Recognition: 2 theorem links
· Lean TheoremMiVE: Multiscale Vision-language features for reference-guided video Editing
Pith reviewed 2026-05-15 05:19 UTC · model grok-4.3
The pith
MiVE pulls multiscale features from a single vision-language model to guide accurate reference-based video edits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
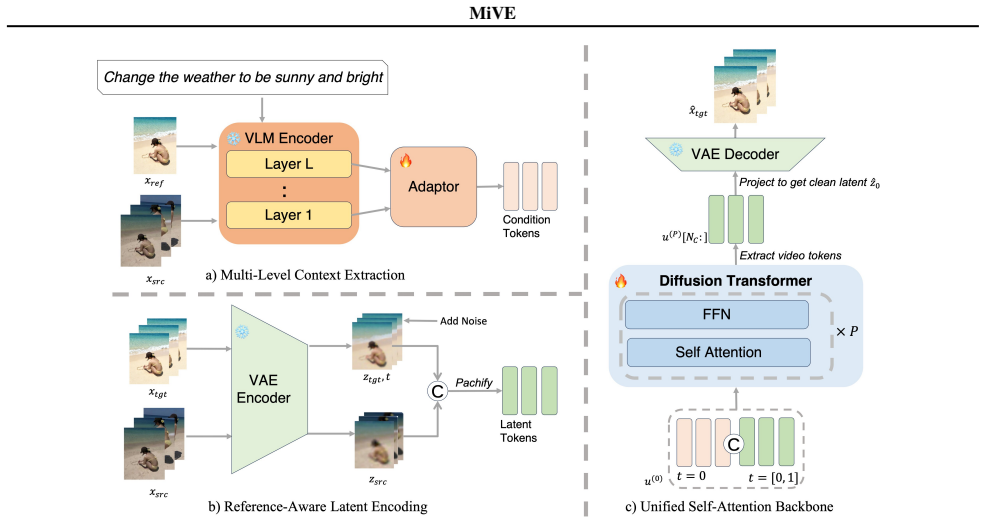
MiVE repurposes a vision-language model as a multiscale feature extractor by taking complementary representations from its early layers for spatial precision and deeper layers for semantic understanding, then fuses them directly inside a unified self-attention Diffusion Transformer to perform reference-guided video edits without modality gaps or loss of fine detail.
What carries the argument
MiVE framework that extracts hierarchical features from Qwen3-VL and integrates them into a unified self-attention Diffusion Transformer.
If this is right
- Original video motion and unedited regions are preserved more faithfully than with separate-encoder or single-layer approaches.
- Text instructions are followed more accurately because global semantics and local details are available together.
- A single model architecture replaces the need for decoupled modality-specific encoders.
- Human evaluators prefer the outputs over both academic baselines and commercial video-editing systems.
Where Pith is reading between the lines
- The same layer-wise extraction pattern could be tested on other diffusion-based video tasks such as generation from scratch or style transfer.
- If early and late layers prove complementary across many VLMs, training objectives might be adjusted to encourage this separation rather than treating all layers equally.
- The unified self-attention design may reduce the engineering overhead of maintaining multiple cross-attention modules in future editing pipelines.
Load-bearing premise
Different layers inside a vision-language model separate spatial details from global semantics in a way that directly improves editing accuracy when fused.
What would settle it
A test that removes early-layer features from the model and measures whether editing precision on tasks requiring exact object placement or boundary alignment drops measurably.
Figures






read the original abstract
Reference-guided video editing takes a source video, a text instruction, and a reference image as inputs, requiring the model to faithfully apply the instructed edits while preserving original motion and unedited content. Existing methods fall into two paradigms, each with inherent limitations: decoupled encoders suffer from modality gaps when processing instructions and visual content independently, while unified vision-language encoders lose fine-grained spatial details by relying solely on final-layer representations. We observe that VLM layers encode complementary information hierarchically -- early layers capture localized spatial details essential for precise editing, while deeper layers encode global semantics for instruction comprehension. Building on this insight, we present MiVE (Multiscale Vision-language features for reference-guided video Editing), a framework that repurposes VLMs as multiscale feature extractors. MiVE extracts hierarchical features from Qwen3-VL and integrates them into a unified self-attention Diffusion Transformer, eliminating the modality mismatch inherent in cross-attention designs. Experiments demonstrate that MiVE achieves state-of-the-art performance by ranking highest in human preference, outperforming both academic methods and commercial systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MiVE, a framework for reference-guided video editing that repurposes a VLM (Qwen3-VL) as a multiscale feature extractor. Early VLM layers supply localized spatial details and deeper layers supply global semantics; these hierarchical features are fused via unified self-attention inside a Diffusion Transformer, avoiding the modality gap of decoupled encoders and the detail loss of single-layer unified encoders. The central claim is that this design yields state-of-the-art performance, measured by highest human preference rankings over both academic baselines and commercial systems.
Significance. If the human-preference results and the hierarchical complementarity assumption are substantiated, the work would offer a practical way to improve spatial fidelity and instruction adherence in video editing without training new encoders, potentially influencing future multimodal diffusion architectures that already rely on pretrained VLMs.
major comments (2)
- [Abstract] Abstract: the claim that MiVE 'achieves state-of-the-art performance by ranking highest in human preference' is presented without any quantitative metrics, baseline names, participant counts, or statistical significance tests, rendering the central empirical claim unverifiable from the manuscript text.
- [Abstract] Abstract: the design rests on the untested assertion that 'VLM layers encode complementary information hierarchically'; no layer-wise ablation, feature-map visualization, or single-layer baseline comparison is referenced to confirm that early-layer features actually supply the localized spatial details required for precise reference-guided editing.
minor comments (1)
- The integration of multiscale VLM features into the DiT self-attention blocks would benefit from an explicit equation or diagram showing how the concatenated features are projected and attended.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and revise the manuscript to improve the abstract's clarity and self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that MiVE 'achieves state-of-the-art performance by ranking highest in human preference' is presented without any quantitative metrics, baseline names, participant counts, or statistical significance tests, rendering the central empirical claim unverifiable from the manuscript text.
Authors: The detailed results—including human preference percentages (MiVE preferred by 72% of participants), baseline names (e.g., VideoCrafter, Runway Gen-3), participant count (n=50), and significance tests—are reported in Section 4.3. We agree the abstract should be verifiable on its own and will add concise quantitative highlights (top preference rate and key baselines) in the revision. revision: yes
-
Referee: [Abstract] Abstract: the design rests on the untested assertion that 'VLM layers encode complementary information hierarchically'; no layer-wise ablation, feature-map visualization, or single-layer baseline comparison is referenced to confirm that early-layer features actually supply the localized spatial details required for precise reference-guided editing.
Authors: The hierarchical complementarity is supported by our feature analysis in Section 3.2 and by the performance gap between multiscale and final-layer variants in the experiments. We acknowledge the abstract lacks an explicit pointer. In revision we will reference the layer-wise visualizations (Figure 3) and single-layer ablation results already present in the main text. revision: yes
Circularity Check
No circularity: design rests on stated empirical observation with external human-preference validation
full rationale
The paper presents the hierarchical VLM-layer complementarity as a direct observation ('We observe that VLM layers encode complementary information hierarchically'), then extracts those features from an off-the-shelf Qwen3-VL and fuses them inside a standard DiT via unified self-attention. No equations, fitted parameters, or predictions are defined in terms of the target result; the SOTA human-preference ranking is measured on held-out edits and is therefore independent of the architectural premise. No self-citations are invoked to justify the core insight, and the method does not rename or re-derive any of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLM layers encode complementary information hierarchically -- early layers capture localized spatial details essential for precise editing, while deeper layers encode global semantics for instruction comprehension.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MiVE extracts hierarchical features from Qwen3-VL and integrates them into a unified self-attention Diffusion Transformer
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zeyinzi Jiang and Zhen Han and Chaojie Mao and Jingfeng Zhang and Yulin Pan and Yu Liu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2503.07598 , eprinttype =. 2503.07598 , timestamp =
-
[2]
Yuxuan Bian and Zhaoyang Zhang and Xuan Ju and Mingdeng Cao and Liangbin Xie and Ying Shan and Qiang Xu , editor =. VideoPainter: Any-length Video Inpainting and Editing with Plug-and-Play Context Control , booktitle =. 2025 , url =. doi:10.1145/3721238.3730673 , timestamp =
-
[3]
Lucy Edit: Open-Weight Text-Guided Video Editing , author =. 2025 , url =
work page 2025
-
[4]
Zhihan Xiao and Lin Liu and Yixin Gao and Xiaopeng Zhang and Haoxuan Che and Songping Mai and Qi Tian , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2512.02933 , eprinttype =. 2512.02933 , timestamp =
-
[5]
VideoCoF: Unified Video Editing with Temporal Reasoner
Xiangpeng Yang and Ji Xie and Yiyuan Yang and Yan Huang and Min Xu and Qiang Wu , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2512.07469 , eprinttype =. 2512.07469 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.07469 2025
-
[6]
Qingyan Bai and Qiuyu Wang and Hao Ouyang and Yue Yu and Hanlin Wang and Wen Wang and Ka Leong Cheng and Shuailei Ma and Yanhong Zeng and Zichen Liu and Yinghao Xu and Yujun Shen and Qifeng Chen , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.15742 , eprinttype =. 2510.15742 , timestamp =
-
[7]
Chenxuan Miao and Yutong Feng and Jianshu Zeng and Zixiang Gao and Hantang Liu and Yunfeng Yan and Donglian Qi and Xi Chen and Bin Wang and Hengshuang Zhao , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2508.18633 , eprinttype =. 2508.18633 , timestamp =
-
[8]
Zhongwei Zhang and Fuchen Long and Wei Li and Zhaofan Qiu and Wu Liu and Ting Yao and Tao Mei , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2512.17650 , eprinttype =. 2512.17650 , timestamp =
-
[9]
Xinyao Liao and Xianfang Zeng and Ziye Song and Zhoujie Fu and Gang Yu and Guosheng Lin , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.14648 , eprinttype =. 2510.14648 , timestamp =
-
[10]
Zhaoyang Li and Dongjun Qian and Kai Su and Qishuai Diao and Xiangyang Xia and Chang Liu and Wenfei Yang and Tianzhu Zhang and Zehuan Yuan , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2510.00438 , eprinttype =. 2510.00438 , timestamp =
-
[11]
Jiahao Hu and Tianxiong Zhong and Xuebo Wang and Boyuan Jiang and Xingye Tian and Fei Yang and Pengfei Wan and Di Zhang , title =. CoRR , volume =. 2024 , url =. doi:10.48550/ARXIV.2411.15260 , eprinttype =. 2411.15260 , timestamp =
-
[12]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang and Baole Ai and Bin Wen and Chaojie Mao and Chen. Wan: Open and Advanced Large-Scale Video Generative Models , journal =. 2025 , url =. doi:10.48550/ARXIV.2503.20314 , eprinttype =. 2503.20314 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.20314 2025
-
[13]
Gang Cheng and Xin Gao and Li Hu and Siqi Hu and Mingyang Huang and Chaonan Ji and Ju Li and Dechao Meng and Jinwei Qi and Penchong Qiao and Zhen Shen and Yafei Song and Ke Sun and Linrui Tian and Feng Wang and Guangyuan Wang and Qi Wang and Zhongjian Wang and Jiayu Xiao and Sheng Xu and Bang Zhang and Peng Zhang and Xindi Zhang and Zhe Zhang and Jingren ...
-
[14]
The Thirteenth International Conference on Learning Representations,
Zhuoyi Yang and Jiayan Teng and Wendi Zheng and Ming Ding and Shiyu Huang and Jiazheng Xu and Yuanming Yang and Wenyi Hong and Xiaohan Zhang and Guanyu Feng and Da Yin and Yuxuan Zhang and Weihan Wang and Yean Cheng and Bin Xu and Xiaotao Gu and Yuxiao Dong and Jie Tang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[15]
Shuai Bai and Yuxuan Cai and Ruizhe Chen and Keqin Chen and Xionghui Chen and Zesen Cheng and Lianghao Deng and Wei Ding and Chang Gao and Chunjiang Ge and Wenbin Ge and Zhifang Guo and Qidong Huang and Jie Huang and Fei Huang and Binyuan Hui and Shutong Jiang and Zhaohai Li and Mingsheng Li and Mei Li and Kaixin Li and Zicheng Lin and Junyang Lin and Xue...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[16]
Chenfei Wu and Jiahao Li and Jingren Zhou and Junyang Lin and Kaiyuan Gao and Kun Yan and Shengming Yin and Shuai Bai and Xiao Xu and Yilei Chen and Yuxiang Chen and Zecheng Tang and Zekai Zhang and Zhengyi Wang and An Yang and Bowen Yu and Chen Cheng and Dayiheng Liu and Deqing Li and Hang Zhang and Hao Meng and Hu Wei and Jingyuan Ni and Kai Chen and Ku...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.02324 2025
-
[17]
Tianyu Yu and Zefan Wang and Chongyi Wang and Fuwei Huang and Wenshuo Ma and Zhihui He and Tianchi Cai and Weize Chen and Yuxiang Huang and Yuanqian Zhao and Bokai Xu and Junbo Cui and Yingjing Xu and Liqing Ruan and Luoyuan Zhang and Hanyu Liu and Jingkun Tang and Hongyuan Liu and Qining Guo and Wenhao Hu and Bingxiang He and Jie Zhou and Jie Cai and Ji ...
-
[18]
GLM-4.5V and GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning , author=. 2026 , eprint=
work page 2026
-
[19]
DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs , booktitle =
Lingchen Meng and Jianwei Yang and Rui Tian and Xiyang Dai and Zuxuan Wu and Jianfeng Gao and Yu. DeepStack: Deeply Stacking Visual Tokens is Surprisingly Simple and Effective for LMMs , booktitle =. 2024 , url =
work page 2024
- [20]
-
[21]
The Thirteenth International Conference on Learning Representations,
Seil Kang and Jinyeong Kim and Junhyeok Kim and Seong Jae Hwang , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[22]
Yaron Lipman and Ricky T. Q. Chen and Heli Ben. Flow Matching for Generative Modeling , booktitle =. 2023 , url =
work page 2023
-
[23]
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. J. Mach. Learn. Res. , volume =. 2020 , url =
work page 2020
-
[24]
Learning Transferable Visual Models From Natural Language Supervision , booktitle =
Alec Radford and Jong Wook Kim and Chris Hallacy and Aditya Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever , editor =. Learning Transferable Visual Models From Natural Language Supervision , booktitle =. 2021 , url =
work page 2021
-
[25]
Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer , title =. 2023 , url =. doi:10.1109/ICCV51070.2023.01100 , timestamp =
-
[26]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin and Ming. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies,. 2019 , url =. doi:10.18653/V1/N19-1423 , timestamp =
-
[27]
Google Gemini , author =
-
[28]
Jialu Chen and Yuanzheng Ci and Xiangyu Du and Zipeng Feng and Kun Gai and Sainan Guo and Feng Han and Jingbin He and Kang He and Xiao Hu and Xiaohua Hu and Boyuan Jiang and Fangyuan Kong and Hang Li and Jie Li and Qingyu Li and Shen Li and Xiaohan Li and Yan Li and Jiajun Liang and Borui Liao and Yiqiao Liao and Weihong Lin and Quande Liu and Xiaokun Liu...
-
[29]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Z. Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer , journal =. 2025 , url =. doi:10.48550/ARXIV.2511.22699 , eprinttype =. 2511.22699 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.22699 2025
-
[30]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs and Stephen Batifol and Andreas Blattmann and Frederic Boesel and Saksham Consul and Cyril Diagne and Tim Dockhorn and Jack English and Zion English and Patrick Esser and Sumith Kulal and Kyle Lacey and Yam Levi and Cheng Li and Dominik Lorenz and Jonas M. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2506.15742 , eprinttype =. 2506....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.15742 2025
-
[31]
9th International Conference on Learning Representations,
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , title =. 9th International Conference on Learning Representations,. 2021 , url =
work page 2021
-
[32]
Haoyang He and Jie Wang and Jiangning Zhang and Zhucun Xue and Xingyuan Bu and Qiangpeng Yang and Shilei Wen and Lei Xie , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2512.07826 , eprinttype =. 2512.07826 , timestamp =
-
[33]
The Thirteenth International Conference on Learning Representations,
Nikhila Ravi and Valentin Gabeur and Yuan. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[34]
Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and Chu, Zhaokai and Cao, Zhe and Zhao, Hongjie and Yang, Minghao and Lai, Jiahao and Wang, Jiaqi and Hu, Yang and Jiang, Xiaohan and Hu, Xiangyu and Gao, Botian and Li, Tianshuo and Liu, Hongshe...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.