Lost or Hidden? A Concept-Level Forgetting in Supervised Continual Learning
Pith reviewed 2026-05-20 22:03 UTC · model grok-4.3
The pith
Much of concept forgetting in continual learning reflects reduced accessibility rather than outright erasure of information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
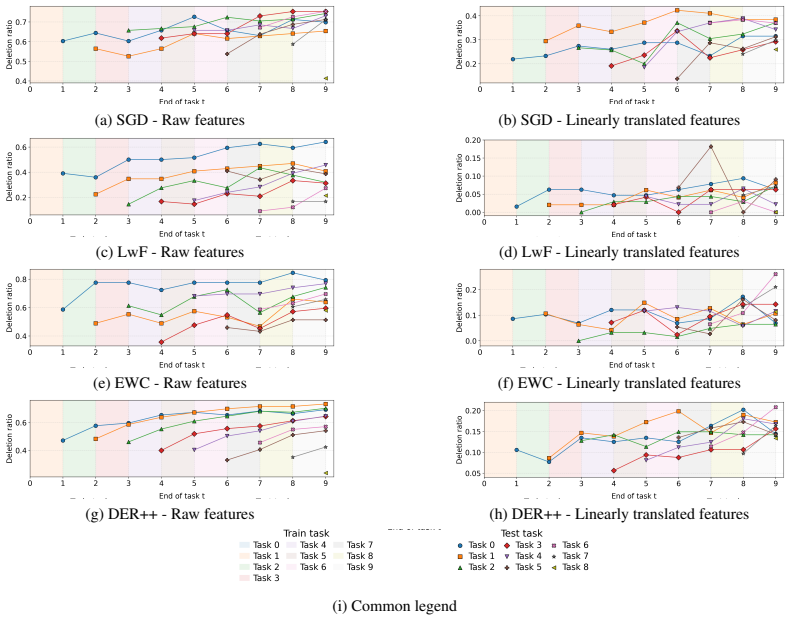
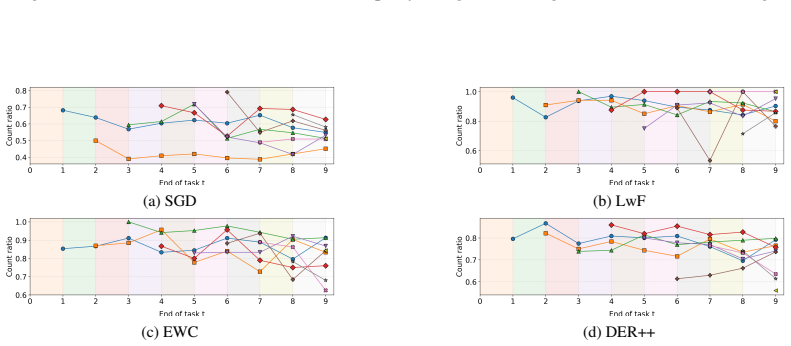
We propose a diagnostic framework leveraging Sparse Autoencoders to define a task-anchored latent feature space. This enables decomposing forgetting into apparent concept deletion, recoverability, and decodability. We show that a large portion of seemingly lost concept-level information can often be recovered under linearity assumption, with concept decodability degrading as more tasks are introduced. Overall, our findings suggest that a significant part of concept-level forgetting can be attributed to changes in the representational accessibility rather than complete information erasure.
What carries the argument
The task-anchored latent feature space from Sparse Autoencoders, treating individual latents as proxies for recurring and relatively disentangled visual patterns to decompose forgetting into deletion, recoverability, and decodability.
If this is right
- Linear recovery methods could restore performance on old tasks without retraining the full model.
- Decodability of concepts declines as the number of tasks grows, indicating a practical limit on how many tasks can be learned sequentially.
- Forgetting can be split into recoverable and truly deleted categories, allowing targeted fixes instead of blanket prevention of drift.
- Standard accuracy metrics underestimate retained knowledge because they do not test internal accessibility.
Where Pith is reading between the lines
- Similar diagnostic frameworks could be tested on language models to see whether forgetting there also stems more from access issues than erasure.
- Continual learning algorithms might add explicit mechanisms to maintain linear decodability of prior concepts.
- Benchmarks for continual learning could incorporate recoverability tests alongside final task accuracy to better measure true retention.
Load-bearing premise
The recoverability analysis rests on treating individual SAE latents as reliable proxies for distinct visual patterns combined with the assumption that linear combinations can recover seemingly lost information.
What would settle it
An experiment showing that linear probes on 'recovered' latents fail to improve accuracy on prior tasks, or that the latents do not consistently map to the same visual patterns across tasks, would falsify the central claim.
Figures





read the original abstract
Continual learning studies how models can adapt to new tasks while retaining previously acquired knowledge. Although a broad spectrum of methods has been proposed to mitigate catastrophic forgetting, the field remains predominantly performance-driven, with limited insight into what forgetting actually corresponds to within the vision model's representation space. Prior work has primarily analyzed forgetting through task-level performance or coarse measures of representational drift, without disentangling output-level accessibility from changes in finer-grained internal structure. To this end, we propose a diagnostic framework that leverages Sparse Autoencoders (SAEs) to define a task-anchored latent feature space, enabling analysis of how task-specific information evolves at a finer granularity, where individual SAE latents are treated as concept proxies for recurring and relatively disentangled visual patterns in the model's internal computations. Within this framework, we decompose forgetting into apparent concept deletion, recoverability, and decodability. We show that a large portion of seemingly lost concept-level information can often be recovered under linearity assumption, with concept decodability degrading as more tasks are introduced. Overall, our findings suggest that a significant part of concept-level forgetting can be attributed to changes in the representational accessibility rather than complete information erasure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a diagnostic framework for concept-level forgetting in supervised continual learning. It uses Sparse Autoencoders (SAEs) to construct a task-anchored latent feature space in which individual latents act as proxies for recurring, relatively disentangled visual patterns. Forgetting is decomposed into apparent concept deletion, recoverability (under a linearity assumption), and decodability. The central empirical claim is that a large fraction of seemingly lost concept information remains recoverable via linear probes, implying that much of the observed forgetting reflects reduced representational accessibility rather than outright erasure; decodability is reported to degrade as the number of tasks increases.
Significance. If the recoverability decomposition and accessibility interpretation hold after validation, the work supplies a finer-grained mechanistic account of forgetting that goes beyond task-level accuracy or coarse representational drift. This could guide the development of continual-learning methods that explicitly target accessibility rather than assuming erasure. The SAE-based proxy approach is a concrete methodological contribution that may be reusable in other representation analyses.
major comments (3)
- [§3.2] §3.2 (definition of task-anchored latent feature space): the claim that SAE latents reliably index recurring and relatively disentangled visual patterns that persist across tasks is introduced without independent verification (no ablation on SAE training, no human or automated concept-consistency checks across task boundaries). Because the entire deletion/recoverability/decodability decomposition rests on these latents, the quantitative attribution to accessibility is not yet load-bearing.
- [§5] §5 (recoverability analysis): recoverability percentages are obtained under an explicit linearity assumption for linear probes on the SAE latents. No experiment tests whether non-linear recovery would materially change the reported fractions; if non-linear structure is required, the accessibility-versus-erasure distinction does not follow from the current metrics.
- [Results] Results section / Table reporting recoverability: the manuscript presents aggregate recoverability figures but does not report per-run variance, confidence intervals, or sensitivity to SAE hyperparameters and task ordering. This makes it difficult to judge whether the “large portion” claim is robust or sensitive to modeling choices.
minor comments (2)
- [Abstract] Abstract: quantitative recoverability percentages, dataset names, and number of tasks are omitted; adding one or two concrete numbers would improve readability.
- [§4] Notation: the precise formulas for the deletion, recoverability, and decodability metrics should be stated in a single early subsection rather than scattered across the decomposition paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the validation needs for our SAE-based diagnostic framework. We respond to each major comment below and have revised the manuscript accordingly to include additional verification, non-linear experiments, and statistical reporting.
read point-by-point responses
-
Referee: [§3.2] §3.2 (definition of task-anchored latent feature space): the claim that SAE latents reliably index recurring and relatively disentangled visual patterns that persist across tasks is introduced without independent verification (no ablation on SAE training, no human or automated concept-consistency checks across task boundaries). Because the entire deletion/recoverability/decodability decomposition rests on these latents, the quantitative attribution to accessibility is not yet load-bearing.
Authors: We agree that stronger verification of the SAE latents as proxies strengthens the foundation of the decomposition. In the revision we add an ablation varying SAE sparsity and dictionary size, plus automated consistency checks via activation cosine similarity and reconstruction overlap across task boundaries. These support that many latents track recurring patterns. We also expand the discussion to note the proxy nature of the approach and the practical limits of exhaustive human validation. revision: yes
-
Referee: [§5] §5 (recoverability analysis): recoverability percentages are obtained under an explicit linearity assumption for linear probes on the SAE latents. No experiment tests whether non-linear recovery would materially change the reported fractions; if non-linear structure is required, the accessibility-versus-erasure distinction does not follow from the current metrics.
Authors: The linearity assumption is intentional, as linear probes provide a direct, standard measure of representational accessibility. To address the concern we have added non-linear probe experiments (two-layer MLPs) in the revised §5. Non-linear recovery yields modestly higher fractions, yet the core observation of substantial recoverability persists and the accessibility interpretation remains supported. We have updated the text to present both linear and non-linear results side-by-side. revision: yes
-
Referee: Results section / Table reporting recoverability: the manuscript presents aggregate recoverability figures but does not report per-run variance, confidence intervals, or sensitivity to SAE hyperparameters and task ordering. This makes it difficult to judge whether the “large portion” claim is robust or sensitive to modeling choices.
Authors: We accept that aggregate figures alone limit assessment of robustness. The revised results section and tables now report per-run standard deviations, 95% bootstrap confidence intervals, and sensitivity sweeps over SAE hyperparameters (sparsity, width) and task permutations. These analyses confirm that the reported recoverability levels remain high and stable across the tested variations. revision: yes
Circularity Check
No significant circularity; decomposition defined independently of fitted outputs
full rationale
The paper introduces a diagnostic framework that defines a task-anchored SAE latent space and then decomposes concept-level forgetting into deletion, recoverability, and decodability as distinct analytical categories. Recoverability is measured by applying a linearity assumption to probe whether information can be recovered from the latents; this is an empirical measurement step rather than a quantity that reduces by construction to parameters fitted on the target metrics. No equations or definitions are shown where a prediction is statistically forced by prior fitting on the same data, nor is the central attribution to accessibility justified solely by self-citation chains. The SAE proxies and linearity assumption are introduced as modeling choices at the framework definition stage, but the resulting percentages are not tautological with those choices. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Individual SAE latents serve as proxies for recurring and relatively disentangled visual patterns in the model's internal computations
- domain assumption Linearity assumption allows recovery of seemingly lost concept-level information
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We decompose forgetting into apparent concept deletion, recoverability, and decodability... a large portion of seemingly lost concept-level information can often be recovered under linearity assumption
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
individual SAE latents are treated as concept proxies for recurring and relatively disentangled visual patterns
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. Aswal and C. Hudelot. ConceptGuard: Neuro-Symbolic Safety Guardrails via Sparse Interpretable Jailbreak Concepts, 2025
work page 2025
-
[2]
Mechanistic Interpretability for AI Safety -- A Review
L. Bereska and E. Gavves. Mechanistic Interpretability for AI Safety – A Review.arXiv preprint arXiv:2404.14082, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
A. Bian, W. Li, H. Yuan, C. Yu, M. Wang, Z. Zhao, A. Lu, P. Ji, and T. Feng. Make Continual Learning Stronger via C-Flat.Advances in Neural Information Processing Systems, 37:7608– 7630, 2024
work page 2024
-
[4]
M. Boschini, L. Bonicelli, P. Buzzega, A. Porrello, and S. Calderara. Class-Incremental Continual Learning into the eXtended DER-verse.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022
work page 2022
-
[5]
P. Buzzega, M. Boschini, A. Porrello, D. Abati, and S. Calderara. Dark Experience for General Continual Learning: a Strong, Simple Baseline.Advances in Neural Information Processing Systems, 33:15920–15930, 2020
work page 2020
- [6]
-
[7]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. InIEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
work page 2009
-
[8]
J. Dunefsky, P. Chlenski, and N. Nanda. Transcoders Find Interpretable LLM Feature Circuits. Advances in Neural Information Processing Systems, 37:24375–24410, 2024
work page 2024
-
[9]
N. Elhage, T. Hume, C. Olsson, N. Schiefer, T. Henighan, S. Kravec, Z. Hatfield-Dodds, R. Lasenby, D. Drain, C. Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [10]
-
[11]
J. Gallifant, S. Chen, K. Sasse, H. Aerts, T. Hartvigsen, and D. Bitterman. Sparse Autoencoder Features for Classifications and Transferability. InConference on Empirical Methods in Natural Language Processing, pages 29927–29951, 2025
work page 2025
-
[12]
Q. Gu, D. Shim, and F. Shkurti. Preserving linear separability in continual learning by backward feature projection. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24286–24295, 2023
work page 2023
-
[13]
K. He, X. Zhang, S. Ren, and J. Sun. Deep Residual Learning for Image Recognition. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
- [14]
- [15]
- [16]
-
[17]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):3521–3526, 2017
work page 2017
-
[18]
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton. Similarity of Neural Network Representations Revisited. InInternational Conference on Machine Learning, 2019
work page 2019
-
[19]
A. Krizhevsky, G. Hinton, et al. Learning Multiple Layers of Features from Tiny Images. 2009
work page 2009
- [20]
- [21]
-
[22]
Putting a Face to Forgetting: Continual Learning meets Mechanistic Interpretability
S. Masip, G. M. van de Ven, J. Ferrando, and T. Tuytelaars. Putting a Face to Forgetting: Continual Learning meets Mechanistic Interpretability.arXiv preprint arXiv:2601.22012, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
M. Pach, S. Karthik, Q. Bouniot, S. Belongie, and Z. Akata. Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models.Advances in Neural Information Process- ing Systems, 2025
work page 2025
-
[24]
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter. Continual Lifelong Learning with Neural Networks: A Review.Neural Networks, 113:54–71, 2019
work page 2019
-
[25]
D. Rolnick, A. Ahuja, J. Schwarz, T. Lillicrap, and G. Wayne. Experience Replay for Continual Learning.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[26]
A. Soutif-Cormerais, A. Carta, A. Cossu, J. Hurtado, V . Lomonaco, J. Van de Weijer, and H. Hemati. A Comprehensive Empirical Evaluation on Online Continual Learning. InIEEE/CVF International Conference on Computer Vision, pages 3518–3528, 2023
work page 2023
-
[27]
E. Verwimp, R. Aljundi, S. Ben-David, M. Bethge, A. Cossu, A. Gepperth, et al. Continual Learning: Applications and the Road Forward.Transactions on Machine Learning Research, 2024
work page 2024
-
[28]
L. Wang, X. Zhang, H. Su, and J. Zhu. A Comprehensive Survey of Continual Learning: Theory, Method and Application.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, 2024. 11 A Concept definition In this work, we understood aconceptas a computational representation of a shared, recurring pattern that helps a model structure i...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.