Recognition: 2 theorem links
· Lean TheoremUniTriGen: Unified Triplet Generation of Aligned Visible-Infrared-Label for Few-Shot RGB-T Semantic Segmentation
Pith reviewed 2026-05-15 05:48 UTC · model grok-4.3
The pith
A single diffusion process in shared latent space generates aligned visible-infrared-label triplets from limited real pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniTriGen jointly encodes VIS, IR, and Label into a shared latent space and models them with a single diffusion process guided by text prompts, augmented by lightweight modality-specific residual adapters and a scene-balanced class-aware few-shot sampling strategy, to produce spatially aligned, semantically consistent, and modality-complementary triplets from limited real paired data.
What carries the argument
Unified triplet generation mechanism that jointly encodes VIS, IR, and Label into a shared latent space and models them with one diffusion process, plus modality-specific residual adapters.
If this is right
- Generated triplets can directly augment training data for existing RGB-T semantic segmentation networks and produce consistent accuracy gains.
- The unified diffusion approach avoids the consistency failures common in cascaded generation pipelines that handle modalities sequentially.
- Scene-balanced sampling increases diversity of generated scenes and classes, reducing bias from imbalanced few-shot real data.
- The framework lowers the data collection burden for RGB-T applications by turning scarce real pairs into larger effective training sets.
Where Pith is reading between the lines
- The shared latent space idea might transfer to other multi-sensor alignment tasks such as visible-depth or radar-camera triplets.
- If the diffusion process reliably preserves cross-modal details, the same architecture could support conditional generation for rare event classes.
- Extending the adapters to handle additional modalities like depth maps would test whether the unified mechanism scales beyond three-way triplets.
- Real-world deployment would require checking whether generated triplets introduce distribution shift that harms performance on new geographic regions.
Load-bearing premise
Jointly encoding VIS, IR, and Label into a shared latent space and modeling them with a single diffusion process will enforce global cross-modal consistency in spatial structure and semantics without introducing artifacts or biases.
What would settle it
Measure spatial misalignment or semantic inconsistency between generated triplets and real reference data, or check whether adding the generated triplets to training sets fails to raise segmentation accuracy on held-out RGB-T test scenes.
Figures



read the original abstract
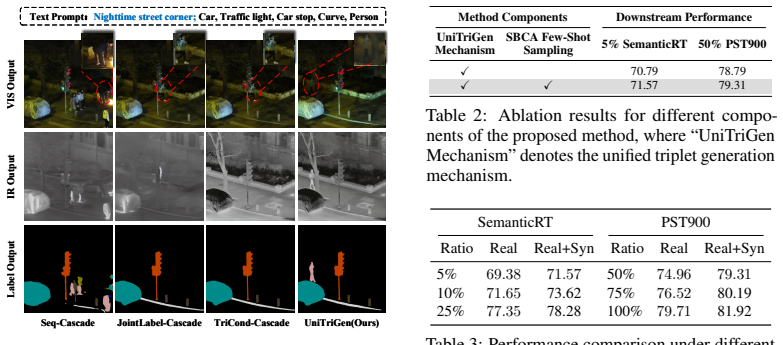
RGB-T semantic segmentation requires strictly aligned VIS-IR-Label triplets; however, such aligned triplet data are often scarce in real-world scenarios. Existing generative augmentation methods usually adopt cascaded generation paradigms, decomposing joint triplet generation into local conditional processes. As a result, consistency among VIS, IR, and Label in spatial structure, semantic content, and cross-modal details cannot be reliably maintained. To address this issue, we propose UniTriGen, a unified triplet generation framework that directly generates spatially aligned, semantically consistent, and modality complementary VIS-IR-Label triplets under the guidance of text prompts. UniTriGen first introduces a unified triplet generation mechanism, where VIS, IR, and Label are jointly encoded into a shared latent space and modeled with a diffusion process to enforce global cross-modal consistency. Lightweight modality-specific residual adapters are further integrated into this mechanism to accommodate modality-specific imaging characteristics and output formats. To mitigate generation bias caused by imbalanced scene and class distributions in limited paired triplets, UniTriGen also employs a scene-balanced and class-aware few-shot sampling strategy, which induces a more balanced sampling distribution and enhances the scene and class diversity of generated triplets. Experiments show that UniTriGen generates high-quality aligned triplets from limited real paired data, thereby achieving consistent performance improvements across various RGB-T semantic segmentation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniTriGen, a unified framework for generating spatially aligned VIS-IR-Label triplets from few-shot paired data. It jointly encodes the three modalities into a shared latent space, models them with a single diffusion process, incorporates lightweight modality-specific residual adapters, and uses scene-balanced class-aware sampling to reduce bias, claiming this produces high-quality consistent triplets that yield performance gains when augmenting various RGB-T semantic segmentation models.
Significance. If the central claim holds, the work offers a principled alternative to cascaded generation pipelines for multi-modal data augmentation, potentially easing the data bottleneck in RGB-T segmentation by enforcing global cross-modal consistency through joint diffusion rather than sequential conditioning.
major comments (2)
- [unified triplet generation mechanism] Unified triplet generation mechanism: The claim that joint encoding of continuous VIS/IR images and categorical label maps into one latent space followed by a single diffusion process enforces global spatial/semantic consistency is load-bearing for the downstream improvement claim, yet the description supplies no explicit alignment losses, pixel-level consistency metrics, or ablation isolating the effect of the shared-space design versus separate encoders; without these, it is unclear whether the residual adapters alone compensate for distribution mismatch between label and image modalities.
- [Experiments] Experiments section: The abstract asserts 'consistent performance improvements across various RGB-T semantic segmentation models' but the provided text contains no quantitative tables, ablation studies on the sampling strategy, error analysis of generated triplet alignment, or validation protocol details; this prevents assessment of whether the generated data actually delivers the claimed gains or merely plausible individual modalities.
minor comments (1)
- [Abstract] The abstract and mechanism description would benefit from a brief statement of the exact form in which labels are encoded (one-hot, embedding, or otherwise) to clarify how categorical data enters the continuous diffusion process.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: Unified triplet generation mechanism: The claim that joint encoding of continuous VIS/IR images and categorical label maps into one latent space followed by a single diffusion process enforces global spatial/semantic consistency is load-bearing for the downstream improvement claim, yet the description supplies no explicit alignment losses, pixel-level consistency metrics, or ablation isolating the effect of the shared-space design versus separate encoders; without these, it is unclear whether the residual adapters alone compensate for distribution mismatch between label and image modalities.
Authors: The unified mechanism models the joint distribution of VIS, IR, and Label modalities directly in a shared latent space via a single diffusion process; this joint modeling is intended to enforce global consistency by construction rather than through auxiliary losses. The modality-specific residual adapters are added precisely to handle distribution differences while preserving the shared-space benefits. That said, we acknowledge the value of isolating the shared-space contribution and will add an ablation comparing the unified encoder against separate modality encoders, along with quantitative pixel-level alignment metrics (e.g., cross-modal IoU and structural similarity between generated components) in the revised manuscript. revision: yes
-
Referee: Experiments section: The abstract asserts 'consistent performance improvements across various RGB-T semantic segmentation models' but the provided text contains no quantitative tables, ablation studies on the sampling strategy, error analysis of generated triplet alignment, or validation protocol details; this prevents assessment of whether the generated data actually delivers the claimed gains or merely plausible individual modalities.
Authors: The full manuscript contains quantitative tables showing performance gains on multiple RGB-T segmentation backbones when augmented with UniTriGen triplets, plus ablations on the scene-balanced sampling strategy. To improve clarity and address the concern directly, we will expand the experiments section with additional tables, an error analysis of generated triplet alignment quality, and explicit details on the validation protocol and few-shot data splits. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper presents UniTriGen as a framework that jointly encodes VIS, IR, and Label into a shared latent space modeled by a single diffusion process, augmented by lightweight residual adapters and a scene-balanced few-shot sampling strategy. These elements are introduced as design choices and training procedures without any equations, predictions, or uniqueness claims that reduce by construction to fitted parameters or self-referential definitions within the paper. No load-bearing self-citations, imported uniqueness theorems, or ansatzes smuggled via prior work are evident in the provided text. The central claims rest on experimental validation of generated triplets improving downstream RGB-T segmentation models, making the approach self-contained against external diffusion modeling benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- modality-specific residual adapter weights
axioms (2)
- domain assumption A single diffusion process in shared latent space enforces global cross-modal consistency among VIS, IR, and Label
- domain assumption Scene-balanced and class-aware few-shot sampling produces more diverse and less biased triplets
invented entities (1)
-
UniTriGen unified triplet generator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
VIS, IR, and Label are jointly encoded into a shared latent space and modeled with a diffusion process to enforce global cross-modal consistency
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lightweight modality-specific residual adapters ... to accommodate modality-specific imaging characteristics
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Textssr: diffusion-based data synthesis for scene text recognition
Xingsong Ye, Yongkun Du, Yunbo Tao, and Zhineng Chen. Textssr: diffusion-based data synthesis for scene text recognition. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17464–17473, 2025
work page 2025
-
[2]
Chenyang Liu, Keyan Chen, Rui Zhao, Zhengxia Zou, and Zhenwei Shi. Text2earth: Unlocking text-driven remote sensing image generation with a global-scale dataset and a foundation model.IEEE Geoscience and Remote Sensing Magazine, 2025
work page 2025
-
[3]
Datasetdm: Synthesizing data with perception annotations using diffusion models
Weijia Wu, Yuzhong Zhao, Hao Chen, Yuchao Gu, Rui Zhao, Yefei He, Hong Zhou, Mike Zheng Shou, and Chunhua Shen. Datasetdm: Synthesizing data with perception annotations using diffusion models. Advances in Neural Information Processing Systems, 36:54683–54695, 2023
work page 2023
-
[4]
Quang Nguyen, Truong Vu, Anh Tran, and Khoi Nguyen. Dataset diffusion: Diffusion-based synthetic data generation for pixel-level semantic segmentation.Advances in Neural Information Processing Systems, 36: 76872–76892, 2023
work page 2023
-
[5]
Dong Zhao, Qi Zang, Shuang Wang, Nicu Sebe, and Zhun Zhong. Pseudo-sd: pseudo controlled stable diffusion for semi-supervised and cross-domain semantic segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22393–22403, 2025
work page 2025
-
[6]
Haoyu Wang, Lei Zhang, Wenrui Liu, Dengyang Jiang, Wei Wei, and Chen Ding. Jodiffusion: Jointly diffusing image with pixel-level annotations for semantic segmentation promotion. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 9775–9783, 2026
work page 2026
-
[7]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[8]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
work page 2023
-
[9]
Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
work page 2023
-
[10]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth International Conference on Learning Representations
-
[12]
Weijia Wu, Yuzhong Zhao, Mike Zheng Shou, Hong Zhou, and Chunhua Shen. Diffumask: Synthesizing images with pixel-level annotations for semantic segmentation using diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1206–1217, 2023
work page 2023
-
[13]
A training-free synthetic data selection method for semantic segmentation
Hao Tang, Siyue Yu, Jian Pang, and Bingfeng Zhang. A training-free synthetic data selection method for semantic segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7229–7237, 2025
work page 2025
-
[14]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[16]
Seggen: Supercharging segmenta- tion models with text2mask and mask2img synthesis
Hanrong Ye, Jason Kuen, Qing Liu, Zhe Lin, Brian Price, and Dan Xu. Seggen: Supercharging segmenta- tion models with text2mask and mask2img synthesis. InEuropean Conference on Computer Vision, pages 352–370. Springer, 2024. 10
work page 2024
-
[17]
Lihe Yang, Xiaogang Xu, Bingyi Kang, Yinghuan Shi, and Hengshuang Zhao. Freemask: Synthetic images with dense annotations make stronger segmentation models.Advances in Neural Information Processing Systems, 36:18659–18675, 2023
work page 2023
-
[18]
Paired image generation with diffusion-guided diffusion models
Haoxuan Zhang, Wenju Cui, Yuzhu Cao, Tao Tan, Jie Liu, Yunsong Peng, and Jian Zheng. Paired image generation with diffusion-guided diffusion models. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 371–381, 2025
work page 2025
-
[19]
Diffusion-based synthetic data generation for visible-infrared person re-identification
Wenbo Dai, Lijing Lu, and Zhihang Li. Diffusion-based synthetic data generation for visible-infrared person re-identification. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11185–11193, 2025
work page 2025
-
[20]
Fangyuan Mao, Jilin Mei, Shun Lu, Fuyang Liu, Liang Chen, Fangzhou Zhao, and Yu Hu. Pid: Physics- informed diffusion model for infrared image generation.Pattern Recognition, 169:111816, 2026
work page 2026
-
[21]
Lingyan Ran, Lidong Wang, Guangcong Wang, Peng Wang, and Yanning Zhang. Diffv2ir: visible-to- infrared diffusion model via vision-language understanding.arXiv preprint arXiv:2503.19012, 2025
-
[22]
HyeongJoo Hwang, Geon-Hyeong Kim, Seunghoon Hong, and Kee-Eung Kim. Variational interaction information maximization for cross-domain disentanglement.Advances in Neural Information Processing Systems, 33:22479–22491, 2020
work page 2020
-
[23]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Image-to-image translation with conditional adversarial networks
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1125–1134, 2017
work page 2017
-
[25]
High- resolution image synthesis and semantic manipulation with conditional gans
Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High- resolution image synthesis and semantic manipulation with conditional gans. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8798–8807, 2018
work page 2018
-
[26]
Unpaired image-to-image translation using cycle-consistent adversarial networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks. InProceedings of the IEEE international conference on computer vision, pages 2223–2232, 2017
work page 2017
-
[27]
Dong-Guw Lee, Myung-Hwan Jeon, Younggun Cho, and Ayoung Kim. Edge-guided multi-domain rgb-to-tir image translation for training vision tasks with challenging labels. In2023 IEEE International Conference on Robotics and Automation (ICRA), pages 8291–8298. IEEE, 2023
work page 2023
-
[28]
Mehmet Akif Özkano˘glu and Sedat Ozer. Infragan: A gan architecture to transfer visible images to infrared domain.Pattern Recognition Letters, 155:69–76, 2022
work page 2022
-
[29]
Zonghao Han, Shun Zhang, Yuru Su, Xiaoning Chen, and Shaohui Mei. Dr-avit: Toward diverse and realistic aerial visible-to-infrared image translation.IEEE Transactions on Geoscience and Remote Sensing, 62:1–13, 2024
work page 2024
-
[30]
Qiyang Sun, Xia Wang, Changda Yan, and Xin Zhang. Vq-infratrans: A unified framework for rgb-ir translation with hybrid transformer.Remote Sensing, 15(24):5661, 2023
work page 2023
-
[31]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, 2024
work page 2024
-
[32]
Any2any: Unified arbitrary modality translation for remote sensing
Haoyang Chen, Jing Zhang, Hebaixu Wang, Shiqin Wang, Pohsun Huang, Jiayuan Li, Haonan Guo, Di Wang, Zheng Wang, and Bo Du. Any2any: Unified arbitrary modality translation for remote sensing. arXiv preprint arXiv:2603.04114, 2026
-
[33]
Xi Yang, Haoyuan Shi, Ziyun Li, Maoying Qiao, Fei Gao, and Nannan Wang. S 3 oil: Semi-supervised sar-to-optical image translation via multi-scale and cross-set matching.IEEE Transactions on Image Processing, 2025
work page 2025
-
[34]
One transformer fits all distributions in multi-modal diffusion at scale
Fan Bao, Shen Nie, Kaiwen Xue, Chongxuan Li, Shi Pu, Yaole Wang, Gang Yue, Yue Cao, Hang Su, and Jun Zhu. One transformer fits all distributions in multi-modal diffusion at scale. InInternational Conference on Machine Learning, pages 1692–1717. PMLR, 2023
work page 2023
-
[35]
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017. 11
work page 2017
-
[36]
Wei Ji, Jingjing Li, Cheng Bian, Zhicheng Zhang, and Li Cheng. Semanticrt: A large-scale dataset and method for robust semantic segmentation in multispectral images. InProceedings of the 31st ACM International Conference on Multimedia, pages 3307–3316, 2023
work page 2023
-
[37]
Pst900: Rgb-thermal calibration, dataset and segmentation network
Shreyas S Shivakumar, Neil Rodrigues, Alex Zhou, Ian D Miller, Vijay Kumar, and Camillo J Taylor. Pst900: Rgb-thermal calibration, dataset and segmentation network. In2020 IEEE international conference on robotics and automation (ICRA), pages 9441–9447. IEEE, 2020
work page 2020
-
[38]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
M-specgene: Generalized foundation model for rgbt multispectral vision
Kailai Zhou, Fuqiang Yang, Shixian Wang, Bihan Wen, Chongde Zi, Linsen Chen, Qiu Shen, and Xun Cao. M-specgene: Generalized foundation model for rgbt multispectral vision. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7861–7872, 2025
work page 2025
-
[40]
Sigma: Siamese mamba network for multi-modal semantic segmentation
Zifu Wan, Pingping Zhang, Yuhao Wang, Silong Yong, Simon Stepputtis, Katia Sycara, and Yaqi Xie. Sigma: Siamese mamba network for multi-modal semantic segmentation. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1734–1744. IEEE, 2025
work page 2025
-
[41]
Jinfu Liu, Hong Liu, Xia Li, Jiale Ren, and Xinhua Xu. Milnet: Multiplex interactive learning network for rgb-t semantic segmentation.IEEE Transactions on Image Processing, 2025. 12
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.