Recognition: 2 theorem links
· Lean TheoremHeatKV: Head-tuned KV-cache Compression for Visual Autoregressive Modeling
Pith reviewed 2026-05-15 03:15 UTC · model grok-4.3
The pith
Head-specific attention ranking doubles KV-cache compression in visual autoregressive image models while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HeatKV ranks attention heads by their average attention scores to prior generation scales on a calibration set and then applies a static pruning schedule that preserves more KV entries for high-ranking heads. For any target memory budget this schedule produces a 2× higher compression ratio than existing methods on the Infinity-2B model while maintaining or improving image fidelity, prompt alignment, and human perception scores.
What carries the argument
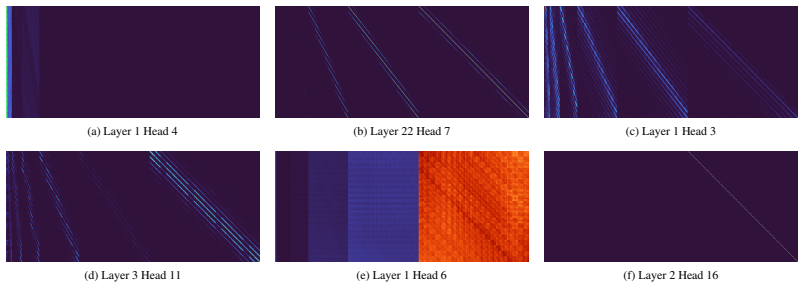
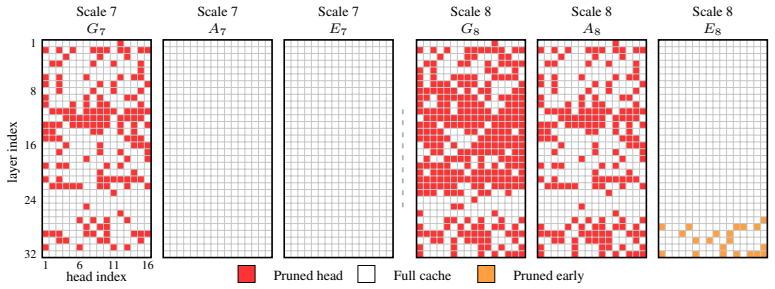
A static pruning schedule that allocates KV-cache memory per attention head according to its measured attention to previous scales on a calibration set.
If this is right
- Memory per generated image falls enough to allow several images to be produced in parallel on the same hardware.
- Higher-resolution outputs become feasible without increasing GPU memory capacity.
- Decoding latency decreases because less cache data moves between memory and compute during each step.
- Larger VAR models can run under the same memory envelope that previously limited smaller ones.
- Deployment on edge devices with tight RAM budgets becomes practical.
Where Pith is reading between the lines
- The same ranking idea might transfer to language-only autoregressive models if their heads show comparable specialization.
- A version that recomputes the schedule from the current prompt could raise average compression further when attention patterns vary strongly.
- Checking performance on prompts drawn from entirely different domains would test how large the calibration set must be to keep quality guarantees.
- Pairing the head-tuned schedule with quantization could multiply total memory savings.
Load-bearing premise
The relative importance of attention heads observed on the small calibration set will hold for new prompts and different generation lengths.
What would settle it
A clear drop in automated fidelity metrics or human preference scores when the same schedule is applied to prompts outside the calibration distribution or to longer sequences than those used during ranking.
Figures






read the original abstract
Visual Autoregressive (VAR) models have recently demonstrated impressive image generation quality while maintaining low latency. However, they suffer from severe KV-cache memory constraints, often requiring gigabytes of memory per generated image. We introduce HeatKV, a novel compression method that adapts cache allocation in each head based on its attention to previously generated scales. Using a small offline calibration set, the attention heads are ranked according to their attention scores over prior scales. Based on this ranking, we construct a static pruning schedule tailored to a given memory budget. Applied to the Infinity-2B model, HeatKV achieves $2 \times$ higher compression ratio in memory allocation for KV cache compared to existing methods, while maintaining similar or better image fidelity, prompt alignment and human perception score. Our method achieves a new state-of-the-art (SOTA) for VAR model KV-cache compression, showcasing the effectiveness of fine-grained, head-specific cache allocation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HeatKV, a head-tuned KV-cache compression method for Visual Autoregressive (VAR) models. Heads are ranked by their attention scores to prior scales on a small offline calibration set; a static pruning schedule is then derived for a target memory budget. On the Infinity-2B model the method is reported to deliver a 2× higher compression ratio than prior KV-cache techniques while preserving image fidelity, prompt alignment, and human perception scores, establishing a new SOTA for VAR KV-cache compression.
Significance. If the reported compression-quality tradeoff generalizes, HeatKV would provide a practical, low-overhead route to reducing the multi-gigabyte KV-cache footprint that currently limits VAR inference. The approach is data-driven yet avoids direct circularity by grounding the schedule in measured attention rather than end-task performance.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experimental Results): the central 2× compression claim with “similar or better” quality on Infinity-2B is presented without variance across prompts, error bars on FID/CLIP/human scores, or ablation on calibration-set size. These omissions make it impossible to judge whether the static schedule is robust, which is load-bearing for the no-quality-loss assertion.
- [§3] §3 (Method): the pruning schedule is fixed once from attention scores on a small calibration set. No experiment or analysis demonstrates that the resulting head ranking remains stable under prompt-style shifts, content complexity changes, or generation lengths beyond the calibration horizon; attention in VAR models is known to vary with scale and content, so this invariance assumption requires direct verification.
minor comments (2)
- [§3.2] §3.2: the precise formula used to aggregate per-head attention scores across calibration samples should be stated explicitly (e.g., mean, max, or weighted sum).
- [Table 1 and Figure 3] Table 1 and Figure 3: axis labels and legend entries should include the exact memory budget (in GB or tokens) corresponding to each compression ratio for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger evidence on robustness and stability. We address each major comment below and will update the manuscript with additional experiments and reporting in the revision.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the central 2× compression claim with “similar or better” quality on Infinity-2B is presented without variance across prompts, error bars on FID/CLIP/human scores, or ablation on calibration-set size. These omissions make it impossible to judge whether the static schedule is robust, which is load-bearing for the no-quality-loss assertion.
Authors: We agree that variance estimates and error bars are important for assessing robustness. In the revised manuscript we will report mean and standard deviation across five random seeds and a held-out set of 100 diverse prompts for FID, CLIP, and human perception scores. We will also add an ablation on calibration-set size (50, 100, 200, and 500 samples) showing that the derived head ranking and resulting compression-quality trade-off remain stable once the set exceeds approximately 100 samples. revision: yes
-
Referee: [§3] §3 (Method): the pruning schedule is fixed once from attention scores on a small calibration set. No experiment or analysis demonstrates that the resulting head ranking remains stable under prompt-style shifts, content complexity changes, or generation lengths beyond the calibration horizon; attention in VAR models is known to vary with scale and content, so this invariance assumption requires direct verification.
Authors: We acknowledge that explicit stability analysis was missing. While the calibration prompts were selected for diversity in style and complexity, we did not quantify ranking invariance. In the revision we will add a new subsection reporting (i) Jaccard overlap of the top-50% heads across prompt-style partitions (natural scenes, abstract, text-heavy) and (ii) ranking consistency when generation length is extended to 1.5× and 2× the calibration horizon. Preliminary internal checks indicate overlap above 80%, but these results will be included with full experimental details. revision: yes
Circularity Check
No significant circularity; pruning schedule derived from external calibration measurements
full rationale
The paper's core procedure ranks attention heads using measured attention scores on a small offline calibration set and then builds a static pruning schedule for a target memory budget. This is an empirical, data-driven construction that does not define the schedule in terms of the final image-quality or compression metrics, nor does it reduce any claimed prediction to a fitted parameter by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present in the provided derivation chain. The 2x compression result is presented as an empirical outcome on Infinity-2B rather than a tautological consequence of the method's own inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Using a small offline calibration set, the attention heads are ranked according to their attention scores over prior scales. Based on this ranking, we construct a static pruning schedule
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
S-CASℓ,h,k = 1/(K−k) Σ βℓ,h[τ,k]
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,
J. Han, J. Liu, Y . Jiang, B. Yan, Y . Zhang, Z. Yuan, B. Peng, and X. Liu, “Infinity: Scaling bitwise autoregressive modeling for high-resolution image synthesis,” inProceedings of the Computer Vision and Pattern Recognition Conference, pp. 15733–15744, 2025
work page 2025
-
[2]
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets,”Advances in neural information processing systems, vol. 27, 2014
work page 2014
-
[3]
A style-based generator architecture for generative adversarial networks,
T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 4401–4410, 2019
work page 2019
-
[4]
Stylegan-xl: Scaling stylegan to large diverse datasets,
A. Sauer, K. Schwarz, and A. Geiger, “Stylegan-xl: Scaling stylegan to large diverse datasets,” inACM SIGGRAPH 2022 conference proceedings, pp. 1–10, 2022
work page 2022
-
[5]
Diffusion models beat gans on image synthesis,
P. Dhariwal and A. Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural informa- tion processing systems, vol. 34, pp. 8780–8794, 2021
work page 2021
-
[6]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 10684–10695, 2022
work page 2022
-
[7]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 4195–4205, 2023
work page 2023
-
[8]
Visual autoregressive modeling: Scalable image gener- ation via next-scale prediction,
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autoregressive modeling: Scalable image gener- ation via next-scale prediction,”Advances in neural information processing systems, vol. 37, pp. 84839– 84865, 2024
work page 2024
-
[9]
Memory-efficient visual autoregressive modeling with scale-aware kv cache compression,
K. Li, Z. Chen, C.-Y . Yang, and J.-N. Hwang, “Memory-efficient visual autoregressive modeling with scale-aware kv cache compression,”Advances in Neural Information Processing Systems, 2025
work page 2025
-
[10]
Generative pretraining from pixels,
M. Chen, A. Radford, R. Child, J. Wu, H. Jun, D. Luan, and I. Sutskever, “Generative pretraining from pixels,” inInternational conference on machine learning, pp. 1691–1703, PMLR, 2020
work page 2020
-
[11]
Taming transformers for high-resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 12873–12883, 2021
work page 2021
-
[12]
Scaling autoregressive models for content-rich text-to-image generation,
J. Yu, Y . Xu, J. Y . Koh, T. Luong, G. Baid, Z. Wang, V . Vasudevan, A. Ku, Y . Yang, B. K. Ayan, B. Hutchinson, W. Han, Z. Parekh, X. Li, H. Zhang, J. Baldridge, and Y . Wu, “Scaling autoregressive models for content-rich text-to-image generation,”Transactions on Machine Learning Research, 2022
work page 2022
-
[13]
Parallelized autoregres- sive visual generation,
Y . Wang, S. Ren, Z. Lin, Y . Han, H. Guo, Z. Yang, D. Zou, J. Feng, and X. Liu, “Parallelized autoregres- sive visual generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12955–12965, 2025
work page 2025
-
[14]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
P. Sun, Y . Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan, “Autoregressive model beats diffusion: Llama for scalable image generation,”arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
HART: Efficient visual generation with hybrid autoregressive transformer,
H. Tang, Y . Wu, S. Yang, E. Xie, J. Chen, J. Chen, Z. Zhang, H. Cai, Y . Lu, and S. Han, “HART: Efficient visual generation with hybrid autoregressive transformer,” inThe Thirteenth International Conference on Learning Representations, 2025. 10
work page 2025
-
[16]
FlowAR: Scale-wise autoregressive image generation meets flow matching,
S. Ren, Q. Yu, J. He, X. Shen, A. Yuille, and L.-C. Chen, “FlowAR: Scale-wise autoregressive image generation meets flow matching,” inForty-second International Conference on Machine Learning, 2025
work page 2025
-
[17]
FlexV AR: Flexible visual autoregressive modeling without residual prediction,
S. Jiao, G. Zhang, Y . Qian, J. Huang, Y . Zhao, H. Shi, L. Ma, Y . Wei, and Z. JIE, “FlexV AR: Flexible visual autoregressive modeling without residual prediction,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[18]
Visual autoregressive modelling for monocular depth estimation,
A. El-Ghoussani, A. Kaup, N. Navab, G. Carneiro, and V . Belagiannis, “Visual autoregressive modelling for monocular depth estimation,”arXiv preprint arXiv:2512.22653, 2025
-
[19]
Visual autoregressive modeling for image super-resolution,
Y . Qu, K. Yuan, J. Hao, K. Zhao, Q. Xie, M. Sun, and C. Zhou, “Visual autoregressive modeling for image super-resolution,” inForty-second International Conference on Machine Learning, 2025
work page 2025
-
[20]
Infinitystar: Unified spacetime autoregressive modeling for visual generation,
J. Liu, J. Han, B. Yan, Wuhui, F. Zhu, X. Wang, Y . Jiang, B. PENG, and Z. Yuan, “Infinitystar: Unified spacetime autoregressive modeling for visual generation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[21]
Efficient streaming language models with attention sinks,
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis, “Efficient streaming language models with attention sinks,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[22]
H2o: Heavy-hitter oracle for efficient generative inference of large language models,
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. Ré, C. Barrett,et al., “H2o: Heavy-hitter oracle for efficient generative inference of large language models,” 2023
work page 2023
-
[23]
Snapkv: Llm knows what you are looking for before generation,
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen, “Snapkv: Llm knows what you are looking for before generation,” 2024
work page 2024
-
[24]
Ada-KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference,
Y . Feng, J. Lv, Y . Cao, X. Xie, and S. K. Zhou, “Ada-KV: Optimizing KV cache eviction by adaptive budget allocation for efficient LLM inference,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[25]
Head-aware kv cache compression for efficient visual autoregressive modeling,
Z. Qin, Y . Lv, M. Lin, H. Guo, Z. Zhang, D. Zou, and W. Lin, “Head-aware kv cache compression for efficient visual autoregressive modeling,” 2026
work page 2026
-
[26]
Ams-kv: Adaptive kv caching in multi-scale visual autoregressive transformers,
B. Xu, Y . Wang, Z. Wang, and P. Li, “Ams-kv: Adaptive kv caching in multi-scale visual autoregressive transformers,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, pp. 27206–27214, 2026
work page 2026
-
[27]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyals,et al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[28]
Language model beats diffusion - tokenizer is key to visual generation,
L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y . Cheng, A. Gupta, X. Gu, A. G. Hauptmann, B. Gong, M.-H. Yang, I. Essa, D. A. Ross, and L. Jiang, “Language model beats diffusion - tokenizer is key to visual generation,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[29]
Image and video tokenization with binary spherical quantization,
Y . Zhao, Y . Xiong, and P. Kraehenbuehl, “Image and video tokenization with binary spherical quantization,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
- [30]
-
[31]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” 2014
work page 2014
-
[32]
The unreasonable effectiveness of deep fea- tures as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep fea- tures as a perceptual metric,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 586–595, 2018
work page 2018
-
[33]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,” inNeural Information Processing Systems, 2017
work page 2017
-
[34]
Geneval: An object-focused framework for evaluating text- to-image alignment,
D. Ghosh, H. Hajishirzi, and L. Schmidt, “Geneval: An object-focused framework for evaluating text- to-image alignment,” inAdvances in Neural Information Processing Systems, vol. 36, pp. 52132–52152, 2023
work page 2023
-
[35]
X. Wu, Y . Hao, K. Sun, Y . Chen, F. Zhu, R. Zhao, and H. Li, “Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis,”arXiv preprint arXiv:2306.09341, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Flashattention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “Flashattention-2: Faster attention with better parallelism and work partitioning,” inThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[37]
Fastvar: Linear visual autoregressive modeling via cached token pruning,
H. Guo, Y . Li, T. Zhang, J. Wang, T. Dai, S.-T. Xia, and L. Benini, “Fastvar: Linear visual autoregressive modeling via cached token pruning,” inProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 19011–19021, 2025
work page 2025
-
[38]
Sparvar: Exploring sparsity in visual autoregressive modeling for training-free acceleration,
Z. Li, N. Wang, T. Bai, C. Mei, P. Wang, S. Qiu, and J. Cheng, “Sparvar: Exploring sparsity in visual autoregressive modeling for training-free acceleration,”arXiv preprint arXiv:2602.04361, 2026. 11
-
[39]
Litevar: Compressing visual autoregressive modelling with efficient attention and quantization,
R. Xie, T. Zhao, Z. Yuan, R. Wan, W. Gao, Z. Zhu, X. Ning, and Y . Wang, “Litevar: Compressing visual autoregressive modelling with efficient attention and quantization,” inWorkshop on Machine Learning and Compression, NeurIPS 2024, 2024
work page 2024
-
[40]
PTQ4ARVG: Post-training quantization for autoregres- sive visual generation models,
X. Liu, Z. Li, J. Zhang, M. Chen, J. Li, and Q. Gu, “PTQ4ARVG: Post-training quantization for autoregres- sive visual generation models,” inThe Fourteenth International Conference on Learning Representations, 2026. 12 A Additional algorithms Algorithm 2CACHESIZEAFTERLAYER(k, ℓ, G k, Gk−1, Ek) Require: scale k, current layer ℓ, target pruning set Gk, previ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.