time of execution) needed to reproduce the experiments? Answer: [Y es] Justification: Details about resources and implementation are provided in Appendix D.1. Guidelines: • The answer [N/A] ...
-
[10]
Guidelines: • The answer [N/A] means that the authors have not reviewed the NeurIPS Code of Ethics
Code of ethics Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines? Answer: [Y es] Justification: Y es, the research conducted in this paper conforms in every respect with the NeurIPS Code of Ethics. Guidelines: • The answer [N/A] means that the authors hav...
-
[11]
30 Guidelines: • The answer [N/A] means that there is no societal impact of the work performed
Broader impacts Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed? Answer: [Y es] Justification: The broader impact of our work is discussed in Appendix F. 30 Guidelines: • The answer [N/A] means that there is no societal impact of the work performed. • If the authors answer [N/A] ...
-
[12]
No new models or datasets are released as part of this work
Safeguards Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pre-trained language models, image generators, or scraped datasets)? Answer: [Y es] Justification: Our work focuses on hallucination detection in LLMs, which does not intro- duce new safety ri...
-
[13]
Guidelines: • The answer [N/A] means that the paper does not use existing assets
Licenses for existing assets Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected? Answer: [Y es] Justification: Y es, we appropriately credit the authors and licenses for all models, methods, and datasets uti...
-
[14]
Guidelines: • The answer [N/A] means that the paper does not release new assets
New assets Question: Are new assets introduced in the paper well documented and is the documenta- tion provided alongside the assets? Answer: [N/A] Justification: The paper does not release new datasets or models. Guidelines: • The answer [N/A] means that the paper does not release new assets. • Researchers should communicate the details of the dataset/cod...
-
[15]
Crowdsourcing and research with human subjects Question: For crowdsourcing experiments and research with human subjects, does the pa- per include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)? Answer: [N/A] Justification: This work does not involve crowdsourcing or researc...
-
[16]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[17]
Declaration of LLM usage Question: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Note that if the LLM is used only for writing, editing, or formatting purposes and does not impact the core methodology, scientific rigor, or originality of the research, declaration i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.