From AI-Generated Content to Agentic Action: Security and Safety Threats in Generative AI
Pith reviewed 2026-05-20 18:02 UTC · model grok-4.3
The pith
As generative AI shifts from content creation to executing actions, security threats expand faster than defenses can keep up.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
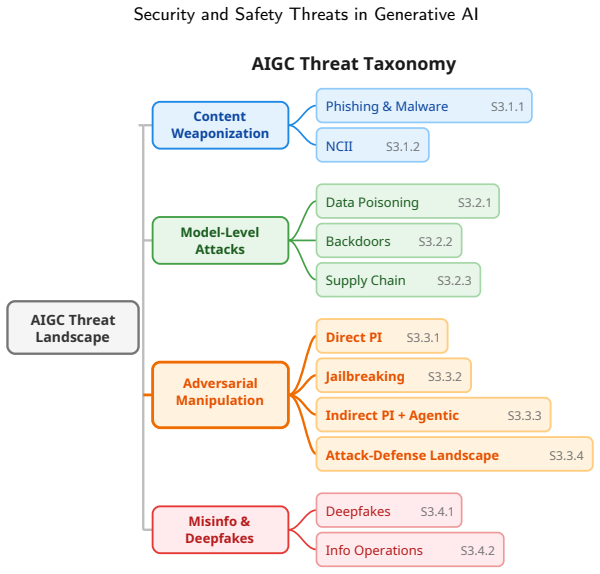
Generative AI systems are increasingly used not only to produce content but also to retrieve data, invoke tools, and execute actions. This work examines the security and safety implications of that shift across content-level, model-level, and agentic threats. It analyzes how attacker access requirements, system autonomy, and the scope of potential harm change as models move from generating artifacts to executing operations through tool chains and external APIs. It then assesses technical countermeasures including detection, watermarking, alignment, and emerging agentic safeguards, and shows that several depend on forms of institutional coordination that current governance arrangements do not
What carries the argument
Staged threat analysis progressing from content-level to model-level to agentic threats, which maps rising attacker requirements, autonomy, and harm scope while checking whether defenses advance at the same rate.
Load-bearing premise
The specific cases reviewed stand in for the general move toward agentic systems and the listed countermeasures cover the main technical options now available.
What would settle it
A report or study documenting large-scale agentic AI deployments where new safeguards have measurably reduced security incidents would test whether defenses are truly lagging.
Figures



read the original abstract
Generative AI systems are increasingly used not only to produce content but also to retrieve data, invoke tools, and execute actions. This work examines the security and safety implications of that shift across content-level, model-level, and agentic threats. We analyze how attacker access requirements, system autonomy, and the scope of potential harm change as models move from generating artifacts to executing operations through tool chains and external APIs. We then assess technical countermeasures including detection, watermarking, alignment, and emerging agentic safeguards, and show that several depend on forms of institutional coordination that current governance arrangements do not yet provide. Across the cases examined, capability deployment and attack-surface expansion repeatedly outpace defensive responses as systems move from generating content to executing real-world actions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript surveys the security and safety implications of generative AI shifting from content generation to agentic systems that retrieve data, invoke tools, and execute real-world actions via APIs. It categorizes threats at content, model, and agentic levels, analyzes changes in attacker access requirements, autonomy, and harm scope, evaluates countermeasures such as detection, watermarking, alignment, and agentic safeguards, and concludes that capability deployment and attack-surface expansion repeatedly outpace defensive responses across the examined cases, with many countermeasures depending on institutional coordination not yet provided by current governance.
Significance. If the observed patterns hold, the paper offers a timely synthesis of escalating risks in the move toward agentic AI, which could help frame future empirical work and policy discussions in AI security. Its structured progression from content-level to action-level threats provides a useful organizing framework. As a qualitative survey without new empirical data, derivations, or falsifiable predictions, its primary value is in highlighting gaps rather than resolving them; no machine-checked proofs or reproducible code are present.
major comments (2)
- [Abstract] Abstract: The load-bearing claim that 'capability deployment and attack-surface expansion repeatedly outpace defensive responses' across examined cases is presented as an observational conclusion but lacks documented case selection criteria, quantitative metrics (e.g., timelines or capability deltas), or explicit counter-examples considered and rejected. This directly affects the generalizability of the central thesis.
- [Countermeasures discussion] Countermeasures assessment: The statement that several defenses 'depend on forms of institutional coordination that current governance arrangements do not yet provide' is central to the safety implications but is not supported by concrete references to specific governance mechanisms, existing standards, or failed coordination attempts, leaving the practical barrier claim under-specified.
minor comments (2)
- [Introduction] The manuscript would benefit from an explicit early definition or taxonomy of 'agentic action' versus prior generative capabilities to improve accessibility for readers outside the immediate subfield.
- [References] Some citations on rapidly evolving topics (e.g., alignment techniques and agentic safeguards) appear to stop short of the most recent preprints; updating the reference list would strengthen the survey character.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's constructive report. We appreciate the feedback on strengthening the presentation of our qualitative survey and have addressed each major comment below with planned revisions to improve transparency and support for key claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The load-bearing claim that 'capability deployment and attack-surface expansion repeatedly outpace defensive responses' across examined cases is presented as an observational conclusion but lacks documented case selection criteria, quantitative metrics (e.g., timelines or capability deltas), or explicit counter-examples considered and rejected. This directly affects the generalizability of the central thesis.
Authors: We thank the referee for this observation. As a qualitative survey synthesizing existing literature rather than an empirical study, the manuscript does not introduce new quantitative metrics or a formal meta-analysis. To address the concern, we will revise the abstract and introduction to explicitly document case selection criteria, focusing on representative, high-profile examples from peer-reviewed works and public reports (2022-2024) that illustrate the shift to agentic systems. We will also add a brief discussion of considered counter-examples, such as partial successes in content detection that have not extended to tool-using agents, to clarify the observational scope and limits on generalizability. revision: yes
-
Referee: [Countermeasures discussion] Countermeasures assessment: The statement that several defenses 'depend on forms of institutional coordination that current governance arrangements do not yet provide' is central to the safety implications but is not supported by concrete references to specific governance mechanisms, existing standards, or failed coordination attempts, leaving the practical barrier claim under-specified.
Authors: We agree this claim requires more concrete grounding to support its policy relevance. In the revised manuscript, we will expand the countermeasures section with specific references, including the EU AI Act's systemic risk obligations for general-purpose models, the NIST AI Risk Management Framework's emphasis on multi-stakeholder coordination, and documented challenges in ISO/IEC standards development for AI watermarking. We will also cite examples of coordination shortfalls, such as inconsistent provider adoption of safety standards despite public commitments, to better substantiate the institutional barrier without overstating the claim. revision: yes
Circularity Check
No circularity: qualitative survey without derivations or fitted inputs
full rationale
The manuscript is a survey paper that reviews security and safety threats as generative AI shifts from content generation to agentic actions. It presents observational patterns across content-level, model-level, and agentic threats plus countermeasures, without any equations, parameter fitting, uniqueness theorems, or self-citation chains that reduce claims to prior results by construction. The central statement that capability deployment outpaces defenses is framed as a summary of examined cases rather than a derived prediction or self-defined quantity. No load-bearing step equates to its own inputs; the analysis remains self-contained as general trend observation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Across the cases examined, capability deployment and attack-surface expansion repeatedly outpace defensive responses as systems move from generating content to executing real-world actions.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We organize this analysis as a complexity progression defined by three escalation dimensions (Table 3)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Acosta-Bermejo, R., Terrazas-Chavez, J.A., Aguirre-Anaya, E., 2025. Automated malware source code generation via uncensored llms and adversarial evasion of censored model. Applied Sciences 15, 9252
work page 2025
-
[2]
Gptzero: Robust detection of llm-generated texts
Adam, G.A., Cui, A., Thomas, E., Napier, E., Shmatko, N., Schnell, J., Tian, J.J., Dronavalli, A., Tian, E., Lee, D., 2026. Gptzero: Robust detection of llm-generated texts. arXiv preprint arXiv:2602.13042
-
[3]
Anil, C., Durmus, E., Panickssery, N., Sharma, M., Benton, J., Kundu, S., Batson, J., Tong, M., Mu, J., Ford, D., et al., 2024. Many-shot jailbreaking. Advances in Neural Information Processing Systems 37, 129696–129742
work page 2024
-
[4]
Anthropic, 2024a. Introducing Computer Use, a New Claude 3.5 Sonnet, and Claude 3.5 Haiku.https://www.anthropic.com/news/ 3-5-models-and-computer-use. Accessed: 2026-03-29
work page 2026
-
[5]
Introducing the Model Context Protocol.https://www.anthropic.com/news/model-context-protocol
Anthropic, 2024b. Introducing the Model Context Protocol.https://www.anthropic.com/news/model-context-protocol. Accessed: 2026-03-29
work page 2026
-
[6]
Anthropic, 2025a. Anthropic Acquires Bun as Claude Code Reaches $1B Milestone.https://www.anthropic.com/news/ anthropic-acquires-bun-as-claude-code-reaches-usd1b-milestone. Claude Code GA May 2025; $1B run-rate revenue by November 2025. Accessed: 2026-03-29
work page 2025
-
[7]
Anthropic, 2025b. Disrupting the First Reported AI-Orchestrated Cyber Espionage Campaign.https://www.anthropic.com/news/ disrupting-AI-espionage. Accessed: 2026-03-29
work page 2026
-
[8]
Donating the Model Context Protocol and Establishing the Agentic AI Foundation.https://www.anthropic
Anthropic, 2025c. Donating the Model Context Protocol and Establishing the Agentic AI Foundation.https://www.anthropic. com/news/donating-the-model-context-protocol-and-establishing-of-the-agentic-ai-foundation. Accessed: 2026- 03-29
work page 2026
-
[9]
Anthropic, 2025d. Model Context Protocol Specification (v2025-11-25).https://modelcontextprotocol.io/specification/ 2025-11-25. Now maintained by the Agentic AI Foundation under the Linux Foundation. Accessed: 2026-03-29
work page 2025
-
[10]
Refusal in language models is mediated by a single direction
Arditi, A., Obeso, O., Syed, A., Paleka, D., Panickssery, N., Gurnee, W., Nanda, N., 2024. Refusal in language models is mediated by a single direction. Advances in Neural Information Processing Systems 37, 136037–136083
work page 2024
-
[11]
Constitutional AI: Harmlessness from AI Feedback
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., et al., 2022. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
International ai safety report 2026
Bengio, Y., Clare, S., Prunkl, C., Andriushchenko, M., Bucknall, B., Murray, M., Bommasani, R., Casper, S., Davidson, T., Douglas, R., et al., 2026. International ai safety report 2026. arXiv preprint arXiv:2602.21012
-
[13]
Bengio, Y., Mindermann, S., Privitera, D., Besiroglu, T., Bommasani, R., Casper, S., Choi, Y., Fox, P., Garfinkel, B., Goldfarb, D., et al.,
-
[14]
arXiv preprint arXiv:2501.17805
International ai safety report. arXiv preprint arXiv:2501.17805
-
[15]
Video generation models as world simulators
Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., Ng, C., Wang, R., Ramesh, A., 2024. Video generation models as world simulators. URL:https://openai.com/index/ video-generation-models-as-world-simulators/
work page 2024
-
[16]
Bullwinkel, B., Russinovich, M., Salem, A., Zanella-Beguelin, S., Jones, D., Severi, G., Kim, E., Hines, K., Minnich, A., Zunger, Y., et al.,
-
[17]
arXiv preprint arXiv:2507.02956
A representation engineering perspective on the effectiveness of multi-turn jailbreaks. arXiv preprint arXiv:2507.02956
-
[18]
Secure and robust watermarking for ai-generated images: A comprehensive survey
Cao, J., Li, Q., Zhang, Z., Ni, J., 2025. Secure and robust watermarking for ai-generated images: A comprehensive survey. arXiv preprint arXiv:2510.02384
-
[19]
Cao, J., Zhang, Z., Li, Q., Ni, J., 2026. Marksweep: A no-box removal attack on ai-generated image watermarking via noise intensification and frequency-aware denoising. arXiv preprint arXiv:2602.15364
-
[20]
Carlini, N., Jagielski, M., Choquette-Choo, C.A., Paleka, D., Pearce, W., Anderson, H., Terzis, A., Thomas, K., Tramèr, F., 2024. Poisoning web-scale training datasets is practical, in: 2024 IEEE Symposium on Security and Privacy (SP), IEEE. pp. 407–425
work page 2024
-
[21]
arXiv preprint arXiv:2503.02857
Chandra,N.A.,Murtfeldt,R.,Qiu,L.,Karmakar,A.,Lee,H.,Tanumihardja,E.,Farhat,K.,Caffee,B.,Paik,S.,Lee,C.,etal.,2025.Deepfake- eval-2024: A multi-modal in-the-wild benchmark of deepfakes circulated in 2024. arXiv preprint arXiv:2503.02857
-
[22]
Jailbreakbench: An open robustness benchmark for jailbreaking large language models
Chao, P., Debenedetti, E., Robey, A., Andriushchenko, M., Croce, F., Sehwag, V., Dobriban, E., Flammarion, N., Pappas, G.J., Tramer, F., et al., 2024. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. Advances in Neural Information Processing Systems 37, 55005–55029
work page 2024
-
[23]
Chao,P.,Robey,A.,Dobriban,E.,Hassani,H.,Pappas,G.J.,Wong,E.,2025. Jailbreakingblackboxlargelanguagemodelsintwentyqueries, in: 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), IEEE. pp. 23–42
work page 2025
-
[24]
Audiojailbreak: Jailbreak attacks against end-to-end large audio-language models
Chen, G., Song, F., Zhao, Z., Jia, X., Liu, Y., Qiao, Y., Zhang, W., Tu, W., Yang, Y., Du, B., 2026. Audiojailbreak: Jailbreak attacks against end-to-end large audio-language models. IEEE Transactions on Dependable and Secure Computing
work page 2026
-
[25]
Demamba: Ai-generated video detection on million-scale genvideo benchmark
Chen, H., Hong, Y., Huang, Z., Xu, Z., Gu, Z., Li, Y., Lan, J., Zhu, H., Zhang, J., Wang, W., et al., 2024. Demamba: Ai-generated video detection on million-scale genvideo benchmark. arXiv preprint arXiv:2405.19707
- [26]
-
[27]
Revealing weaknesses in text watermarking through self-information rewrite attacks
Cheng, Y., Guo, H., Li, Y., Sigal, L., 2025. Revealing weaknesses in text watermarking through self-information rewrite attacks. arXiv preprint arXiv:2505.05190
-
[28]
Deep fakes: A looming challenge for privacy, democracy, and national security
Chesney, B., Citron, D., 2019. Deep fakes: A looming challenge for privacy, democracy, and national security. Calif. L. Rev. 107, 1753
work page 2019
-
[29]
Chou, S.Y., Chen, P.Y., Ho, T.Y., 2023. How to backdoor diffusion models?, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4015–4024
work page 2023
-
[30]
Undetectablewatermarksforlanguagemodels,in:TheThirtySeventhAnnualConferenceonLearning Theory, PMLR
Christ,M.,Gunn,S.,Zamir,O.,2024. Undetectablewatermarksforlanguagemodels,in:TheThirtySeventhAnnualConferenceonLearning Theory, PMLR. pp. 1125–1139
work page 2024
-
[31]
EvaluatingsecurityriskinDeepSeekandotherfrontierreasoningmodels
CiscoRobustIntelligence,2025. EvaluatingsecurityriskinDeepSeekandotherfrontierreasoningmodels. CiscoSecurityBlog.https:// blogs.cisco.com/security/evaluating-security-risk-in-deepseek-and-other-frontier-reasoning-models. In col- laboration with the University of Pennsylvania. Accessed: 2026-03-29. First Author et al.:Preprint submitted to ElsevierPage 20 ...
work page 2025
-
[32]
Coalition for Content Provenance and Authenticity, 2025. C2PA Specification v2.2.https://c2pa.org/specifications/ specifications/2.2/specs/C2PA_Specification.html. Open standard for digital content provenance. Accessed: 2026-03-29
work page 2025
-
[33]
InterimMeasuresfortheManagementofGenerativeArtificialIntelligenceServices
CyberspaceAdministrationofChinaandothers,2023. InterimMeasuresfortheManagementofGenerativeArtificialIntelligenceServices. http://www.cac.gov.cn/. Effective August 15, 2023
work page 2023
-
[34]
Dathathri, S., See, A., Ghaisas, S., Huang, P.S., McAdam, R., Welbl, J., Bachani, V., Kaskasoli, A., Stanforth, R., Matejovicova, T., et al.,
-
[35]
Scalable watermarking for identifying large language model outputs. Nature 634, 818–823
-
[36]
Asvspoof2021:Automaticspeakerverificationspoofingandcountermeasureschallengeevaluationplan
Delgado, H., Evans, N., Kinnunen, T., Lee, K.A., Liu, X., Nautsch, A., Patino, J., Sahidullah, M., Todisco, M., Wang, X., et al., 2021. Asvspoof2021:Automaticspeakerverificationspoofingandcountermeasureschallengeevaluationplan. arXivpreprintarXiv:2109.00535
-
[37]
Multilingualjailbreakchallengesinlargelanguagemodels
Deng,Y.,Zhang,W.,Pan,S.J.,Bing,L.,2023. Multilingualjailbreakchallengesinlargelanguagemodels. arXivpreprintarXiv:2310.06474
-
[38]
Dugan,L.,Hwang,A.,Trhlík,F.,Zhu,A.,Ludan,J.M.,Xu,H.,Ippolito,D.,Callison-Burch,C.,2024. Raid:Asharedbenchmarkforrobust evaluationofmachine-generatedtextdetectors,in:Proceedingsofthe62ndAnnualMeetingoftheAssociationforComputationalLinguistics (Volume 1: Long Papers), pp. 12463–12492
work page 2024
-
[39]
KTO: Model Alignment as Prospect Theoretic Optimization
Ethayarajh, K., Xu, W., Muennighoff, N., Jurafsky, D., Kiela, D., 2024. Kto: Model alignment as prospect theoretic optimization. arXiv preprint arXiv:2402.01306
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Regulation(EU)2024/1689–TheAIAct.https://digital-strategy
EuropeanParliamentandCounciloftheEuropeanUnion,2024. Regulation(EU)2024/1689–TheAIAct.https://digital-strategy. ec.europa.eu/en/policies/regulatory-framework-ai. Entered into force August 1, 2024. Accessed: 2026-03-29
work page 2024
-
[41]
Fernandez,P.,Couairon,G.,Jégou,H.,Douze,M.,Furon,T.,2023. Thestablesignature:Rootingwatermarksinlatentdiffusionmodels,in: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 22466–22477
work page 2023
-
[42]
Video seal: Open and efficient video watermarking
Fernandez, P., Elsahar, H., Yalniz, I.Z., Mourachko, A., 2024. Video seal: Open and efficient video watermarking. arXiv preprint arXiv:2412.09492
-
[43]
Badllama: cheaply removing safety fine-tuning from llama 2-chat 13b
Gade, P., Lermen, S., Rogers-Smith, C., Ladish, J., 2023. Badllama: cheaply removing safety fine-tuning from llama 2-chat 13b. arXiv preprint arXiv:2311.00117
-
[44]
Gao, L., Schulman, J., Hilton, J., 2023. Scaling laws for reward model overoptimization, in: International Conference on Machine Learning, PMLR. pp. 10835–10866
work page 2023
-
[45]
Artificial intelligence - carrying us into the future
Ghosh, S., Frase, H., Williams, A., Luger, S., Röttger, P., Barez, F., McGregor, S., Fricklas, K., Kumar, M., Bollacker, K., et al., 2025. Ailuminate: Introducing v1. 0 of the ai risk and reliability benchmark from mlcommons. arXiv preprint arXiv:2503.05731
-
[46]
Gong, Y., Ran, D., Liu, J., Wang, C., Cong, T., Wang, A., Duan, S., Wang, X., 2025. Figstep: Jailbreaking large vision-language models via typographic visual prompts, in: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 23951–23959
work page 2025
-
[47]
Lessons from Defending Gemini Against Indirect Prompt Injections
Google DeepMind, 2025. Advancing Gemini’s Security Safeguards.https://deepmind.google/blog/ advancing-geminis-security-safeguards/. Accompanied by white paper “Lessons from Defending Gemini Against Indirect Prompt Injections”. Accessed: 2026-03-29
work page 2025
-
[48]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al., 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., Fritz, M., 2023. Not what you’ve signed up for: Compromising real-world llm-integratedapplicationswithindirectpromptinjection,in:Proceedingsofthe16thACMworkshoponartificialintelligenceandsecurity, pp. 79–90
work page 2023
-
[50]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo,D.,Yang,D.,Zhang,H.,Song,J.,Wang,P.,Zhu,Q.,Xu,R.,Zhang,R.,Ma,S.,Bi,X.,etal.,2025. Deepseek-r1:Incentivizingreasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
CursorVulnerability(CVE-2025-59944):HowaCase-SensitivityBugExposedtheRisksofAgenticDeveloperTools
Gustafson,B.,2025. CursorVulnerability(CVE-2025-59944):HowaCase-SensitivityBugExposedtheRisksofAgenticDeveloperTools. LakeraBlog.https://www.lakera.ai/blog/cursor-vulnerability-cve-2025-59944. CVE-2025-59944.Accessed:2026-03-29
work page 2025
-
[52]
Spotting llms with binoculars: Zero-shot detection of machine-generated text, 2024
Hans, A., Schwarzschild, A., Cherepanova, V., Kazemi, H., Saha, A., Goldblum, M., Geiping, J., Goldstein, T., 2024. Spotting llms with binoculars: Zero-shot detection of machine-generated text. arXiv preprint arXiv:2401.12070
-
[53]
Spear phishing with large language models,
Hazell, J., 2023. Spear phishing with large language models. arXiv preprint arXiv:2305.06972
-
[54]
Lora:Low-rankadaptationoflargelanguage models
Hu,E.J.,Shen,Y.,Wallis,P.,Allen-Zhu,Z.,Li,Y.,Wang,S.,Wang,L.,Chen,W.,etal.,2022. Lora:Low-rankadaptationoflargelanguage models. Iclr 1, 3
work page 2022
-
[55]
Videoshield: Regulating diffusion-based video generation models via watermarking
Hu, R., Zhang, J., Li, Y., Li, J., Guo, Q., Qiu, H., Zhang, T., 2025. Videoshield: Regulating diffusion-based video generation models via watermarking. arXiv preprint arXiv:2501.14195
-
[56]
Radar: Robust ai-text detection via adversarial learning
Hu, X., Chen, P.Y., Ho, T.Y., 2023. Radar: Robust ai-text detection via adversarial learning. Advances in neural information processing systems 36, 15077–15095
work page 2023
-
[57]
Safety tax: Safety alignment makes your large reasoning models less reasonable
Huang, T., Hu, S., Ilhan, F., Tekin, S.F., Yahn, Z., Xu, Y., Liu, L., 2025. Safety tax: Safety alignment makes your large reasoning models less reasonable. arXiv preprint arXiv:2503.00555
-
[58]
Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training
Hubinger,E.,Denison,C.,Mu,J.,Lambert,M.,Tong,M.,MacDiarmid,M.,Lanham,T.,Ziegler,D.M.,Maxwell,T.,Cheng,N.,etal.,2024. Sleeper agents: Training deceptive llms that persist through safety training. arXiv preprint arXiv:2401.05566
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Safetensors:ASimple,SafeWaytoStoreandDistributeTensors.https://huggingface.co/docs/safetensors
HuggingFace,2023. Safetensors:ASimple,SafeWaytoStoreandDistributeTensors.https://huggingface.co/docs/safetensors. Accessed: 2026-03-29
work page 2023
-
[60]
Security at Hugging Face.https://huggingface.co/docs/hub/security
Hugging Face, 2024. Security at Hugging Face.https://huggingface.co/docs/hub/security. Accessed: 2026-03-29
work page 2024
-
[61]
Qwen2.5-Coder Technical Report
Hui,B.,Yang,J.,Cui,Z.,Yang,J.,Liu,D.,Zhang,L.,Liu,T.,Zhang,J.,Yu,B.,Lu,K.,etal.,2024. Qwen2.5-codertechnicalreport. arXiv preprint arXiv:2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, H., Upasani, K., Chi, J., Rungta, R., Iyer, K., Mao, Y., Tontchev, M., Hu, Q., Fuller, B., Testuggine, D., et al., 2023. Llama guard: Llm-based input-output safeguard for human-ai conversations. arXiv preprint arXiv:2312.06674
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[63]
Model AI Governance Framework for Agentic AI
Infocomm Media Development Authority (IMDA), 2026. Model AI Governance Framework for Agentic AI. Technical Report. Government of Singapore. URL:https://www.imda.gov.sg/-/media/imda/files/about/emerging-tech-and-research/ First Author et al.:Preprint submitted to ElsevierPage 21 of 25 Security and Safety Threats in Generative AI artificial-intelligence/mgf...
work page 2026
-
[64]
Ai-generatedvideodetectionviaperceptualstraightening
Internò,C.,Geirhos,R.,Olhofer,M.,Liu,S.,Hammer,B.,Klindt,D.,2025. Ai-generatedvideodetectionviaperceptualstraightening. arXiv preprint arXiv:2507.00583
-
[65]
Invariant Labs, 2025a. MCP Security Notification: Tool Poisoning Attacks.https://invariantlabs.ai/blog/ mcp-security-notification-tool-poisoning-attacks. Accessed: 2026-03-29
work page 2026
-
[66]
Invariant Labs, 2025b. WhatsApp MCP Exploited: Exfiltrating Your Message History via MCP.https://invariantlabs.ai/blog/ whatsapp-mcp-exploited. Accessed: 2026-03-29
work page 2026
-
[67]
Critical mcp-remote RCE Vulnerability (CVE-2025-6514)
JFrog Security Research, 2025. Critical mcp-remote RCE Vulnerability (CVE-2025-6514). JFrog Blog.https://jfrog.com/blog/ 2025-6514-critical-mcp-remote-rce-vulnerability/. CVSS 9.6. Accessed: 2026-03-29
work page 2025
-
[68]
Jiang, F., Xu, Z., Niu, L., Xiang, Z., Ramasubramanian, B., Li, B., Poovendran, R., 2024. Artprompt: Ascii art-based jailbreak attacks against aligned llms, in: Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pp. 15157–15173
work page 2024
-
[69]
FoolingAIAgents:Web-BasedIndirectPromptInjectionObservedintheWild
Kaleli,B.,Farooqi,S.,Starov,O.,Mohamed,N.,2026. FoolingAIAgents:Web-BasedIndirectPromptInjectionObservedintheWild. Palo Alto Networks Unit 42.https://unit42.paloaltonetworks.com/ai-agent-prompt-injection/. Accessed: 2026-03-29
work page 2026
-
[70]
A watermark for large language models, in: International conference on machine learning, PMLR
Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., Goldstein, T., 2023. A watermark for large language models, in: International conference on machine learning, PMLR. pp. 17061–17084
work page 2023
-
[71]
Safellm:Unlearningharmfuloutputsfromlargelanguagemodelsagainstjailbreakattacks
Li,X.,Wu,X.,Li,Q.,Ni,J.,Lu,R.,2025. Safellm:Unlearningharmfuloutputsfromlargelanguagemodelsagainstjailbreakattacks. arXiv preprint arXiv:2508.15182
-
[72]
Li, Y., Guo, H., Zhou, K., Zhao, W.X., Wen, J.R., 2024a. Images are achilles’ heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models, in: European Conference on Computer Vision, Springer. pp. 174–189
-
[73]
arXiv preprint arXiv:2402.00798
Li,Z.,Hua,W.,Wang,H.,Zhu,H.,Zhang,Y.,2024b.Formal-llm:Integratingformallanguageandnaturallanguageforcontrollablellm-based agents. arXiv preprint arXiv:2402.00798
-
[74]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
Liu,X.,Xu,N.,Chen,M.,Xiao,C.,2023. Autodan:Generatingstealthyjailbreakpromptsonalignedlargelanguagemodels. arXivpreprint arXiv:2310.04451
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[75]
Lu, P., Li, Q., Zhu, H., Sovernigo, G., Lin, X., 2021. Voxstructor: Voice reconstruction from voiceprint, in: International Conference on Information Security, Springer. pp. 374–397
work page 2021
-
[76]
The Dark Side of LLMs: Agent-based Attack Vectors for System-level Compromise
Lupinacci, M., Pironti, F.A., Blefari, F., Romeo, F., Arena, L., Furfaro, A., 2025. The dark side of llms: Agent-based attacks for complete computer takeover. arXiv preprint arXiv:2507.06850
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Macko, D., Moro, R., Uchendu, A., Lucas, J., Yamashita, M., Pikuliak, M., Srba, I., Le, T., Lee, D., Simko, J., et al., 2023. Multitude: Large-scale multilingual machine-generated text detection benchmark, in: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 9960–9987
work page 2023
-
[78]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, M., Phan, L., Yin, X., Zou, A., Wang, Z., Mu, N., Sakhaee, E., Li, N., Basart, S., Li, B., et al., 2024. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Mei,K.,Zhu,X.,Xu,W.,Hua,W.,Jin,M.,Li,Z.,Xu,S.,Ye,R.,Ge,Y.,Zhang,Y.,2024. Aios:Llmagentoperatingsystem. arXivpreprint arXiv:2403.16971
-
[80]
Simpo: Simple preference optimization with a reference-free reward
Meng, Y., Xia, M., Chen, D., 2024. Simpo: Simple preference optimization with a reference-free reward. Advances in Neural Information Processing Systems 37, 124198–124235
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.