Evaluating Container Orchestration for Neuromorphic Workloads in Virtual Edge Environments
Pith reviewed 2026-05-19 19:04 UTC · model grok-4.3
pith:JFZYJZM6 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{JFZYJZM6}
Prints a linked pith:JFZYJZM6 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
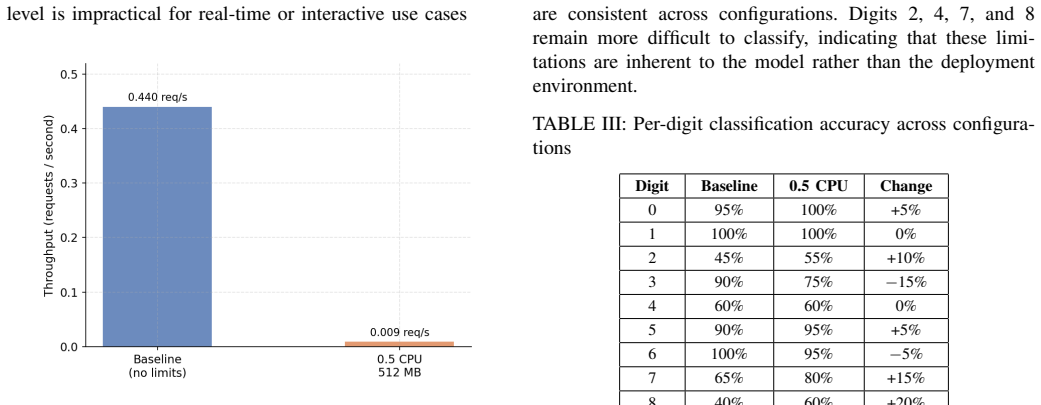
SNN workloads are highly sensitive to CPU restrictions in Kubernetes-based virtual edge environments, with 0.5 cores causing 47.6 times higher latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Spiking neural network workloads prove highly sensitive to resource availability when deployed in a single-node K3d Kubernetes cluster on a virtualized Windows host. Limiting CPU to 0.5 cores raises median latency by 47.6 times and cuts throughput by 49 times, with accuracy holding steady in all successful runs. The cluster handles deployment and scaling of the workloads, yet the default routing policy produces high tail latency for scaled replicas, pointing to a mismatch for inference tasks.
What carries the argument
Resource restriction experiments on SNN inference in K3d, measuring latency, throughput, accuracy, and overhead under different CPU and memory allocations.
If this is right
- Adequate CPU provisioning is necessary to prevent extreme latency increases and throughput losses in containerized SNN deployments.
- Default Kubernetes load balancing strategies lead to significant tail latencies for concurrent SNN inference replicas.
- Neuromorphic workloads can be orchestrated successfully if memory limits are not exceeded.
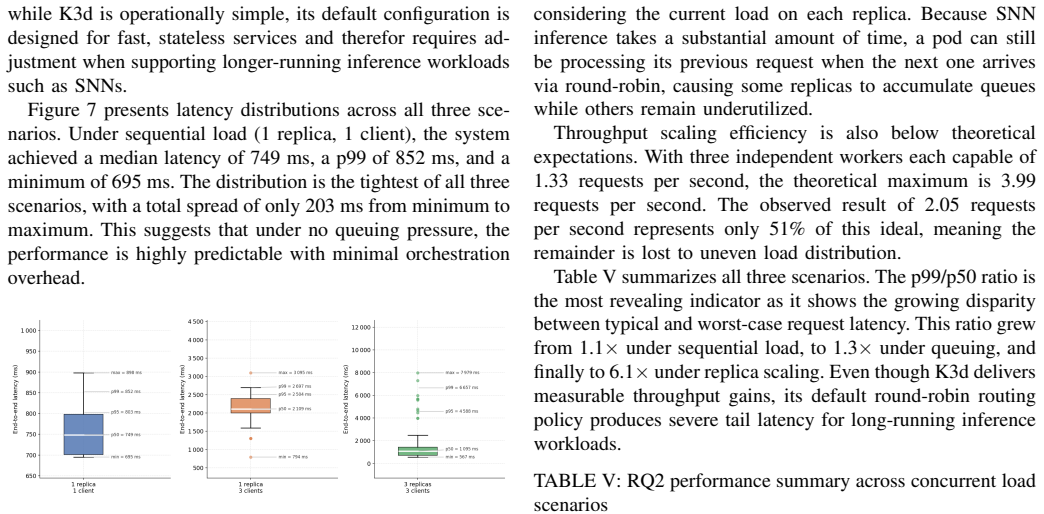
- SNN classification accuracy remains consistent regardless of resource constraints that permit execution.
Where Pith is reading between the lines
- The findings could extend to physical edge hardware, implying similar resource tuning needs for real deployments.
- Custom orchestration policies might better match the event-driven nature of SNNs to reduce tail latencies.
- Future optimizations could focus on memory efficiency to allow more constrained configurations without failure.
Load-bearing premise
A single-node K3d cluster on Windows 11 with WSL2 and Docker Desktop represents typical virtual edge environments and SNN behavior.
What would settle it
Repeating the CPU restriction tests to 0.5 cores on physical edge devices and checking if latency multiplies by approximately 47.6 times and throughput drops by 49 times.
Figures






read the original abstract
The growing adoption of edge computing has created an increasing need for workloads capable of operating under strict resource and energy constraints. Neuromorphic computing, and spiking neural networks (SNNs) in particular, offers an energy-efficient alternative to conventional machine learning through event-driven computation. However, how SNN workloads behave when deployed within modern container orchestration frameworks, especially in edge environments, remains largely unexplored. This paper investigates the feasibility of deploying and orchestrating SNN workloads in a virtual edge environment using Kubernetes, focusing on end-to-end latency, throughput, classification accuracy, infrastructure overhead, and runtime behavior under concurrent load. Experiments were conducted on a single-node K3d cluster running on a Windows 11 host with WSL2 and Docker Desktop. The results show that SNN workloads are highly sensitive to resource availability. Restricting CPU to 0.5 cores increased median latency by 47.6x and reduced throughput by 49x, while the most constrained configuration failed due to insufficient memory. Classification accuracy remained stable across all working configurations. From an orchestration perspective, K3d successfully deployed and scaled SNN workloads, though its default round-robin routing policy introduced significant tail latency under replica scaling, highlighting a mismatch between stateless load-balancing assumptions and long-running inference workloads. Overall, this study provides a baseline for deploying neuromorphic workloads in containerized edge environments and highlights the importance of resource provisioning and orchestration configuration. Future work should explore improved routing strategies, memory optimization, and validation on physical edge hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates the deployment of spiking neural network (SNN) workloads using the K3d Kubernetes distribution in a virtual edge environment simulated via a single-node cluster on Windows 11 with WSL2 and Docker Desktop. It reports that SNN workloads are highly sensitive to CPU resource restrictions, with a 0.5-core limit causing a 47.6x increase in median latency and 49x reduction in throughput while classification accuracy remains stable across viable configurations. The work also notes that K3d can deploy and scale the workloads but that its default round-robin policy produces high tail latency, and positions the study as a baseline for container-orchestrated neuromorphic edge computing.
Significance. If the quantitative sensitivity results hold, the paper supplies a useful empirical baseline on resource provisioning for event-driven neuromorphic workloads under container orchestration, an area that has received limited prior attention. The identification of a mismatch between stateless load-balancing assumptions and long-running inference tasks is a practical observation that could inform future orchestration designs for edge AI.
major comments (1)
- Abstract and experimental setup description: The central claims of 47.6x median latency increase and 49x throughput drop at 0.5 CPU cores rest entirely on measurements from a single-node K3d cluster atop Windows 11 + WSL2 + Docker Desktop. This stack introduces additional scheduling, memory-mapping, and I/O layers absent from native Linux/ARM edge nodes. No direct comparison (e.g., cgroups-only vs. full virtualization or perf-counter isolation of host overhead) is reported, so the observed multipliers may partly reflect the experimental platform rather than intrinsic SNN behavior under container orchestration. This directly affects the interpretation of the results as a model for virtual edge environments.
minor comments (2)
- Abstract: The statement that 'classification accuracy remained stable across all working configurations' would be strengthened by reporting the number of trials, variance, or confidence intervals; the current phrasing leaves the robustness of the stability claim unclear.
- The manuscript mentions 'infrastructure overhead' as one of the investigated aspects but does not supply concrete metrics (e.g., CPU or memory overhead percentages) for this quantity in the results summary.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential value of this work as an empirical baseline. We address the major comment below.
read point-by-point responses
-
Referee: Abstract and experimental setup description: The central claims of 47.6x median latency increase and 49x throughput drop at 0.5 CPU cores rest entirely on measurements from a single-node K3d cluster atop Windows 11 + WSL2 + Docker Desktop. This stack introduces additional scheduling, memory-mapping, and I/O layers absent from native Linux/ARM edge nodes. No direct comparison (e.g., cgroups-only vs. full virtualization or perf-counter isolation of host overhead) is reported, so the observed multipliers may partly reflect the experimental platform rather than intrinsic SNN behavior under container orchestration. This directly affects the interpretation of the results as a model for virtual edge environments.
Authors: We agree that the chosen platform (single-node K3d on Windows 11 + WSL2 + Docker Desktop) introduces virtualization layers not present on native Linux/ARM edge hardware, and that no isolation experiments (e.g., cgroups-only or perf-counter measurements) were performed to quantify host overhead separately. The manuscript is explicitly scoped to virtual edge environments, and this stack was selected to enable reproducible container-orchestration experiments with K3d. The reported sensitivity results therefore characterize SNN behavior under the full containerized virtual setup rather than claiming to isolate intrinsic neuromorphic properties. In revision we will add an explicit limitations paragraph in the experimental setup section that discusses these platform-specific factors and their possible contribution to the observed multipliers. We will also expand the future-work paragraph to prioritize native-hardware validation. These textual changes will clarify the scope without altering the core claims. revision: yes
Circularity Check
No circularity: purely empirical benchmarking with direct measurements
full rationale
The paper reports experimental results from running SNN workloads on a single-node K3d cluster, measuring latency, throughput, accuracy, and orchestration behavior under CPU/memory restrictions. No derivations, equations, predictive models, or first-principles claims appear in the abstract or described content. All reported multipliers (e.g., 47.6x latency increase) are direct observations from the testbed rather than outputs of any fitted function or self-referential construction. The study is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The virtual K3d environment on WSL2 accurately simulates edge computing conditions for SNN workloads
Reference graph
Works this paper leans on
-
[1]
Neuro-inspired task offloading in edge-IoT networks using spiking neural networks
F. D. Rossi, “Neuro-inspired task offloading in edge-IoT networks using spiking neural networks.” [Online]. Available: http://arxiv.org/ abs/2511.01127
-
[2]
Edge intelligence with spiking neural networks
S. Deng, D. Yu, C. Lv, X. Du, L. Jiang, X. Zhao, W. Tong, X. Zheng, W. Fang, P. Zhao, G. Pan, S. Dustdar, and A. Y . Zomaya, “Edge intelligence with spiking neural networks.” [Online]. Available: http://arxiv.org/abs/2507.14069
-
[3]
Container orchestration and kubernetes enhancements,
S. Das, “Container orchestration and kubernetes enhancements,” vol. 16, no. 1. [Online]. Available: https://www.ijsat.org/research-paper.php?id= 2594
-
[4]
jennyhpham/distributed neuro sim,
J. Pham, “jennyhpham/distributed neuro sim,” original-date: 2025- 12-10T21:06:43Z. [Online]. Available: https://github.com/jennyhpham/ distributed neuro sim
work page 2025
-
[5]
Neuromorphic computing at scale,
D. Kudithipudi, C. Schuman, C. M. Vineyard, T. Pandit, C. Merkel, R. Kubendran, J. B. Aimone, G. Orchard, C. Mayr, R. Benosman, J. Hays, C. Young, C. Bartolozzi, A. Majumdar, S. G. Cardwell, M. Payvand, S. Buckley, S. Kulkarni, H. A. Gonzalez, G. Cauwenberghs, C. S. Thakur, A. Subramoney, and S. Furber, “Neuromorphic computing at scale,” vol. 637, no. 804...
-
[6]
A survey on neuromorphic computing: Models and hardware,
A. Shrestha, H. Fang, Z. Mei, D. P. Rider, Q. Wu, and Q. Qiu, “A survey on neuromorphic computing: Models and hardware,” vol. 22, no. 2, pp. 6–35. [Online]. Available: https: //ieeexplore.ieee.org/abstract/document/9782767
-
[7]
Exploring neuromorphic computing based on spiking neural networks: Algorithms to hardware,
N. Rathi, I. Chakraborty, A. Kosta, A. Sengupta, A. Ankit, P. Panda, and K. Roy, “Exploring neuromorphic computing based on spiking neural networks: Algorithms to hardware,” vol. 55, no. 12, pp. 243:1–243:49. [Online]. Available: https://dl.acm.org/doi/10.1145/3571155
-
[8]
Exploring temporal information dynamics in spiking neural networks
Y . Kim, Y . Li, H. Park, Y . Venkatesha, A. Hambitzer, and P. Panda, “Exploring temporal information dynamics in spiking neural networks.” [Online]. Available: http://arxiv.org/abs/2211.14406
-
[9]
Spiking Deep Networks with LIF Neurons
E. Hunsberger and C. Eliasmith, “Spiking deep networks with LIF neurons.” [Online]. Available: http://arxiv.org/abs/1510.08829
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Spiking neural networks and their applications: A review,
K. Yamazaki, V .-K. V o-Ho, D. Bulsara, and N. Le, “Spiking neural networks and their applications: A review,” vol. 12, no. 7, p. 863, publisher: Multidisciplinary Digital Publishing Institute. [Online]. Available: https://www.mdpi.com/2076-3425/12/7/863
work page 2076
-
[11]
Learning rules in spiking neural networks: A survey,
Z. Yi, J. Lian, Q. Liu, H. Zhu, D. Liang, and J. Liu, “Learning rules in spiking neural networks: A survey,” vol. 531, pp. 163–179. [Online]. Available: https://www.sciencedirect.com/science/article/pii/ S0925231223001662
-
[12]
Y . Dong, D. Zhao, Y . Li, and Y . Zeng, “An unsupervised STDP-based spiking neural network inspired by biologically plausible learning rules and connections,” vol. 165, pp. 799–808. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0893608023003301
-
[13]
TrueNorth: Accelerating from zero to 64 million neurons in 10 years,
M. V . DeBole, B. Taba, A. Amir, F. Akopyan, A. Andreopoulos, W. P. Risk, J. Kusnitz, C. Ortega Otero, T. K. Nayak, R. Appuswamy, P. J. Carlson, A. S. Cassidy, P. Datta, S. K. Esser, G. J. Garreau, K. L. Holland, S. Lekuch, M. Mastro, J. McKinstry, C. di Nolfo, B. Paulovicks, J. Sawada, K. Schleupen, B. G. Shaw, J. L. Klamo, M. D. Flickner, J. V . Arthur,...
-
[14]
Loihi: A neuromorphic manycore processor with on-chip learning,
M. Davies, N. Srinivasa, T.-H. Lin, G. Chinya, Y . Cao, S. H. Choday, G. Dimou, P. Joshi, N. Imam, S. Jain, Y . Liao, C.-K. Lin, A. Lines, R. Liu, D. Mathaikutty, S. McCoy, A. Paul, J. Tse, G. Venkataramanan, Y .-H. Weng, A. Wild, Y . Yang, and H. Wang, “Loihi: A neuromorphic manycore processor with on-chip learning,” vol. 38, no. 1, pp. 82–99. [Online]. ...
-
[15]
SpiNNaker 2: A 10 million core processor system for brain simulation and machine learning
C. Mayr, S. Hoeppner, and S. Furber, “SpiNNaker 2: A 10 million core processor system for brain simulation and machine learning.” [Online]. Available: http://arxiv.org/abs/1911.02385
-
[16]
BindsNET: A machine learning-oriented spiking neural networks library in python,
H. Hazan, D. J. Saunders, H. Khan, D. Patel, D. T. Sanghavi, H. T. Siegelmann, and R. Kozma, “BindsNET: A machine learning-oriented spiking neural networks library in python,” vol. 12. [Online]. Available: https://www.frontiersin.org/journals/ neuroinformatics/articles/10.3389/fninf.2018.00089/full
-
[17]
Edge computing: Vision and challenges,
W. Shi, J. Cao, Q. Zhang, Y . Li, and L. Xu, “Edge computing: Vision and challenges,” vol. 3, no. 5, pp. 637–646. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/7488250
-
[18]
An overview on edge computing research,
K. Cao, Y . Liu, G. Meng, and Q. Sun, “An overview on edge computing research,” vol. 8, pp. 85 714–85 728. [Online]. Available: https://ieeexplore.ieee.org/document/9083958
-
[19]
A comprehensive review on edge computing - architecture, algorithm, and devices,
A. G. P, A. Madhumitha, B. P. Swathi, G. R. M, and B. Vanaja, “A comprehensive review on edge computing - architecture, algorithm, and devices,” vol. 11, no. 11, pp. 545–553. [Online]. Available: https://ijirt.org/IJIRT|AnUGCCompliantPeerreviewedJournal| InternationalOpenAccessJournal
-
[20]
J. Qi, C. Liu, X. Zhang, L. Wang, R. Wang, J. Dong, and Y . Yu, “A survey on open-source edge computing simulators and emulators: The computing and networking convergence perspective.” [Online]. Available: http://arxiv.org/abs/2505.09995
-
[21]
Fogify: A fog computing emulation framework,
M. Symeonides, Z. Georgiou, D. Trihinas, G. Pallis, and M. D. Dikaiakos, “Fogify: A fog computing emulation framework,” in2020 IEEE/ACM Symposium on Edge Computing (SEC), pp. 42–54. [Online]. Available: https://ieeexplore.ieee.org/document/9355701
-
[22]
B. Burns, B. Grant, D. Oppenheimer, E. Brewer, and J. Wilkes, “Borg, omega, and kubernetes,” vol. 59, no. 5, pp. 50–57. [Online]. Available: https://dl.acm.org/doi/10.1145/2890784
-
[23]
Skydiver: A spiking neural network accelerator exploiting spatio-temporal workload balance,
Q. Chen, C. Gao, X. Fang, and H. Luan, “Skydiver: A spiking neural network accelerator exploiting spatio-temporal workload balance,” vol. 41, no. 12, pp. 5732–5736. [Online]. Available: http://arxiv.org/ abs/2203.07516
-
[24]
EdgeMap: An optimized mapping toolchain for spiking neural network in edge computing,
J. Xue, L. Xie, F. Chen, L. Wu, Q. Tian, Y . Zhou, R. Ying, and P. Liu, “EdgeMap: An optimized mapping toolchain for spiking neural network in edge computing,” vol. 23, no. 14. [Online]. Available: https://www.mdpi.com/1424-8220/23/14/6548
-
[25]
Performance evaluation of container orchestration tools in edge computing environments,
I. ˇCili´c, P. Krivi ´c, I. Podnar ˇZarko, and M. Ku ˇsek, “Performance evaluation of container orchestration tools in edge computing environments,” vol. 23, no. 8, p. 4008, publisher: Multidisciplinary Digital Publishing Institute. [Online]. Available: https://www.mdpi.com/ 1424-8220/23/8/4008
-
[26]
Performance Evaluation of Deep Learning Tools in Docker Containers
P. Xu, S. Shi, and X. Chu, “Performance evaluation of deep learning tools in docker containers.” [Online]. Available: http: //arxiv.org/abs/1711.03386
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
M. V . DeBole, R. Appuswamy, N. McGlohon, B. Taba, S. K. Esser, F. Akopyan, J. V . Arthur, A. Amir, A. Andreopoulos, P. J. Carlson, A. S. Cassidy, P. Datta, M. D. Flickner, R. Gandhasri, G. J. Garreau, M. Ito, J. L. Klamo, J. A. Kusnitz, N. J. McClatchey, J. L. McKinstry, T. K. Nayak, C. O. Otero, H. Penner, W. P. Risk, J. Sawada, J. Sivagnaname, D. F. Sm...
- [28]
-
[29]
Unsupervised learning of digit recognition using spike-timing-dependent plasticity,
P. U. Diehl and M. Cook, “Unsupervised learning of digit recognition using spike-timing-dependent plasticity,” vol. 9. [Online]. Avail- able: https://www.frontiersin.org/journals/computational-neuroscience/ articles/10.3389/fncom.2015.00099/full
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.