Recognition: no theorem link
DRL-STAF: A Deep Reinforcement Learning Framework for State-Aware Forecasting of Complex Multivariate Hidden Markov Processes
Pith reviewed 2026-05-15 04:36 UTC · model grok-4.3
The pith
DRL-STAF jointly forecasts observations and estimates discrete hidden states in complex multivariate hidden Markov processes by combining deep neural networks with reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
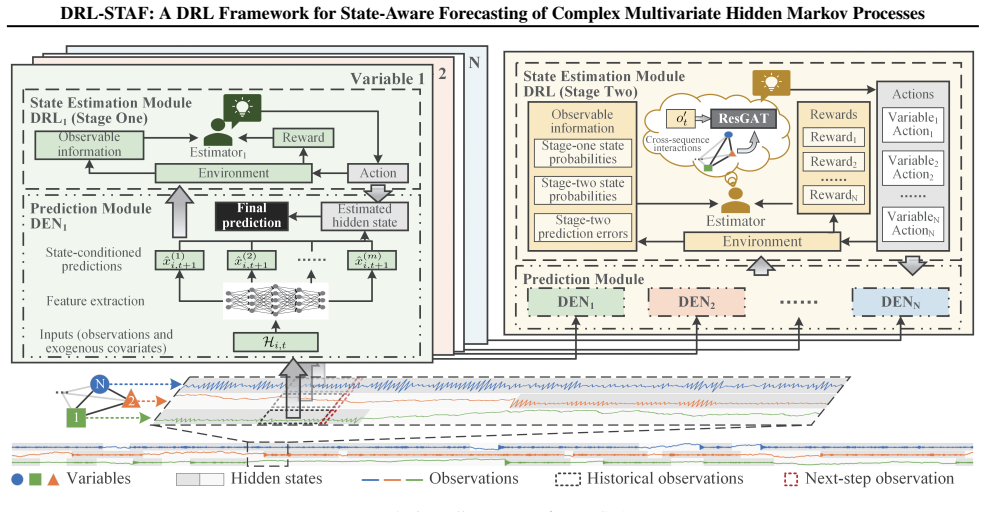
DRL-STAF models complex nonlinear emissions using deep neural networks and estimates discrete hidden states using reinforcement learning for complex multivariate hidden Markov processes, jointly predicting next-step observations and the corresponding hidden states while reducing reliance on predefined transition structures and mitigating state-space explosion.
What carries the argument
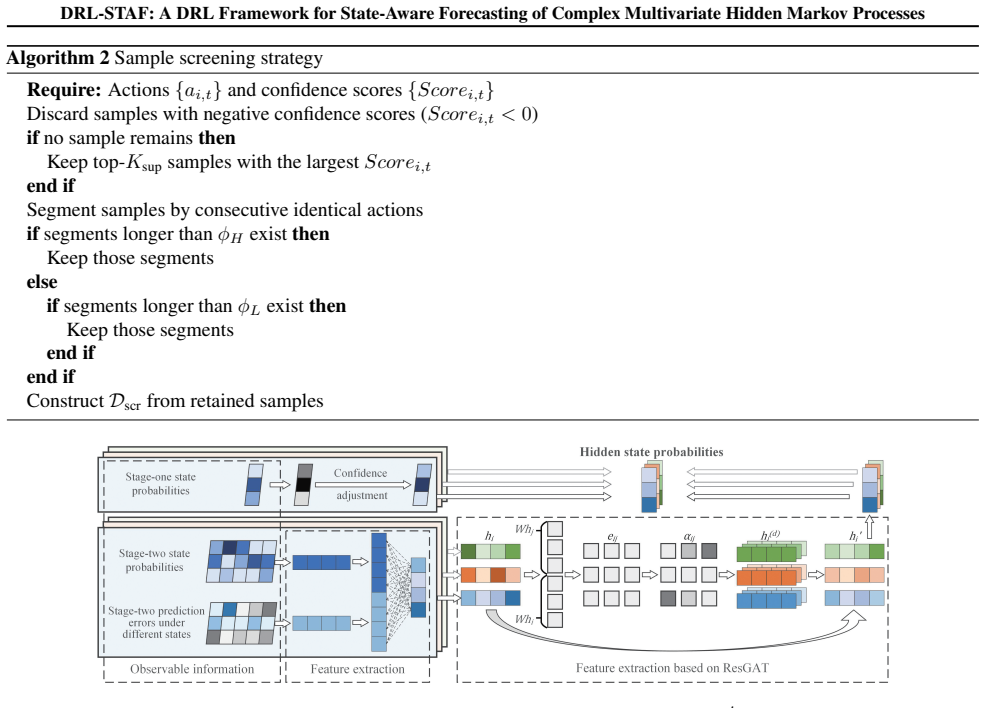
DRL-STAF framework that integrates deep neural networks for emission modeling with a reinforcement learning component that selects hidden states to optimize forecasting accuracy and learns transition dynamics from data.
If this is right
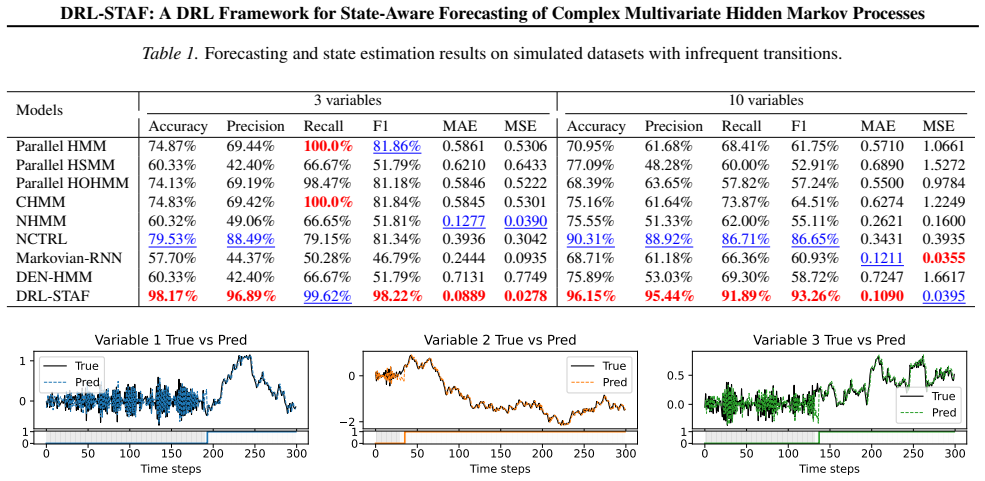
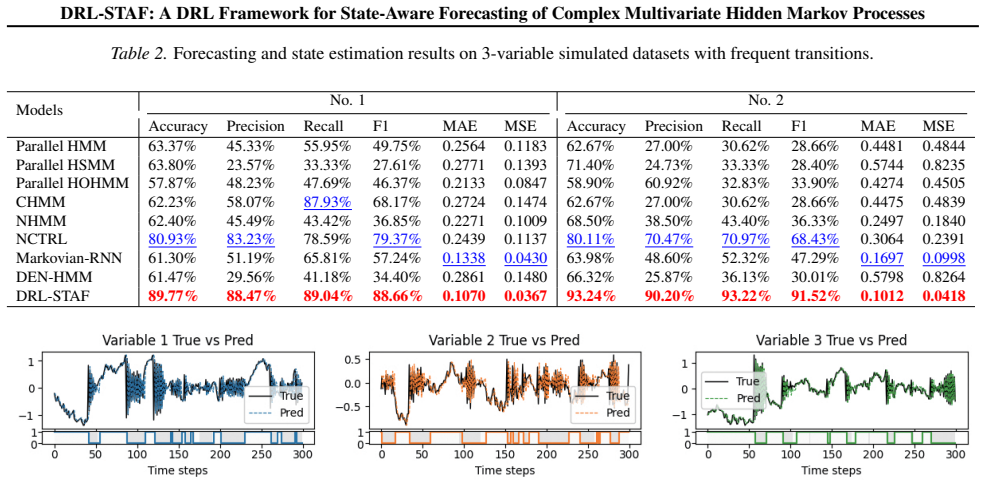
- Forecasting accuracy exceeds that of HMM variants, standalone deep learning models, and existing DL-HMM hybrids in most tested cases.
- The method supplies reliable estimates of the underlying hidden states alongside the forecasts.
- The approach scales to multivariate settings without encountering the combinatorial state-space explosion typical of standard HMMs.
- Transition dynamics adapt flexibly to varied temporal patterns because no fixed transition matrix is imposed in advance.
Where Pith is reading between the lines
- The same reinforcement-learning state estimator could be swapped into other latent-variable time-series models to add interpretability.
- Applications in domains with partially observed regimes, such as sensor networks or financial regimes, would benefit from the joint prediction and state output.
- Performance would likely degrade if the reward signal used by the reinforcement learner fails to align with the true forecasting objective.
- Continuous-valued state extensions would require replacing the discrete action space of the current reinforcement-learning agent.
Load-bearing premise
Reinforcement learning can accurately recover the discrete hidden states and their transition dynamics directly from observed sequences without any predefined structural constraints.
What would settle it
On a synthetic multivariate hidden Markov dataset with known ground-truth states, check whether DRL-STAF's estimated states match the true sequence at rates significantly above chance while also producing lower forecasting error than HMM baselines and hybrid models.
Figures



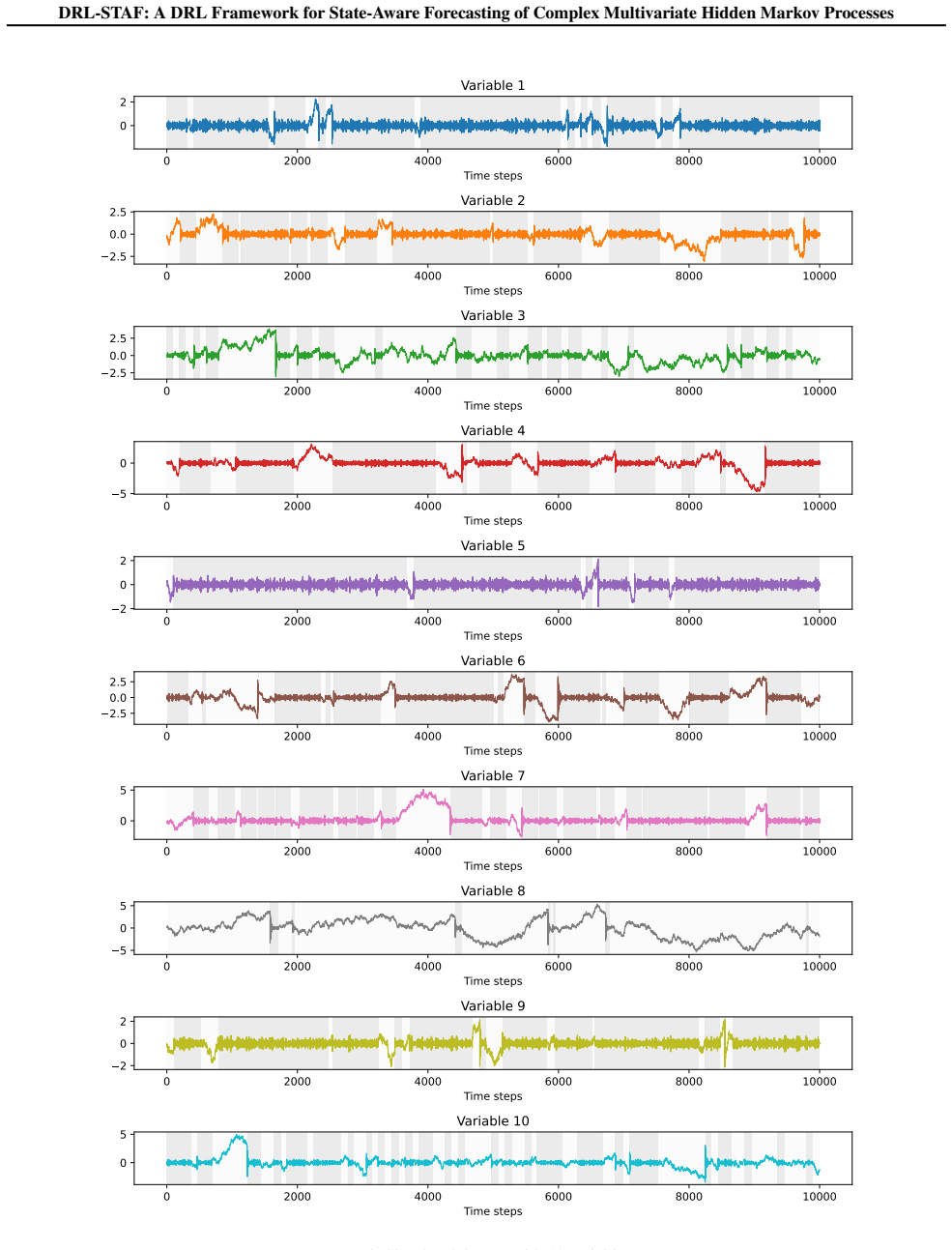
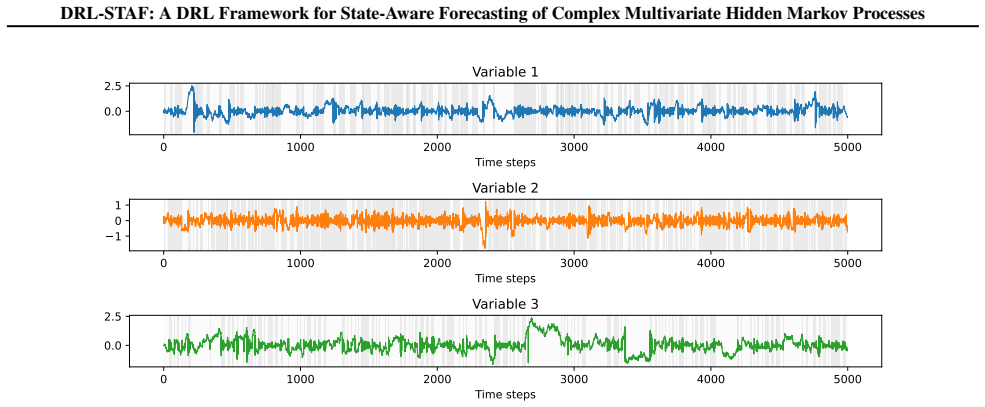









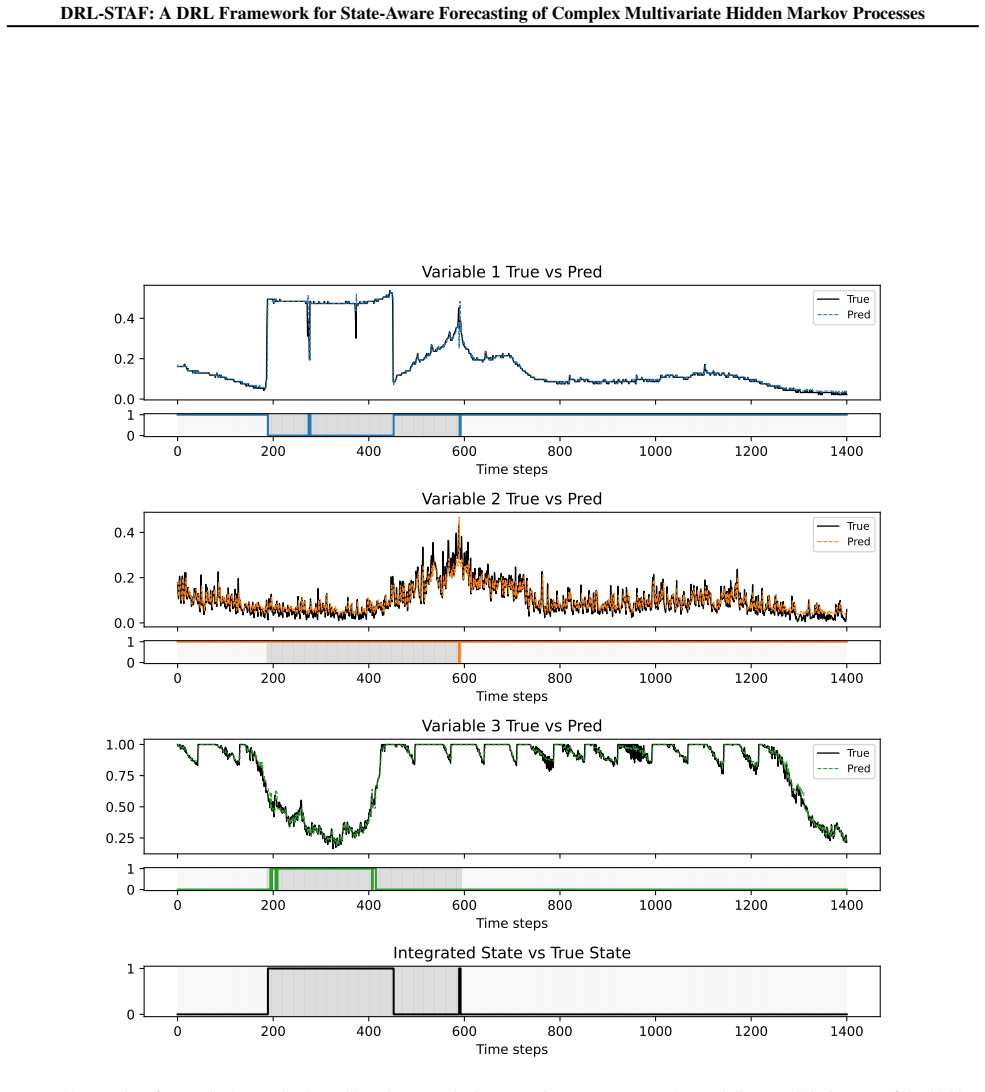
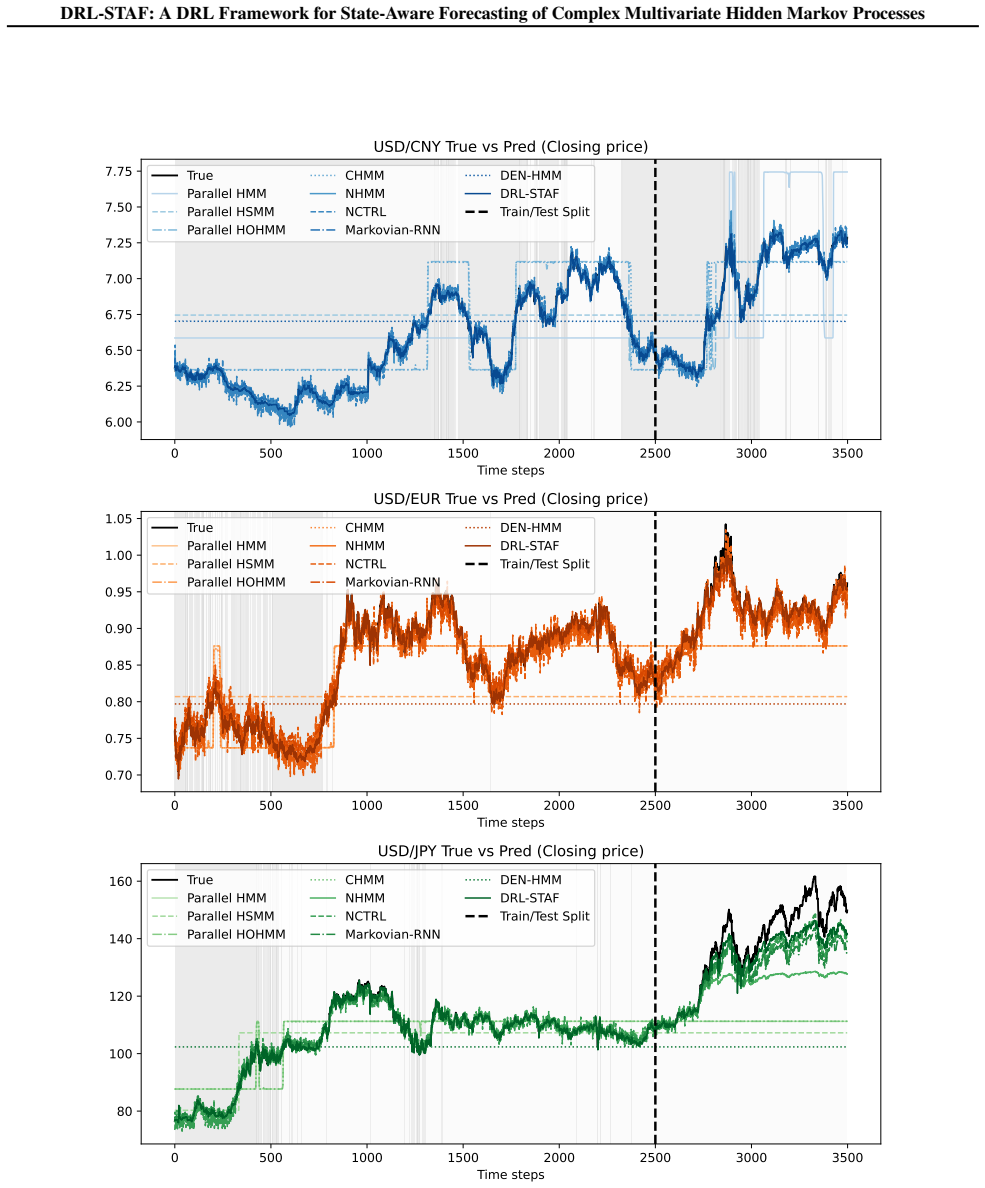
read the original abstract
Forecasting multivariate hidden Markov processes is challenging due to nonlinear and nonstationary observations, latent state transitions, and cross-sequence dependencies. While deep learning methods achieve strong predictive accuracy, they typically lack explicit state modeling, whereas Hidden Markov Models (HMMs) provide interpretable latent states but struggle with complex nonlinear emissions and scalability. To address these limitations, we propose DRL-STAF, a Deep Reinforcement Learning based STate-Aware Forecasting framework that jointly predicts next-step observations and estimates the corresponding hidden states for complex multivariate hidden Markov processes. Specifically, DRL-STAF models complex nonlinear emissions using deep neural networks and estimates discrete hidden states using reinforcement learning, reducing the reliance on predefined transition structures and enabling flexible adaptation to diverse temporal dynamics. In particular, DRL-STAF mitigates the state-space explosion encountered by typical multivariate HMM-based methods. Extensive experiments demonstrate that DRL-STAF outperforms HMM variants, standalone deep learning models, and existing DL-HMM hybrids in most cases, while also providing reliable hidden-state estimates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DRL-STAF, a Deep Reinforcement Learning based STate-Aware Forecasting framework for complex multivariate hidden Markov processes. It models nonlinear emissions with deep neural networks and uses reinforcement learning to estimate discrete hidden states, enabling flexible adaptation to temporal dynamics without predefined transition structures. The central claim is that this joint approach outperforms HMM variants, standalone deep learning models, and DL-HMM hybrids in forecasting accuracy while providing reliable hidden-state estimates, as demonstrated on synthetic data and real-world benchmarks.
Significance. If validated, this framework offers a significant advance by combining the predictive power of deep learning with the state interpretability of HMMs through RL, addressing scalability issues in multivariate settings. The synthetic experiments showing state recovery above chance and consistent benchmark gains with standard deviations indicate practical utility in fields requiring both accurate forecasts and latent state inference, such as financial time series or biological signal processing.
minor comments (3)
- [Abstract] The abstract asserts outperformance but does not include any quantitative metrics, specific baselines, or dataset details; adding a sentence with key results would strengthen the summary.
- [§4] The experimental protocol for real-world benchmarks should specify the train/test split ratios and the number of runs for standard deviations to allow full reproducibility.
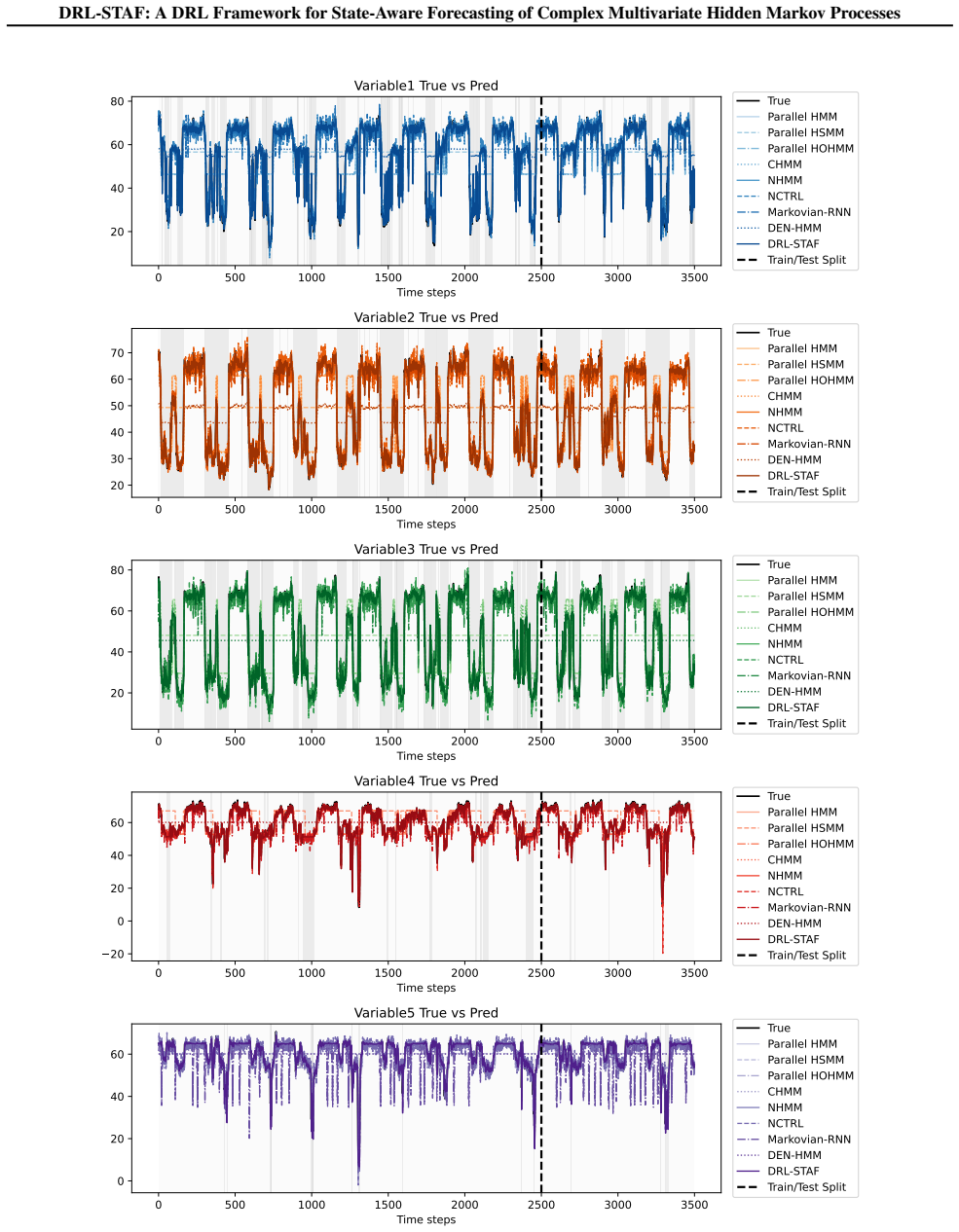
- [Figure 2] The caption for the state estimation visualization is vague on how the recovered states are aligned with ground truth; clarify the matching procedure.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our work on DRL-STAF and for recommending minor revision. The report does not enumerate any specific major comments, so we have no individual points to address point-by-point at this time. We remain ready to incorporate any minor suggestions or clarifications the referee may wish to provide in a subsequent round.
Circularity Check
No significant circularity
full rationale
The paper's derivation uses standard deep neural networks to model nonlinear emissions and reinforcement learning to estimate discrete hidden states via a policy over state-action pairs with rewards based on prediction error. This chain relies on conventional RL optimization and NN training without reducing any 'prediction' to a fitted parameter by construction, without load-bearing self-citations, and without smuggling ansatzes or renaming known results. Experimental comparisons to HMM variants and DL baselines on synthetic and real data provide independent validation, keeping the framework self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The data-generating process can be represented as a hidden Markov model with discrete latent states and nonlinear emissions.
Reference graph
Works this paper leans on
-
[1]
Modeling Long- and Short-Term Temporal Patterns with Deep Neural Networks , author =. ACM SIGIR , pages =
-
[2]
A Recurrent Latent Variable Model for Sequential Data , author =. NeurIPS , pages =
-
[4]
Categorical Reparameterization with Gumbel-Softmax , author =. ICLR , year =
-
[5]
The Concrete Distribution: A Continuous Relaxation of Discrete Random Variables , author =. ICLR , year =
-
[6]
IEEE Transactions on Audio, Speech, and Language Processing , author =
Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition , volume =. IEEE Transactions on Audio, Speech, and Language Processing , author =. 2012 , pages =
work page 2012
-
[7]
Temporally disentangled representation learning under unknown nonstationarity , volume =. NeurIPS , author =. 2023 , pages =
work page 2023
-
[8]
Proceedings of the Workshop on Structured Prediction for NLP , author =
Unsupervised neural hidden Markov models , language =. Proceedings of the Workshop on Structured Prediction for NLP , author =. 2016 , pages =
work page 2016
- [9]
-
[10]
Inference suboptimality in variational autoencoders , language =. ICML , author =
-
[11]
Tighter variational bounds are not necessarily better , language =. ICML , author =. 2018 , pages =
work page 2018
-
[12]
Flexible and accurate inference and learning for deep generative models , volume =
V\'. Flexible and accurate inference and learning for deep generative models , volume =. NeurIPS , language =
-
[13]
IEEE Transactions on Medical Imaging , author =
Interactions between large-scale functional brain networks are captured by sparse coupled. IEEE Transactions on Medical Imaging , author =. 2018 , pages =
work page 2018
-
[14]
Spectral temporal graph neural network for multivariate time-series forecasting , volume =. NeurIPS , author =. 2020 , pages =
work page 2020
-
[15]
Archives of Computational Methods in Engineering , author =
A systematic review of hidden markov models and their applications , volume =. Archives of Computational Methods in Engineering , author =. 2021 , pages =
work page 2021
- [16]
-
[17]
IEEE Transactions on Neural Networks and Learning Systems , author =
Markovian. IEEE Transactions on Neural Networks and Learning Systems , author =. 2023 , pages =
work page 2023
-
[18]
Applied Soft Computing , author =
Hidden. Applied Soft Computing , author =. 2024 , pages =
work page 2024
-
[19]
Information Processing & Management , author =
Forecasting movements of stock time series based on hidden state guided deep learning approach , volume =. Information Processing & Management , author =. 2023 , pages =
work page 2023
- [20]
-
[21]
Journal of Power Sources , author =
Deep learning-based fault diagnosis of high-power. Journal of Power Sources , author =. 2025 , pages =
work page 2025
- [22]
-
[23]
Applied Soft Computing , author =
Prediction maintenance based on vibration analysis and deep learning — a case study of a drying press supported on a hidden markov model , volume =. Applied Soft Computing , author =. 2024 , pages =
work page 2024
-
[24]
Artificial Intelligence Review , author =
Deep learning-based time series forecasting , volume =. Artificial Intelligence Review , author =. 2024 , pages =
work page 2024
-
[25]
ACM Computing Surveys , author =
Graph deep learning for time series forecasting , volume =. ACM Computing Surveys , author =. 2025 , pages =
work page 2025
-
[26]
Proceedings of the IEEE , author =
A tutorial on hidden markov models and selected applications in speech recognition , volume =. Proceedings of the IEEE , author =. 1989 , pages =
work page 1989
-
[27]
Journal of Intelligent Manufacturing , author =
Industrial system working condition identification using operation-adjusted hidden markov model , volume =. Journal of Intelligent Manufacturing , author =. 2023 , pages =
work page 2023
-
[28]
IEEE Computational Intelligence Magazine , author =
Modelling behaviour in. IEEE Computational Intelligence Magazine , author =. 2017 , pages =
work page 2017
-
[29]
Journal of Manufacturing Systems , author =
Human-robot collaboration empowered by hidden semi-. Journal of Manufacturing Systems , author =. 2022 , pages =
work page 2022
-
[30]
IEEE Transactions on Intelligent Transportation Systems , author =
Efficient traffic estimation with multi-sourced data by parallel coupled hidden markov model , volume =. IEEE Transactions on Intelligent Transportation Systems , author =. 2019 , pages =
work page 2019
-
[31]
IEEE Transactions on Industrial Informatics , author =
Time-adaptive expectation maximization learning framework for. IEEE Transactions on Industrial Informatics , author =. 2023 , pages =
work page 2023
-
[32]
IEEE Transactions on Neural Networks and Learning Systems , author =
Clustering hidden markov models with variational bayesian hierarchical. IEEE Transactions on Neural Networks and Learning Systems , author =. 2023 , pages =
work page 2023
- [33]
-
[34]
Particle gibbs for infinite hidden markov models , volume =. NeurIPS , author =
-
[35]
Robust anomaly detection for multivariate time series through stochastic recurrent neural network , author=. SIGKDD , pages=
-
[36]
Seshadri, N. and Sundberg, C.-E.W. , journal=. List Viterbi decoding algorithms with applications , year=
-
[37]
Bansal, V. and Zhou, S. DEN - HMM : Deep emission network based hidden Markov model with time-evolving multivariate observations. IISE Transactions, 0: 0 1--14, 2025
work page 2025
-
[38]
Bolton, T. A. W., Tarun, A., Sterpenich, V., Schwartz, S., and Van De Ville, D. Interactions between large-scale functional brain networks are captured by sparse coupled HMMs . IEEE Transactions on Medical Imaging, 37 0 (1): 0 230--240, 2018
work page 2018
-
[39]
Spectral temporal graph neural network for multivariate time-series forecasting
Cao, D., Wang, Y., Duan, J., Zhang, C., Zhu, X., Huang, C., Tong, Y., Xu, B., Bai, J., Tong, J., and Zhang, Q. Spectral temporal graph neural network for multivariate time-series forecasting. In NeurIPS, volume 33, pp.\ 17766--17778, 2020
work page 2020
-
[40]
EM procedures using mean field-like approximations for Markov model-based image segmentation
Celeux, G., Forbes, F., and Peyrard, N. EM procedures using mean field-like approximations for Markov model-based image segmentation. Pattern Recognition, 36 0 (1): 0 131--144, 2003
work page 2003
-
[41]
A recurrent latent variable model for sequential data
Chung, J., Kastner, K., Dinh, L., Goel, K., Courville, A., and Bengio, Y. A recurrent latent variable model for sequential data. In NeurIPS, pp.\ 2980--2988, 2015
work page 2015
-
[42]
Inference suboptimality in variational autoencoders
Cremer, C., Li, X., and Duvenaud, D. Inference suboptimality in variational autoencoders. In ICML, 2018
work page 2018
-
[43]
E., Dong Yu , Li Deng , and Acero, A
Dahl, G. E., Dong Yu , Li Deng , and Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 20 0 (1): 0 30--42, 2012
work page 2012
-
[44]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear -time sequence modeling with selective state spaces. arXiv, 2024. doi:10.48550/arXiv.2312.00752
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.00752 2024
-
[45]
Ilhan, F., Karaahmetoglu, O., Balaban, I., and Kozat, S. S. Markovian RNN : An Adaptive Time Series Prediction Network With HMM - Based Switching for Nonstationary Environments . IEEE Transactions on Neural Networks and Learning Systems, 34 0 (2): 0 715--728, 2023
work page 2023
-
[46]
Categorical reparameterization with gumbel-softmax
Jang, E., Gu, S., and Poole, B. Categorical reparameterization with gumbel-softmax. In ICLR, 2017
work page 2017
-
[47]
Modeling long- and short-term temporal patterns with deep neural networks
Lai, G., Chang, W.-C., Yang, Y., and Liu, H. Modeling long- and short-term temporal patterns with deep neural networks. In ACM SIGIR, pp.\ 95--104, 2018
work page 2018
-
[48]
Lan, H., Liu, Z., Hsiao, J. H., Yu, D., and Chan, A. B. Clustering hidden markov models with variational bayesian hierarchical EM . IEEE Transactions on Neural Networks and Learning Systems, 34 0 (3): 0 1537--1551, 2023
work page 2023
-
[49]
Li, W. and Zhang, C. A Markov -switching hidden heterogeneous network autoregressive model for multivariate time series data with multimodality. IISE Transactions, 55 0 (11): 0 1118--1132, 2023
work page 2023
-
[50]
Lin, C.-H., Wang, K.-J., Tadesse, A. A., and Woldegiorgis, B. H. Human-robot collaboration empowered by hidden semi- Markov model for operator behaviour prediction in a smart assembly system. Journal of Manufacturing Systems, 62: 0 317--333, 2022
work page 2022
-
[51]
Lotfi, S., Izmailov, P., Benton, G., Goldblum, M., and Wilson, A. G. Bayesian Model Selection , the Marginal Likelihood , and Generalization . In ICML, pp.\ 14223--14247, 2022
work page 2022
-
[52]
Maddison, C. J., Mnih, A., and Teh, Y. W. The concrete distribution: A continuous relaxation of discrete random variables. In ICLR, 2017
work page 2017
-
[53]
A systematic review of hidden markov models and their applications
Mor, B., Garhwal, S., and Kumar, A. A systematic review of hidden markov models and their applications. Archives of Computational Methods in Engineering, 28 0 (3): 0 1429--1448, 2021
work page 2021
-
[54]
A tutorial on hidden markov models and selected applications in speech recognition
Rabiner, L. A tutorial on hidden markov models and selected applications in speech recognition. Proceedings of the IEEE, 77 0 (2): 0 257--286, 1989
work page 1989
-
[55]
A., Maddison, C., Igl, M., Wood, F., and Teh, Y
Rainforth, T., Kosiorek, A., Le, T. A., Maddison, C., Igl, M., Wood, F., and Teh, Y. W. Tighter variational bounds are not necessarily better. In ICML, pp.\ 4277--4285, 2018
work page 2018
-
[56]
Modelling behaviour in UAV operations using higher order double chain markov models
Rodriguez-Fernandez, V., Gonzalez-Pardo, A., and Camacho, D. Modelling behaviour in UAV operations using higher order double chain markov models. IEEE Computational Intelligence Magazine, 12 0 (4): 0 28--37, 2017
work page 2017
-
[57]
Seshadri, N. and Sundberg, C.-E. List viterbi decoding algorithms with applications. IEEE Transactions on Communications, 42 0 (234): 0 313--323, 1994
work page 1994
-
[58]
Song, X., Yao, W., Fan, Y., Dong, X., Chen, G., Niebles, J. C., Xing, E., and Zhang, K. Temporally disentangled representation learning under unknown nonstationarity. In NeurIPS, volume 36, pp.\ 8092--8113, 2023
work page 2023
-
[59]
Robust anomaly detection for multivariate time series through stochastic recurrent neural network
Su, Y., Zhao, Y., Niu, C., Liu, R., Sun, W., and Pei, D. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In SIGKDD, pp.\ 2828--2837, 2019
work page 2019
-
[60]
Industrial system working condition identification using operation-adjusted hidden markov model
Sun, J., Deep, A., Zhou, S., and Veeramani, D. Industrial system working condition identification using operation-adjusted hidden markov model. Journal of Intelligent Manufacturing, 34 0 (6): 0 2611--2624, 2023
work page 2023
-
[61]
M., Bisk, Y., Vaswani, A., Marcu, D., and Knight, K
Tran, K. M., Bisk, Y., Vaswani, A., Marcu, D., and Knight, K. Unsupervised neural hidden markov models. In Proceedings of the Workshop on Structured Prediction for NLP, pp.\ 63--71, 2016
work page 2016
-
[62]
Tripuraneni, N., Gu, S. S., Ge, H., and Ghahramani, Z. Particle gibbs for infinite hidden markov models. In NeurIPS, volume 28, 2015
work page 2015
-
[63]
V\' e rtes, E. and Sahani, M. Flexible and accurate inference and learning for deep generative models. In NeurIPS, volume 31, 2018
work page 2018
-
[64]
Wang, S., Zhang, X., Li, F., Yu, P. S., and Huang, Z. Efficient traffic estimation with multi-sourced data by parallel coupled hidden markov model. IEEE Transactions on Intelligent Transportation Systems, 20 0 (8): 0 3010--3023, 2019
work page 2019
-
[65]
You, Y. and Oechtering, T. J. Time-adaptive expectation maximization learning framework for HMM based data-driven gas sensor calibration. IEEE Transactions on Industrial Informatics, 19 0 (7): 0 7986--7994, 2023
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.