Mixing Times of Glauber Dynamics on Masked Language Models
Pith reviewed 2026-05-20 22:22 UTC · model grok-4.3
The pith
Iterative masked token resampling in MLMs forms a Glauber chain that mixes in O(n log n) time at high temperature but shows metastability at low temperature.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating MLM generation as Glauber dynamics on the discrete space of token sequences, the authors establish that bounded cross-token influence produces a high-temperature contraction implying O(n log n) mixing time, while a uniform local margin condition produces metastability with exponentially slow escape from semantic basins at low temperatures.
What carries the argument
Glauber dynamics Markov chain on token sequences, driven by local MLM conditionals, with contraction mapping at high temperature and metastability analysis at low temperature.
If this is right
- Generation at high temperature produces reliable sampling without long-lived traps when influence remains bounded.
- Low-temperature regimes trap the chain in recurrent semantic basins for exponential durations.
- Mixing exhibits a sharp phase transition as a function of temperature and sequence length.
- Induced stationary distributions contain measurable persistent structures such as long-lived traps.
Where Pith is reading between the lines
- The same contraction-versus-metastability tradeoff may appear in other iterative token-sampling schemes.
- Temperature schedules could be chosen explicitly to avoid exponential trapping on long sequences.
- Empirical checks for the bounded-influence condition on new models would predict their practical mixing behavior.
Load-bearing premise
The masked language models satisfy either bounded cross-token influence or a uniform local margin condition.
What would settle it
Direct computation of mixing time scaling with sequence length at high temperature under bounded influence, or measurement of escape time from semantic basins at low temperature under the margin condition, would confirm or refute the predicted bounds.
Figures






read the original abstract
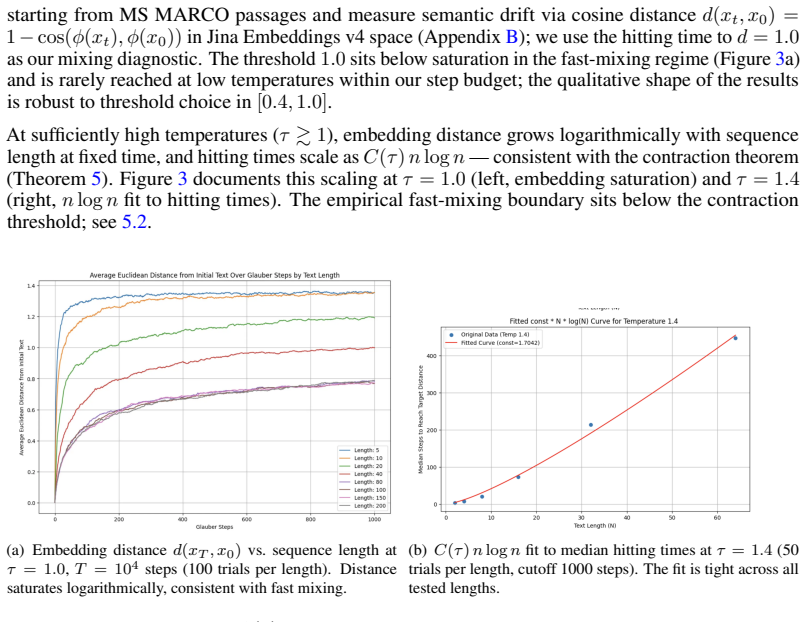
Masked language models (MLMs) define local conditional distributions over tokens but do not, in general, correspond to any consistent joint distribution over sequences. This raises a fundamental question: what global distributional behavior is induced when such conditionals are used iteratively for generation? We address this question by modeling iterative masked-token resampling as a Glauber dynamics Markov chain on the discrete space of token sequences. We first show that MLM conditionals are intrinsically incompatible: we introduce a rectangle test that certifies this incompatibility and empirically verify its prevalence across modern MLMs. We then provide a theoretical analysis of the induced Markov chain. Under bounded cross-token influence, we establish a high-temperature contraction result implying $O(n\log n)$ mixing time where $n$ is the sequence length. In contrast, we prove that under a uniform local margin condition, the chain exhibits metastability, with exponentially slow escape from semantic basins at low temperatures. Empirically, we demonstrate a phase transition in mixing behavior as a function of temperature and sequence length, consistent with the theoretical predictions. We further characterize the induced stationary behavior through semantic trajectories, identifying persistent structures such as long-lived traps and recurrent semantic basins, with political content serving as a measurable case study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript models iterative masked-token resampling in masked language models as Glauber dynamics on token sequences. It introduces a rectangle test to certify incompatibility of the conditionals and empirically verifies its prevalence. Under bounded cross-token influence, a high-temperature contraction yields O(n log n) mixing time. Under uniform local margin, the chain exhibits metastability with exponentially slow escape from semantic basins at low temperatures. Empirically, a phase transition in mixing behavior is shown as a function of temperature and length, with further characterization of stationary behavior via semantic trajectories and a political-content case study.
Significance. If the stated conditions hold, the work supplies a Markov-chain framework linking local MLM conditionals to global sampling dynamics, including explicit mixing and metastability bounds. The rectangle test and the empirical phase-transition results are concrete contributions. The combination of Dobrushin-style contraction analysis with metastability arguments from statistical physics is a strength when the assumptions are satisfied.
major comments (2)
- [§4] §4 (High-temperature contraction): The O(n log n) mixing-time claim rests on the total influence sum being bounded by a constant strictly less than 1 uniformly in n. The manuscript does not report direct numerical estimates of these influence sums on the concrete MLMs and temperatures used in the experiments, so it is unclear whether the high-temperature regime is actually attained.
- [§5] §5 (Metastability): The exponential escape-time lower bound requires a uniform local margin condition. No direct measurements of this margin on the studied models and low-temperature regimes are provided, leaving the applicability of the metastability result to the empirical phase transition unverified.
minor comments (2)
- [§3] Clarify how the rectangle test is computed in practice (e.g., number of token pairs sampled and tolerance thresholds).
- [Empirical results] Add error bars or multiple random seeds to the mixing-time and phase-transition plots to quantify variability.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below and will revise the paper to strengthen the connection between our theoretical assumptions and the reported experiments.
read point-by-point responses
-
Referee: [§4] §4 (High-temperature contraction): The O(n log n) mixing-time claim rests on the total influence sum being bounded by a constant strictly less than 1 uniformly in n. The manuscript does not report direct numerical estimates of these influence sums on the concrete MLMs and temperatures used in the experiments, so it is unclear whether the high-temperature regime is actually attained.
Authors: We agree that reporting direct numerical estimates of the total influence sums on the specific MLMs and temperatures used in the experiments would make the applicability of the high-temperature contraction result clearer. In the revised manuscript we will add these computations for the models and temperature settings appearing in the empirical phase-transition studies, confirming that the sums remain strictly below 1 in the high-temperature regime. revision: yes
-
Referee: [§5] §5 (Metastability): The exponential escape-time lower bound requires a uniform local margin condition. No direct measurements of this margin on the studied models and low-temperature regimes are provided, leaving the applicability of the metastability result to the empirical phase transition unverified.
Authors: We acknowledge that direct measurements of the uniform local margin on the studied models and low-temperature regimes would help verify the applicability of the metastability lower bound to the observed empirical phase transitions. In the revision we will include these margin measurements for the low-temperature settings used in the experiments. revision: yes
Circularity Check
Derivation is self-contained under explicit assumptions with no reduction to inputs by construction
full rationale
The paper models MLM resampling as Glauber dynamics and derives an O(n log n) mixing time via a high-temperature contraction under the bounded cross-token influence assumption, using standard Dobrushin-style analysis on the Markov chain. The metastability claim similarly follows from proving slow escape under the uniform local margin condition. Neither result is obtained by fitting parameters to the target mixing times or by redefining quantities in terms of themselves; the rectangle test is an independent empirical diagnostic for incompatibility, and the phase-transition experiments are presented as consistency checks rather than as the source of the bounds. No self-citation chains or ansatzes are invoked to force the central claims, so the derivation remains independent of the concrete model outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- temperature
axioms (2)
- domain assumption Bounded cross-token influence
- domain assumption Uniform local margin condition
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under bounded cross-token influence, we establish a high-temperature contraction result implying O(n log n) mixing time
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
uniform local margin condition... exponentially slow escape from semantic basins
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Struc- tured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems, volume 34, pages 17981–17993, 2021
work page 2021
-
[2]
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics, 48(1):207–219, 2022
work page 2022
-
[3]
Cross-lingual language model pretraining.Advances in neural information processing systems, 32, 2019
Alexis Conneau and Guillaume Lample. Cross-lingual language model pretraining.Advances in neural information processing systems, 32, 2019
work page 2019
-
[4]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4171–4186. Association for Computational Linguistics, 2019
work page 2019
-
[5]
Realtox- icityprompts: Evaluating neural toxic degeneration in language models
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtox- icityprompts: Evaluating neural toxic degeneration in language models. InFindings of the association for computational linguistics: EMNLP 2020, pages 3356–3369, 2020
work page 2020
-
[6]
Roy J. Glauber. Time-dependent statistics of the ising model.Journal of Mathematical Physics, 4(2):294–307, 1963
work page 1963
-
[7]
DiffuSeq: Sequence to Sequence Text Generation with Diffusion Models
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and LingPeng Kong. Diffuseq: Sequence to sequence text generation with diffusion models.arXiv preprint arXiv:2210.08933, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
Diffusionbert: Improving generative masked language models with diffusion models
Zhengfu He, Tianxiang Sun, Qiong Tang, Kuanning Wang, Xuan-Jing Huang, and Xipeng Qiu. Diffusionbert: Improving generative masked language models with diffusion models. In Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers), pages 4521–4534, 2023
work page 2023
-
[9]
Levin, Yuval Peres, and Elizabeth L
David A. Levin, Yuval Peres, and Elizabeth L. Wilmer.Markov Chains and Mixing Times. American Mathematical Society, 2nd edition, 2017
work page 2017
-
[10]
Visualizing and understanding neural models in nlp
Jiwei Li, Xinlei Chen, Eduard Hovy, and Dan Jurafsky. Visualizing and understanding neural models in nlp. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 681–691, 2016
work page 2016
-
[11]
Xiang Li, John Thickstun, Ishaan Gulrajani, Percy S Liang, and Tatsunori B Hashimoto. Diffusion-lm improves controllable text generation.Advances in neural information processing systems, 35:4328–4343, 2022
work page 2022
-
[12]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[13]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Stereoset: Measuring stereotypical bias in pretrained language models
Moin Nadeem, Anna Bethke, and Siva Reddy. Stereoset: Measuring stereotypical bias in pretrained language models. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 5356–5371, 2021
work page 2021
-
[15]
Crows-pairs: A challenge dataset for measuring social biases in masked language models
Nikita Nangia, Clara Vania, Rasika Bhalerao, and Samuel Bowman. Crows-pairs: A challenge dataset for measuring social biases in masked language models. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 1953–1967, 2020
work page 2020
-
[16]
Subham Sekhar Sahoo, Marianne Arriola, Aaron Gokaslan, Edgar Mariano Marroquin, Alexan- der M. Rush, Yair Schiff, Justin T. Chiu, and V olodymyr Kuleshov. Simple and effective masked diffusion language models. InAdvances in Neural Information Processing Systems, 2024. 11
work page 2024
-
[17]
Julian Salazar, Davis Liang, Toan Q Nguyen, and Katrin Kirchhoff. Masked language model scoring. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 2699–2712, 2020
work page 2020
-
[18]
The woman worked as a babysitter: On biases in language generation
Emily Sheng, Kai-Wei Chang, Premkumar Natarajan, and Nanyun Peng. The woman worked as a babysitter: On biases in language generation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, pages 3407–3412, 2019
work page 2019
-
[19]
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. How to fine-tune bert for text classifi- cation? InChina national conference on Chinese computational linguistics, pages 194–206. Springer, 2019
work page 2019
-
[20]
Ian Tenney, Patrick Xia, Berlin Chen, Alex Wang, Adam Poliak, R Thomas McCoy, Najoung Kim, Benjamin Van Durme, Samuel R Bowman, Dipanjan Das, et al. What do you learn from context? probing for sentence structure in contextualized word representations.arXiv preprint arXiv:1905.06316, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[21]
Bert has a mouth, and it must speak: Bert as a markov random field language model
Alex Wang and Kyunghyun Cho. Bert has a mouth, and it must speak: Bert as a markov random field language model. InProceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation, pages 30–36. Association for Computational Linguistics, 2019
work page 2019
-
[22]
Benjamin Warner, Antoine Chaffin, Benjamin Clavié, Orion Weller, Oskar Hallström, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, et al. Smarter, better, faster, longer: A modern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. InProceedings of the 63rd Annual Meeting of the Associati...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.