Recognition: 2 theorem links
· Lean TheoremCalibAnyView: Beyond Single-View Camera Calibration in the Wild
Pith reviewed 2026-05-15 05:56 UTC · model grok-4.3
The pith
CalibAnyView enables camera calibration from any number of views in the wild by enforcing cross-view geometric consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CalibAnyView is a unified formulation supporting an arbitrary number of input views by explicitly modeling cross-view geometric consistency, constructed via a large-scale multi-view video dataset and a multi-view transformer that predicts dense perspective fields integrated into geometric optimization to estimate camera intrinsics and gravity direction.
What carries the argument
The multi-view transformer predicting dense perspective fields, combined with a geometric optimization framework for joint intrinsics and gravity estimation.
If this is right
- Outperforms state-of-the-art single-view calibration methods even in single-view mode.
- Performance improves further when multiple views are provided.
- Supports reliable 3D reconstruction and robotic perception from in-the-wild imagery.
- Works robustly across diverse camera models and lens distortions.
Where Pith is reading between the lines
- Could be integrated into video-based SLAM systems for continuous calibration.
- May enable calibration from casual phone videos without special setups.
- Opens the door to learning-based calibration for other sensors like depth cameras if similar datasets are built.
Load-bearing premise
The constructed large-scale multi-view video dataset covers sufficient diversity of real-world camera models, dynamic scenes, motion trajectories, and lens distortions to allow generalization to new inputs.
What would settle it
Evaluating the model on a held-out test set featuring camera models or distortion patterns entirely absent from the training dataset and measuring if intrinsic estimates remain accurate.
Figures

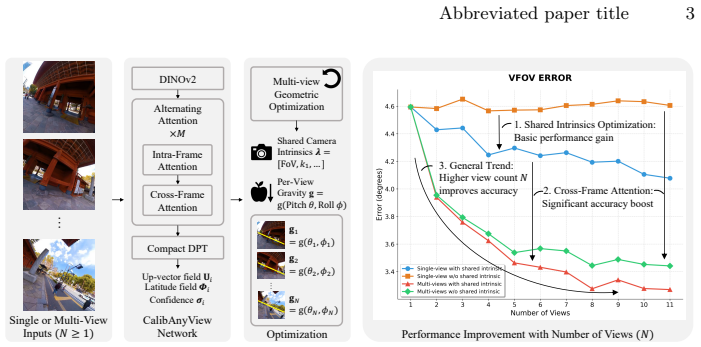
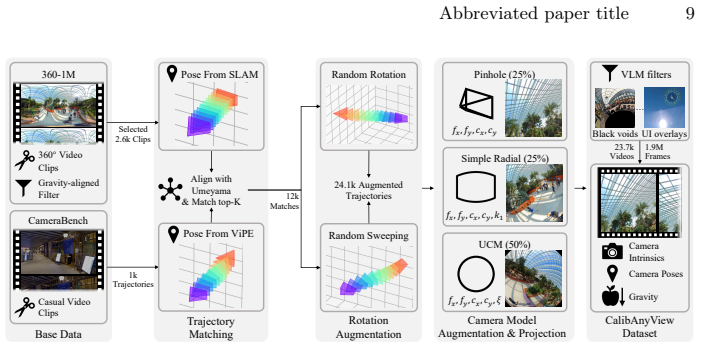
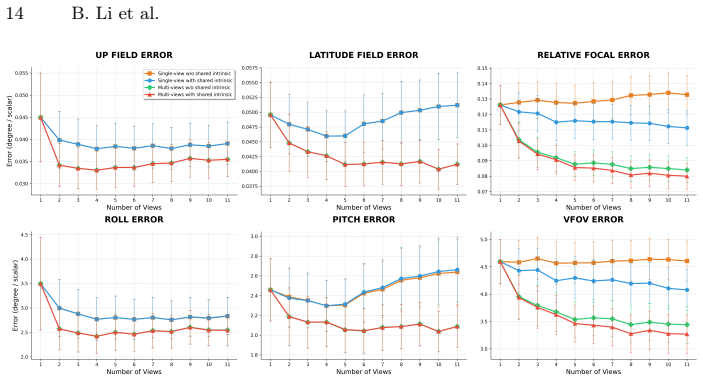





















read the original abstract
Camera calibration is a fundamental prerequisite for reliable geometric perception, yet classical approaches rely on controlled acquisition setups that are impractical for in-the-wild imagery. Recent learning-based methods have shown promising results for single-view calibration, but inherently neglect geometric consistency across multiple views. We introduce CalibAnyView, a unified formulation that supports an arbitrary number of input views ($N \geq 1$) by explicitly modeling cross-view geometric consistency. To facilitate this, we construct a large-scale multi-view video dataset covering diverse real-world scenarios, including multiple camera models, dynamic scenes, realistic motion trajectories, and heterogeneous lens distortions. Building on this dataset, we develop a multi-view transformer that predicts dense perspective fields, which are further integrated into a geometric optimization framework to jointly estimate camera intrinsics and gravity direction. Extensive experiments demonstrate that CalibAnyView consistently outperforms state-of-the-art methods, achieves strong robustness under single-view settings, and further improves with multi-view inference, providing a reliable foundation for downstream tasks such as 3D reconstruction and robotic perception in the wild.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CalibAnyView, a unified formulation for camera calibration supporting an arbitrary number of input views (N ≥ 1). It constructs a large-scale multi-view video dataset covering diverse camera models, dynamic scenes, motion trajectories, and lens distortions; trains a multi-view transformer to predict dense perspective fields; and integrates these into a geometric optimization framework to jointly recover intrinsics and gravity direction. The central claim is that the method consistently outperforms prior single-view state-of-the-art approaches, remains robust in single-view settings, and yields further gains under multi-view inference.
Significance. If the quantitative claims hold, the work is significant because it extends learning-based single-view calibration to enforce explicit cross-view geometric consistency without requiring controlled capture setups. The new dataset and the perspective-field-plus-optimization pipeline could serve as a practical foundation for downstream tasks such as 3D reconstruction and robotic perception in unconstrained environments.
major comments (3)
- [Dataset Construction] Dataset section: the assertion that the constructed multi-view video dataset sufficiently covers real-world diversity (camera models, lens distortions, trajectories) is load-bearing for the generalization claim, yet no statistical comparison (histograms, divergence metrics, or coverage statistics) is provided against independent corpora such as KITTI, nuScenes, or existing calibration benchmarks.
- [Experiments] Experiments section: the abstract states that CalibAnyView 'consistently outperforms state-of-the-art methods' and 'further improves with multi-view inference,' but the manuscript supplies no numerical tables, baseline implementations, ablation results on view count, or error metrics (e.g., focal-length error, distortion coefficient error, gravity angular error). Without these, the central performance claim cannot be verified.
- [Method] Geometric optimization: the integration step that converts predicted perspective fields into joint intrinsics and gravity estimates is described at a high level; the precise objective function, handling of N > 2 views, and any weighting between single-view and cross-view terms are not specified, making it impossible to assess whether reported multi-view gains arise from genuine consistency enforcement or from simple averaging.
minor comments (2)
- [Abstract] Abstract: reporting 'consistent outperformance' without any numerical values is atypical and reduces immediate readability; a single sentence summarizing key error reductions would help.
- [Method] Notation: the term 'perspective fields' is introduced without an early formal definition or diagram; a short equation or figure in §3 would clarify the representation before the transformer architecture is described.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and will revise the manuscript to improve clarity, completeness, and verifiability of the claims.
read point-by-point responses
-
Referee: [Dataset Construction] Dataset section: the assertion that the constructed multi-view video dataset sufficiently covers real-world diversity (camera models, lens distortions, trajectories) is load-bearing for the generalization claim, yet no statistical comparison (histograms, divergence metrics, or coverage statistics) is provided against independent corpora such as KITTI, nuScenes, or existing calibration benchmarks.
Authors: We agree that quantitative coverage analysis would strengthen the generalization argument. In the revised manuscript we will add histograms of focal lengths, distortion coefficients, scene dynamics, and motion trajectories, along with divergence metrics (e.g., KL divergence or Wasserstein distance) comparing our dataset against KITTI, nuScenes, and standard calibration benchmarks. revision: yes
-
Referee: [Experiments] Experiments section: the abstract states that CalibAnyView 'consistently outperforms state-of-the-art methods' and 'further improves with multi-view inference,' but the manuscript supplies no numerical tables, baseline implementations, ablation results on view count, or error metrics (e.g., focal-length error, distortion coefficient error, gravity angular error). Without these, the central performance claim cannot be verified.
Authors: We will expand the experiments section to include complete numerical tables with all requested error metrics (focal-length error, distortion coefficients, gravity angular error), explicit baseline implementations, and ablation studies that vary the number of input views (N=1 to N=8). These additions will make the performance claims directly verifiable. revision: yes
-
Referee: [Method] Geometric optimization: the integration step that converts predicted perspective fields into joint intrinsics and gravity estimates is described at a high level; the precise objective function, handling of N > 2 views, and any weighting between single-view and cross-view terms are not specified, making it impossible to assess whether reported multi-view gains arise from genuine consistency enforcement or from simple averaging.
Authors: We will provide the exact objective function (including the formulation for arbitrary N>2), the weighting coefficients between single-view and cross-view terms, and a clear description of how perspective-field residuals are aggregated across views. This will demonstrate that the reported gains result from explicit geometric consistency rather than averaging. revision: yes
Circularity Check
No significant circularity: standard supervised pipeline with independent geometric optimization
full rationale
The paper constructs a multi-view video dataset, trains a transformer to predict dense perspective fields from it, and feeds those predictions into a separate geometric optimization step that enforces cross-view consistency to recover intrinsics and gravity. This chain follows conventional supervised learning plus post-hoc optimization; the optimization equations operate on the model's outputs rather than re-fitting parameters from the same training data, and no load-bearing self-citation or self-definitional loop reduces the claimed predictions to the inputs by construction. Dataset creation and model training introduce ordinary distribution dependence but do not create the circular reductions enumerated in the analysis criteria.
Axiom & Free-Parameter Ledger
free parameters (1)
- Transformer hyperparameters and training schedule
axioms (1)
- domain assumption Perspective fields can encode sufficient cross-view geometric consistency for joint intrinsics and gravity estimation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
predicts dense perspective fields (up-vector and latitude) ... integrated into a geometric optimization framework to jointly estimate camera intrinsics and gravity direction
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified formulation that supports an arbitrary number of input views (N ≥ 1) by explicitly modeling cross-view geometric consistency
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Communications of the ACM54(10), 105–112 (2011)
Agarwal, S., Furukawa, Y., Snavely, N., Simon, I., Curless, B., Seitz, S.M., Szeliski, R.: Building rome in a day. Communications of the ACM54(10), 105–112 (2011)
work page 2011
-
[2]
Joint 2D-3D-Semantic Data for Indoor Scene Understanding
Armeni, I., Sax, S., Zamir, A.R., Savarese, S.: Joint 2D-3D-Semantic Data for Indoor Scene Understanding. arXiv:1702.01105 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Bao, S.Y., Savarese, S.: Semantic structure from motion. In: CVPR 2011. pp. 2025–
work page 2011
- [5]
-
[6]
Caprile, B., Torre, V.: Using vanishing points for camera calibration. IJCV4(2), 127–139 (1990)
work page 1990
-
[7]
In: IEEE International Conference on Robotics and Automation
Carrera, G., Angeli, A., Davison, A.J.: Slam-based automatic extrinsic calibra- tion of a multi-camera rig. In: IEEE International Conference on Robotics and Automation. pp. 2652–2659. IEEE (2011)
work page 2011
- [8]
-
[9]
In: IEEE International Conference on Robotics and Automation
Civera, J., Bueno, D.R., Davison, A.J., Montiel, J.M.M.: Camera self-calibration for sequential bayesian structure from motion. In: IEEE International Conference on Robotics and Automation. pp. 403–408. IEEE (2009)
work page 2009
-
[10]
Coughlan, J.M., Yuille, A.L.: Manhattan World: Compass Direction from a Bayesian Inference. In: ICCV (1999)
work page 1999
-
[11]
Engel, J., Koltun, V., Cremers, D.: Direct sparse odometry40(3), 611–625 (2017)
work page 2017
- [12]
-
[13]
GimbalDiffusion: Gravity-Aware Camera Control for Video Generation
Fortier-Chouinard, F., Hold-Geoffroy, Y., Deschaintre, V., Gadelha, M., Lalonde, J.F.: Gimbaldiffusion: Gravity-aware camera control for video generation. arXiv preprint arXiv:2512.09112 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
- [15]
-
[16]
In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision
Hagemann, A., Knorr, M., Stiller, C.: Deep geometry-aware camera self-calibration from video. In: Proceedings of the IEEE/CVF International Conference on Com- puter Vision. pp. 3438–3448 (2023)
work page 2023
-
[17]
Autonomous robots39(3), 259–277 (2015)
Heng, L., Lee, G.H., Pollefeys, M.: Self-calibration and visual slam with a multi- camera system on a micro aerial vehicle. Autonomous robots39(3), 259–277 (2015)
work page 2015
-
[18]
Hold-Geoffroy, Y., Piché-Meunier, D., Sunkavalli, K., Bazin, J.C., Rameau, F., Lalonde, J.F.: A Deep Perceptual Measure for Lens and Camera Calibration. IEEE TPAMI (2022)
work page 2022
- [19]
-
[20]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Huang, H., Liu, C., Zhu, Y., Cheng, H., Braud, T., Yeung, S.K.: 360loc: A dataset and benchmark for omnidirectional visual localization with cross-device queries. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 22314–22324 (2024)
work page 2024
-
[21]
Vipe: Video pose engine for 3d geometric perception.arXiv preprint arXiv:2508.10934, 2025
Huang, J., Zhou, Q., Rabeti, H., Korovko, A., Ling, H., Ren, X., Shen, T., Gao, J., Slepichev,D.,Lin,C.H.,etal.:Vipe:Videoposeenginefor3dgeometricperception. arXiv preprint arXiv:2508.10934 (2025)
-
[22]
Jeong, Y., Ahn, S., Choy, C., Anandkumar, A., Cho, M., Park, J.: Self-calibrating neural radiance fields. In: ICCV (2021)
work page 2021
- [23]
-
[24]
Kendall, A., Gal, Y.: What uncertainties do we need in bayesian deep learning for computer vision? NeurIPS30(2017)
work page 2017
-
[25]
Kluger, F., Brachmann, E., Ackermann, H., Rother, C., Yang, M.Y., Rosenhahn, B.: CONSAC: Robust Multi-Model Fitting by Conditional Sample Consensus. In: CVPR (2020)
work page 2020
- [26]
-
[27]
Lee, J., Go, H., Lee, H., Cho, S., Sung, M., Kim, J.: Ctrl-c: Camera calibration transformer with line-classification. In: ICCV (2021)
work page 2021
- [28]
-
[29]
arXiv preprint arXiv:2510.23589 (2025)
Liang, E., Bhattacharjee, R., Dey, S., Moschopoulos, R., Wang, C., Liao, M., Tan, G., Wang, A., Kayan, K., Alexandropoulos, S., et al.: Influx: A benchmark for self- calibration of dynamic intrinsics of video cameras. arXiv preprint arXiv:2510.23589 (2025)
-
[30]
Lin, Z., Cen, S., Jiang, D., Karhade, J., Wang, H., Mitra, C., Ling, Y.T.T., Huang, Y., Zawar, R., Bai, X., et al.: Towards understanding camera motions in any video. In:TheThirty-ninthAnnualConferenceonNeuralInformationProcessingSystems Datasets and Benchmarks Track (2025)
work page 2025
- [31]
- [32]
- [33]
- [34]
-
[35]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Pautrat, R., Liu, S., Hruby, P., Pollefeys, M., Barath, D.: Vanishing point estima- tioninuncalibrated images withprior gravitydirection. In:ICCV. pp.14118–14127 (2023)
work page 2023
- [37]
-
[38]
Pritts, J., Kukelova, Z., Larsson, V., Lochman, Y., Chum, O.: Minimal Solvers for Rectifying from Radially-Distorted Conjugate Translations. IEEE TPAMI (2020)
work page 2020
- [39]
- [40]
- [41]
-
[42]
In: Conference on robot learning
Shah, D., Osiński, B., Levine, S., et al.: Lm-nav: Robotic navigation with large pre- trained models of language, vision, and action. In: Conference on robot learning. pp. 492–504. pmlr (2023)
work page 2023
-
[43]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (June 2016)
Shi, W., Caballero, J., Huszar, F., Totz, J., Aitken, A.P., Bishop, R., Rueckert, D., Wang, Z.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (June 2016)
work page 2016
- [44]
-
[45]
Sumikura, S., Shibuya, M., Sakurada, K.: Openvslam: A versatile visual slam framework. In: ACM MM. pp. 2292–2295 (2019)
work page 2019
-
[46]
In: Robotics: Science and systems
Teichman, A., Miller, S., Thrun, S.: Unsupervised intrinsic calibration of depth sensors via slam. In: Robotics: Science and systems. vol. 248, p. 3 (2013)
work page 2013
-
[47]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Tirado-Garín, J., Civera, J.: Anycalib: On-manifold learning for model-agnostic single-view camera calibration. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8044–8055 (2025)
work page 2025
-
[48]
IEEE TPAMI13(4), 376–380 (2002)
Umeyama, S.: Least-squares estimation of transformation parameters between two point patterns. IEEE TPAMI13(4), 376–380 (2002)
work page 2002
-
[49]
In: Proceedings of the International Conference on 3D Vision (3DV) (2020)
Vasiljevic, I., Guizilini, V., Ambrus, R., Pillai, S., Burgard, W., Shakhnarovich, G., Gaidon, A.: Neural ray surfaces for self-supervised learning of depth and ego- motion. In: Proceedings of the International Conference on 3D Vision (3DV) (2020)
work page 2020
-
[50]
In: European Conference on Com- puter Vision
Veicht, A., Sarlin, P.E., Lindenberger, P., Pollefeys, M.: Geocalib: Learning single- image calibration with geometric optimization. In: European Conference on Com- puter Vision. pp. 1–20. Springer (2024) Abbreviated paper title 21
work page 2024
-
[51]
Wallingford,M.,Bhattad,A.,Kusupati,A.,Ramanujan,V.,Deitke,M.,Kembhavi, A., Mottaghi, R., Ma, W.C., Farhadi, A.: From an image to a scene: Learning to imagine the world from a million 360 videos. NeurIPS37, 17743–17760 (2024)
work page 2024
- [52]
- [53]
- [54]
- [55]
-
[56]
arXiv preprint arXiv:2102.07064 (2021)
Wang, Z., Wu, S., Xie, W., Chen, M., Prisacariu, V.A.: Neural radiance fields without known camera parameters. arXiv preprint arXiv:2102.07064 (2021)
-
[57]
Xian, W., Li, Z., Fisher, M., Eisenmann, J., Shechtman, E., Snavely, N.: Up- rightNet: Geometry-Aware Camera Orientation Estimation from Single Images. In: ICCV (2019)
work page 2019
-
[58]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (2026)
Zhang, C., Li, B., Wei, M., Cao, Y.P., Gambardella, C.C., Phung, D., Cai, J.: Unified camera positional encoding for controlled video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference (2026)
work page 2026
-
[59]
In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
Zhang, C., Liang, H., Chen, D.Y., Wu, Q., Plataniotis, K.N., Gambardella, C.C., Cai, J.: Panflow: Decoupled motion control for panoramic video generation. In: Proceedings of the AAAI Conference on Artificial Intelligence (2026)
work page 2026
-
[60]
In: Proceedings of the seventh ieee international conference on computer vision
Zhang, Z.: Flexible camera calibration by viewing a plane from unknown orien- tations. In: Proceedings of the seventh ieee international conference on computer vision. vol. 1, pp. 666–673. Ieee (1999)
work page 1999
-
[61]
Zhang, Z.: A flexible new technique for camera calibration. IEEE TPAMI22(11), 1330–1334 (2000) 22 B. Li et al. A Ablation Study We conduct multiple ablation studies to validate our architectural choices in TartanAir dataset, including the choice of the head architecture and the design of the dense prediction (DPT) head. Overall results are summarized in T...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.