KGPFN: Unlocking the Potential of Knowledge Graph Foundation Model via In-Context Learning
Pith reviewed 2026-06-30 20:26 UTC · model grok-4.3
The pith
KGPFN adapts knowledge graph models to unseen graphs by retrieving and aggregating relation instances inside a Prior-Data Fitted Network at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
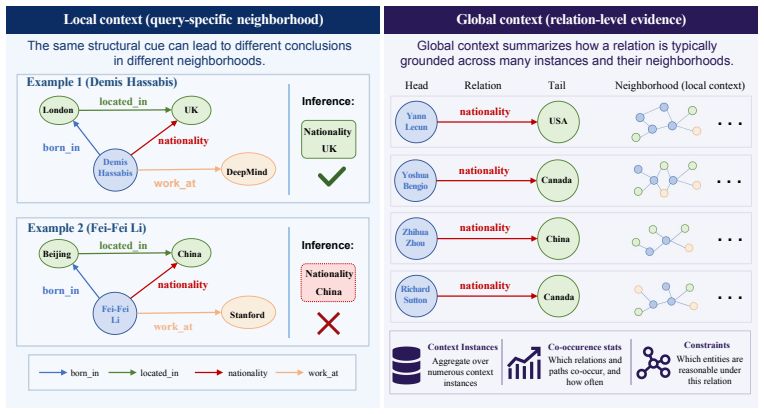
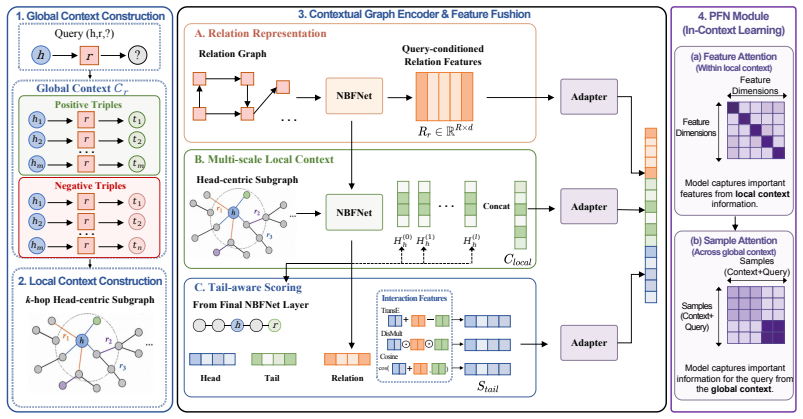
KGPFN first learns relation representations via message passing on relation graphs to capture cross-graph relational invariances. For any query it encodes local neighborhoods with a multi-layer NBFNet and constructs global context by retrieving a large set of instances of the query relation together with their local neighborhoods. These are aggregated inside a Prior-Data Fitted Network that combines feature-level and sample-level attention, allowing the model to learn when to reuse pretrained patterns and when to override them with contextual evidence. Through multi-graph pretraining, the resulting system adapts to previously unseen graphs using in-context learning alone.
What carries the argument
Prior-Data Fitted Network that aggregates local neighborhoods around query entities with global context from retrieved relation instances via combined feature-level and sample-level attention.
If this is right
- A single pretrained model can be deployed on new graphs without any parameter updates or fine-tuning.
- Global context from many retrieved relation instances can override or reinforce patterns learned during pretraining.
- Relation-level invariances captured by message passing on relation graphs become reusable across different graphs.
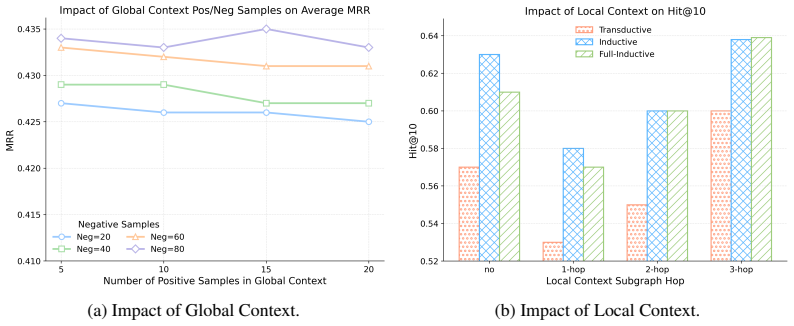
- Scaling the number of retrieved context instances directly improves adaptation performance on unseen graphs.
- The separation of pretraining for regularities from inference-time context aggregation reduces the need for task-specific retraining.
Where Pith is reading between the lines
- The same retrieval-plus-aggregation pattern could be tested on other structured domains such as molecular or citation graphs where instance neighborhoods are well-defined.
- If retrieval cost remains manageable, the approach may reduce reliance on gradient-based adaptation for any foundation model that operates over relational data.
- The emphasis on global relation context suggests that purely local neighborhood methods may be insufficient when entity and relation distributions shift between graphs.
- One could measure how performance changes when the retrieved context instances are deliberately drawn from graphs with increasing distributional distance from the query graph.
Load-bearing premise
Retrieving many instances of the query relation together with their local neighborhoods supplies transferable evidence that generalizes to graphs whose entity and relation distributions differ from the pretraining collection.
What would settle it
Evaluating the model on a new knowledge graph whose relation and entity distributions are shifted far from the pretraining collection and checking whether accuracy falls below that of fine-tuned baselines.
Figures

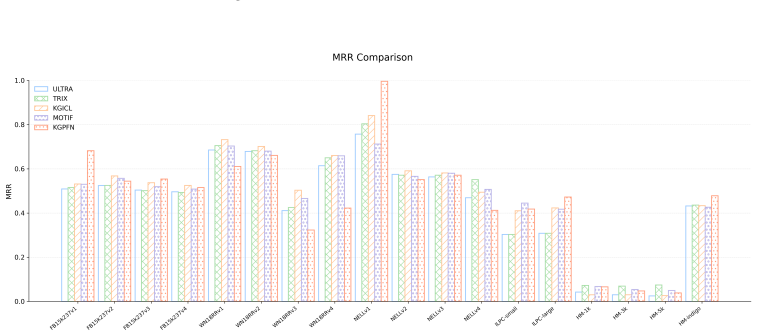
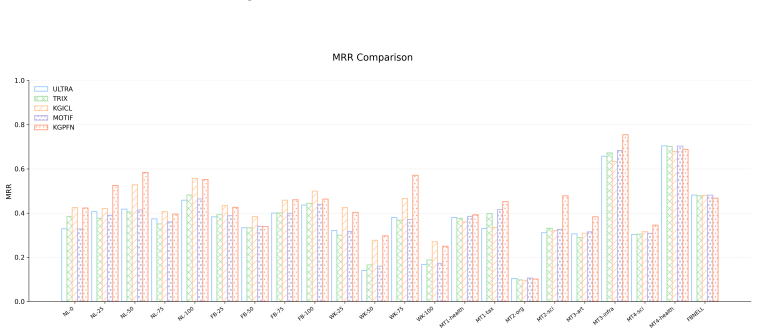
read the original abstract
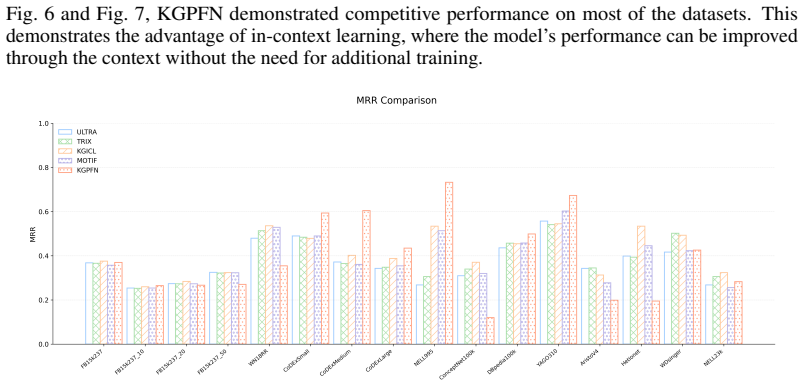
Knowledge graph (KG) foundation models aim to generalize across graphs with unseen entities and relations by learning transferable relational structure. However, most existing methods primarily emphasize relation-level universality, while in-context learning, the other pillar of foundation models remains under-explored for KG reasoning. In KGs, context is inherently structured and heterogeneous: effective prediction requires conditioning on the local context around the query entities as well as the global context that summarizes how a relation behaves across many instances. We propose KGPFN, a KG foundation model using Prior-data Fitted Network that unifies transferable relational regularities with inference-time in-context learning from structured context. KGPFN first learns relation representations via message passing on relation graphs to capture cross-graph relational invariances. For query-specific reasoning, it encodes local neighborhoods using a multi-layer NBFNet as local context. To enable ICL at global scale, it constructs relation-specific global context by retrieving a large set of instances of the query relation together with their local neighborhoods, and aggregates them within a Prior-Data Fitted Network framework that combines feature-level and sample-level attention. Through multi-graph pretraining on diverse KGs, KGPFN learns when to instantiate reusable patterns and when to override them using contextual evidence. Experiments on 57 KG benchmarks demonstrate that KGPFN achieves strong adaptation to previously unseen graphs through in-context learning alone, consistently outperforming competitive fine-tuned KG foundation models. Our code is available at https://github.com/HKUST-KnowComp/KGPFN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KGPFN, a knowledge graph foundation model that combines multi-graph pretraining with in-context learning via a Prior-Data Fitted Network (PFN). It learns relation representations through message passing on relation graphs, encodes local query context with multi-layer NBFNet, retrieves global instances of the query relation plus neighborhoods, and aggregates them using feature-level and sample-level attention inside the PFN. After pretraining on diverse KGs, the model claims to adapt to previously unseen graphs using ICL alone and to outperform competitive fine-tuned KG foundation models across 57 benchmarks.
Significance. If the experimental results hold under proper controls, the work would be significant for shifting emphasis in KG foundation models from fine-tuning to inference-time ICL on structured heterogeneous context. It provides a concrete architecture that unifies cross-graph relational invariances with global evidence aggregation, potentially enabling more scalable generalization without per-graph parameter updates.
major comments (2)
- [Experiments] Experiments section (and any associated tables/figures reporting the 57 benchmarks): the central claim that adaptation occurs 'through in-context learning alone' and that gains are not primarily from pre-learned relation representations requires explicit controls for distribution shift. No stratification by shift metrics (e.g., JS divergence on relation-frequency histograms between pretraining and test KGs) or ablation removing the PFN aggregation step is described, leaving open the possibility that reported outperformance is driven by the message-passing relation encoder rather than the ICL mechanism.
- [Method] Method description (the paragraph detailing PFN aggregation): the claim that the PFN 'combines feature-level and sample-level attention' to supply transferable evidence needs to be supported by the precise equations or pseudocode for how retrieved instances are encoded and attended; without these, it is impossible to verify that the aggregation step is parameter-free at inference time or truly distinct from standard attention-based retrieval.
minor comments (2)
- [Abstract] Abstract: the phrase 'Prior-data Fitted Network' is inconsistently capitalized; standardize to 'Prior-Data Fitted Network' or the acronym PFN throughout.
- [Abstract] The GitHub link is provided but no mention of whether the 57-benchmark splits, pretraining graphs, or evaluation scripts are released; adding this would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments highlight important areas for strengthening the experimental controls and methodological clarity. We address each major comment below and commit to revisions where appropriate.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and any associated tables/figures reporting the 57 benchmarks): the central claim that adaptation occurs 'through in-context learning alone' and that gains are not primarily from pre-learned relation representations requires explicit controls for distribution shift. No stratification by shift metrics (e.g., JS divergence on relation-frequency histograms between pretraining and test KGs) or ablation removing the PFN aggregation step is described, leaving open the possibility that reported outperformance is driven by the message-passing relation encoder rather than the ICL mechanism.
Authors: We agree that explicit controls would more rigorously isolate the contribution of the ICL mechanism from the pre-learned relation representations. In the revised manuscript, we will add (i) an ablation that removes the PFN aggregation step while retaining the message-passing relation encoder and local NBFNet context, and (ii) a stratification of the 57 benchmarks by distribution-shift metrics such as Jensen-Shannon divergence on relation-frequency histograms between the multi-graph pretraining corpus and each test KG. These additions will directly address whether the reported gains are driven primarily by inference-time contextual evidence aggregation. revision: yes
-
Referee: [Method] Method description (the paragraph detailing PFN aggregation): the claim that the PFN 'combines feature-level and sample-level attention' to supply transferable evidence needs to be supported by the precise equations or pseudocode for how retrieved instances are encoded and attended; without these, it is impossible to verify that the aggregation step is parameter-free at inference time or truly distinct from standard attention-based retrieval.
Authors: We acknowledge that the current description would benefit from greater formal precision. Although the manuscript already outlines the overall PFN framework, we will insert the exact equations governing instance encoding, the feature-level attention over retrieved neighborhoods, and the sample-level attention across instances. We will also provide pseudocode clarifying that no additional parameters are updated at inference time and that the aggregation differs from standard cross-attention retrieval by operating inside the pre-fitted PFN prior. These details will be placed in the revised Method section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and method sketch describe an architecture that learns relation representations via message passing, encodes local context with NBFNet, retrieves global instances of the query relation, and aggregates them inside a PFN with feature- and sample-level attention. No equations appear that would reduce the final prediction to a fitted parameter or self-defined quantity by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are quoted. The central claim is framed as an empirical outcome on 57 benchmarks rather than a closed mathematical derivation, leaving the ICL step independent of the inputs in the text examined.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Many-shot in-context learning
Rishabh Agarwal, Avi Singh, Lei Zhang, Bernd Bohnet, Luis Rosias, Stephanie Chan, Biao Zhang, Ankesh Anand, Zaheer Abbas, Azade Nova, et al. Many-shot in-context learning. Advances in Neural Information Processing Systems, 37:76930–76966, 2024
2024
-
[2]
Complex query answering on eventuality knowledge graph with implicit logical constraints.Advances in Neural Information Processing Systems, 36:30534–30553, 2023
Jiaxin Bai, Xin Liu, Weiqi Wang, Chen Luo, and Yangqiu Song. Complex query answering on eventuality knowledge graph with implicit logical constraints.Advances in Neural Information Processing Systems, 36:30534–30553, 2023
2023
-
[3]
Query2particles: Knowledge graph reasoning with particle embeddings
Jiaxin Bai, Zihao Wang, Hongming Zhang, and Yangqiu Song. Query2particles: Knowledge graph reasoning with particle embeddings. InFindings of the Association for Computational Linguistics: NAACL 2022, pages 2703–2714, 2022
2022
-
[4]
Top ten challenges towards agentic neural graph databases.arXiv preprint arXiv:2501.14224, 2025
Jiaxin Bai, Zihao Wang, Yukun Zhou, Hang Yin, Weizhi Fei, Qi Hu, Zheye Deng, Jiayang Cheng, Tianshi Zheng, Hong Ting Tsang, et al. Top ten challenges towards agentic neural graph databases.arXiv preprint arXiv:2501.14224, 2025
-
[5]
The logical expressiveness of graph neural networks
Pablo Barceló, Egor V Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, and Juan Pablo Silva. The logical expressiveness of graph neural networks. InInternational conference on learning representations, 2020
2020
-
[6]
Neural graph databases
Maciej Besta, Patrick Iff, Florian Scheidl, Kazuki Osawa, Nikoli Dryden, Michal Podstawski, Tiancheng Chen, and Torsten Hoefler. Neural graph databases. InLearning on Graphs Conference, pages 31–1. PMLR, 2022
2022
-
[7]
Translating embeddings for modeling multi-relational data.Advances in neural information processing systems, 26, 2013
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. Translating embeddings for modeling multi-relational data.Advances in neural information processing systems, 26, 2013
2013
-
[8]
Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences
Yixin Cao, Xiang Wang, Xiangnan He, Zikun Hu, and Tat-Seng Chua. Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. In The world wide web conference, pages 151–161, 2019
2019
-
[9]
Meta relational learning for few-shot link prediction in knowledge graphs
Mingyang Chen, Wen Zhang, Wei Zhang, Qiang Chen, and Huajun Chen. Meta relational learning for few-shot link prediction in knowledge graphs. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 4217–4226, 2019
2019
-
[10]
Can graph neural networks count substructures?Advances in neural information processing systems, 33:10383–10395, 2020
Zhengdao Chen, Lei Chen, Soledad Villar, and Joan Bruna. Can graph neural networks count substructures?Advances in neural information processing systems, 33:10383–10395, 2020
2020
-
[11]
Many-shot cot-icl: Making in-context learning truly learn, 2026
Tsz Ting Chung, Lemao Liu, Mo Yu, and Dit-Yan Yeung. Many-shot cot-icl: Making in-context learning truly learn, 2026
2026
-
[12]
A prompt-based knowledge graph foundation model for universal in-context reasoning.Advances in Neural Information Processing Systems, 37:7095– 7124, 2024
Yuanning Cui, Zequn Sun, and Wei Hu. A prompt-based knowledge graph foundation model for universal in-context reasoning.Advances in Neural Information Processing Systems, 37:7095– 7124, 2024
2024
-
[13]
Convolutional 2d knowledge graph embeddings
Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. Convolutional 2d knowledge graph embeddings. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018. 10
2018
-
[14]
GraphPFN: A Prior-Data Fitted Graph Foundation Model
Dmitry Eremeev, Oleg Platonov, Gleb Bazhenov, Artem Babenko, and Liudmila Prokhorenkova. Graphpfn: A prior-data fitted graph foundation model.arXiv preprint arXiv:2509.21489, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Mikhail Galkin, Max Berrendorf, and Charles Tapley Hoyt. An open challenge for inductive link prediction on knowledge graphs.arXiv preprint arXiv:2203.01520, 2022
-
[16]
Towards foundation models for knowledge graph reasoning.arXiv preprint arXiv:2310.04562, 2023
Mikhail Galkin, Xinyu Yuan, Hesham Mostafa, Jian Tang, and Zhaocheng Zhu. Towards foundation models for knowledge graph reasoning.arXiv preprint arXiv:2310.04562, 2023
-
[17]
Unifying deductive and abductive reasoning in knowledge graphs with masked diffusion model
Yisen Gao, Jiaxin Bai, Yi Huang, Xingcheng Fu, Qingyun Sun, and Yangqiu Song. Unifying deductive and abductive reasoning in knowledge graphs with masked diffusion model. In Proceedings of the ACM Web Conference 2026, pages 3600–3611, 2026
2026
-
[18]
Controllable Logical Hypothesis Generation for Abductive Reasoning in Knowledge Graphs
Yisen Gao, Jiaxin Bai, Tianshi Zheng, Qingyun Sun, Ziwei Zhang, Xingcheng Fu, Jianxin Li, and Yangqiu Song. Controllable logical hypothesis generation for abductive reasoning in knowledge graphs.arXiv preprint arXiv:2505.20948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
TabPFN-2.5: Advancing the State of the Art in Tabular Foundation Models
Léo Grinsztajn, Klemens Flöge, Oscar Key, Felix Birkel, Philipp Jund, Brendan Roof, Benjamin Jäger, Dominik Safaric, Simone Alessi, Adrian Hayler, et al. Tabpfn-2.5: Advancing the state of the art in tabular foundation models.arXiv preprint arXiv:2511.08667, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Knowledge Transfer for Out-of-Knowledge-Base Entities: A Graph Neural Network Approach
Takuo Hamaguchi, Hidekazu Oiwa, Masashi Shimbo, and Yuji Matsumoto. Knowledge transfer for out-of-knowledge-base entities: A graph neural network approach.arXiv preprint arXiv:1706.05674, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Systematic integration of biomedical knowledge prioritizes drugs for repurposing.elife, 6:e26726, 2017
Daniel Scott Himmelstein, Antoine Lizee, Christine Hessler, Leo Brueggeman, Sabrina L Chen, Dexter Hadley, Ari Green, Pouya Khankhanian, and Sergio E Baranzini. Systematic integration of biomedical knowledge prioritizes drugs for repurposing.elife, 6:e26726, 2017
2017
-
[22]
TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second
Noah Hollmann, Samuel Müller, Katharina Eggensperger, and Frank Hutter. Tabpfn: A transformer that solves small tabular classification problems in a second.arXiv preprint arXiv:2207.01848, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
How expressive are knowledge graph foundation models?arXiv preprint arXiv:2502.13339, 2025
Xingyue Huang, Pablo Barceló, Michael M Bronstein, Ismail Ilkan Ceylan, Mikhail Galkin, Juan L Reutter, and Miguel Romero Orth. How expressive are knowledge graph foundation models?arXiv preprint arXiv:2502.13339, 2025
-
[24]
Ingram: Inductive knowledge graph embedding via relation graphs
Jaejun Lee, Chanyoung Chung, and Joyce Jiyoung Whang. Ingram: Inductive knowledge graph embedding via relation graphs. InInternational conference on machine learning, pages 18796–18809. PMLR, 2023
2023
-
[25]
Dbpedia–a large- scale, multilingual knowledge base extracted from wikipedia.Semantic web, 6(2):167–195, 2015
Jens Lehmann, Robert Isele, Max Jakob, Anja Jentzsch, Dimitris Kontokostas, Pablo N Mendes, Sebastian Hellmann, Mohamed Morsey, Patrick Van Kleef, Sören Auer, et al. Dbpedia–a large- scale, multilingual knowledge base extracted from wikipedia.Semantic web, 6(2):167–195, 2015
2015
-
[26]
NGDBench: Towards Neural Graph Data Management
Yufei Li, Yisen Gao, Jiaxin Bai, Jiaxuan Xiong, Haoyu Huang, Zhongwei Xie, Hong Ting Tsang, and Yangqiu Song. Towards neural graph data management.arXiv preprint arXiv:2603.05529, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Tianyin Liao, Chunyu Hu, Yicheng Sui, Xingxuan Zhang, Peng Cui, Jianxin Li, and Ziwei Zhang. Tfmlinker: Universal link predictor by graph in-context learning with tabular foundation models.arXiv preprint arXiv:2602.08592, 2026
-
[28]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Indigo: Gnn-based inductive knowledge graph completion using pair-wise encoding.Advances in Neural Information Processing Systems, 34:2034–2045, 2021
Shuwen Liu, Bernardo Grau, Ian Horrocks, and Egor Kostylev. Indigo: Gnn-based inductive knowledge graph completion using pair-wise encoding.Advances in Neural Information Processing Systems, 34:2034–2045, 2021
2034
-
[30]
Never-ending learning.Communications of the ACM, 61(5):103–115, 2018
Tom Mitchell, William Cohen, Estevam Hruschka, Partha Talukdar, Bishan Yang, Justin Bet- teridge, Andrew Carlson, Bhavana Dalvi, Matt Gardner, Bryan Kisiel, et al. Never-ending learning.Communications of the ACM, 61(5):103–115, 2018. 11
2018
-
[31]
Statistical foundations of prior-data fitted networks
Thomas Nagler. Statistical foundations of prior-data fitted networks. InInternational Conference on Machine Learning, pages 25660–25676. PMLR, 2023
2023
-
[32]
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
TabICL: A Tabular Foundation Model for In-Context Learning on Large Data
Jingang Qu, David HolzmÞller, GaÃl Varoquaux, and Marine Le Morvan. Tabicl: A tabular foundation model for in-context learning on large data.arXiv preprint arXiv:2502.05564, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
TabICLv2: A better, faster, scalable, and open tabular foundation model.arXiv:2602.11139, 2026
Jingang Qu, David Holzmüller, Gaël Varoquaux, and Marine Le Morvan. Tabiclv2: A better, faster, scalable, and open tabular foundation model.arXiv preprint arXiv:2602.11139, 2026
-
[35]
Hongyu Ren, Mikhail Galkin, Michael Cochez, Zhaocheng Zhu, and Jure Leskovec. Neural graph reasoning: Complex logical query answering meets graph databases.arXiv preprint arXiv:2303.14617, 2023
-
[36]
Hongyu Ren, Weihua Hu, and Jure Leskovec. Query2box: Reasoning over knowledge graphs in vector space using box embeddings.arXiv preprint arXiv:2002.05969, 2020
-
[37]
Codex: A comprehensive knowledge graph completion bench- mark
Tara Safavi and Danai Koutra. Codex: A comprehensive knowledge graph completion bench- mark. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8328–8350, 2020
2020
-
[38]
Conceptnet 5.5: An open multilingual graph of general knowledge
Robyn Speer, Joshua Chin, and Catherine Havasi. Conceptnet 5.5: An open multilingual graph of general knowledge. InProceedings of the AAAI conference on artificial intelligence, volume 31, 2017
2017
-
[39]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[40]
Yago: a core of semantic knowl- edge
Fabian M Suchanek, Gjergji Kasneci, and Gerhard Weikum. Yago: a core of semantic knowl- edge. InProceedings of the 16th international conference on World Wide Web, pages 697–706, 2007
2007
-
[41]
Timepfn: Effective multivariate time series forecasting with synthetic data
Ege Onur Taga, Muhammed Emrullah Ildiz, and Samet Oymak. Timepfn: Effective multivariate time series forecasting with synthetic data. InProceedings of the AAAI conference on artificial intelligence, volume 39, pages 20761–20769, 2025
2025
-
[42]
Inductive relation prediction by subgraph reasoning
Komal Teru, Etienne Denis, and Will Hamilton. Inductive relation prediction by subgraph reasoning. InInternational conference on machine learning, pages 9448–9457. PMLR, 2020
2020
-
[43]
Observed versus latent features for knowledge base and text inference
Kristina Toutanova and Danqi Chen. Observed versus latent features for knowledge base and text inference. InProceedings of the 3rd workshop on continuous vector space models and their compositionality, pages 57–66, 2015
2015
-
[44]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Relational In-Context Learning via Synthetic Pre-training with Structural Prior
Yanbo Wang, Jiaxuan You, Chuan Shi, and Muhan Zhang. Relational in-context learning via synthetic pre-training with structural prior.arXiv preprint arXiv:2603.03805, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[46]
Ngdb-zoo: Towards efficient and scalable neural graph databases training
Zhongwei Xie, Jiaxin Bai, Shujie Liu, Haoyu Huang, Yufei Li, Yisen Gao, Hong Ting Tsang, and Yangqiu Song. Ngdb-zoo: Towards efficient and scalable neural graph databases training. arXiv preprint arXiv:2602.21597, 2026
-
[47]
Xingxuan Zhang, Gang Ren, Han Yu, Hao Yuan, Hui Wang, Jiansheng Li, Jiayun Wu, Lang Mo, Li Mao, Mingchao Hao, et al. Limix: Unleashing structured-data modeling capability for generalist intelligence.arXiv preprint arXiv:2509.03505, 2025
-
[48]
Yucheng Zhang, Beatrice Bevilacqua, Mikhail Galkin, and Bruno Ribeiro. Trix: A more expres- sive model for zero-shot domain transfer in knowledge graphs.arXiv preprint arXiv:2502.19512, 2025
-
[49]
Jincheng Zhou, Beatrice Bevilacqua, and Bruno Ribeiro. An ood multi-task perspective for link prediction with new relation types and nodes.arXiv preprint arXiv:2307.06046, 23, 2023. 12 A Detailed Theoretical Proofs In this appendix, we provide the rigorous mathematical foundations for the reasoning mechanism of KGPFN. We formally prove how conditional mes...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.