Successive convex optimization for transformer encoder model predictive control
Pith reviewed 2026-06-30 20:07 UTC · model grok-4.3
The pith
Deriving difference-of-convex forms for transformer encoders allows successive convex programming to guarantee feasible and convergent solutions for nonconvex model predictive control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors derive difference of convex representations of the transformer encoder components and embed them in a successive convex programming iteration. This ensures recursive feasibility and convergence of the SCP iterates, with each iterate yielding a feasible solution estimate. Under mild assumptions, the iteration converges to a locally optimal solution of the MPC problem.
What carries the argument
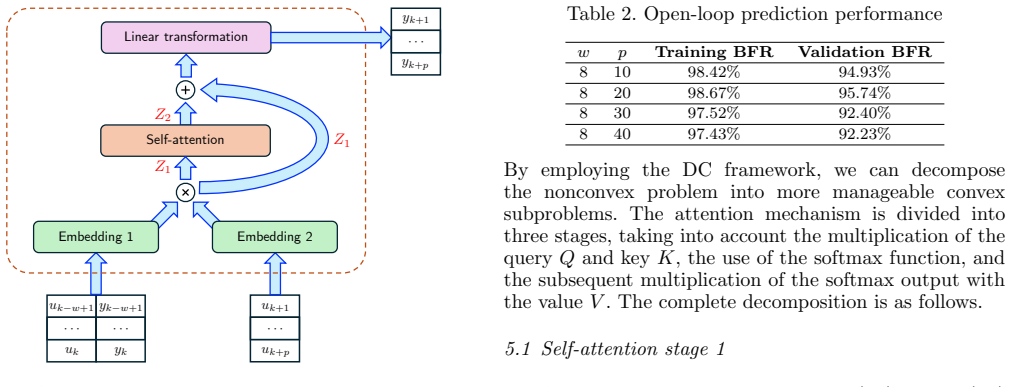
Successive convex programming iteration using difference-of-convex representations of the transformer encoder components including the attention mechanism
If this is right
- Recursive feasibility is guaranteed for the MPC problem.
- The SCP iterates converge to a locally optimal solution under mild assumptions.
- Each iterate satisfies the problem constraints.
- The framework applies to data-driven predictions from transformer encoders in control.
Where Pith is reading between the lines
- Similar DC representations might be derivable for other neural architectures used in prediction.
- The method could be extended to handle uncertainty in the transformer predictions within the MPC framework.
- It opens the possibility of using transformer models in safety-critical control applications where feasibility must be maintained.
Load-bearing premise
Difference-of-convex representations of the transformer encoder components can be derived and embedded into the SCP iteration without introducing additional approximation error that invalidates the feasibility or convergence claims.
What would settle it
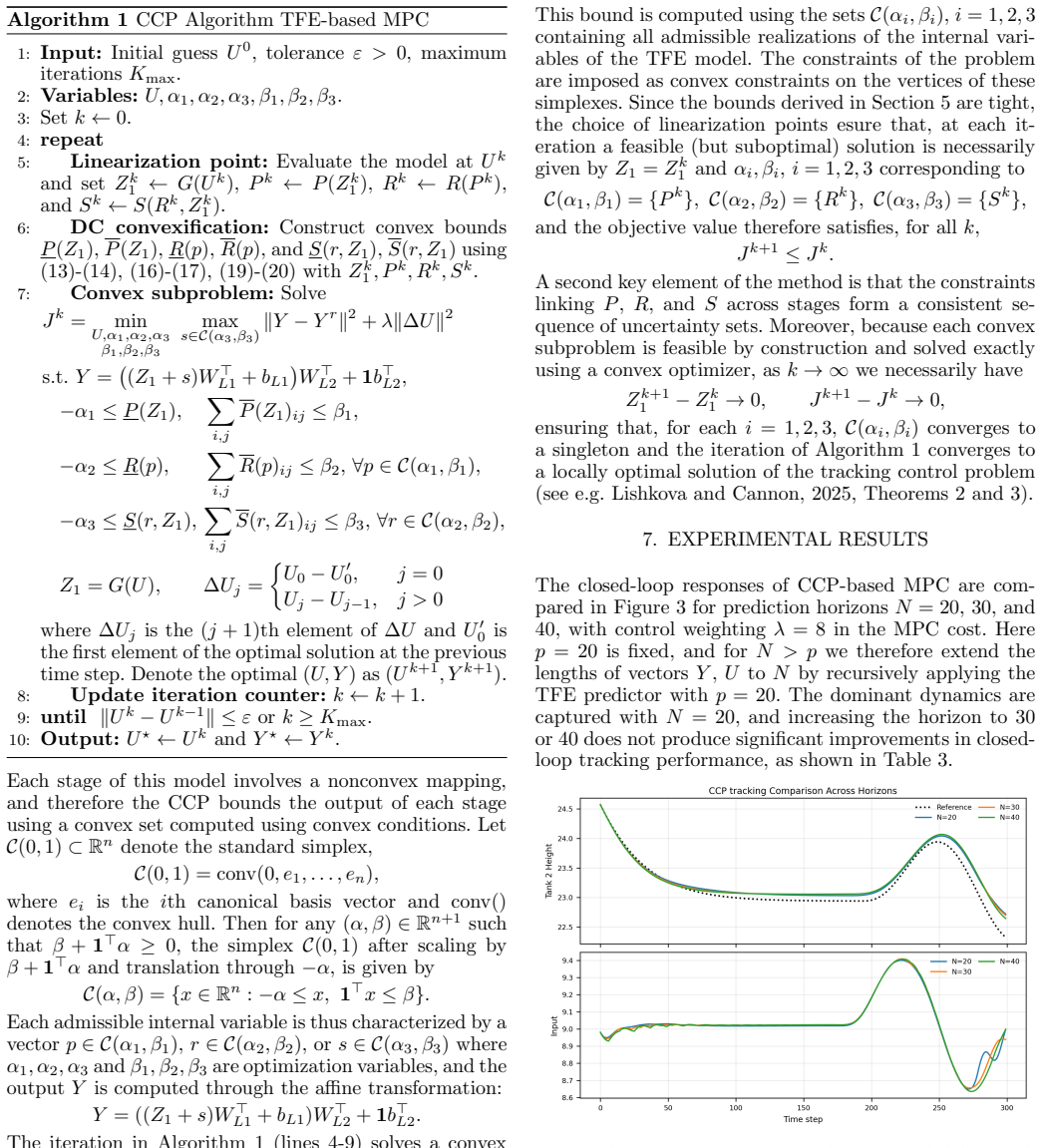
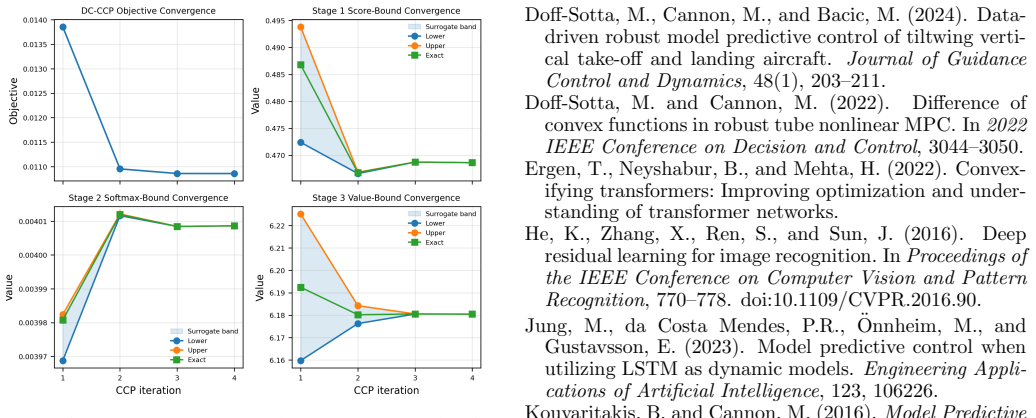
Observing whether the SCP iterates on the benchmark nonlinear control problem remain feasible and whether their costs converge to a stationary value when the derived DC representations are used.
Figures

read the original abstract
We propose a data-driven Model Predictive Control (MPC) framework that employs a transformer encoder to generate multi-step predictions. To handle the nonconvex attention mechanism, we derive difference of convex (DC) representations of the transformer encoder components and embed them in a successive convex programming (SCP) iteration. Recursive feasibility and convergence of the SCP iterates are guaranteed, and each iterate yields a solution estimate satisfying the problem constraints. Under mild assumptions, the SCP iteration converges to a locally optimal solution of the MPC problem. The approach is illustrated on a benchmark nonlinear control problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a data-driven MPC framework that uses a transformer encoder for multi-step predictions. Nonconvex components, particularly the attention mechanism, are handled by deriving DC representations that are embedded into an SCP iteration. The authors claim that this construction guarantees recursive feasibility, that each SCP iterate satisfies the original constraints, and that the iterates converge to a locally optimal solution of the MPC problem under mild assumptions. The method is illustrated on a benchmark nonlinear control problem.
Significance. If the DC representations of the transformer encoder (including attention) are exact and the feasibility/convergence proofs transfer without hidden approximation error, the work would offer a principled way to incorporate expressive but nonconvex learned predictors into MPC while retaining theoretical guarantees. This could be relevant for data-driven control applications where transformer-based models are attractive but their nonconvexity has previously precluded rigorous recursive-feasibility arguments.
major comments (2)
- [Abstract / DC derivation section] Abstract and the section deriving the DC representations of the transformer encoder: the central claim requires that the attention map (softmax(QK^T / sqrt(d)) V) admits an exact DC decomposition f = g - h (g, h convex) that holds with equality for all inputs in the operating domain. If the derivation instead produces a surrogate or domain-restricted form, the SCP subproblems solved at each iteration are no longer equivalent to the stated MPC, so the recursive-feasibility and convergence statements do not carry over to the original problem.
- [SCP iteration and feasibility theorem] The section stating the SCP iteration and the recursive-feasibility theorem: the proof that each iterate remains feasible for the original (nonconvex) MPC constraints relies on the embedded DC program being identical to the true problem. The manuscript must explicitly verify that no additional approximation error is introduced by the DC embedding; otherwise the feasibility claim is not supported.
minor comments (1)
- [Notation / early sections] Notation for the transformer dimensions (d, number of heads, sequence length) should be introduced once and used consistently; several symbols appear without prior definition in the abstract and early sections.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the emphasis placed on the exactness of the DC embeddings, which is indeed central to transferring the theoretical guarantees. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / DC derivation section] Abstract and the section deriving the DC representations of the transformer encoder: the central claim requires that the attention map (softmax(QK^T / sqrt(d)) V) admits an exact DC decomposition f = g - h (g, h convex) that holds with equality for all inputs in the operating domain. If the derivation instead produces a surrogate or domain-restricted form, the SCP subproblems solved at each iteration are no longer equivalent to the stated MPC, so the recursive-feasibility and convergence statements do not carry over to the original problem.
Authors: The DC decomposition of the attention map (and the remaining transformer-encoder blocks) is constructed to be exact and to hold with equality for every input inside the operating domain used by the MPC. Section 3 derives convex g and h such that the attention output equals g - h identically on that domain; the construction exploits the DC structure of the scaled dot-product and the softmax without introducing surrogates or additional restrictions beyond the natural boundedness of the state and input trajectories. Consequently the SCP subproblems remain equivalent to the original nonconvex MPC, and the recursive-feasibility and convergence claims apply directly. revision: no
-
Referee: [SCP iteration and feasibility theorem] The section stating the SCP iteration and the recursive-feasibility theorem: the proof that each iterate remains feasible for the original (nonconvex) MPC constraints relies on the embedded DC program being identical to the true problem. The manuscript must explicitly verify that no additional approximation error is introduced by the DC embedding; otherwise the feasibility claim is not supported.
Authors: The identity between the DC program and the original problem follows immediately from the exact decomposition established in Section 3. To make this link fully explicit, we will insert a short clarifying paragraph immediately before the statement of the recursive-feasibility theorem that recalls the equality g - h = attention output and states that therefore no approximation error enters the embedded constraints. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper's central claims rest on deriving exact DC representations for the transformer encoder (including attention) and then applying standard SCP convergence results to the resulting DC program. The abstract and description present the feasibility and local optimality guarantees as following directly from the SCP iteration under the stated mild assumptions, without any reduction of the target MPC solution to a fitted parameter, self-citation chain, or renamed input. No load-bearing step is shown to be equivalent to its own inputs by construction; the DC embedding is presented as an independent modeling step whose exactness is asserted rather than derived from the convergence claim itself. This is the normal case of a self-contained derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Awasthi, P., Mao, A., Mohri, M., and Zhong, Y. (2024). Dc-programming for neural network optimizations. Journal of Global Optimization, 1–17
2024
-
[2]
Doff-Sotta, M., Cannon, M., and Bacic, M. (2024). Data- driven robust model predictive control of tiltwing verti- cal take-off and landing aircraft.Journal of Guidance Control and Dynamics, 48(1), 203–211
2024
-
[3]
and Cannon, M
Doff-Sotta, M. and Cannon, M. (2022). Difference of convex functions in robust tube nonlinear MPC. In2022 IEEE Conference on Decision and Control, 3044–3050
2022
-
[4]
Ergen, T., Neyshabur, B., and Mehta, H. (2022). Convex- ifying transformers: Improving optimization and under- standing of transformer networks
2022
-
[5]
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778. doi:10.1109/CVPR.2016.90
-
[6]
Gustavsson, E. (2023). Model predictive control when utilizing LSTM as dynamic models.Engineering Appli- cations of Artificial Intelligence, 123, 106226
2023
-
[7]
and Cannon, M
Kouvaritakis, B. and Cannon, M. (2016).Model Predictive Control. Springer, Switzerland
2016
-
[8]
Krausch, N., Doff-Sotta, M., Cannon, M., Neubauer, P., and Cruz Bournazou, M. (2025). Deep learning adaptive Model Predictive Control of Fed-Batch Cultivations. Computers and Chemical Engineering, 203, 109344
2025
-
[9]
and Boyd, S
Lipp, T. and Boyd, S. (2016). Variations and extensions of the convex–concave procedure.Optimization and Engineering, 17(2), 263–287
2016
-
[10]
and Cannon, M
Lishkova, Y. and Cannon, M. (2025). A successive convex- ification approach for robust receding horizon control. IEEE Trans. Autom. Control, 70(10), 6436–6448
2025
-
[11]
Machalek, D., Tuttle, J., Andersson, K., and Powell, K.M. (2022). Dynamic energy system modeling using hybrid physics-based and machine learning encoder–decoder models.Energy and AI, 9, 100172
2022
-
[12]
and Bemporad, A
Masti, D. and Bemporad, A. (2021). Learning nonlinear state–space models using autoencoders.Automatica, 129, 109666. MOSEK ApS (2025).The MOSEK Python Fusion API manual. Version 11.0
2021
-
[13]
and Wright, S
Nocedal, J. and Wright, S. (2006).Numerical Optimiza- tion. Springer, New York, USA, 2nd edition
2006
-
[14]
Norouzi, A., Heidarifar, H., Borhan, H., Shahbakhti, M., and Koch, C.R. (2023). Integrating machine learning and model predictive control for automotive applica- tions: A review and future directions.Engineering Ap- plications of Artificial Intelligence, 120, 105878
2023
-
[15]
Hedengren, J.D. (2023). Simultaneous multistep trans- former architecture for model predictive control.Com- puters and Chemical Engineering, 178, 108396
2023
-
[16]
(2017).Model Predictive Control: Theory, Computation, and Design
Rawlings, J.B., Mayne, D.Q., and Diehl, M. (2017).Model Predictive Control: Theory, Computation, and Design. Nob Hill Publishing, LLC, Madison, WI, 2nd edition
2017
-
[17]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., and Polosukhin, I. (2017). Attention is all you need. In31st Conference on Neural Information Processing Systems (NIPS), 6000–6010
2017
-
[18]
Wong, W.C., Li, J., and Wang, X. (2018). Recurrent neural network-based model predictive control for continuous pharmaceutical manufacturing
2018
-
[19]
and Lawry´ nczuk, M
Zarzycki, K. and Lawry´ nczuk, M. (2022). Advanced pre- dictive control for GRU and LSTM networks.Informa- tion Sciences, 616, 229–254
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.