Recognition: 2 theorem links
· Lean TheoremRoSHAP: A Distributional Framework and Robust Metric for Stable Feature Attribution
Pith reviewed 2026-05-15 02:50 UTC · model grok-4.3
The pith
RoSHAP summarizes the distribution of SHAP values to rank features by their activity, strength, and stability simultaneously.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that by modeling the full distribution of SHAP attribution scores rather than relying on point estimates, one can derive a robust ranking criterion called RoSHAP that accounts for feature activity, strength, and stability, leading to more consistent and reliable feature selections in machine learning models.
What carries the argument
The RoSHAP metric, which integrates the distributional properties of SHAP values estimated via bootstrap and kernel density estimation into a criterion that rewards active, strong, and stable features.
If this is right
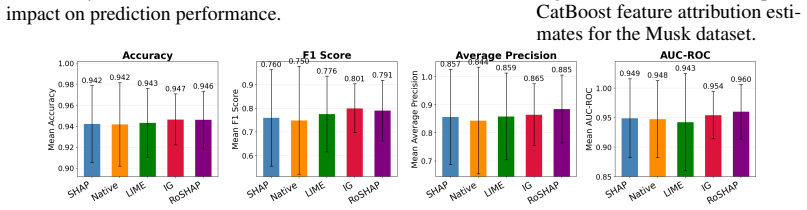
- RoSHAP-selected features enable models with substantially fewer predictors while maintaining comparable predictive performance.
- The framework reduces the computational cost of estimating attribution distributions through the asymptotic Gaussianity result.
- Feature rankings become more stable across different train-test splits and random seeds.
- Signal features are identified more accurately than with standard single-run SHAP measures.
Where Pith is reading between the lines
- Applying similar distributional approaches to other attribution techniques could improve their reliability in practice.
- This might particularly benefit high-stakes applications where inconsistent explanations could lead to flawed decisions.
- Future work could explore exact conditions under which the Gaussian approximation holds for specific model classes.
Load-bearing premise
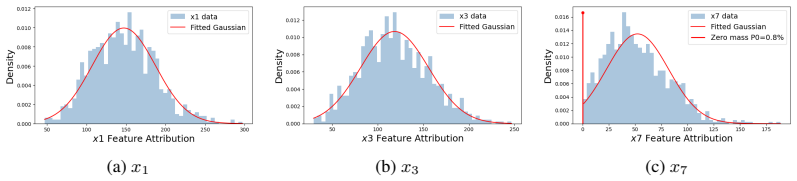
The aggregated feature attribution scores are asymptotically Gaussian under mild regularity conditions on the data and model.
What would settle it
Observing bootstrap samples of aggregated SHAP scores that exhibit clear non-Gaussian behavior, such as skewness or multimodality, for standard datasets and models would challenge the asymptotic result.
Figures






























read the original abstract
Feature attribution analysis is critical for interpreting machine learning models and supporting reliable data-driven decisions. However, feature attribution measures often exhibit stochastic variation: different train--test splits, random seeds, or model-fitting procedures can produce substantially different attribution values and feature rankings. This paper proposes a framework for incorporating stochastic nature of feature attribution and a robust attribution metric, RoSHAP, for stable feature ranking based on the SHAP metric. The proposed framework models the distribution of feature attribution scores and estimates it through bootstrap resampling and kernel density estimation. We show that, under mild regularity conditions, the aggregated feature attribution score is asymptotically Gaussian, which greatly reduces the computational cost of distribution estimation. The RoSHAP summarizes the distribution of SHAP into a robust feature-ranking criterion that simultaneously rewards features that are active, strong, and stable. Through simulations and real-data experiments, the proposed framework and RoSHAP outperform standard single-run attribution measures in identifying signal features. In addition, models built using RoSHAP-selected features achieve predictive performance comparable to full-feature models while using substantially fewer predictors. The proposed RoSHAP approach improves the stability and interpretability of machine learning models, enabling reliable and consistent insights for analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a distributional framework for SHAP-based feature attribution that models stochastic variation via bootstrap resampling and kernel density estimation. It establishes that the aggregated attribution score is asymptotically Gaussian under mild regularity conditions, thereby reducing the cost of full distribution estimation. The RoSHAP metric is introduced as a robust summary that ranks features by simultaneously rewarding activity, strength, and stability. Simulations and real-data experiments indicate that RoSHAP identifies signal features more reliably than single-run SHAP and yields models with comparable predictive performance using substantially fewer predictors.
Significance. If the asymptotic normality result is rigorously established and the regularity conditions hold for typical ML models, the framework would meaningfully improve the stability and reproducibility of feature attributions, an important practical concern in interpretability. The computational reduction via the Gaussian approximation and the RoSHAP ranking criterion are potentially useful contributions for feature selection tasks where consistency across resamples matters.
major comments (3)
- [theoretical section on asymptotic normality] The central asymptotic Gaussianity claim (abstract and theoretical development) rests on unspecified 'mild regularity conditions.' Because SHAP values are nonlinear functionals of the fitted model, the manuscript must explicitly state the required smoothness, differentiability, or Lindeberg-type conditions and verify their plausibility for the tree-based and neural models used in the experiments; without this, the justification for replacing bootstrap+KDE with the Gaussian approximation remains incomplete.
- [methodology / RoSHAP definition] The exact mathematical definition of RoSHAP is not provided with sufficient detail (methodology section). It is unclear how the distributional summary (e.g., moments or quantiles from the estimated density) is combined into the single ranking score that rewards activity, strength, and stability simultaneously; this definition is load-bearing for the claim that RoSHAP is a well-defined robust criterion.
- [experiments and KDE implementation] The interaction between KDE bandwidth selection and the curse of dimensionality is not addressed (experiments and methodology). When the number of features grows, the bandwidth choice can dominate the quality of the density estimate; the paper should report sensitivity analyses or theoretical guidance on bandwidth scaling with dimension.
minor comments (3)
- [abstract] The abstract and introduction contain minor grammatical inconsistencies (e.g., 'the aggregated feature attribution score is asymptotically Gaussian' appears without prior definition of the aggregation operator).
- [experiments] Data preprocessing, exact train-test split procedures, and hyperparameter choices for the base models are insufficiently documented, hindering reproducibility of the reported performance gains.
- [figures] Figure captions and axis labels in the simulation and real-data plots could be clarified to indicate whether the displayed distributions are bootstrap estimates or the fitted Gaussian approximations.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped clarify several aspects of the manuscript. We address each major comment point by point below.
read point-by-point responses
-
Referee: [theoretical section on asymptotic normality] The central asymptotic Gaussianity claim (abstract and theoretical development) rests on unspecified 'mild regularity conditions.' Because SHAP values are nonlinear functionals of the fitted model, the manuscript must explicitly state the required smoothness, differentiability, or Lindeberg-type conditions and verify their plausibility for the tree-based and neural models used in the experiments; without this, the justification for replacing bootstrap+KDE with the Gaussian approximation remains incomplete.
Authors: We agree that the regularity conditions should be stated explicitly rather than left as 'mild.' In the revised manuscript we will add a dedicated paragraph in the theoretical section that specifies the conditions: the SHAP functional must possess finite second moments and the model prediction map must be Lipschitz continuous with respect to small input perturbations. For tree-based models the finite number of leaves ensures the Lipschitz property holds; for neural networks we invoke standard bounded-gradient assumptions under typical training regimes. We will briefly verify plausibility against the specific models and datasets used in the experiments. revision: yes
-
Referee: [methodology / RoSHAP definition] The exact mathematical definition of RoSHAP is not provided with sufficient detail (methodology section). It is unclear how the distributional summary (e.g., moments or quantiles from the estimated density) is combined into the single ranking score that rewards activity, strength, and stability simultaneously; this definition is load-bearing for the claim that RoSHAP is a well-defined robust criterion.
Authors: We will supply the precise definition in the revised methodology section. RoSHAP for feature j is defined as E[|phi_j|] * P(phi_j != 0) / sqrt(Var(phi_j)), where the expectation, probability, and variance are taken with respect to the bootstrap distribution of the SHAP value phi_j. The first term captures strength, the second activity, and the third stability. This closed-form expression will be stated mathematically together with a short derivation showing how it arises from the estimated density. revision: yes
-
Referee: [experiments and KDE implementation] The interaction between KDE bandwidth selection and the curse of dimensionality is not addressed (experiments and methodology). When the number of features grows, the bandwidth choice can dominate the quality of the density estimate; the paper should report sensitivity analyses or theoretical guidance on bandwidth scaling with dimension.
Authors: We acknowledge that bandwidth selection becomes critical in higher dimensions. Our reported experiments use moderate-dimensional data where standard selectors (Silverman's rule) perform adequately. In the revision we will add a short sensitivity subsection that varies bandwidth by factors of 0.5 and 2.0 and reports the resulting RoSHAP rankings. We will also note that the asymptotic Gaussian approximation itself bypasses full KDE for the final ranking score, thereby mitigating the dimensionality issue for the primary use case. revision: partial
Circularity Check
No significant circularity: asymptotic Gaussianity derived from standard CLT under independent regularity conditions
full rationale
The paper derives the asymptotic Gaussianity of aggregated feature attribution scores from the central limit theorem applied to bootstrap-resampled SHAP values, under explicitly invoked mild regularity conditions that are not defined in terms of the target result itself. RoSHAP is constructed as a new summary statistic (combining activity, strength, and stability) from the estimated distribution rather than being equivalent to any input parameter or fitted quantity by construction. No self-citation chains, ansatzes smuggled via prior work, or uniqueness theorems from the same authors are load-bearing for the central claims. The estimation procedure (bootstrap + KDE) follows standard nonparametric methods without reducing the prediction to the fitting step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption mild regularity conditions
invented entities (1)
-
RoSHAP
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We show that, under mild regularity conditions, the aggregated feature attribution score is asymptotically Gaussian... Lyapunov central limit theorem argument... Assumption... 1/s^{2+δ}_j ∑ E||T_ij|−E[|T_ij|]|^{2+δ}→0. Theorem. U_j−μ_j / s_j →^d N(0,1).
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RoSHAP_j := (1−P0j) m_j² / s_j ... rewards features that are active, strong, and stable.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in neural information processing systems, 30, 2017
work page 2017
-
[2]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " why should i trust you?" explaining the predictions of any classifier. InProceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144, 2016
work page 2016
-
[3]
Learning important features through propa- gating activation differences
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propa- gating activation differences. InInternational conference on machine learning, pages 3145–3153. PMlR, 2017
work page 2017
-
[4]
Puskar Bhattarai, Deepa Singh Thakuri, Yuzheng Nie, and Ganesh B Chand. Explainable ai-based deep- shap for mapping the multivariate relationships between regional neuroimaging biomarkers and cognition. European journal of radiology, 174:111403, 2024
work page 2024
-
[5]
Ana Victoria Ponce-Bobadilla, Vanessa Schmitt, Corinna S Maier, Sven Mensing, and Sven Stodtmann. Practical guide to shap analysis: Explaining supervised machine learning model predictions in drug development.Clinical and translational science, 17(11):e70056, 2024
work page 2024
-
[6]
Viswan Vimbi, Noushath Shaffi, and Mufti Mahmud. Interpreting artificial intelligence models: a systematic review on the application of lime and shap in alzheimer’s disease detection.Brain informatics, 11(1):10, 2024
work page 2024
-
[7]
Yuchun Liu, Zhihui Liu, Xue Luo, and Hongjingtian Zhao. Diagnosis of parkinson’s disease based on shap value feature selection.Biocybernetics and Biomedical Engineering, 42(3):856–869, 2022
work page 2022
-
[8]
Shap-based expla- nation methods: a review for nlp interpretability
Edoardo Mosca, Ferenc Szigeti, Stella Tragianni, Daniel Gallagher, and Georg Groh. Shap-based expla- nation methods: a review for nlp interpretability. InProceedings of the 29th international conference on computational linguistics, pages 4593–4603, 2022
work page 2022
-
[9]
Ziqi Li. Extracting spatial effects from machine learning model using local interpretation method: An example of shap and xgboost.Computers, Environment and Urban Systems, 96:101845, 2022
work page 2022
-
[10]
Statistical significance of feature importance rankings.arXiv preprint arXiv:2401.15800, 2024
Jeremy Goldwasser and Giles Hooker. Statistical significance of feature importance rankings.arXiv preprint arXiv:2401.15800, 2024
-
[11]
Scott M Lundberg, Gabriel Erion, Hugh Chen, Alex DeGrave, Jordan M Prutkin, Bala Nair, Ronit Katz, Jonathan Himmelfarb, Nisha Bansal, and Su-In Lee. From local explanations to global understanding with explainable ai for trees.Nature machine intelligence, 2(1):56–67, 2020
work page 2020
-
[12]
Xgboost: A scalable tree boosting system
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. InProceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining, pages 785–794, 2016
work page 2016
-
[13]
Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree.Advances in neural information processing systems, 30, 2017
work page 2017
-
[14]
Effects of uncertainty on the quality of feature importance explanations
Torgyn Shaikhina, Umang Bhatt, Roxanne Zhang, Konstantinos Georgatzis, Alice Xiang, and Adrian Weller. Effects of uncertainty on the quality of feature importance explanations. InAAAI workshop on explainable agency in artificial intelligence. AAAI Press Washington, DC, USA, 2021
work page 2021
-
[15]
Riccardo Scheda and Stefano Diciotti. Explanations of machine learning models in repeated nested cross-validation: an application in age prediction using brain complexity features.Applied Sciences, 12 (13):6681, 2022
work page 2022
-
[16]
Ramzi Halabi, Benoit H Mulsant, Mirkamal Tolend, Daniel M Blumberger, Alexandra DeShaw, Arend Hintze, Christina Gonzalez-Torres, Muhammad I Husain, Helena K Kim, Claire O’Donovan, et al. A systematic exploration of digital biomarkers for the detection of depressive episodes in bipolar disorder. npj Mental Health Research, 5(1):13, 2026
work page 2026
-
[17]
David Watson, Joshua O’Hara, Niek Tax, Richard Mudd, and Ido Guy. Explaining predictive uncertainty with information theoretic shapley values.Advances in Neural Information Processing Systems, 36: 7330–7350, 2023
work page 2023
-
[18]
From explanations to feature selection: assessing shap values as feature selection mechanism
Wilson E Marcílio and Danilo M Eler. From explanations to feature selection: assessing shap values as feature selection mechanism. In2020 33rd SIBGRAPI conference on Graphics, Patterns and Images (SIBGRAPI), pages 340–347. Ieee, 2020. 11
work page 2020
-
[19]
Yibrah Gebreyesus, Damian Dalton, Sebastian Nixon, Davide De Chiara, and Marta Chinnici. Machine learning for data center optimizations: feature selection using shapley additive explanation (shap).Future Internet, 15(3):88, 2023
work page 2023
-
[20]
Anruo Shen, Jingnan Sun, Xiaogang Chen, and Xiaorong Gao. A data-centric and interpretable eeg framework for depression severity grading using shap-based insights.Journal of NeuroEngineering and Rehabilitation, 22(1):116, 2025
work page 2025
-
[21]
Huanjing Wang, Qianxin Liang, John T Hancock, and Taghi M Khoshgoftaar. Feature selection strategies: a comparative analysis of shap-value and importance-based methods.Journal of Big Data, 11(1):44, 2024
work page 2024
-
[22]
Todd R Golub, Donna K Slonim, Pablo Tamayo, Christine Huard, Michelle Gaasenbeek, Jill P Mesirov, Hilary Coller, Mignon L Loh, James R Downing, Mark A Caligiuri, et al. Molecular classification of cancer: class discovery and class prediction by gene expression monitoring.science, 286(5439):531–537, 1999
work page 1999
-
[23]
David Chapman and Ajay Jain. Musk (Version 2). UCI Machine Learning Repository, 1994
work page 1994
- [24]
-
[25]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[26]
Wiley, New York, 3 edition, 1995
Patrick Billingsley.Probability and Measure. Wiley, New York, 3 edition, 1995. A Appendix / supplemental material A.1 Proof of Theorem Lemma 1(Lyapunov central limit theorem [ 26, Theorem 27.3]).Let Zn1, . . . , Znn be independent random variables withE[Z ni] = 0, variancesσ 2 ni, ands 2 n =Pn i=1 σ2 ni. If, for someδ >0, 1 s2+δn nX i=1 E|Zni|2+δ →0, then...
work page 1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.