ReactiveGWM: Steering NPC in Reactive Game World Models
Pith reviewed 2026-05-19 16:27 UTC · model grok-4.3
The pith
ReactiveGWM decouples player controls from NPC behaviors to enable zero-shot strategy transfer across game world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
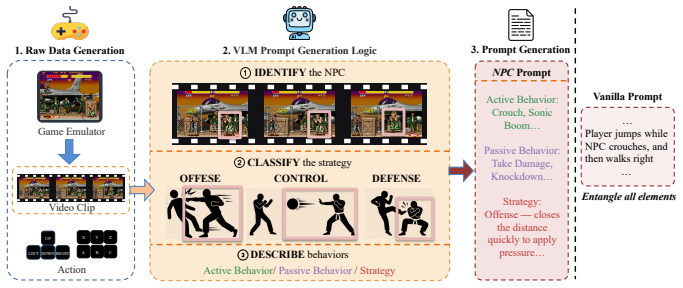
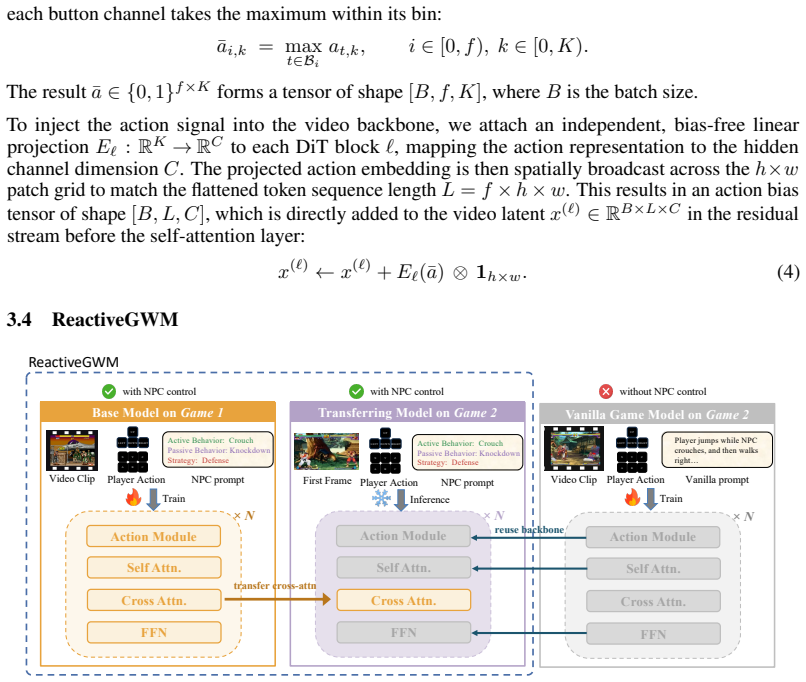
ReactiveGWM synthesizes dynamic interactions between the player and NPC by explicitly decoupling player controls from NPC behaviors. Player actions are injected into the diffusion backbone via a lightweight additive bias, while high-level NPC responses are grounded through cross-attention modules. Crucially, these modules learn a game-agnostic representation of interactive logic. This enables zero-shot strategy transfer: the learned modules can be plugged directly into off-the-shelf, unannotated world models of different games, instantly unlocking steerable NPC interactions without any domain-specific retraining.
What carries the argument
Cross-attention modules that ground high-level NPC responses and learn a game-agnostic representation of interactive logic for direct transfer.
If this is right
- The model maintains fine-grain player controllability while producing robust, prompt-aligned NPC strategy adherence.
- Steerable NPC interactions become available in any off-the-shelf unannotated world model without retraining.
- The approach scales to strategy-rich player-NPC engagements across multiple game titles.
- High-level NPC behaviors like Offense, Control, and Defense can be directed independently of low-level player inputs.
Where Pith is reading between the lines
- The same decoupling pattern could be tested in other interactive simulation settings where one agent must respond to another without retraining per domain.
- If the interactive logic proves largely universal, similar modules might later support prompt-based control in multi-agent or robotics environments.
- Extending the set of NPC response categories beyond Offense, Control, and Defense could be checked for continued transfer performance.
Load-bearing premise
The cross-attention modules learn a game-agnostic representation of interactive logic that transfers directly into different games without retraining or fine-tuning.
What would settle it
Plugging the cross-attention modules into an off-the-shelf world model of a new game and observing that NPC responses no longer match the prompted strategies, such as producing wrong defensive actions when an offense prompt is given.
Figures









read the original abstract
Current game world models simulate environments from a subjective, player-centric perspective. However, by treating the Non-Player Character (NPC) merely as background pixels, these models cannot capture interactions between the player and NPC. In that sense, they act as passive video renderers rather than real simulation engines, lacking the physical understanding needed to model action-induced NPC reactivities. We introduce ReactiveGWM, a reactive game world model that synthesizes dynamic interactions between the player and NPC. Instead of entangling all interaction dynamics, ReactiveGWM explicitly decouples player controls from NPC behaviors. Player actions are injected into the diffusion backbone via a lightweight additive bias, while high-level NPC responses (e.g., Offense, Control, Defense) are grounded through cross-attention modules. Crucially, these modules learn a game-agnostic representation of interactive logic. This enables zero-shot strategy transfer: our learned modules can be plugged directly into off-the-shelf, unannotated world models of different games. This instantly unlocks steerable NPC interactions without any domain-specific retraining. Evaluated on two Street Fighter games, ReactiveGWM maintains fine-grain player controllability while achieving robust, prompt-aligned NPC strategy adherence, paving the way for scalable, strategy-rich interaction with the NPC.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ReactiveGWM, a reactive game world model for synthesizing dynamic player-NPC interactions in diffusion-based simulators. It decouples player controls (injected via additive bias into the diffusion backbone) from NPC behaviors (modeled via cross-attention modules for high-level strategies like Offense, Control, Defense). The key innovation is that these modules learn a game-agnostic representation of interactive logic, enabling zero-shot transfer by plugging the modules into off-the-shelf world models of different games without retraining. The approach is evaluated on two Street Fighter games, claiming maintained player controllability and robust prompt-aligned NPC strategy adherence.
Significance. If the central claims hold, this work could significantly advance game world models by turning them into reactive simulation engines capable of modeling NPC reactivities. The decoupling and plug-and-play transfer mechanism offers a scalable way to add steerable NPC interactions across games, which is a notable contribution if the generalization to dissimilar games is demonstrated. The absence of quantitative results in the provided description makes it difficult to assess the practical impact at this stage.
major comments (2)
- [Abstract] Abstract: The claim that the cross-attention modules 'learn a game-agnostic representation of interactive logic' enabling 'zero-shot strategy transfer' to 'different games' lacks supporting evidence. The evaluation is described only for two Street Fighter games, which share near-identical action spaces, visual styles, and physics. No results or experiments are provided for transfer to world models with substantially different dynamics, such as varying physics or control vocabularies, which is necessary to substantiate the broader claim.
- [Abstract] Abstract: No quantitative metrics, ablation studies, or error analysis are mentioned despite the abstract stating that ReactiveGWM 'maintains fine-grain player controllability while achieving robust, prompt-aligned NPC strategy adherence'. This makes it impossible to verify the strength of the results or the robustness of the decoupling approach.
minor comments (1)
- [Abstract] The description of the architecture could benefit from more detail on how the lightweight additive bias for player actions is implemented and how it interacts with the cross-attention modules.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our claims and the presentation of results. We address each major comment below and describe the revisions planned for the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the cross-attention modules 'learn a game-agnostic representation of interactive logic' enabling 'zero-shot strategy transfer' to 'different games' lacks supporting evidence. The evaluation is described only for two Street Fighter games, which share near-identical action spaces, visual styles, and physics. No results or experiments are provided for transfer to world models with substantially different dynamics, such as varying physics or control vocabularies, which is necessary to substantiate the broader claim.
Authors: We appreciate this observation on the breadth of the generalization claim. Our experiments demonstrate zero-shot transfer of the cross-attention modules between two Street Fighter variants without retraining, where the games differ in character-specific movesets and minor visual/physics details. This supports high-level strategy decoupling from low-level game specifics. However, we acknowledge that these games are not substantially dissimilar in core dynamics. To strengthen the evidence, we will add new experiments transferring the modules to an off-the-shelf world model from a different genre (e.g., a platformer with distinct control vocabulary and physics) and include the results in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: No quantitative metrics, ablation studies, or error analysis are mentioned despite the abstract stating that ReactiveGWM 'maintains fine-grain player controllability while achieving robust, prompt-aligned NPC strategy adherence'. This makes it impossible to verify the strength of the results or the robustness of the decoupling approach.
Authors: We agree that the abstract would benefit from explicit reference to supporting evidence. The full manuscript reports quantitative results, including player controllability via action prediction accuracy and NPC strategy adherence via prompt alignment metrics, as well as ablation studies on the additive bias and cross-attention components and error analysis for edge cases. We will revise the abstract to summarize these key quantitative findings and metrics to better substantiate the claims. revision: yes
Circularity Check
No circularity: ReactiveGWM is presented as a new architectural construction
full rationale
The paper introduces ReactiveGWM by describing a decoupling of player controls (via additive bias) from NPC behaviors (via cross-attention modules) and asserts that the modules learn a game-agnostic representation enabling zero-shot transfer. No equations, derivations, or self-citations are provided in the text that reduce the transfer claim or the agnostic representation to a fitted quantity defined by the model itself or to prior author work. The approach is framed as a novel construction evaluated on Street Fighter variants rather than a closed derivation chain that collapses to its inputs by construction. This is the most common honest finding for model-proposal papers without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cross-attention modules can learn a game-agnostic representation of interactive logic
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Player actions are injected into the diffusion backbone via a lightweight additive bias, while high-level NPC responses (e.g., Offense, Control, Defense) are grounded through cross-attention modules. Crucially, these modules learn a game-agnostic representation of interactive logic.
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
This enables zero-shot strategy transfer: our learned modules can be plugged directly into off-the-shelf, unannotated world models of different games.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and François Fleuret. Diffusion for world modeling: Visual details matter in atari.Advances in Neural Information Processing Systems, 37:58757–58791, 2024
work page 2024
-
[2]
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Shaojie Bai, J. Zico Kolter, and Vladlen Koltun. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.arXiv:1803.01271, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, Jessica Yung, Ci...
work page 2025
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[6]
Street fighter II: Champion Edition
Capcom. Street fighter II: Champion Edition. Video game, 1992. Arcade
work page 1992
- [7]
-
[8]
Weifeng Chen, Yatai Ji, Jie Wu, Hefeng Wu, Pan Xie, Jiashi Li, Xin Xia, Xuefeng Xiao, and Liang Lin. Control-a-video: Controllable text-to-video diffusion models with motion prior and reward feedback learning.arXiv preprint arXiv:2305.13840, 2023
-
[9]
Oasis: A universe in a transformer.URL: https://oasis-model
Etched Decart, Quinn McIntyre, Spruce Campbell, Xinlei Chen, and Robert Wachen. Oasis: A universe in a transformer.URL: https://oasis-model. github. io, 2(3):6, 2024
work page 2024
-
[10]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
David Ha and Jürgen Schmidhuber. Recurrent world models facilitate policy evolution.Advances in neural information processing systems, 31, 2018
work page 2018
-
[12]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018. 10
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[14]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, pages 2555–2565. PMLR, 2019
work page 2019
-
[15]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[16]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Matrix-game 2.0: An open-source real-time and streaming interactive world model, 2026
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, Baixin Xu, Hao-Xiang Guo, Kaixiong Gong, Size Wu, Wei Li, Xuchen Song, Yang Liu, Yangguang Li, and Yahui Zhou. Matrix-game 2.0: An open-source real-time and streaming interactive world model, 2026
work page 2026
-
[18]
Animate anyone: Consistent and controllable image-to-video synthesis for character animation
Li Hu. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8153–8163, 2024
work page 2024
-
[19]
Animate anyone 2: High-fidelity character image animation with environment affordance
Li Hu, Guangyuan Wang, Zhen Shen, Xin Gao, Dechao Meng, Lian Zhuo, Peng Zhang, Bang Zhang, and Liefeng Bo. Animate anyone 2: High-fidelity character image animation with environment affordance. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10207–10217, 2025
work page 2025
-
[20]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Genie 2: A large-scale foundation world model
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Moufarek, Guy Scully, Jeremy Shar, Jimmy Shi, Stephen Spencer, Jessica Yung, Michael Dennis, Sultan Kenjeyev, Shangbang Long, Vlad Mnih, Harris Chan, Maxime Gazeau, Bonnie Li, Fabio Pardo, Luyu Wang, Lei Zhang, Frederic Besse, Tim Harley, Anna ...
work page 2024
-
[24]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
work page 2023
-
[25]
Open-Sora 2.0: Training a Commercial-Level Video Generation Model in $200k
Xiangyu Peng, Zangwei Zheng, Chenhui Shen, Tom Young, Xinying Guo, Binluo Wang, Hang Xu, Hongxin Liu, Mingyan Jiang, Wenjun Li, Yuhui Wang, Anbang Ye, Gang Ren, Qianran Ma, Wanying Liang, Xiang Lian, Xiwen Wu, Yuting Zhong, Zhuangyan Li, Chaoyu Gong, Guojun Lei, Leijun Cheng, Limin Zhang, Minghao Li, Ruijie Zhang, Silan Hu, Shijie Huang, Xiaokang Wang, Yu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Stable retro, a maintained fork of openai’s gym-retro
Mathieu Poliquin. Stable retro, a maintained fork of openai’s gym-retro. https://github.com/ Farama-Foundation/stable-retro, 2026
work page 2026
-
[27]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, et al. Mastering atari, go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
work page 2020
-
[29]
Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory
Skywork AI Matrix-Game Team. Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory. Technical report, 2026. 11
work page 2026
-
[30]
Vision bridge transformer at scale.arXiv preprint arXiv:2511.23199, 2025
Zhenxiong Tan, Zeqing Wang, Xingyi Yang, Songhua Liu, and Xinchao Wang. Vision bridge transformer at scale.arXiv preprint arXiv:2511.23199, 2025
-
[31]
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M. Dai, Anja Hauth, and et al. Gemini: A family of highly capable multimodal models, 2025
work page 2025
- [32]
-
[33]
Advancing open-source world models, 2026
Robbyant Team, Zelin Gao, Qiuyu Wang, Yanhong Zeng, Jiapeng Zhu, Ka Leong Cheng, Yixuan Li, Hanlin Wang, Yinghao Xu, Shuailei Ma, Yihang Chen, Jie Liu, Yansong Cheng, Yao Yao, Jiayi Zhu, Yihao Meng, Kecheng Zheng, Qingyan Bai, Jingye Chen, Zehong Shen, Yue Yu, Xing Zhu, Yujun Shen, and Hao Ouyang. Advancing open-source world models, 2026
work page 2026
-
[34]
Diffusion Models Are Real-Time Game Engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Videocomposer: Compositional video synthesis with motion controllability
Xiang Wang, Hangjie Yuan, Shiwei Zhang, Dayou Chen, Jiuniu Wang, Yingya Zhang, Yujun Shen, Deli Zhao, and Jingren Zhou. Videocomposer: Compositional video synthesis with motion controllability. Advances in Neural Information Processing Systems, 36:7594–7611, 2023
work page 2023
-
[37]
Zeqing Wang, Bowen Zheng, Xingyi Yang, Zhenxiong Tan, Yuecong Xu, and Xinchao Wang. Minute-long videos with dual parallelisms.Proceedings of the AAAI Conference on Artificial Intelligence, 40(12):10358– 10366, Mar. 2026
work page 2026
-
[38]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
work page 2004
-
[39]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[40]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
work page 2023
-
[41]
Draganything: Motion control for anything using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for anything using entity representation. In European Conference on Computer Vision, pages 331–348. Springer, 2024
work page 2024
-
[42]
Magicanimate: Temporally consistent human image animation using diffusion model
Zhongcong Xu, Jianfeng Zhang, Jun Hao Liew, Hanshu Yan, Jia-Wei Liu, Chenxu Zhang, Jiashi Feng, and Mike Zheng Shou. Magicanimate: Temporally consistent human image animation using diffusion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1481–1490, 2024
work page 2024
-
[43]
Direct-a-video: Customized video generation with user-directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user-directed camera movement and object motion. InACM SIGGRAPH 2024 Conference Papers, pages 1–12, 2024
work page 2024
-
[44]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Drag- nuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089, 2023
work page internal anchor Pith review arXiv 2023
-
[46]
Gamefactory: Creating new games with generative interactive videos
Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Gamefactory: Creating new games with generative interactive videos. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11590–11599, October 2025. 12
work page 2025
-
[47]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
work page 2018
-
[48]
Tora: Trajectory-oriented diffusion transformer for video generation
Zhenghao Zhang, Junchao Liao, Menghao Li, Zuozhuo Dai, Bingxue Qiu, Siyu Zhu, Long Qin, and Weizhi Wang. Tora: Trajectory-oriented diffusion transformer for video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2063–2073, 2025
work page 2063
-
[49]
Shenhao Zhu, Junming Leo Chen, Zuozhuo Dai, Zilong Dong, Yinghui Xu, Xun Cao, Yao Yao, Hao Zhu, and Siyu Zhu. Champ: Controllable and consistent human image animation with 3d parametric guidance. InEuropean Conference on Computer Vision, pages 145–162. Springer, 2024. 13 A Data construction This appendix details the data construction pipeline introduced i...
work page 2024
-
[50]
Sonic Boom? -> Control
-
[51]
Extended distance crouch/zoning posture? -> Control
-
[52]
Sustained forward movement OR >=2 close-range attacks? -> Offense
-
[53]
Otherwise -> Defense EDGE CASES: - Post-match KO/defeat/victory animation for most of clip -> npc_visible=false - Rendering broken or NPC missing/unidentifiable -> npc_visible=false - Ryu fireball does NOT count as Guile Sonic Boom Output EXACTLY this JSON object: { "npc_side": "left" or "right", "npc_visible": true or false, "category": "Control" | "Defe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.