Don't Stop Me Yet: Sampling Loss Minima via Dissipative Riemannian Mechanics
Pith reviewed 2026-05-19 15:27 UTC · model grok-4.3
The pith
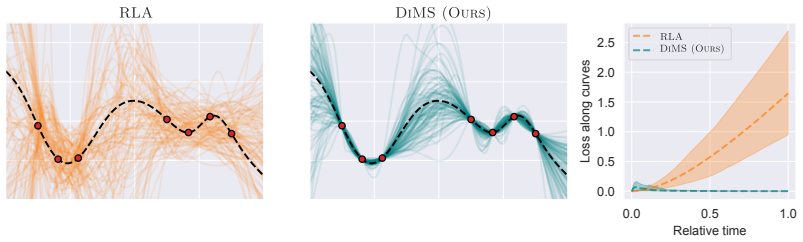
A new dynamical sampler called DiMS exactly targets the connected components of reparameterization-invariant minima in neural network losses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
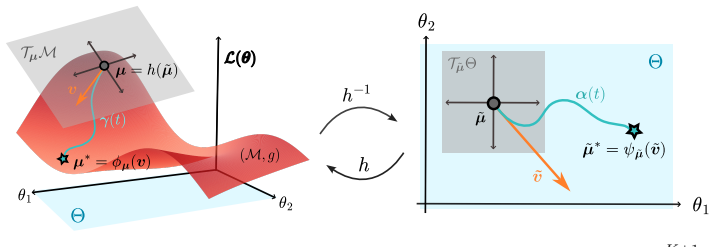
The minima of modern neural network loss functions typically form connected components of reparameterization invariant solutions on the training data. A dynamical system based on kinetic energy, subject to a gravitational pull and a friction term that dissipates energy, produces trajectories that are guaranteed to sample exactly from these minimum level sets rather than from larger low-loss regions or single valleys.
What carries the argument
Dissipative Riemannian dynamical system driven by kinetic energy, gravitational attraction to lower loss, and a friction term that removes energy until motion is confined to minimum level sets.
If this is right
- DiMS produces samples that remain exactly on the minimum level sets instead of diffusing through larger low-loss regions.
- The sampler can move between different minima valleys while respecting the reparameterization invariance constraint.
- Hyperparameters with direct physical interpretations let users adjust the degree of exploration.
- Uncertainty estimates derived from these samples outperform those obtained from previous local or diffusive methods in Bayesian inference tasks.
Where Pith is reading between the lines
- The same energy-dissipation construction could be adapted to sample symmetric solution sets in other high-dimensional non-convex problems outside neural networks.
- Exact sampling of reparameterization components may help isolate which directions in parameter space truly affect generalization versus those absorbed by symmetry.
- Running the sampler from multiple random initializations would produce an empirical map of distinct minima components that could be compared against theoretical predictions of connectivity.
Load-bearing premise
Minima of modern neural network loss functions typically form connected components of reparameterization invariant solutions on the training data.
What would settle it
Generate samples with DiMS and check whether every sample produces identical predictions on the training set and achieves exactly the minimum loss value; any deviation would show the sampler is not confined to the claimed level sets.
Figures





read the original abstract
The minima of modern neural network loss functions are typically not isolated, rather they form connected components of reparameterization invariant solutions on the training data. Analytically characterizing these solutions is a hard problem, but sampling approaches are feasible. By construction, existing methods either spread over low-loss regions, and thus do not sample reparameterization invariant solutions exactly, or are inherently local, which limits exploration of other minima valleys. We propose sampling such reparameterization invariant models using a dynamical system based on kinetic energy, subject to a gravitational pull and a friction term that dissipates energy from the system. Our proposed sampler, DiMS, is guaranteed to sample exactly from the minimum level sets and depends on physically motivated hyperparameters which allows control over the exploration capabilities of the sampler. We consider uncertainty quantification in Bayesian inference as the motivating problem and observe improved performance compared to previously proposed approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiMS, a sampler based on dissipative Riemannian dynamics that incorporates kinetic energy, a gravitational pull toward lower loss values, and a friction term. It claims that neural network loss minima typically form connected components of reparameterization-invariant solutions on the training data, and that the proposed dynamics are guaranteed to sample exactly from the corresponding minimum level sets. The approach is motivated by uncertainty quantification in Bayesian inference and reports improved performance over prior samplers.
Significance. If the exact-sampling guarantee can be established and the structural assumption on loss landscapes holds, the work offers a physically interpretable framework for targeting flat, reparameterization-invariant minima with controllable exploration via hyperparameters. This could strengthen Bayesian methods by avoiding both overly diffuse low-loss sampling and overly local exploration, addressing a recognized limitation in existing approaches.
major comments (3)
- [Abstract] Abstract: the central claim that DiMS 'is guaranteed to sample exactly from the minimum level sets' is presented as following directly from the construction of the dynamical system, yet no theorem, invariant-measure derivation, or even proof sketch is supplied. The guarantee is load-bearing and requires a formal statement (presumably in the section defining the Riemannian dynamics and friction term) showing that the invariant support coincides precisely with the minimum level sets under the stated constancy and connectedness assumptions.
- [Abstract] Abstract: the guarantee can hold only if the loss is exactly constant on the connected components of reparameterization-invariant solutions and the dynamics cannot escape them. The manuscript states this structural property as typical for modern networks but supplies no theorem, lemma, or experiment confirming constancy versus merely low-loss connectivity; if the loss varies inside putative components or reparameterization orbits do not exhaust the minima, the sampler targets a strictly larger set than claimed.
- [Abstract] The abstract asserts that the method 'depends on physically motivated hyperparameters which allows control over the exploration capabilities,' yet provides no quantitative analysis or ablation showing how the friction and gravitational parameters map to mixing time or coverage of distinct minima valleys. This control is advertised as a practical advantage and should be demonstrated with concrete scaling or sensitivity results.
minor comments (2)
- [Abstract] The abstract would be clearer if it briefly indicated the specific Riemannian metric employed (e.g., whether it is the Fisher information metric or a simpler choice) and the precise form of the friction term.
- Notation for the kinetic energy and gravitational potential should be introduced consistently when the dynamical system is first defined, to avoid ambiguity when later referring to energy dissipation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating planned revisions to strengthen the formal and empirical support for our claims while remaining faithful to the manuscript's content and assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that DiMS 'is guaranteed to sample exactly from the minimum level sets' is presented as following directly from the construction of the dynamical system, yet no theorem, invariant-measure derivation, or even proof sketch is supplied. The guarantee is load-bearing and requires a formal statement (presumably in the section defining the Riemannian dynamics and friction term) showing that the invariant support coincides precisely with the minimum level sets under the stated constancy and connectedness assumptions.
Authors: We agree that the exact-sampling guarantee requires an explicit formal statement. In the revised manuscript we will insert a theorem in the section on dissipative Riemannian dynamics. The theorem will establish that, under the assumptions of constant loss on connected components of reparameterization-invariant solutions and that the dynamics remain confined to those components, the unique invariant measure is supported precisely on the minimum level sets. A proof sketch will be supplied that combines the Hamiltonian structure of the kinetic term, the conservative gravitational force derived from the loss, and the dissipative friction term that drives the system to the level sets. revision: yes
-
Referee: [Abstract] Abstract: the guarantee can hold only if the loss is exactly constant on the connected components of reparameterization-invariant solutions and the dynamics cannot escape them. The manuscript states this structural property as typical for modern networks but supplies no theorem, lemma, or experiment confirming constancy versus merely low-loss connectivity; if the loss varies inside putative components or reparameterization orbits do not exhaust the minima, the sampler targets a strictly larger set than claimed.
Authors: The constancy assumption follows from the reparameterization invariance of the training loss for the architectures considered. We will add a short lemma that formally states this invariance property and its implication for level-set constancy. We will also include a modest empirical check on a toy network demonstrating near-constant loss along reparameterization orbits; we note that exhaustive verification on large-scale models remains an open empirical question and will be listed as a modeling assumption with discussion of possible deviations. revision: partial
-
Referee: [Abstract] The abstract asserts that the method 'depends on physically motivated hyperparameters which allows control over the exploration capabilities,' yet provides no quantitative analysis or ablation showing how the friction and gravitational parameters map to mixing time or coverage of distinct minima valleys. This control is advertised as a practical advantage and should be demonstrated with concrete scaling or sensitivity results.
Authors: We accept that the abstract claim on controllable exploration should be supported by quantitative evidence. The revised manuscript will contain a new ablation subsection that systematically varies the friction coefficient and gravitational strength. We will report estimated mixing times (via integrated autocorrelation) and coverage of distinct minima (via the number of unique basins visited across independent runs), together with sensitivity plots that illustrate the trade-off between exploration and convergence speed. revision: yes
Circularity Check
No circularity: guarantee follows from explicit dynamical system construction under stated landscape assumption
full rationale
The paper states the structural property of NN loss minima as a typical empirical fact (connected reparameterization-invariant components) and then constructs DiMS dynamics (kinetic energy + gravitational term + friction) whose invariant sets are exactly those level sets by design of the vector field. The exact-sampling guarantee is therefore a direct mathematical consequence of the ODE construction once the landscape assumption is granted; it is not obtained by fitting parameters to data, by renaming an input, or by a self-citation chain that itself lacks independent verification. No equation or claim reduces the target distribution to the fitted inputs by definition.
Axiom & Free-Parameter Ledger
free parameters (1)
- physically motivated hyperparameters
axioms (1)
- domain assumption Minima of modern neural network loss functions form connected components of reparameterization invariant solutions on the training data.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
¨α=−(˙αᵀHL(α)˙α+κ)·gradL(α)−η(t)·˙α with η(t)=η₀∥˙α∥√(1+∥∇L∥²cos²ω)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.26266 , year=
A Likely Geometry of Generative Models , author=. arXiv preprint arXiv:2510.26266 , year=
-
[2]
Neural Information Processing Systems (NeurIPS) , year=
Roy, Hrittik and Miani, Marco and Ek, Carl Henrik and Hennig, Philipp and Pf. Neural Information Processing Systems (NeurIPS) , year=
-
[3]
Neural Information Processing Systems (NeurIPS) , year=
Bergamin, Federico and Moreno-Mu. Neural Information Processing Systems (NeurIPS) , year=
-
[4]
Yu, Hanlin and Hartmann, Marcelo and Sanchez, Bernardo Williams Moreno and Girolami, Mark and Klami, Arto , booktitle=
-
[5]
Reichlin, Alfredo and Vasco, Miguel and Kragic Jensfelt, Danica , journal=
-
[6]
Roch, Hendrik and Shen, Chun , journal=
-
[7]
Li, Yiming and Qiu, Jiacheng and Calinon, Sylvain , journal=
-
[8]
Di Sipio, Riccardo and Diaz-Rodriguez, Jairo and Serrano, Luis , journal=
-
[9]
Hoffman, Matthew D and Gelman, Andrew and others , journal=
-
[10]
Welling, Max and Teh, Yee W , booktitle=
-
[11]
Ma, Yi-An and Chen, Yuansi and Jin, Chi and Flammarion, Nicolas and Jordan, Michael I , journal=
-
[12]
International Conference on Machine Learning (ICML) , year=
Papamarkou, Theodore and Skoularidou, Maria and Palla, Konstantina and Aitchison, Laurence and Arbel, Julyan and Dunson, David and Filippone, Maurizio and Fortuin, Vincent and Hennig, Philipp and Hern. International Conference on Machine Learning (ICML) , year=
-
[13]
Kristiadi, Agustinus and Eschenhagen, Runa and Hennig, Philipp , journal=
-
[14]
International Conference on Geometric Science of Information (GSI) , year=
Da Costa, Natha. International Conference on Geometric Science of Information (GSI) , year=
-
[15]
Minguzzi, Ettore , journal=
-
[16]
Cline, Douglas , year=
-
[17]
Neural Information Processing Systems (NeurIPS) , year=
Kr. Neural Information Processing Systems (NeurIPS) , year=
-
[18]
Kunstner, Frederik and Hennig, Philipp and Balles, Lukas , journal=
-
[19]
International Conference on Machine Learning (ICML) , year=
Immer, Alexander and Bauer, Matthias and Fortuin, Vincent and R. International Conference on Machine Learning (ICML) , year=
-
[20]
Daxberger, Erik and Kristiadi, Agustinus and Immer, Alexander and Eschenhagen, Runa and Bauer, Matthias and Hennig, Philipp , journal=
-
[21]
Immer, Alexander and Korzepa, Maciej and Bauer, Matthias , booktitle=
-
[22]
International conference on artificial intelligence and statistics , pages=
Do Bayesian neural networks need to be fully stochastic? , author=. International conference on artificial intelligence and statistics , pages=. 2023 , organization=
work page 2023
-
[23]
Advances in Neural Information Processing Systems , volume=
Should we learn most likely functions or parameters? , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
arXiv preprint arXiv:2602.00199 , year=
Reducing Memorisation in Generative Models via Riemannian Bayesian Inference , author=. arXiv preprint arXiv:2602.00199 , year=
- [25]
- [26]
-
[27]
Finsler-Lagrange geometry: Applications to dynamical systems , author=. 2007 , publisher=
work page 2007
-
[28]
Kovachki, Nikola B and Stuart, Andrew M , journal=
-
[29]
arXiv preprint arXiv:2510.23684 , year=
Fadel, Samuel G and Roy, Hrittik and Kr. arXiv preprint arXiv:2510.23684 , year=
-
[30]
Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs , year =
Garipov, Timur and Izmailov, Pavel and Podoprikhin, Dmitrii and Vetrov, Dmitry P and Wilson, Andrew G , booktitle =. Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs , year =
-
[31]
International Conference on Machine Learning (ICML) , year =
Essentially No Barriers in Neural Network Energy Landscape , author =. International Conference on Machine Learning (ICML) , year =
-
[32]
International Conference on Machine Learning (ICML) , year =
Sharp Minima Can Generalize For Deep Nets , author =. International Conference on Machine Learning (ICML) , year =
-
[33]
Neural Information Processing Systems (NeurIPS) , year =
Li, Hao and Xu, Zheng and Taylor, Gavin and Studer, Christoph and Goldstein, Tom , title=. Neural Information Processing Systems (NeurIPS) , year =
-
[34]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Sharpness-aware minimization for efficiently improving generalization , author=. arXiv preprint arXiv:2010.01412 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
Advances in neural information processing systems , volume=
Implicit bias of gradient descent on linear convolutional networks , author=. Advances in neural information processing systems , volume=
-
[36]
MacKay, David JC , journal=
-
[37]
Flat minima , author=. Neural computation , volume=. 1997 , publisher=
work page 1997
-
[38]
Chen, Tianqi and Fox, Emily and Guestrin, Carlos , booktitle=
-
[39]
Journal of the Royal Statistical Society Series B: Statistical Methodology , year=
Riemann manifold langevin and hamiltonian monte carlo methods , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , year=
-
[40]
Neal, Radford M , journal=
-
[41]
International Conference on Learning Representations , year=
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima , author=. International Conference on Learning Representations , year=
-
[42]
The role of permutation invariance in linear mode connectivity of neural networks , author=. arXiv preprint arXiv:2110.06296 , year=
-
[43]
Zhao, Bo and Dehmamy, Nima and Walters, Robin and Yu, Rose , booktitle =
- [44]
-
[45]
Nesterov, Yurii , booktitle=
-
[46]
Averaging Weights Leads to Wider Optima and Better Generalization
Averaging weights leads to wider optima and better generalization , author=. arXiv preprint arXiv:1803.05407 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advances in neural information processing systems , volume=
Simple and scalable predictive uncertainty estimation using deep ensembles , author=. Advances in neural information processing systems , volume=
-
[48]
Su, Weijie and Boyd, Stephen and Candes, Emmanuel J , journal=
-
[49]
Maddox, Wesley J and Izmailov, Pavel and Garipov, Timur and Vetrov, Dmitry P and Wilson, Andrew Gordon , journal=
-
[50]
arXiv preprint arXiv:2512.24381 , year=
Tubular Riemannian Laplace Approximations for Bayesian Neural Networks , author=. arXiv preprint arXiv:2512.24381 , year=
-
[51]
Lan, Shiwei and Stathopoulos, Vassilios and Shahbaba, Babak and Girolami, Mark , journal=
-
[52]
Advances in neural information processing systems , volume=
Sparse Gaussian processes using pseudo-inputs , author=. Advances in neural information processing systems , volume=
-
[53]
LeCun, Yann and Boser, Bernhard and Denker, John S and Henderson, Donnie and Howard, Richard E and Hubbard, Wayne and Jackel, Lawrence D , journal=
- [54]
-
[55]
Chen, Ricky TQ and Rubanova, Yulia and Bettencourt, Jesse and Duvenaud, David K , journal=
-
[56]
Dormand, John R. and Prince, Peter J. , journal=. 1980 , publisher=
work page 1980
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.