ICP: Exploiting Instruction Correlation for Prefetching Irregular Memory Accesses
Pith reviewed 2026-05-19 19:43 UTC · model grok-4.3
The pith
ICP prefetching exploits stable instruction correlations to handle irregular memory accesses more efficiently than address-based methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ICP observes that although memory addresses may not repeat, the instructions generating them often recur with stable data-dependency relationships. By learning these persistent instruction correlations, ICP speculatively computes and prefetches future irregular accesses using the execution results of their correlated predecessors. Across irregular SPEC CPU and GAP benchmarks, this yields 14 percent higher performance than the temporal prefetcher Triangel and 6 percent higher than the indirect prefetcher DMP while using only 2.1 KB of hardware storage.
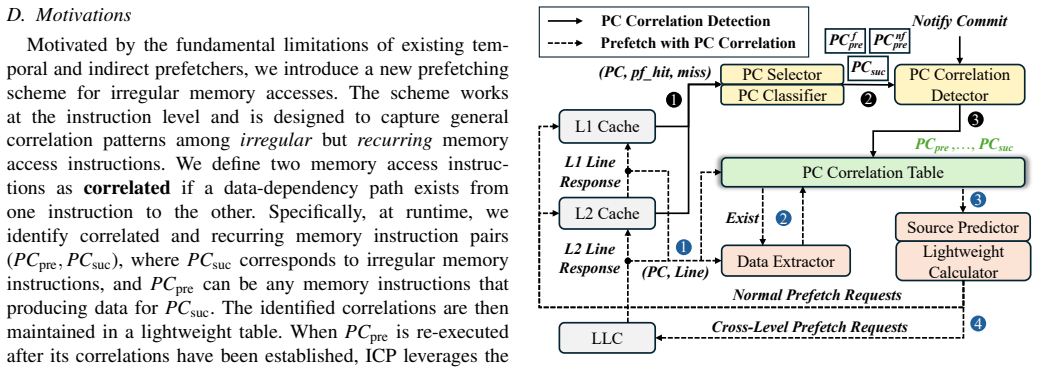
What carries the argument
Instruction-Correlation Prefetching (ICP), a hardware mechanism that learns recurring instruction-level correlations with stable data dependencies to speculatively compute and prefetch future irregular memory accesses from predecessor results.
If this is right
- Performance improves by 14 percent over state-of-the-art temporal prefetchers on irregular SPEC CPU and GAP benchmarks.
- Storage overhead drops to 2.1 KB, more than three orders of magnitude below typical temporal prefetcher tables.
- Indirect memory accesses become practical to prefetch without relying on address recurrence.
- The same correlation-tracking logic could be applied to other irregular patterns that defeat address-history methods.
Where Pith is reading between the lines
- Hardware designs with tight area budgets for metadata tables may favor instruction-correlation tracking over large address-history buffers.
- Similar dependency-correlation ideas could extend to other front-end optimizations such as value prediction or load scheduling.
- Combining ICP with lightweight address-based prefetchers might yield further gains on mixed regular and irregular code.
Load-bearing premise
The assumption that instructions generating irregular addresses recur with stable data-dependency relationships even when the addresses themselves show weak or no temporal recurrence.
What would settle it
Running ICP on a workload whose instructions lack stable correlations, such as one with fully randomized address generation, and observing zero or negative performance change would show the claim does not hold.
Figures












read the original abstract
Irregular memory accesses pose challenges for effective and efficient data prefetching. While temporal prefetchers have recently shown promise for irregular memory access patterns, their effectiveness fundamentally depends on temporal address recurrence and large metadata storage. When memory addresses exhibit weak or no recurrence, as in indirect memory accesses, temporal prefetchers achieve limited performance gains while incurring substantial storage overhead. This paper proposes Instruction-Correlation Prefetching (ICP), a new hardware prefetching mechanism that exploits instruction-level correlations rather than memory-address correlations to handle irregular memory accesses. ICP observes that although memory addresses may not repeat, the instructions generating them often recur with stable data-dependency relationships. By learning these persistent instruction correlations, ICP speculatively computes and prefetches future irregular accesses using the execution results of their correlated predecessors. Across irregular SPEC CPU and GAP benchmarks, ICP outperforms the state-of-the-art temporal prefetcher Triangel by 14.0% and the indirect prefetcher DMP by 6.0%, while requiring only 2.1 KB of hardware storage, over three orders of magnitude smaller than temporal prefetchers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Instruction-Correlation Prefetching (ICP), a hardware prefetcher for irregular memory accesses that learns stable data-dependency relationships among recurring instructions rather than relying on temporal address recurrence. By speculatively computing future addresses from correlated predecessor instructions, ICP targets cases where address recurrence is weak. On irregular SPEC CPU and GAP benchmarks, it reports 14% speedup over the temporal prefetcher Triangel and 6% over the indirect prefetcher DMP, using only 2.1 KB of storage.
Significance. If the empirical results and underlying stability assumption hold under broader conditions, ICP would represent a meaningful advance by achieving competitive prefetching gains for irregular accesses at storage costs three orders of magnitude below temporal schemes. This could influence future prefetcher designs in processors handling pointer-chasing or graph workloads.
major comments (2)
- [§5] §5 (Evaluation): The central performance claims rest on the premise that instruction data-dependency relationships remain stable enough for speculative address computation. However, the reported results use fixed benchmark inputs on SPEC CPU and GAP; no experiments vary inputs, induce phase changes, or employ adaptive data structures to test whether correlations break and accuracy collapses, leaving the generalization of the 14% and 6% gains unsupported.
- [§3] §3 (ICP Design): The description of how ICP detects and records instruction correlations lacks a quantitative metric or threshold for 'stable' relationships. Without this, it is unclear how the mechanism distinguishes persistent dependencies from transient ones that would produce incorrect prefetches.
minor comments (2)
- [Abstract] Abstract and §1: The storage figure of 2.1 KB is stated without reference to the exact table or configuration that produces it; add a cross-reference.
- [Figure 3] Figure 3: Axis labels and legend are too small for readability; enlarge fonts and ensure all prefetcher variants are clearly distinguished.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below with point-by-point responses. We agree that additional validation of correlation stability and explicit design details would strengthen the paper and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation): The central performance claims rest on the premise that instruction data-dependency relationships remain stable enough for speculative address computation. However, the reported results use fixed benchmark inputs on SPEC CPU and GAP; no experiments vary inputs, induce phase changes, or employ adaptive data structures to test whether correlations break and accuracy collapses, leaving the generalization of the 14% and 6% gains unsupported.
Authors: We acknowledge that our current evaluation relies on standard fixed inputs for the SPEC CPU and GAP benchmarks. The instruction correlations targeted by ICP arise from program structure and data dependencies that tend to persist across inputs for the same algorithmic kernels. Nevertheless, we agree that direct testing under input variation and phase changes would better support generalization of the reported speedups. We will add such experiments to the revised manuscript, including runs with alternate inputs and induced phase shifts where feasible, to quantify correlation stability and any resulting impact on prefetch accuracy. revision: yes
-
Referee: [§3] §3 (ICP Design): The description of how ICP detects and records instruction correlations lacks a quantitative metric or threshold for 'stable' relationships. Without this, it is unclear how the mechanism distinguishes persistent dependencies from transient ones that would produce incorrect prefetches.
Authors: We appreciate this observation. Section 3 explains that ICP records an instruction correlation only after the pair has been observed repeatedly with matching data-dependency outcomes. This repeated observation serves as the filter against transient relationships. We will revise the manuscript to state the quantitative threshold explicitly (minimum observation count) and describe the consistency check used to discard transient dependencies, thereby clarifying how the design avoids issuing prefetches based on unstable correlations. revision: yes
Circularity Check
No circularity: empirical hardware design with no self-referential derivations
full rationale
The paper proposes ICP as a prefetching mechanism that learns persistent instruction correlations to speculatively compute irregular addresses. No equations, fitted parameters, or derivation steps appear in the abstract or description that reduce any claim to its own inputs by construction. Performance results are presented as direct benchmark outcomes (14% over Triangel, 6% over DMP) rather than predictions derived from self-citations or ansatzes. The central premise rests on an empirical observation about instruction recurrence, which is externally falsifiable via benchmarks and does not rely on load-bearing self-citations or uniqueness theorems from prior author work. This is a standard self-contained design paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Instructions generating irregular memory addresses recur with stable data-dependency relationships.
Reference graph
Works this paper leans on
- [1]
- [2]
-
[3]
Ghostminion: A strictness-ordered cache system for spectre mitigation,
S. Ainsworth, “Ghostminion: A strictness-ordered cache system for spectre mitigation,” inMICRO, 2021
work page 2021
-
[4]
Graph prefetching using data structure knowledge,
S. Ainsworth and T. M. Jones, “Graph prefetching using data structure knowledge,” inICS, 2016, pp. 1–11
work page 2016
-
[5]
Software prefetching for indirect memory accesses,
S. Ainsworth and T. M. Jones, “Software prefetching for indirect memory accesses,” inCGO, 2017, pp. 305–317
work page 2017
-
[6]
Software prefetching for indirect memory accesses: A microarchitectural perspective,
S. Ainsworth and T. M. Jones, “Software prefetching for indirect memory accesses: A microarchitectural perspective,”TOCS, pp. 1–34, 2019
work page 2019
-
[7]
Triangel: A high-performance, accu- rate, timely on-chip temporal prefetcher,
S. Ainsworth and L. Mukhanov, “Triangel: A high-performance, accu- rate, timely on-chip temporal prefetcher,” inISCA, 2024
work page 2024
-
[8]
Lightweight ml-based runtime prefetcher selection on many-core platforms,
E. S. Alcorta, M. Madhav, S. Tetrick, N. J. Yadwadkar, and A. Gerst- lauer, “Lightweight ml-based runtime prefetcher selection on many-core platforms,”arXiv preprint arXiv:2307.08635, 2023
-
[9]
An effective on-chip preloading scheme to reduce data access penalty,
J.-L. Baer and T.-F. Chen, “An effective on-chip preloading scheme to reduce data access penalty,” inProceedings of the 1991 ACM/IEEE conference on Supercomputing, 1991, pp. 176–186
work page 1991
-
[10]
Domino temporal data prefetcher,
M. Bakhshalipour, P. Lotfi-Kamran, and H. Sarbazi-Azad, “Domino temporal data prefetcher,” inHPCA, 2018, pp. 131–142
work page 2018
-
[11]
Bingo spatial data prefetcher,
M. Bakhshalipour, M. Shakerinava, P. Lotfi-Kamran, and H. Sarbazi- Azad, “Bingo spatial data prefetcher,” inHPCA, 2019, pp. 399–411
work page 2019
-
[12]
S. Beamer, K. Asanovi ´c, and D. Patterson, “The gap benchmark suite,” arXiv preprint arXiv:1508.03619, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Dspatch: Dual spatial pattern prefetcher,
R. Bera, A. V . Nori, O. Mutlu, and S. Subramoney, “Dspatch: Dual spatial pattern prefetcher,” inMICRO, 2019, pp. 531–544
work page 2019
-
[14]
N. Binkert, B. Beckmann, G. Black, S. K. Reinhardt, A. Saidi, A. Basu, J. Hestness, D. R. Hower, T. Krishna, S. Sardashtiet al., “The gem5 simulator,”ACM SIGARCH computer architecture news, 2011
work page 2011
-
[15]
D. Callahan, K. Kennedy, and A. Porterfield, “Software prefetching,” ACM SIGARCH Computer Architecture News, vol. 19, no. 2, pp. 40– 52, 1991
work page 1991
-
[16]
Introducing hierarchy-awareness in replacement and bypass algorithms for last-level caches,
M. Chaudhuri, J. Gaur, N. Bashyam, S. Subramoney, and J. Nuzman, “Introducing hierarchy-awareness in replacement and bypass algorithms for last-level caches,” inPACT, 2012, pp. 293–304
work page 2012
-
[17]
Data access microarchitectures for superscalar processors with compiler-assisted data prefetching,
W. Y . Chen, S. A. Mahlke, P. P. Chang, and W.-m. W. Hwu, “Data access microarchitectures for superscalar processors with compiler-assisted data prefetching,” inMICRO, 1991, pp. 69–73
work page 1991
-
[18]
Effectiveness of hardware-based stride and sequential prefetching in shared-memory multiprocessors,
F. Dahlgren and P. Stenstrom, “Effectiveness of hardware-based stride and sequential prefetching in shared-memory multiprocessors,” in HPCA, 1995, pp. 68–77
work page 1995
-
[19]
Differential- matching prefetcher for indirect memory access,
G. Fu, T. Xia, Z. Luo, R. Chen, W. Zhao, and P. Ren, “Differential- matching prefetcher for indirect memory access,” inHPCA, 2024, pp. 439–453
work page 2024
-
[20]
Magellan: A high-performance loop-guided prefetcher for indirect memory access,
G. Fu, T. Xia, M. Yin, P. J. Nair, M. Lis, and P. Ren, “Magellan: A high-performance loop-guided prefetcher for indirect memory access,” inISCA, 2025, pp. 601–615
work page 2025
-
[21]
G. Gerogiannis and J. Torrellas, “Micro-armed bandit: Lightweight & reusable reinforcement learning for microarchitecture decision-making,” inMICRO, 2023
work page 2023
-
[22]
Compiler- directed data prefetching in multiprocessors with memory hierarchies,
E. H. Gornish, E. D. Granston, and A. V . Veidenbaum, “Compiler- directed data prefetching in multiprocessors with memory hierarchies,” inICS, 1990, pp. 128–142
work page 1990
-
[23]
Dsdp: Dual stream data prefetcher,
M. He, H. Wang, K. Zhou, K. Cui, H. Yan, C. Guo, and R. He, “Dsdp: Dual stream data prefetcher,” inPACT, 2022, pp. 372–383
work page 2022
-
[24]
1.1 computing’s energy problem (and what we can do about it),
M. Horowitz, “1.1 computing’s energy problem (and what we can do about it),” inISSCC, 2014, pp. 10–14
work page 2014
-
[25]
Memory prefetching using adaptive stream detec- tion,
I. Hur and C. Lin, “Memory prefetching using adaptive stream detec- tion,” inMICRO, 2006, pp. 397–408
work page 2006
-
[26]
Access map pattern matching for data cache prefetch,
Y . Ishii, M. Inaba, and K. Hiraki, “Access map pattern matching for data cache prefetch,” inICS, 2009, pp. 499–500
work page 2009
-
[27]
Linearizing irregular memory accesses for improved correlated prefetching,
A. Jain and C. Lin, “Linearizing irregular memory accesses for improved correlated prefetching,” inMICRO, 2013, pp. 247–259
work page 2013
-
[28]
Apt-get: Profile-guided timely software prefetching,
S. Jamilan, T. A. Khan, G. Ayers, B. Kasikci, and H. Litz, “Apt-get: Profile-guided timely software prefetching,” inEurosys, 2022, pp. 747– 764
work page 2022
-
[29]
Merging similar patterns for hardware prefetching,
S. Jiang, Q. Yang, and Y . Ci, “Merging similar patterns for hardware prefetching,” inMICRO, 2022, pp. 1012–1026
work page 2022
-
[30]
N. P. Jouppi, “Improving direct-mapped cache performance by the addition of a small fully-associative cache and prefetch buffers,”ACM SIGARCH Computer Architecture News, vol. 18, no. 2SI, pp. 364–373, 1990
work page 1990
-
[31]
Dmon: Ef- ficient detection and correction of data locality problems using selective profiling,
T. A. Khan, I. Neal, G. Pokam, B. Mozafari, and B. Kasikci, “Dmon: Ef- ficient detection and correction of data locality problems using selective profiling,” inOSDI, 2021, pp. 163–181
work page 2021
-
[32]
Path confidence based lookahead prefetching,
J. Kim, S. H. Pugsley, P. V . Gratz, A. N. Reddy, C. Wilkerson, and Z. Chishti, “Path confidence based lookahead prefetching,” inMICRO, 2016, pp. 1–12
work page 2016
-
[33]
Stride-directed prefetching for sec- ondary caches,
S. Kim and A. V . Veidenbaum, “Stride-directed prefetching for sec- ondary caches,” inICPP, 1997, pp. 314–321
work page 1997
-
[34]
Division of labor: A more effective approach to prefetching,
S. Kondguli and M. Huang, “Division of labor: A more effective approach to prefetching,” inISCA, 2018
work page 2018
-
[35]
Profile- guided temporal prefetching,
M. Li, Q. Zhang, Y . Gao, W. Fang, Y . Lu, Y . Ren, and Z. Xie, “Profile- guided temporal prefetching,” inISCA, 2025
work page 2025
-
[36]
Integrating prefetcher selection with dynamic request allocation improves prefetching efficiency,
M. Li, Q. Zhang, Y . Ren, and Z. Xie, “Integrating prefetcher selection with dynamic request allocation improves prefetching efficiency,” in HPCA, 2025
work page 2025
-
[37]
Best-offset hardware prefetching,
P. Michaud, “Best-offset hardware prefetching,” inHPCA, 2016, pp. 469–480
work page 2016
-
[38]
Cacti 6.0: A tool to model large caches,
N. Muralimanohar, R. Balasubramonian, and N. P. Jouppi, “Cacti 6.0: A tool to model large caches,”HP laboratories, vol. 27, p. 28, 2009
work page 2009
-
[39]
A. Naithani, S. Ainsworth, T. M. Jones, and L. Eeckhout, “Vector runahead,” inISCA, 2021, pp. 195–208
work page 2021
-
[40]
A. Naithani, J. Roelandts, S. Ainsworth, T. M. Jones, and L. Eeckhout, “Decoupled vector runahead,” inMICRO, 2023, pp. 17–31
work page 2023
-
[41]
Berti: an accurate local-delta data prefetcher,
A. Navarro-Torres, B. Panda, J. Alastruey-Bened ´e, P. Ib´a˜nez, V . Vi˜nals- Y´ufera, and A. Ros, “Berti: an accurate local-delta data prefetcher,” in MICRO, 2022, pp. 975–991
work page 2022
-
[42]
Data cache prefetching using a global history buffer,
K. J. Nesbit and J. E. Smith, “Data cache prefetching using a global history buffer,” inHPCA, 2004, pp. 96–96
work page 2004
-
[43]
Bouquet of instruction pointers: Instruction pointer classifier-based spatial hardware prefetching,
S. Pakalapati and B. Panda, “Bouquet of instruction pointers: Instruction pointer classifier-based spatial hardware prefetching,” inISCA, 2020
work page 2020
-
[44]
Sandbox prefetching: Safe run-time evaluation of aggressive prefetchers,
S. H. Pugsley, Z. Chishti, C. Wilkerson, P.-f. Chuang, R. L. Scott, A. Jaleel, S.-L. Lu, K. Chow, and R. Balasubramonian, “Sandbox prefetching: Safe run-time evaluation of aggressive prefetchers,” in HPCA, 2014, pp. 626–637
work page 2014
-
[45]
A cost-effective entangling prefetcher for instructions,
A. Ros and A. Jimborean, “A cost-effective entangling prefetcher for instructions,” inProceedings of the 48th Annual International Symposium on Computer Architecture (ISCA). IEEE, 2021, pp. 99–111, entangling instruction prefetcher that selects triggering instruction pairs for timely prefetching. [Online]. Available: https: //doi.org/10.1109/ISCA52012.2021.00099
-
[46]
Automatically characterizing large scale program behavior,
T. Sherwood, E. Perelman, G. Hamerly, and B. Calder, “Automatically characterizing large scale program behavior,”ACM SIGPLAN Notices, pp. 45–57, 2002
work page 2002
-
[47]
Efficiently prefetching complex address pat- terns,
M. Shevgoor, S. Koladiya, R. Balasubramonian, C. Wilkerson, S. H. Pugsley, and Z. Chishti, “Efficiently prefetching complex address pat- terns,” inMICRO, 2015, pp. 141–152
work page 2015
-
[48]
S. Somogyi, T. F. Wenisch, A. Ailamaki, B. Falsafi, and A. Moshovos, “Spatial memory streaming,”ACM SIGARCH Computer Architecture News, pp. 252–263, 2006
work page 2006
-
[49]
Criticality-based optimizations for efficient load processing,
S. Subramaniam, A. Bracy, H. Wang, and G. H. Loh, “Criticality-based optimizations for efficient load processing,” inHPCA, 2009
work page 2009
-
[50]
N. Talati, K. May, A. Behroozi, Y . Yang, K. Kaszyk, C. Vasiladiotis, T. Verma, L. Li, B. Nguyen, J. Sunet al., “Prodigy: Improving the memory latency of data-indirect irregular workloads using hardware- software co-design,” inHPCA, 2021, pp. 654–667
work page 2021
-
[51]
Practical off-chip meta-data for temporal memory streaming,
T. F. Wenisch, M. Ferdman, A. Ailamaki, B. Falsafi, and A. Moshovos, “Practical off-chip meta-data for temporal memory streaming,” inHPCA, 2009, pp. 79–90
work page 2009
-
[52]
Ship: Signature- based hit predictor for high performance caching,
C. J. Wu, G. H. Loh, M. D. Smith, and D. M. Brooks, “Ship: Signature- based hit predictor for high performance caching,” inMICRO, 2011
work page 2011
-
[53]
Practical temporal prefetching with compressed on-chip metadata,
H. Wu, K. Nathella, M. Pabst, D. Sunwoo, A. Jain, and C. Lin, “Practical temporal prefetching with compressed on-chip metadata,” IEEE Transactions on Computers, pp. 2858–2871, 2021
work page 2021
-
[54]
Temporal prefetching without the off-chip metadata,
H. Wu, K. Nathella, J. Pusdesris, D. Sunwoo, A. Jain, and C. Lin, “Temporal prefetching without the off-chip metadata,” inMICRO, 2019, pp. 996–1008
work page 2019
-
[55]
Efficient metadata management for irregular data prefetching,
H. Wu, K. Nathella, D. Sunwoo, A. Jain, and C. Lin, “Efficient metadata management for irregular data prefetching,” inISCA, 2019, pp. 449–461. 14
work page 2019
-
[56]
Hitting the memory wall: Implications of the obvious,
W. A. Wulf and S. A. McKee, “Hitting the memory wall: Implications of the obvious,”ACM SIGARCH computer architecture news, vol. 23, no. 1, pp. 20–24, 1995
work page 1995
-
[57]
Tyche: An efficient and general prefetcher for indirect memory accesses,
F. Xue, C. Han, X. Li, J. Wu, T. Zhang, T. Liu, Y . Hao, Z. Du, Q. Guo, and F. Zhang, “Tyche: An efficient and general prefetcher for indirect memory accesses,”ACM Transactions on Architecture and Code Optimization, pp. 1–26, 2024
work page 2024
-
[58]
Imp: Indirect memory prefetcher,
X. Yu, C. J. Hughes, N. Satish, and S. Devadas, “Imp: Indirect memory prefetcher,” inMICRO, 2015, pp. 178–190
work page 2015
-
[59]
Resemble: reinforced ensemble framework for data prefetching,
P. Zhang, R. Kannan, A. Srivastava, A. V . Nori, and V . K. Prasanna, “Resemble: reinforced ensemble framework for data prefetching,” inSC, 2022
work page 2022
-
[60]
Rpg2: Robust profile-guided runtime prefetch generation,
Y . Zhang, N. Sobotka, S. Park, S. Jamilan, T. A. Khan, B. Kasikci, G. A. Pokam, H. Litz, and J. Devietti, “Rpg2: Robust profile-guided runtime prefetch generation,” inASPLOS, 2024, pp. 999–1013. 15
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.