Recognition: no theorem link
Breaking Dual Bottlenecks: Evolving Unified Multimodal Models into Self-Adaptive Interleaved Visual Reasoners
Pith reviewed 2026-05-15 04:47 UTC · model grok-4.3
The pith
Unified multimodal models learn to switch autonomously between direct generation, reflection, and planning to close the understanding-generation gap in image tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
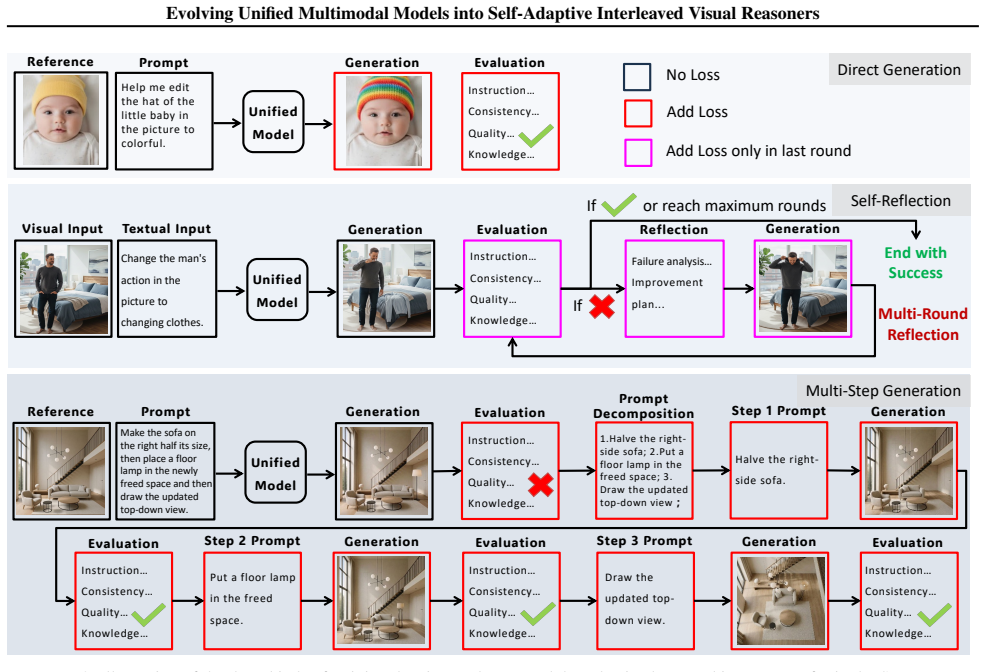
By training on a hierarchical pipeline of direct, reflective, and multi-step planning paths together with step-wise reasoning rewards and an intra-group complexity penalty, unified multimodal models acquire the ability to switch autonomously among generation strategies according to prompt complexity, thereby removing the attention entanglement bottleneck that hampers blind planning and the visual refinement bottleneck that leaves errors uncorrected.
What carries the argument
The hierarchical data pipeline that supplies execution paths across three adaptive modes (direct generation, self-reflection, multi-step planning) together with the step-wise reasoning rewards and complexity penalty that steer reinforcement learning toward autonomous mode selection.
If this is right
- Generation fidelity rises on X2I tasks for both simple and complex instructions compared with prior unified models.
- The model selects generation, reflection, or planning paths without external control signals.
- Step-wise rewards maintain logical consistency across the chosen reasoning sequence.
- The complexity penalty reduces redundant computation while preserving output quality.
Where Pith is reading between the lines
- The same hierarchical pipeline could be reused to train unified models for video or audio generation tasks that also require interleaved understanding and synthesis.
- Inference cost may drop because simple prompts avoid unnecessary multi-step planning at runtime.
- Adding an explicit capability estimator inside the model could make mode selection more robust on prompts outside the original training distribution.
Load-bearing premise
The constructed data pipeline and the chosen rewards plus penalty will teach the model to pick the right mode for each prompt without creating fresh bottlenecks or overfitting to the new training distribution.
What would settle it
A held-out test set of complex prompts on which the trained model shows no measurable gain in pixel-level fidelity over non-adaptive baselines or fails to demonstrate correct mode switching when instruction complexity increases.
Figures













read the original abstract
Recent unified models integrate multimodal understanding and generation within a single framework. However, an "understanding-generation gap" persists, where models can capture user intent but often fail to translate this semantic knowledge into precise pixel-level manipulation. This gap results in two bottlenecks in anything-to-image task (X2I): the attention entanglement bottleneck, where blind planning struggles with complex prompts, and the visual refinement bottleneck, where unstructured feedback fails to correct imperfections efficiently. In this paper, we propose a novel framework that empowers unified models to autonomously switch between generation strategies based on instruction complexity and model capability. To achieve this, we construct a hierarchical data pipeline that constructs execution paths across three adaptive modes: direct generation for simple cases, self-reflection for quality refinement, and multi-step planning for decomposing complex scenarios. Building on this pipeline, we contribute a high-quality dataset with over 50,000 samples and implement a two-stage training strategy comprising SFT and RL. Specifically, we design step-wise reasoning rewards to ensure logical consistency and intra-group complexity penalty to prevent redundant computational overhead. Extensive experiments demonstrate that our method outperforms existing baselines on X2I, achieving superior generation fidelity among simple-to-complex instructions. The code is released at https://github.com/WeChatCV/Interleaved_Visual_Reasoner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that unified multimodal models suffer from an understanding-generation gap manifesting as attention entanglement and visual refinement bottlenecks in X2I tasks. It introduces a self-adaptive framework that enables autonomous mode switching among direct generation, self-reflection, and multi-step planning by constructing a hierarchical data pipeline, releasing a 50k-sample dataset, and applying a two-stage SFT+RL training process with step-wise reasoning rewards and an intra-group complexity penalty. Experiments are said to show superior generation fidelity over baselines across simple-to-complex instructions.
Significance. If the adaptive mechanism generalizes beyond the synthetic dataset and the reported fidelity gains are not artifacts of the custom reward design, the work could meaningfully advance unified multimodal architectures by demonstrating practical autonomous reasoning allocation. The code release supports reproducibility, though the absence of detailed ablations on mode-selection accuracy limits immediate impact assessment.
major comments (2)
- [§3 and Experiments] The central claim of autonomous mode switching rests on the two-stage SFT+RL pipeline and the hierarchical data pipeline (described in the abstract and §3). However, because execution paths and mode labels are synthetically assigned in the 50k-sample construction, it is unclear whether the model learns genuine complexity-based adaptation or spurious prompt-mode correlations; no out-of-distribution evaluation or mode-selection accuracy metrics are provided to rule out overfitting.
- [Training Strategy] The step-wise reasoning rewards and intra-group complexity penalty are presented as key to enforcing logical consistency and preventing redundant overhead, yet the manuscript does not report the specific reward weights, the value of the complexity penalty coefficient, or sensitivity analysis for the mode-switching thresholds (listed as free parameters in the axiom ledger). This leaves open whether the outperformance on X2I is robust or the result of post-hoc tuning.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments' but provides no table or figure references; adding explicit citations to quantitative results (e.g., Table 2 or Figure 4) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commit to specific revisions that strengthen the evidence for autonomous mode switching.
read point-by-point responses
-
Referee: [§3 and Experiments] The central claim of autonomous mode switching rests on the two-stage SFT+RL pipeline and the hierarchical data pipeline (described in the abstract and §3). However, because execution paths and mode labels are synthetically assigned in the 50k-sample construction, it is unclear whether the model learns genuine complexity-based adaptation or spurious prompt-mode correlations; no out-of-distribution evaluation or mode-selection accuracy metrics are provided to rule out overfitting.
Authors: We acknowledge that mode labels originate from the synthetic hierarchical pipeline. However, the RL stage optimizes directly for generation quality via step-wise rewards, encouraging the model to discover effective mode choices rather than rote correlations. To address the concern rigorously, we will add quantitative mode-selection accuracy on a held-out test split (comparing model-chosen modes to pipeline labels) and include qualitative results on out-of-distribution real-world prompts in the revised manuscript. revision: yes
-
Referee: [Training Strategy] The step-wise reasoning rewards and intra-group complexity penalty are presented as key to enforcing logical consistency and preventing redundant overhead, yet the manuscript does not report the specific reward weights, the value of the complexity penalty coefficient, or sensitivity analysis for the mode-switching thresholds (listed as free parameters in the axiom ledger). This leaves open whether the outperformance on X2I is robust or the result of post-hoc tuning.
Authors: We agree that explicit hyperparameter values and sensitivity analysis are necessary for assessing robustness. In the revised manuscript we will report the precise weights for the step-wise reasoning rewards, the exact coefficient of the intra-group complexity penalty, and a sensitivity study over the mode-switching thresholds, placed in Section 4 and the appendix. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs a hierarchical data pipeline and 50k-sample dataset to train a two-stage SFT+RL procedure with custom step-wise rewards and complexity penalties, then reports empirical outperformance on X2I benchmarks. No equations, self-citations, or uniqueness claims reduce the central performance result to a definitional restatement of the training inputs; the reported gains are presented as outcomes of training and evaluation rather than tautological by construction. The approach is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- intra-group complexity penalty coefficient
- mode-switching thresholds
axioms (1)
- domain assumption Reinforcement learning with step-wise rewards produces logically consistent generation paths
invented entities (1)
-
self-adaptive interleaved visual reasoner
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-01-29. Guo, Z., Zhang, R., Li, H., Zhang, M., Chen, X., Wang, S., Feng, Y ., Pei, P., and Heng, P.-A. Thinking-while- generating: Interleaving textual reasoning throughout vi- sual generation.arXiv preprint arXiv:2511.16671, 2025a. Guo, Z., Zhang, R., Tong, C., Zhao, Z., Huang, R., Zhang, H., Zhang, M., Liu, J., Zhang, S., Gao, P., et al. C...
-
[4]
**Generated Image (Y)**: The resulting image to be evaluated. Your Objective: Evaluate how faithfully the Generated Image (Y) fulfills the **Instruction**, focusing on whether the requested changes or additions were executed correctly. ## Reasoning Steps:
-
[5]
**Detect Change**: What has been added, modified, or created in Y compared to X? (If X is Text-only, evaluate Y directly against the text)
-
[6]
**Expected Visual Caption**: Describe the ideal result if the instruction were perfectly followed
-
[7]
**Instruction Match**: - Was the correct subject/attribute modified or created? - For **Spatial/Size** changes: Is the placement or scale correct relative to the instruction? - For **Subject-driven** (Multi-image): Does the generated subject perform the action/state requested in the instruction?
-
[8]
**Decision**: Assign a score based on compliance. ## Evaluation Scale (1 to 5): - **5 Perfect Compliance**: Y precisely matches the instruction; all required changes are present, accurate, and clearly visible. - **4 Minor Omission**: The core instruction is met, but a minor detail or nuance of the prompt is missing or slightly off. - **3 Partial Complianc...
-
[9]
This could be a single image, multiple images (reference set), or nothing
**Input Image(s) (X)**: The original image(s). This could be a single image, multiple images (reference set), or nothing
-
[10]
**Instruction**: A directive describing the desired output
-
[11]
**Generated Image (Y)**: The resulting image to be evaluated. Your Objective: Evaluate how well the **identity, core attributes, and non-instructed elements** from the Input Image(s) (X) are preserved in the Generated Image (Y). ## Evaluation Logic by Input Type: - **Case 1: Pure Text Input**: If there is no input image, the consistency is automatically p...
-
[13]
**Instruction**: A directive describing the desired modification or creation
-
[14]
**Generated Image (Y)**: The resulting image to be evaluated. ## Objective: Evaluate the perceptual quality, structural integrity, and aesthetic harmony of the Generated Image (Y). You must determine if the image is a high-quality, physically plausible result or a flawed AI generation. ## Evaluation Criteria:
-
[15]
**Structural Coherence**: Are shapes, anatomy, and textures accurate? Check for "AI hallucinations" like extra limbs, melted objects, or garbled text
-
[16]
**Lighting & Color Harmony**: Is the lighting consistent within the scene? Do shadows and highlights follow a logical light source? (Fail: Objects looking "pasted" or lighting that contradicts the environment)
-
[17]
**Technical Fidelity**: Check for "sticker effects," jagged edges, or unrealistic sharpness/blur. Does the image have consistent grain and resolution throughout?
-
[18]
**Compositional Logic**: Does the scene layout make sense? Are the perspective and Depth of Field (DoF) handled naturally? Does the level of grain/noise and focus (Depth of Field) of the edited region match across the original image? (Fail: A 4K sharp object in a blurry background, unless it's intended bokeh). ## Evaluation Scale (1 to 5): - **5 Excellent...
-
[19]
**Input Image(s) (X)**: The reference source (Single, Multiple, or None)
-
[20]
**Instruction**: A directive describing the intended modification or creation
-
[21]
**Generated Image (Y)**: The resulting image to be evaluated
-
[22]
**Explanation** (optional): Additional context about the knowledge required. ## The 3-Step Forensic Inspection Protocol **Phase 1: Geometry, Scale & Depth (Priority)** - **Perspective**: Is the perspective of the generated content (new subject, edit area) consistent with the background or existing scene in X? - **Relative Scale**: Is the size of the gener...
-
[23]
**Original Image**: The source image
-
[24]
**Edited Image**: The failed attempt
-
[25]
**Editing Instruction**: {editing_instruction}
-
[26]
**Evaluation Scores & Evidence**: - **Consistency ({consistency_score}/5)**: Reasoning: {consistency_reasoning} - **Instruction ({instruction_score}/5)**: Reasoning: {instruction_reasoning} - **Quality ({quality_score}/5)**: Reasoning: {quality_reasoning} - **Knowledge ({knowledge_score}/5)**: Reasoning: {knowledge_reasoning} ### Task 1: Failure Analysis ...
-
[27]
**Atomic Steps:** Each step should focus on changing one specific visual aspect
-
[28]
**Logical Order (Local -> Global):** * **Priority 1: Local Structure & Content.** specific object modifications (e.g., "change clothes," "add glasses," "fix hair") must happen *first*. This anchors the subject's identity before the environment changes. * **Priority 2: Global Atmosphere & Style.** Broad changes (e.g., "change time of day," "apply oil paint...
-
[29]
**Visual Reasoning:** Do not just split the sentence grammatically. Think about *how* an image generator works. If the user says "Make the apple rotten," plan it visually: "add mold spots (Local)" -> "change color to brown (Local)" -> "adjust lighting to be gloomy (Global)"
-
[30]
**Preservation:** Implicitly maintain the identity of the parts that shouldn't change
-
[31]
Achieve the edit in as few steps as possible
**Step Count:** Aim for 2-3 steps. Achieve the edit in as few steps as possible
-
[32]
**The "Move" Logic** If the user asks to move an object, decompose it into removing the object from the original position first, then adding it to the new position
-
[33]
If Step 1 turns a 'cat' into a 'tiger', Step 2 must refer to it as 'the tiger', not 'the cat'
**Subject Reference Update** Update the terminology in later steps to match changes made in earlier steps. If Step 1 turns a 'cat' into a 'tiger', Step 2 must refer to it as 'the tiger', not 'the cat'
-
[34]
**Atomic Interaction** Keep tight physical interactions combined. 'A man holding a sword' is better generated in one specific step or by explicitly targeting the interaction area, rather than generating a man and a sword separately
-
[35]
**Clean Slate Strategy** If adding an object to a cluttered area, consider an implicit step to 'clear or empty' that specific surface first to ensure clean generation
-
[36]
Each step MUST state that all unrelated visual regions remain unchanged. # Input Data:
-
[37]
**Image**: The source image
-
[38]
**Editing Instruction**: "{}"
-
[39]
Turn the wooden chair into a futuristic gaming chair
**Explanation** (optional): "{}" # Output Format Return **only** a JSON list of strings, where each string is a prompt for a single step. Do not include markdown code blocks or explanations outside the JSON. # Few-Shot Examples **Example 1 (Logic: Local Shape First -> Surface Material)** * **User Instruction:** "Turn the wooden chair into a futuristic gam...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.