Editor's Choice: Evaluating Abstract Intent in Image Editing through Atomic Entity Analysis
Pith reviewed 2026-06-30 21:38 UTC · model grok-4.3
The pith
Abstract image editing benchmarks show models struggle to balance intent and preservation on non-literal instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Standard architectures struggle to balance intent and preservation in abstract image editing, commonly defaulting to under-editing or over-editing, as revealed by applying the Entity-Rubrics framework to the AbstractEdit benchmark.
What carries the argument
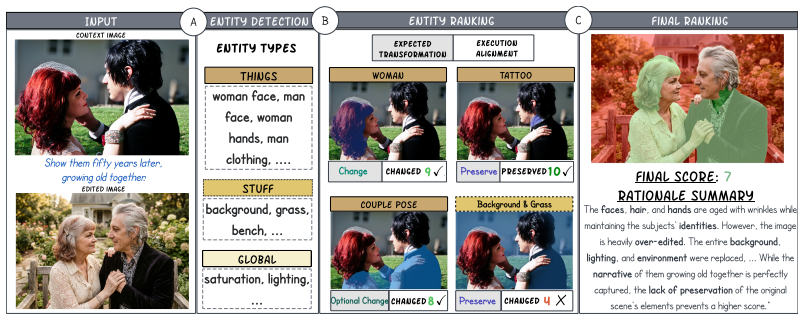
Entity-Rubrics, a framework that decomposes abstract edits into separate entity-level assessments to measure how well models follow the instruction.
If this is right
- Meaningful progress requires advanced LLM text encoders combined with iterative thinking.
- The entity-based paradigm can be reused as a reward model for training.
- Models can be guided to interpret abstract communication more reliably.
- The same breakdown can surface specific failure modes inside test-time critique loops.
Where Pith is reading between the lines
- The same entity decomposition could be used at training time rather than only at evaluation time.
- Taxonomies of abstract edits developed here may transfer to other multimodal generation tasks.
- Iterative refinement loops informed by entity rubrics could be tested on future model releases.
Load-bearing premise
Entity-level rubrics scores will match human judgments on whether an abstract edit was carried out correctly.
What would settle it
Collecting new human ratings on the AbstractEdit set and finding low correlation with the Entity-Rubrics scores would falsify the framework's validity.
Figures





















read the original abstract
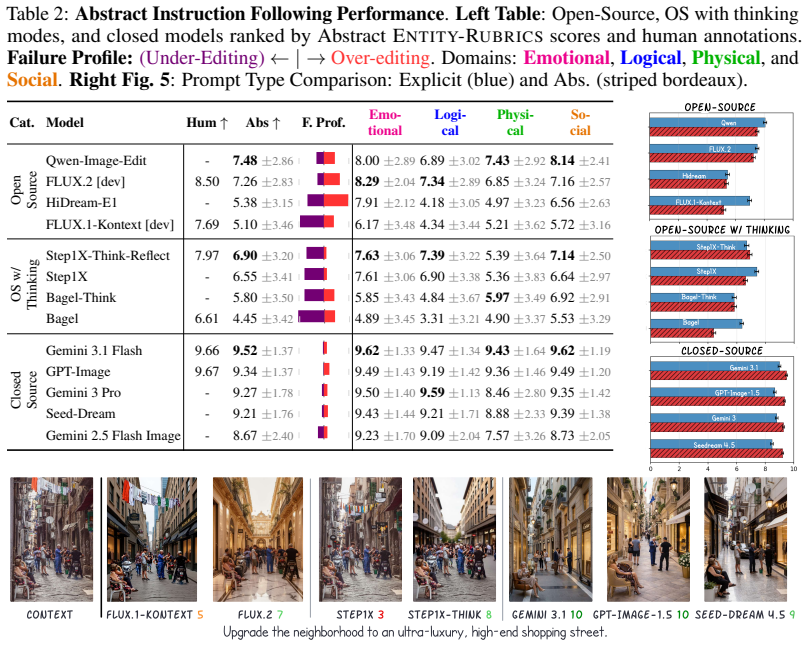
Humans naturally communicate through abstract concepts like "mood". However, current image editing benchmarks focus primarily on explicit, literal commands, leaving abstract instructions largely underexplored. In this work, we first formalize the definition and taxonomy of abstract image editing. To measure instruction-following in this challenging domain, we introduce Entity-Rubrics, a framework that breaks down abstract edits into individual, entity-level assessments and achieves strong correlation with human judgment. Alongside this framework, we contribute AbstractEdit, the first benchmark dedicated to abstract image editing across diverse real-world scenes. Evaluating 11 leading models on this dataset reveals a fundamental challenge: standard architectures struggle to balance intent and preservation, commonly defaulting to under-editing or over-editing. Our analysis demonstrates that driving meaningful improvements relies heavily on integrating advanced LLM text encoders and iterative thinking. Looking forward, our entity-based paradigm can generalize beyond assessment to serve as a reward model, enable models to correctly interpret abstract communication, or highlight specific failures in test-time critique loops. Ultimately, we hope this work serves as a stepping stone toward seamless multimodal interaction, closing the gap between rigid machine execution and the natural, open-ended way humans communicate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes a definition and taxonomy of abstract image editing, introduces the Entity-Rubrics framework that decomposes abstract edits into entity-level assessments and is claimed to achieve strong correlation with human judgment, contributes the AbstractEdit benchmark for diverse real-world scenes, and evaluates 11 leading models. It concludes that standard architectures struggle to balance intent and preservation (defaulting to under- or over-editing), that improvements depend on advanced LLM text encoders and iterative thinking, and that the entity-based paradigm can generalize to reward models or test-time critique.
Significance. If the Entity-Rubrics correlation and benchmark validity hold, the work addresses an underexplored gap between literal and abstract instruction following in image editing. A reliable entity-level scoring method could support more natural multimodal interaction and provide targeted diagnostics for model failures, with potential extension to training signals.
major comments (2)
- [Abstract] Abstract: the claim that Entity-Rubrics 'achieves strong correlation with human judgment' supplies no quantitative support (Pearson/Spearman coefficient, rater count, inter-rater agreement, or per-edit-type breakdown). This is load-bearing because the AbstractEdit benchmark's reliability and the subsequent model-performance conclusions rest on it.
- [Abstract] Abstract: the evaluation of 11 models and the claim that they 'commonly default to under-editing or over-editing' provides no protocol details, quantitative metrics, or dataset statistics. Without these, the central empirical finding cannot be assessed.
minor comments (1)
- [Abstract] Abstract: the taxonomy of abstract edits is referenced but not summarized; a brief enumeration of categories would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the abstract to include the requested quantitative details and protocol information.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Entity-Rubrics 'achieves strong correlation with human judgment' supplies no quantitative support (Pearson/Spearman coefficient, rater count, inter-rater agreement, or per-edit-type breakdown). This is load-bearing because the AbstractEdit benchmark's reliability and the subsequent model-performance conclusions rest on it.
Authors: We agree the abstract should be self-contained on this point. The full manuscript provides the quantitative support in Section 4 (Entity-Rubrics Evaluation), including Pearson/Spearman coefficients, rater count, inter-rater agreement, and per-edit-type breakdowns. We will revise the abstract to incorporate these key figures. revision: yes
-
Referee: [Abstract] Abstract: the evaluation of 11 models and the claim that they 'commonly default to under-editing or over-editing' provides no protocol details, quantitative metrics, or dataset statistics. Without these, the central empirical finding cannot be assessed.
Authors: The evaluation protocol for the 11 models, quantitative metrics (entity-level intent and preservation scores used to identify under/over-editing), and AbstractEdit dataset statistics are detailed in Sections 5 and 6. We will update the abstract with a concise summary of the protocol, metrics, and key statistics. revision: yes
Circularity Check
No circularity: new benchmark and framework introduced without self-referential derivations or fitted predictions
full rationale
The paper introduces Entity-Rubrics and AbstractEdit as new contributions for evaluating abstract image edits. The abstract and provided text contain no equations, no fitted parameters renamed as predictions, no self-citation chains justifying uniqueness theorems, and no ansatzes smuggled via prior work. The reported correlation with human judgment is presented as an empirical outcome of the new framework rather than defined in terms of itself or prior fitted values. The model evaluation results follow directly from applying the benchmark, with no reduction to inputs by construction. This is a standard empirical benchmark paper with independent content.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Blended diffusion for text-driven editing of natural images
Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18208–18218, 2022
2022
-
[2]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023
2023
-
[3]
Make it count: Text-to-image generation with an accurate number of objects
Lital Binyamin, Yoad Tewel, Hilit Segev, Eran Hirsch, Royi Rassin, and Gal Chechik. Make it count: Text-to-image generation with an accurate number of objects. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13242–13251, 2025
2025
-
[4]
FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison, 2025
Black Forest Labs. FLUX.2: Analyzing and enhancing the latent space of FLUX – representation comparison, 2025
2025
-
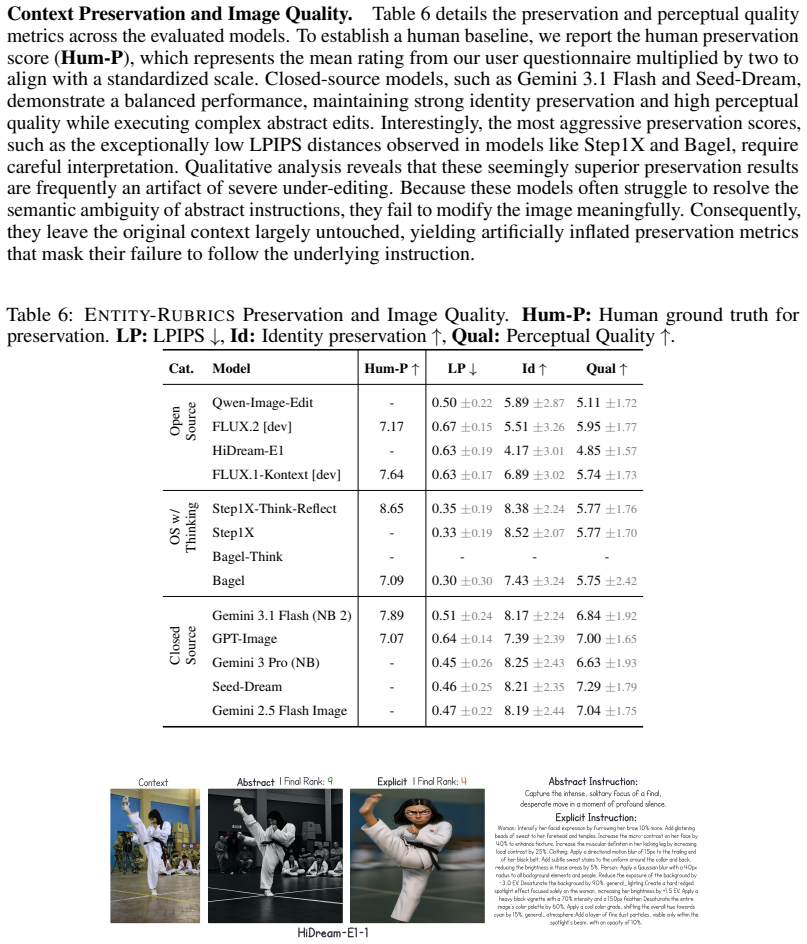
[5]
A large annotated corpus for learning natural language inference
Samuel Bowman, Gabor Angeli, Christopher Potts, and Christopher D Manning. A large annotated corpus for learning natural language inference. InProceedings of the 2015 conference on empirical methods in natural language processing, pages 632–642, 2015
2015
-
[6]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[7]
Coco-stuff: Thing and stuff classes in context
Holger Caesar, Jasper Uijlings, and Vittorio Ferrari. Coco-stuff: Thing and stuff classes in context. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1209–1218, 2018
2018
-
[8]
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zhang, Fengbin Gao, Peihan Xu, et al. Hidream-i1: A high-efficient image generative foundation model with sparse diffusion transformer.arXiv preprint arXiv:2505.22705, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
I Chern, Steffi Chern, Shiqi Chen, Weizhe Yuan, Kehua Feng, Chunting Zhou, Junxian He, Gra- ham Neubig, Pengfei Liu, et al. Factool: Factuality detection in generative ai–a tool augmented framework for multi-task and multi-domain scenarios.arXiv preprint arXiv:2307.13528, 2023
-
[10]
Grounding in communication
Herbert H Clark and Susan E Brennan. Grounding in communication. 1991
1991
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Be decisive: Noise-induced layouts for multi-subject generation
Omer Dahary, Yehonathan Cohen, Or Patashnik, Kfir Aberman, and Daniel Cohen-Or. Be decisive: Noise-induced layouts for multi-subject generation. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–12, 2025
2025
-
[13]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Rongyao Fang, Chengqi Duan, Kun Wang, Linjiang Huang, Hao Li, Shilin Yan, Hao Tian, Xingyu Zeng, Rui Zhao, Jifeng Dai, et al. Got: Unleashing reasoning capability of multimodal large language model for visual generation and editing.arXiv preprint arXiv:2503.10639, 2025
-
[15]
Dan Friedman and Adji Bousso Dieng. The vendi score: A diversity evaluation metric for machine learning.arXiv preprint arXiv:2210.02410, 2022
-
[16]
Tsu-Jui Fu, Wenze Hu, Xianzhi Du, William Yang Wang, Yinfei Yang, and Zhe Gan. Guid- ing instruction-based image editing via multimodal large language models.arXiv preprint arXiv:2309.17102, 2023
-
[17]
MIT press, 2004
Peter Gardenfors.Conceptual spaces: The geometry of thought. MIT press, 2004
2004
-
[18]
Zorik Gekhman, Jonathan Herzig, Roee Aharoni, Chen Elkind, and Idan Szpektor. Trueteacher: Learning factual consistency evaluation with large language models.arXiv preprint arXiv:2305.11171, 2023
-
[19]
Image generation with Gemini | Gemini API | Google AI for developers
Google DeepMind. Image generation with Gemini | Gemini API | Google AI for developers. Online Documentation, 2026. Accessed: April 6, 2026
2026
-
[20]
Gemini API documentation: Image generation and editing
Google Developers. Gemini API documentation: Image generation and editing. https: //ai.google.dev/gemini-api/docs/image-generation#gemini-image-editing ,
-
[21]
Accessed: April 18, 2026
2026
-
[22]
Logic and conversation
Herbert P Grice. Logic and conversation. InSpeech acts, pages 41–58. Brill, 1975
1975
-
[23]
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Qingdong He, Xueqin Chen, Chaoyi Wang, Yanjie Pan, Xiaobin Hu, Zhenye Gan, Yabiao Wang, Chengjie Wang, Xiangtai Li, and Jiangning Zhang. Reasoning to edit: Hypothetical instruction-based image editing with visual reasoning.arXiv preprint arXiv:2507.01908, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
True: Re- evaluating factual consistency evaluation.arXiv preprint arXiv:2204.04991, 2022
Or Honovich, Roee Aharoni, Jonathan Herzig, Hagai Taitelbaum, Doron Kukliansy, Vered Cohen, Thomas Scialom, Idan Szpektor, Avinatan Hassidim, and Yossi Matias. True: Re- evaluating factual consistency evaluation.arXiv preprint arXiv:2204.04991, 2022
-
[25]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023
2023
-
[26]
Smartedit: Exploring complex instruction- based image editing with multimodal large language models
Yuzhou Huang, Liangbin Xie, Xintao Wang, Ziyang Yuan, Xiaodong Cun, Yixiao Ge, Jiantao Zhou, Chao Dong, Rui Huang, Ruimao Zhang, et al. Smartedit: Exploring complex instruction- based image editing with multimodal large language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8362–8371, 2024
2024
-
[27]
Ekaterina Iakovleva, Fabio Pizzati, Philip Torr, and Stéphane Lathuilière. Specify and edit: Overcoming ambiguity in text-based image editing.arXiv preprint arXiv:2407.20232, 2024
-
[28]
Visual style prompting with swapping self-attention.arXiv preprint arXiv:2402.12974, 2024
Jaeseok Jeong, Junho Kim, Yunjey Choi, Gayoung Lee, and Youngjung Uh. Visual style prompting with swapping self-attention.arXiv preprint arXiv:2402.12974, 2024
-
[29]
Instruction-based image editing with planning, reasoning, and generation
Liya Ji, Chenyang Qi, and Qifeng Chen. Instruction-based image editing with planning, reasoning, and generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17506–17515, 2025. 11
2025
-
[30]
Bohan Jia, Wenxuan Huang, Yuntian Tang, Junbo Qiao, Jincheng Liao, Shaosheng Cao, Fei Zhao, Zhaopeng Feng, Zhouhong Gu, Zhenfei Yin, et al. Compbench: Benchmarking complex instruction-guided image editing.arXiv preprint arXiv:2505.12200, 2025
-
[31]
Iterative multi-granular image editing using diffusion models
KJ Joseph, Prateksha Udhayanan, Tripti Shukla, Aishwarya Agarwal, Srikrishna Karanam, Koustava Goswami, and Balaji Vasan Srinivasan. Iterative multi-granular image editing using diffusion models. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 8107–8116, 2024
2024
-
[32]
Routledge, 2020
Gunther Kress and Theo Van Leeuwen.Reading images: The grammar of visual design. Routledge, 2020
2020
-
[33]
Evaluating the factual consistency of abstractive text summarization
Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the factual consistency of abstractive text summarization. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 9332–9346, Online, November 2020. Association for Co...
2020
-
[34]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12268–12290, 2024
2024
-
[35]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.International journal of computer vision, 128(7):1956–1981, 2020
1956
-
[36]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Editthinker: Unlocking iterative reasoning for any image editor
Hongyu Li, Manyuan Zhang, Dian Zheng, Ziyu Guo, Yimeng Jia, Kaituo Feng, Hao Yu, Yexin Liu, Yan Feng, Peng Pei, et al. Editthinker: Unlocking iterative reasoning for any image editor. arXiv preprint arXiv:2512.05965, 2025
-
[38]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Yuhui Zhang, Yongchan Kwon, Serena Yeung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems, 35:17612–17625, 2022
2022
-
[39]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[40]
Step1X-Edit: A Practical Framework for General Image Editing
Shiyu Liu, Yucheng Han, Peng Xing, Fukun Yin, Rui Wang, Wei Cheng, Jiaqi Liao, Yingming Wang, Honghao Fu, Chunrui Han, et al. Step1x-edit: A practical framework for general image editing.arXiv preprint arXiv:2504.17761, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Design guidelines for prompt engineering text-to-image generative models
Vivian Liu and Lydia B Chilton. Design guidelines for prompt engineering text-to-image generative models. InProceedings of the 2022 CHI conference on human factors in computing systems, pages 1–23, 2022
2022
-
[42]
I2ebench: A comprehensive benchmark for instruction-based image editing.Advances in Neural Information Processing Systems, 37:41494–41516, 2024
Yiwei Ma, Jiayi Ji, Ke Ye, Weihuang Lin, Zhibin Wang, Yonghan Zheng, Qiang Zhou, Xiaoshuai Sun, and Rongrong Ji. I2ebench: A comprehensive benchmark for instruction-based image editing.Advances in Neural Information Processing Systems, 37:41494–41516, 2024
2024
-
[43]
On faithfulness and factuality in abstractive summarization
Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 1906–1919, 2020. 12
1906
-
[44]
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12076–12100, 2023
2023
-
[45]
Some observations on mental models
Donald A Norman. Some observations on mental models. InMental models, pages 7–14. Psychology Press, 2014
2014
-
[46]
GPT-Image-1.5 Model Documentation
OpenAI.Image generation, December 2025. GPT-Image-1.5 Model Documentation
2025
-
[47]
A taxonomy of prompt modifiers for text-to-image generation.Behaviour & Information Technology, 43(15):3763–3776, 2024
Jonas Oppenlaender. A taxonomy of prompt modifiers for text-to-image generation.Behaviour & Information Technology, 43(15):3763–3776, 2024
2024
-
[48]
Yuandong Pu, Le Zhuo, Songhao Han, Jinbo Xing, Kaiwen Zhu, Shuo Cao, Bin Fu, Si Liu, Hongsheng Li, Yu Qiao, et al. Picabench: How far are we from physically realistic image editing?arXiv preprint arXiv:2510.17681, 2025
-
[49]
Yusu Qian, Eli Bocek-Rivele, Liangchen Song, Jialing Tong, Yinfei Yang, Jiasen Lu, Wenze Hu, and Zhe Gan. Pico-banana-400k: A large-scale dataset for text-guided image editing.arXiv preprint arXiv:2510.19808, 2025
-
[50]
Yusu Qian, Jiasen Lu, Tsu-Jui Fu, Xinze Wang, Chen Chen, Yinfei Yang, Wenze Hu, and Zhe Gan. Gie-bench: Towards grounded evaluation for text-guided image editing.arXiv preprint arXiv:2505.11493, 2025
-
[51]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[52]
Seedream 4.0: Toward Next-generation Multimodal Image Generation
Team Seedream, Yunpeng Chen, Yu Gao, Lixue Gong, Meng Guo, Qiushan Guo, Zhiyao Guo, Xiaoxia Hou, Weilin Huang, Yixuan Huang, et al. Seedream 4.0: Toward next-generation multimodal image generation, 2025.URL https://arxiv. org/abs/2509.20427, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
Emu edit: Precise image editing via recognition and generation tasks
Shelly Sheynin, Adam Polyak, Uriel Singer, Yuval Kirstain, Amit Zohar, Oron Ashual, Devi Parikh, and Yaniv Taigman. Emu edit: Precise image editing via recognition and generation tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8871–8879, 2024
2024
-
[54]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Yoad Tewel, Rinon Gal, Dvir Samuel, Yuval Atzmon, Lior Wolf, and Gal Chechik. Add- it: Training-free object insertion in images with pretrained diffusion models.arXiv preprint arXiv:2411.07232, 2024
-
[56]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022
2022
-
[57]
Omnistyle: Filtering high quality style transfer data at scale
Ye Wang, Ruiqi Liu, Jiang Lin, Fei Liu, Zili Yi, Yilin Wang, and Rui Ma. Omnistyle: Filtering high quality style transfer data at scale. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7847–7856, 2025
2025
-
[58]
Yuhan Wang, Siwei Yang, Bingchen Zhao, Letian Zhang, Qing Liu, Yuyin Zhou, and Cihang Xie. Gpt-image-edit-1.5 m: A million-scale, gpt-generated image dataset.arXiv preprint arXiv:2507.21033, 2025
-
[59]
Genartist: Multimodal llm as an agent for unified image generation and editing.Advances in Neural Information Processing Systems, 37:128374–128395, 2024
Zhenyu Wang, Aoxue Li, Zhenguo Li, and Xihui Liu. Genartist: Multimodal llm as an agent for unified image generation and editing.Advances in Neural Information Processing Systems, 37:128374–128395, 2024. 13
2024
-
[60]
Long-form factuality in large language models.Advances in Neural Information Processing Systems, 37:80756–80827, 2024
Jerry Wei, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, Daiyi Peng, Ruibo Liu, Da Huang, et al. Long-form factuality in large language models.Advances in Neural Information Processing Systems, 37:80756–80827, 2024
2024
-
[61]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
2025
-
[62]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-image technical report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Complex- edit: Cot-like instruction generation for complexity-controllable image editing benchmark
Siwei Yang, Mude Hui, Bingchen Zhao, Yuyin Zhou, Nataniel Ruiz, and Cihang Xie. Complex- edit: Cot-like instruction generation for complexity-controllable image editing benchmark. arXiv preprint arXiv:2504.13143, 2025
-
[64]
Mingde Yao, Zhiyuan You, King-Man Tam, Menglu Wang, and Tianfan Xue. Photoagent: Agen- tic photo editing with exploratory visual aesthetic planning.arXiv preprint arXiv:2602.22809, 2026
-
[65]
Chun-Hsiao Yeh, Yilin Wang, Nanxuan Zhao, Richard Zhang, Yuheng Li, Yi Ma, and Kr- ishna Kumar Singh. Beyond simple edits: X-planner for complex instruction-based image editing.arXiv preprint arXiv:2507.05259, 2025
-
[66]
Anyedit: Mastering unified high-quality image editing for any idea
Qifan Yu, Wei Chow, Zhongqi Yue, Kaihang Pan, Yang Wu, Xiaoyang Wan, Juncheng Li, Siliang Tang, Hanwang Zhang, and Yueting Zhuang. Anyedit: Mastering unified high-quality image editing for any idea. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26125–26135, 2025
2025
-
[67]
Flexedit: Marrying free-shape masks to vllm for flexible image editing
Tianshuo Yuan, Yuxiang Lin, Jue Wang, Zhi-Qi Cheng, Xiaolong Wang, Jiao GH, Wei Chen, and Xiaojiang Peng. Flexedit: Marrying free-shape masks to vllm for flexible image editing. arXiv preprint arXiv:2408.12429, 2024
-
[68]
Why johnny can’t prompt: how non-ai experts try (and fail) to design llm prompts
J Diego Zamfirescu-Pereira, Richmond Y Wong, Bjoern Hartmann, and Qian Yang. Why johnny can’t prompt: how non-ai experts try (and fail) to design llm prompts. InProceedings of the 2023 CHI conference on human factors in computing systems, pages 1–21, 2023
2023
-
[69]
Editworld: Simulating world dynamics for instruction-following image editing
Bohan Zeng, Ling Yang, Jiaming Liu, Minghao Xu, Yuanxing Zhang, Pengfei Wan, Wentao Zhang, and Shuicheng Yan. Editworld: Simulating world dynamics for instruction-following image editing. InProceedings of the 33rd ACM International Conference on Multimedia, pages 12674–12681, 2025
2025
-
[70]
Huixuan Zhang and Xiaojun Wan. Re-thinking the automatic evaluation of image-text alignment in text-to-image models.arXiv preprint arXiv:2506.08480, 2025
-
[71]
Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
2023
-
[72]
make it more formal
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 14 Appendix Limitations While our dataset and evaluation framework provide a robust foundation for eval...
2018
-
[73]
This defines the overall ’vibe’ of the edit
**Create an Abstract Prompt (The "What")**: Write a new, creative, and high-level prompt inspired by the category’s theme. This defines the overall ’vibe’ of the edit. The instruction must be open to interpretation in terms of How exactly to achieve it, I.e, different people will interpret it differently
-
[74]
**Probablity Sampling**: Ensure that each generated response is sampled randomly from the distribution
-
[75]
Increase roughness to 80%,
**Define Entity-Specific Edits (The "How")**: - **Discovery**: Actively identify more relevant entities in the image or context that were not provided in the {entities} list. Include them in your explicit list. For each relevant ‘Image Entity‘, determine its role in the edit. This is the technical process. It is precise, measurable, and leaves no room for...
-
[76]
This applies to the entire scene
**Define a General Instruction**: Write instructions that describes any global changes to the image’s overall e.g., style, lighting, mood, or color palette. This applies to the entire scene
-
[77]
Place a [Object] 10cm to the left of [Entity] at a 30-degree angle
**Insertion/Removal Entities**: You may suggest new entities to be inserted in the image to better align with the abstract prompt as an explicit instruction specifying the entity and its placement. These should be realistic and contextually appropriate. If no insertions/removals are needed, leave this blank. For each insertion, you MUST provide coordinate...
-
[78]
thinking
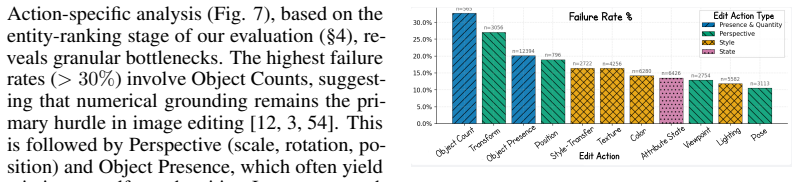
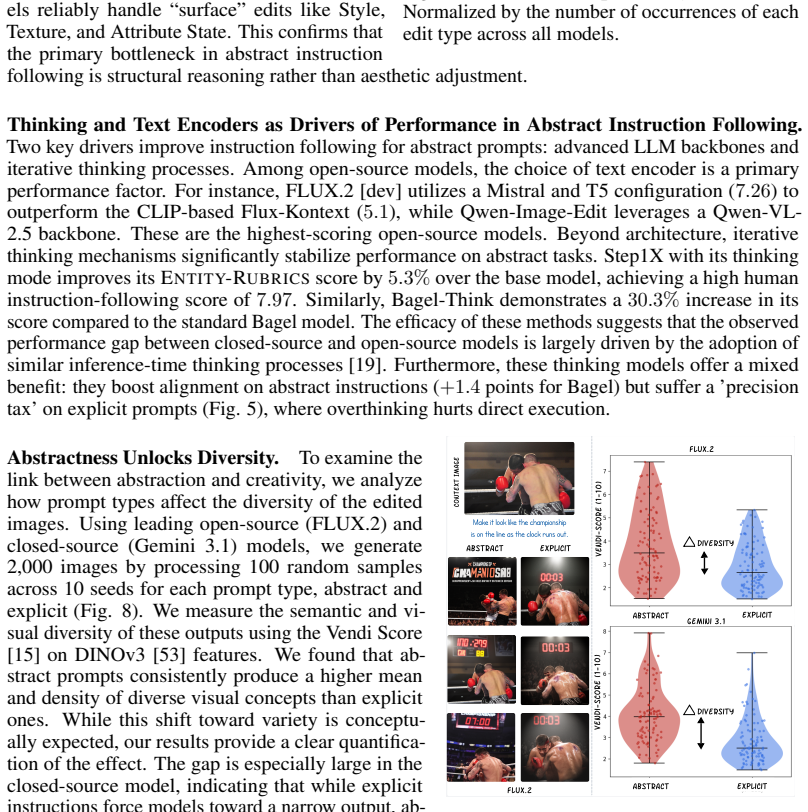
and perceptual similarity to the context image (LPIPS [71]). Table 4: Architecture Summary of Baseline Image Editing Models. DiT notes Diffusion-Transformer. ✓and✗denote the presence or absence of a dedicated thinking mode, respectively. Category Model Company Text-Encoder Image Generator Size/Params Thinking Flux-Kontext [dev] Black Forest Labs CLIP + T5...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.