Recognition: 2 theorem links
· Lean TheoremMed-DisSeg: Dispersion-Driven Representation Learning for Fine-Grained Medical Image Segmentation
Pith reviewed 2026-05-15 01:45 UTC · model grok-4.3
The pith
A dispersive loss treating batch representations as negatives produces boundary-aware embeddings that improve fine-grained medical image segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Med-DisSeg combines a dispersive loss with adaptive attention to jointly improve representation learning and anatomical delineation. The dispersive loss enlarges inter-sample margins by treating in-batch hidden representations as negative pairs, yielding well-dispersed and boundary-aware embeddings. The encoder then strengthens structure-sensitive responses while the decoder performs adaptive multi-scale calibration to preserve complementary local and global cues, leading to state-of-the-art results on heterogeneous medical images.
What carries the argument
The Dispersive Loss, which enlarges inter-sample margins by treating in-batch hidden representations as negative pairs to produce dispersed boundary-aware embeddings.
If this is right
- The encoder produces stronger structure-sensitive activations around target anatomy.
- The decoder preserves both fine local texture and global shape information through adaptive calibration.
- The approach yields consistent state-of-the-art segmentation accuracy across five datasets in three imaging modalities.
- It remains competitive on multi-organ CT segmentation without task-specific redesign.
Where Pith is reading between the lines
- The same batch-wise dispersion mechanism could be tested on non-medical dense prediction tasks such as natural scene segmentation to check if the boundary benefit generalizes beyond anatomy.
- If the gain depends on batch size, practitioners might need larger batches or memory-bank alternatives when GPU memory is limited.
- The negligible overhead suggests the loss could be added as a plug-in to existing medical segmentation pipelines without retraining from scratch.
Load-bearing premise
Treating in-batch representations as negative pairs will enlarge margins in a way that improves anatomical boundary delineation rather than merely increasing feature variance without semantic benefit.
What would settle it
Run the model on a held-out medical segmentation dataset where adding the dispersive loss measurably increases feature variance and inter-sample distances yet leaves boundary precision (measured by Hausdorff distance or surface Dice) unchanged or worse compared to the baseline without the loss.
Figures






read the original abstract
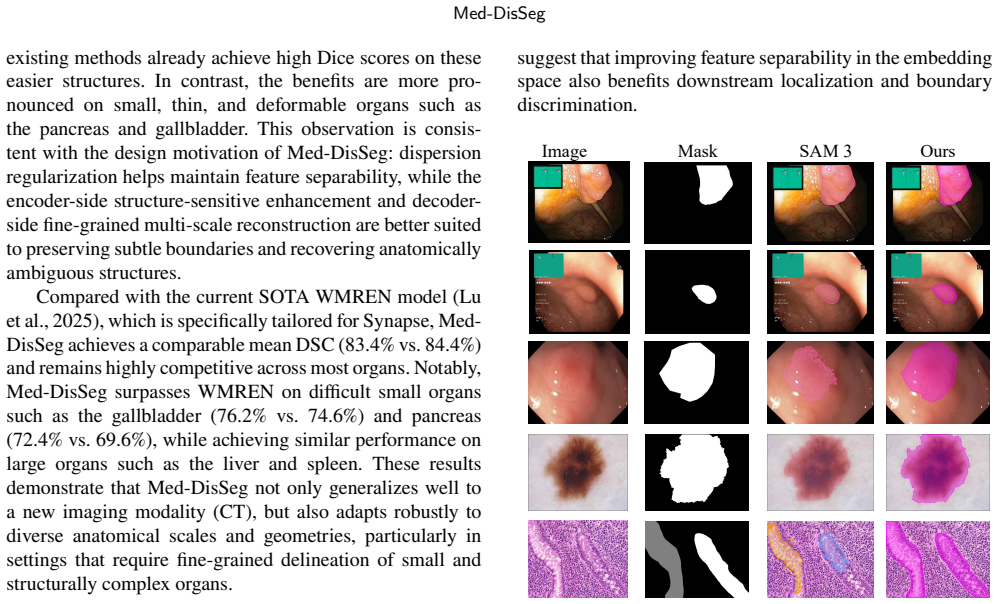
Accurate medical image segmentation is fundamental to precision medicine, yet robust delineation remains challenging under heterogeneous appearances, ambiguous boundaries, and large anatomical variability. Similar intensity and texture patterns between targets and surrounding tissues often lead to blurred activations and unreliable separation. We attribute these failures to representation collapse during encoding and insufficient fine grained multi scale decoding. To address these issues, we propose Med DisSeg, a dispersion driven medical image segmentation framework that jointly improves representation learning and anatomical delineation. Med DisSeg combines a lightweight Dispersive Loss with adaptive attention for fine grained structure segmentation. The Dispersive Loss enlarges inter sample margins by treating in batch hidden representations as negative pairs, producing well dispersed and boundary aware embeddings with negligible overhead. Based on these enhanced representations, the encoder strengthens structure sensitive responses, while the decoder performs adaptive multi scale calibration to preserve complementary local texture and global shape information. Extensive experiments on five datasets spanning three imaging modalities demonstrate consistent state of the art performance. Moreover, Med DisSeg achieves competitive results on multi organ CT segmentation, supporting its robustness and cross task applicability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Med-DisSeg, a dispersion-driven framework for fine-grained medical image segmentation. It introduces a lightweight Dispersive Loss that treats in-batch hidden representations as negative pairs to enlarge inter-sample margins and yield well-dispersed, boundary-aware embeddings. This is paired with adaptive attention in the decoder for multi-scale calibration to mitigate representation collapse and ambiguous boundaries. The method reports consistent state-of-the-art results on five datasets across three modalities plus competitive multi-organ CT performance.
Significance. If validated, the work would supply a low-overhead mechanism for improving representation quality in medical segmentation under heterogeneous appearances and anatomical variability. The negligible computational cost and cross-modality applicability would be practical strengths for precision-medicine pipelines.
major comments (2)
- [Abstract] Abstract: the central claim that treating in-batch hidden representations as negative pairs produces 'boundary aware embeddings' lacks any stated mechanism or positive-pair construction showing how inter-sample repulsion sharpens intra-image anatomical boundaries rather than merely increasing feature variance. Medical images frequently contain similar anatomies across batches, so this link is load-bearing and requires explicit derivation or ablation.
- [Experiments] Experimental section (implied by abstract claims): no ablation tables, error bars, or controlled comparisons isolating the Dispersive Loss from other design choices are referenced, making it impossible to confirm that reported SOTA gains are attributable to dispersion rather than unstated components.
minor comments (1)
- [Abstract] Abstract: the five datasets and three modalities are not named, which would improve immediate readability.
Simulated Author's Rebuttal
We sincerely thank the referee for the constructive and insightful comments. We address each major point below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that treating in-batch hidden representations as negative pairs produces 'boundary aware embeddings' lacks any stated mechanism or positive-pair construction showing how inter-sample repulsion sharpens intra-image anatomical boundaries rather than merely increasing feature variance. Medical images frequently contain similar anatomies across batches, so this link is load-bearing and requires explicit derivation or ablation.
Authors: We thank the referee for this important observation. The Dispersive Loss is formulated in Section 3.2 as a repulsion objective on normalized in-batch representations (L_disp = sum_{i≠j} ||h_i - h_j||^2 / (||h_i|| ||h_j||)), which enlarges inter-sample margins without explicit positives. This dispersion mitigates representation collapse and encourages the encoder to capture finer intra-image variations, including at boundaries, because gradients push similar anatomical patterns apart. To strengthen the manuscript, we will add an explicit derivation in the revised Section 3.2 showing the gradient flow to boundary regions and discuss why negative-only pairs are sufficient here. We will also include a targeted ablation on alternative positive-pair constructions. revision: yes
-
Referee: [Experiments] Experimental section (implied by abstract claims): no ablation tables, error bars, or controlled comparisons isolating the Dispersive Loss from other design choices are referenced, making it impossible to confirm that reported SOTA gains are attributable to dispersion rather than unstated components.
Authors: We agree that explicit isolation of the Dispersive Loss is essential for attributing gains. The manuscript already contains ablation studies in Section 4.3 comparing the full model to variants without the loss, showing consistent drops in Dice and boundary metrics. To address the concern fully, the revised version will expand these with error bars from three independent runs, add a controlled table isolating the loss from the adaptive decoder, and include incremental component analysis to confirm the dispersion contribution to the reported SOTA results. revision: yes
Circularity Check
No circularity; dispersive loss defined directly with external benchmark validation
full rationale
The paper introduces the Dispersive Loss by explicit construction: it enlarges inter-sample margins through in-batch negative pairs on hidden representations. This definition is not derived from the target outcome (boundary awareness) but is instead a design choice whose effects are then measured on five independent external datasets spanning multiple modalities. No equations, fitted parameters, or self-citations are shown that would make the central performance claims equivalent to the loss definition by construction. The derivation therefore remains self-contained against external benchmarks rather than reducing to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption In-batch hidden representations can be treated as negative pairs to enlarge inter-sample margins without collapsing semantic content.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dispersive Loss ... log E_{i≠j}[exp(−D(z_i,z_j)/τ)] (Eq. 2); variants InfoNCE-L2, InfoNCE-Cos, Hinge, Covariance off-diagonal (Eqs. 3–6)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dispersive Loss enlarges inter-sample margins ... boundary-aware embeddings
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Transunet: Transformers make strong encoders for medical image segmentation. arXiv preprint arXiv:2102.04306 . Chen,T.,Kornblith,S.,Norouzi,M.,Hinton,G.,2020.Asimpleframework for contrastive learning of visual representations, in: Proceedings of theInternationalConferenceonMachineLearning(ICML),PMLR.pp. 1597–1607. Chen, Y., Chen, F., Huang, C.,
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
CAS- TLE: Cluster-Aided Space Transformation for Local Explanations
Combining contrastive learning and shape awareness for semi-supervised medical image segmentation. Expert Systems with Applications 242, 122567. doi:10.1016/j.eswa. 2023.122567. Codella, N., et al.,
-
[3]
Skin lesion analysis toward melanoma detection 2018:Achallengehostedbytheinternationalskinimagingcollaboration (isic). arXiv preprint arXiv:1902.03368 . Fan, D.P., et al.,
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Cpfnet: Context pyramid and feature fusion network for medical image segmentation. Neurocomputing 376, 222–235. Gu,Z.,etal.,2019. Ce-net:Contextencodernetworkfor2dmedicalimage segmentation. IEEE Transactions on Medical Imaging 38, 2281–2292. Guo, Y., et al.,
work page 2019
-
[5]
Skin lesion analysis toward melanoma detection: A challenge at the isic 2016, in: IEEE International Symposium on Biomedical Imaging (ISBI) Challenge, pp. 1–10. Hatamizadeh, A., Tang, Y., Nath, V., Yang, D., Myronenko, A., Landman, B.,Roth,H.R.,Xu,D.,2022. Unetr:Transformersfor3dmedicalimage segmentation, in: Proceedings of the IEEE/CVF Winter Conference ...
work page 2016
-
[6]
Squeeze-and-excitation networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7132–7141. Isensee,F.,Jaeger,P.F.,Kohl,S.A.A.,Petersen,J.,Maier-Hein,K.H.,2021. nnu-net: A self-configuring method for deep learning-based biomedical image segmentation. Nature Methods 18, 203–211. :Preprint submitted to Elsevier ...
work page 2021
-
[7]
Knowledge-Based Systems 178, 149–162
Dunet: A deformable network for retinal vessel segmentation. Knowledge-Based Systems 178, 149–162. URL:https://www.sciencedirect.com/science/ article/pii/S0950705119301984, doi:10.1016/j.knosys.2019.04.025. Kingma, D.P., Ba, J.,
-
[8]
arXiv preprint arXiv:2511.16719 URL:https://arxiv.org/abs/2511.16719. Lei,M.,Wu,H.,Lv,X.,Wang,X.,2025.Condseg:Ageneralmedicalimage segmentation framework via contrast-driven feature enhancement, in: ProceedingsoftheAAAIConferenceonArtificialIntelligence,Chicago. pp. 4571–4579. Li,X.,Ma,S.,Xu,J.,Tang,J.,He,S.,Guo,F.,2024.Transiam:Aggregating multi-modal vi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1016/j 2025
-
[9]
Expert Systems with Applications 238, 121754
Cafe-net: Cross-attention and feature exploration network for polyp segmentation. Expert Systems with Applications 238, 121754. doi:10. 1016/j.eswa.2023.121754. Liu,Y.,Wang,H.,Chen,Z.,Huangliang,K.,Zhang,H.,2022. Transunet+: Redesigning the skip connection to enhance features in medical image segmentation. Knowledge-Based Systems 256, 109859. URL:https://...
-
[10]
Wavelet multi-scale region-enhanced network for medical image segmentation, in: Proceedings of IJCAI 2025, pp. 1–10. Ma, C., Wang, Z.,
work page 2025
-
[11]
Knowledge-Based Systems 300, 112203
Semi-mamba-unet: Pixel-level contrastive and cross-supervised visual mamba-based unet for semi-supervised medical image segmentation. Knowledge-Based Systems 300, 112203. URL:https://www.sciencedirect.com/science/article/pii/ S0950705124008372, doi:10.1016/j.knosys.2024.112203. Malekmohammadi,A.,Soryani,M.,Kozegar,E.,2024. Masssegmentation inautomatedbrea...
-
[12]
Attention U-Net: Learning Where to Look for the Pancreas
Attentionu-net:Learningwheretolookforthepancreas. arXivpreprint arXiv:1804.03999 . Park, M., et al.,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Emcad: Efficient multi- scaleconvolutionalattentiondecodingformedicalimagesegmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1–10. Ronneberger,O.,Fischer,P.,Brox,T.,2015. U-net:Convolutionalnetworks for biomedical image segmentation, in: International Conference on Medical Image Computing and Co...
work page 2015
-
[14]
Knowledge-Based Systems 283, 111127
Mln-net: A multi-source medical image segmentation method for clustered mi- crocalcifications using multiple layer normalization. Knowledge-Based Systems 283, 111127. URL:https://www.sciencedirect.com/science/ article/pii/S0950705123008778, doi:10.1016/j.knosys.2023.111127. Wang, R., He, K.,
-
[15]
Diffuse and disperse: Image generation with representation regularization. arXiv preprint arXiv:2506.09027 . Wang,R.,etal.,2022. Boundary-awarecontextneuralnetworkformedical image segmentation. Medical Image Analysis 78, 102395. Woo, S., Park, J., Lee, J.Y., Kweon, I.S.,
-
[16]
Voco: A simple-yet-effective volume contrastive learning framework for 3d medical image analysis, in: Pro- ceedingsoftheIEEE/CVFConferenceonComputerVisionandPattern Recognition (CVPR), pp. 1–10. Wu,X.,Li,Z.,etal.,2022. Fat-net:Feature-adaptivetransformersforpolyp segmentation. Computers in Biology and Medicine 146, 105676. Xu, L., et al.,
work page 2022
-
[17]
Dcsau-net: Dual-channel and spatial attentionu-netformedicalimagesegmentation. IEEEAccess11,1–12. Yu,Z.,etal.,2023. Eiu-net:Enhancedfeatureextractionandimprovedskip connectionsinu-netforskinlesionsegmentation. ComputersinBiology and Medicine 162, 107081. Zhang, H., et al.,
work page 2023
-
[18]
Unet++: Anestedu-netarchitectureformedicalimagesegmentation,in:Interna- tionalWorkshoponDeepLearninginMedicalImageAnalysis,Springer. pp. 3–11. Zhu,W.,etal.,2024. Selfreg-unet:Self-regularizedunetformedicalimage segmentation, in: Medical Image Computing and Computer-Assisted Intervention (MICCAI), Springer. pp. 1–10. :Preprint submitted to Elsevier Page 14...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.