StAD: Stein Amortized Divergence for Fast Likelihoods with Diffusion and Flow
Pith reviewed 2026-05-19 21:29 UTC · model grok-4.3
pith:N5PXGTBX Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{N5PXGTBX}
Prints a linked pith:N5PXGTBX badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
StAD uses the Langevin-Stein operator to learn PF-ODE divergences without ever computing Jacobians.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StAD distills the divergence of the PF-ODE using the Langevin-Stein operator so that likelihoods can be obtained without computing the Jacobian of the learned vector field; the resulting amortized estimates are competitive with Hutchinson-style methods on image benchmarks and, when regularity conditions hold, produce vector fields that belong to the Stein class and therefore generalize to varied generative models.
What carries the argument
The Langevin-Stein operator applied as a distillation target to amortize and predict the divergence of the PF-ODE vector field.
If this is right
- Likelihood evaluation becomes faster and exhibits lower variance than the Hutchinson estimator on CIFAR-10 and ImageNet.
- The same learned divergence predictor applies across multiple diffusion and flow architectures without retraining the Jacobian estimator.
- Density estimation workflows that require repeated likelihood calls become more practical for Bayesian analysis.
- Under the stated regularity conditions the method extends to a broader class of generative models beyond the training distribution.
Where Pith is reading between the lines
- High-dimensional Bayesian workflows could evaluate model evidence at lower cost by swapping in the amortized divergence.
- The Stein-class property might allow the same distilled predictor to serve as a drop-in module for related ODE-based density estimators.
- Training the distillation network once could amortize divergence costs across many downstream sampling or inference runs.
Load-bearing premise
Regularity conditions exist that allow the learned vector fields to satisfy the Stein class and thereby generalize.
What would settle it
Exact likelihood values computed via the analytical Jacobian on a low-dimensional Gaussian model differ systematically from the StAD estimates by more than the reported variance reduction.
Figures



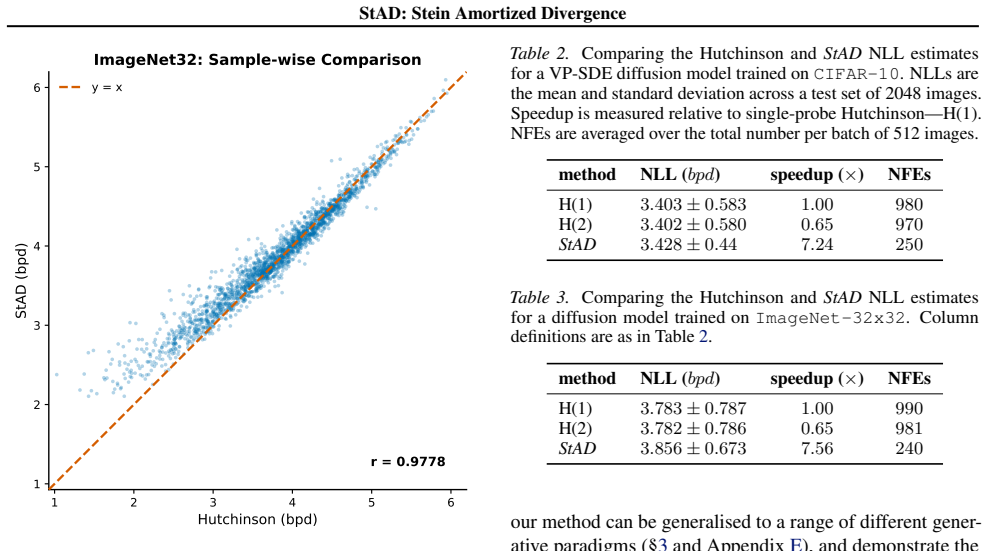

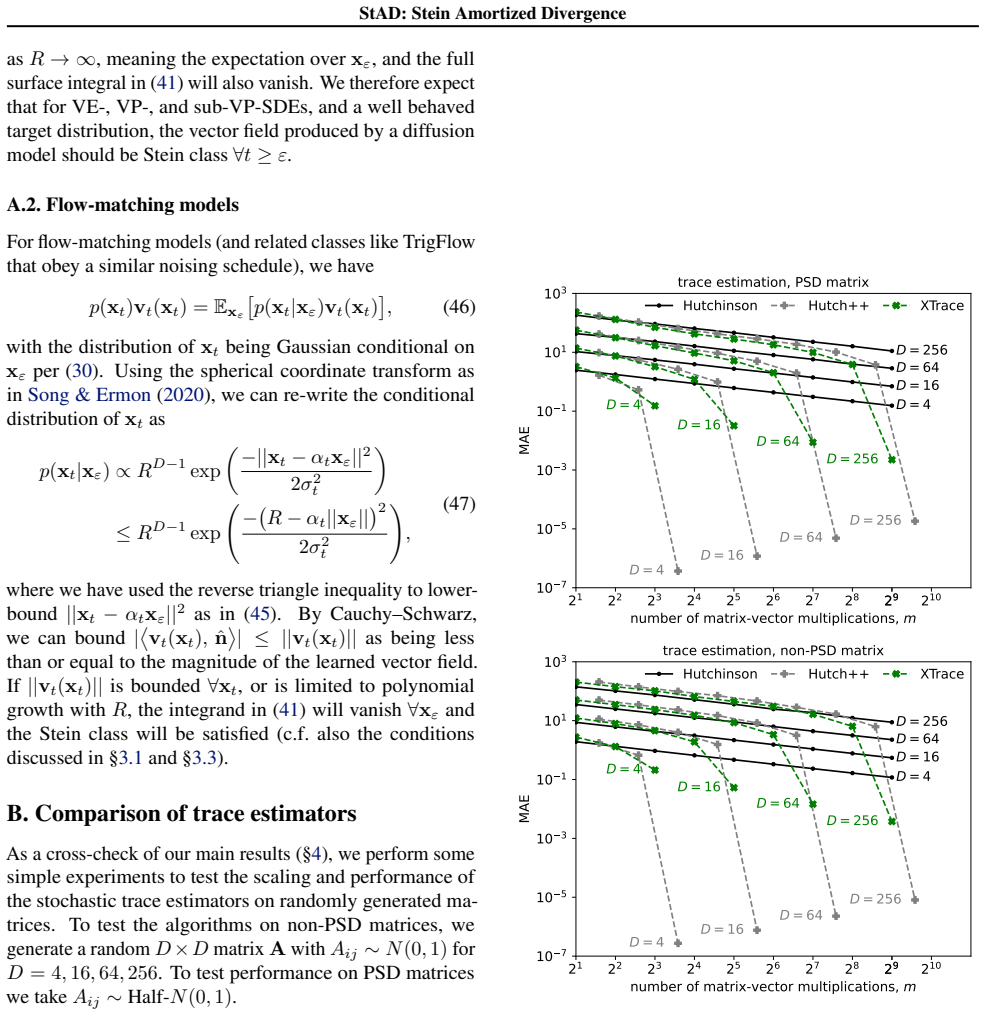




read the original abstract
Diffusion and flow-based models are ubiquitously used for generative modelling and density estimation. They admit a deterministic probability flow ordinary differential equation (PF-ODE), analogous to continuous normalizing flows (CNFs), which describes the transport of the probability mass. Obtaining the likelihood from these models is of interest to many workflows, especially Bayesian analysis, and requires solving the trace of the Jacobian to compute the divergence of the learned PF-ODE, which is either $\mathcal{O}(D^2)$ to compute exactly or $\mathcal{O}(D)$ with a noisy estimate. We introduce StAD, a new distillation method to predict and learn the divergence of the PF-ODE using the Langevin-Stein operator without ever computing the Jacobian. We show that our method is competitive with the Hutchinson and Hutch++ on CIFAR-10, ImageNet and other density estimation tasks, consistently improving the variance and speed of the likelihood predictions compared to the Hutchinson. We additionally show our method will generalize to a varied class of generative models, and show that under some regularity conditions these learned vector fields can be made to satisfy the Stein class.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StAD, a distillation method to approximate the divergence of the PF-ODE in diffusion and flow models via the Langevin-Stein operator, avoiding explicit Jacobian trace computation. It reports competitive likelihood estimation performance with reduced variance and improved speed relative to the Hutchinson estimator on CIFAR-10 and ImageNet, and asserts generalization across generative models provided the learned vector fields satisfy the Stein class under stated regularity conditions.
Significance. If the empirical speed/variance gains are reproducible with proper controls and the regularity conditions can be verified or bounded, the approach would offer a practical route to faster likelihoods in high-dimensional generative models without sacrificing the theoretical grounding of the Stein identity.
major comments (1)
- Abstract and generalization section: the claim that StAD generalizes to a varied class of generative models rests on the assertion that the distilled vector fields satisfy the Stein class under the invoked regularity conditions. The manuscript supplies neither empirical verification (e.g., Stein identity residuals on held-out models or datasets) nor bounds confirming that typical PF-ODE vector fields on CIFAR-10/ImageNet obey these conditions; this is load-bearing for the theoretical justification of the reported variance and speed advantages outside the distillation distribution.
minor comments (1)
- The abstract states competitive results on CIFAR-10 and ImageNet yet the manuscript should include explicit tables with error bars, run-time measurements, and ablation controls so that the variance and speed claims can be quantitatively assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concern regarding the generalization claim and the supporting evidence for the regularity conditions below, and will revise the paper to strengthen this aspect.
read point-by-point responses
-
Referee: Abstract and generalization section: the claim that StAD generalizes to a varied class of generative models rests on the assertion that the distilled vector fields satisfy the Stein class under the invoked regularity conditions. The manuscript supplies neither empirical verification (e.g., Stein identity residuals on held-out models or datasets) nor bounds confirming that typical PF-ODE vector fields on CIFAR-10/ImageNet obey these conditions; this is load-bearing for the theoretical justification of the reported variance and speed advantages outside the distillation distribution.
Authors: We agree that explicit empirical verification and bounds would strengthen the generalization claim. The current manuscript invokes standard regularity conditions (e.g., sufficient smoothness and decay at infinity for the vector field to belong to the Stein class) under which the identity holds, and demonstrates competitive performance on the evaluated models. In the revision we will add (i) empirical measurements of Stein identity residuals on held-out data and additional generative models, and (ii) a short discussion with references showing that the Lipschitz continuity and bounded-gradient properties typical of trained PF-ODE vector fields on CIFAR-10/ImageNet are sufficient to satisfy the invoked conditions. These additions will directly support the theoretical justification for variance and speed advantages beyond the distillation distribution. revision: yes
Circularity Check
No significant circularity; derivation relies on external Stein operator and empirical benchmarks
full rationale
The paper presents StAD as a distillation approach that replaces Jacobian trace computation with the Langevin-Stein operator for PF-ODE divergence. Competitiveness is demonstrated via direct empirical comparisons to Hutchinson and Hutch++ estimators on CIFAR-10, ImageNet, and other tasks, with reported improvements in variance and speed. Generalization to varied generative models is stated under explicit regularity conditions that enable Stein class membership; these conditions are invoked as assumptions rather than derived from the method itself. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or renamed input. The central claims remain independently verifiable against external benchmarks and the established Stein identity, satisfying the criteria for a self-contained derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Diffusion and flow-based models admit a deterministic probability flow ordinary differential equation (PF-ODE).
- ad hoc to paper Under some regularity conditions these learned vector fields can be made to satisfy the Stein class.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce StAD, a new distillation method to predict and learn the divergence of the PF-ODE using the Langevin-Stein operator without ever computing the Jacobian... under some regularity conditions these learned vector fields can be made to satisfy the Stein class.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
lim R→∞ ∮∂BR p(x)δ(x)v(x),n̂ dS = 0 ... We regularise δ such that this occurs by construction... κR ... cosine transition
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Alsing, J., Peiris, H., Mortlock, D., Leja, J., and Leistedt, B
URL https://doi.org/10.1093/mnras/ stz1960. Alsing, J., Peiris, H., Mortlock, D., Leja, J., and Leistedt, B. Forward modeling of galaxy populations for cosmo- logical redshift distribution inference.The Astrophysical Journal Supplement Series, 264(2):29, February 2023. URL https://doi.org/10.3847/1538-4365/ ac9583. Alsing, J., Thorp, S., Deger, S., Peiris...
-
[2]
cc/paper_files/paper/2019/file/ ba7609ee5789cc4dff171045a693a65f- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ ba7609ee5789cc4dff171045a693a65f- Paper.pdf. B´enard, C., Staber, B., and Da Veiga, S. Kernel Stein discrepancy thinning: a theoretical perspective of pathologies and a practical fix with regularization. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Adva...
work page 2019
-
[3]
cc/paper_files/paper/2023/file/ 9a8eb202c060b7d81f5889631cbcd47e- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ 9a8eb202c060b7d81f5889631cbcd47e- Paper-Conference.pdf. Biloˇs, M. and G¨unnemann, S. Scalable normalizing flows for permutation invariant densities. In Meila, M. and Zhang, T. (eds.),Proceedings of the 38th International Conference on Machine Learning, volume 139 ofPro- ceedings of Machine ...
work page 2023
-
[4]
A Downsampled Variant of ImageNet as an Alternative to the CIFAR datasets
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 770f8e448d07586afbf77bb59f698587- Paper.pdf. Chen, R. T. Q., Rubanova, Y ., Bettencourt, J., and Duvenaud, D. K. Neural ordinary differential equa- tions. In Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., and Garnett, R. (eds.), Advances in Neural Information Process...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
NICE: Non-linear Independent Components Estimation
URL https://doi.org/10.3847/1538- 3881/ad54bf. 10 StAD: Stein Amortized Divergence Dinh, L., Krueger, D., and Bengio, Y . NICE: non-linear independent components estimation. In Bengio, Y . and LeCun, Y . (eds.),3rd International Conference on Learn- ing Representations, May 2015. URL http://arxiv. org/abs/1410.8516. Dormand, J. and Prince, P. A family of ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3847/1538- 2015
-
[6]
cc/paper_files/paper/2025/file/ 6d13e085b79d454da5910e4ca82a3d9d- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2025/file/ 6d13e085b79d454da5910e4ca82a3d9d- Paper-Conference.pdf. Girard, D. A. A fast ‘Monte-Carlo cross-validation’ pro- cedure for large least squares problems with noisy data. Numerische Mathematik, 56:1–23, 1989. URL https: //doi.org/10.1007/BF01395775. Gittens, A. and Mahoney, M. Revisiting the ...
-
[7]
Ho, J., Jain, A., and Abbeel, P
URL https://proceedings.mlr.press/ v119/grathwohl20a.html. Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 6840–6851. Curran Associates, Inc.,
-
[8]
cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 4c5bcfec8584af0d967f1ab10179ca4b- Paper.pdf. Huang, Y ., Transue, T., Wang, S.-H., Feldman, W. M., Zhang, H., and Wang, B. Improving flow match- ing by aligning flow divergence. In Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Ma- haraj, T., Wagstaff, K., and Zhu, J. (ed...
work page 2020
-
[9]
11 StAD: Stein Amortized Divergence Hutchinson, M
URL https://proceedings.mlr.press/ v267/huang25ag.html. 11 StAD: Stein Amortized Divergence Hutchinson, M. F. A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines.Com- munications in Statistics – Simulation and Computation, 18(3):1059–1076, 1989. URL https://doi.org/ 10.1080/03610918908812806. Hyv¨arinen, A. Estimati...
-
[10]
cc/paper_files/paper/2022/file/ a98846e9d9cc01cfb87eb694d946ce6b- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ a98846e9d9cc01cfb87eb694d946ce6b- Paper-Conference.pdf. Karras, T., Aittala, M., Lehtinen, J., Hellsten, J., Aila, T., and Laine, S. Analyzing and improving the training dy- namics of diffusion models. In2024 IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pp. 24174–...
work page 2022
-
[11]
Shan Jia, Mingzhen Huang, Zhou Zhou, Yan Ju, Jialing Cai, and Siwei Lyu
IEEE Computer Society. URL https://doi. org/10.1109/CVPR52733.2024.02282. Kingma, D. and Gao, R. Understanding diffusion objectives as the ELBO with simple data augmen- tation. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.),Ad- vances in Neural Information Processing Systems, volume 36, pp. 65484–65516. Curran Associat...
-
[12]
cc/paper_files/paper/2023/file/ ce79fbf9baef726645bc2337abb0ade2- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ ce79fbf9baef726645bc2337abb0ade2- Paper-Conference.pdf. Kobyzev, I., Prince, S. J., and Brubaker, M. A. Normaliz- ing flows: An introduction and review of current meth- ods.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43(11):3964–3979, 2021. URL https: //doi.org/10.1109/TP...
-
[13]
cc/paper_files/paper/2016/file/ b3ba8f1bee1238a2f37603d90b58898d- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2016/file/ b3ba8f1bee1238a2f37603d90b58898d- Paper.pdf. Liu, Q., Lee, J., and Jordan, M. A kernelized Stein dis- crepancy for goodness-of-fit tests. In Balcan, M. F. and Weinberger, K. Q. (eds.),Proceedings of The 33rd Inter- national Conference on Machine Learning, volume 48 of Proceedings of Machine ...
work page 2016
-
[14]
Liu, X., Du, H., Deng, W., and Zhang, R
URL https://openreview.net/forum? id=1k4yZbbDqX. Liu, X., Du, H., Deng, W., and Zhang, R. Optimal stochas- tic trace estimation in generative modeling. In Li, Y ., Mandt, S., Agrawal, S., and Khan, E. (eds.),Proceedings of The 28th International Conference on Artificial Intelli- gence and Statistics, volume 258 ofProceedings of Ma- chine Learning Research...
-
[15]
URL https://proceedings.mlr.press/ v258/liu25k.html. Lu, C. and Song, Y . Simplifying, stabilizing and scaling continuous-time consistency models. In Yue, Y . (ed.), 13th International Conference on Learning Represen- tations, April 2025. URL https://openreview. net/forum?id=LyJi5ugyJx. Luhman, E. and Luhman, T. Knowledge distillation in iter- ative gener...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
cc/paper_files/paper/2023/file/ f115f619b62833aadc5acb058975b0e6- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ f115f619b62833aadc5acb058975b0e6- Paper-Conference.pdf. Maoutsa, D., Reich, S., and Opper, M. Interacting particle solutions of Fokker–Planck equations through gradient- log-density estimation.Entropy, 22(8):802, July 2020. URLhttps://doi.org/10.3390/e22080802. Meyer, R. A., Musco, C., Musco...
-
[17]
cc/paper_files/paper/2019/file/ bdbca288fee7f92f2bfa9f7012727740- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ bdbca288fee7f92f2bfa9f7012727740- Paper.pdf. Perez, E., Strub, F., de Vries, H., Dumoulin, V ., and Courville, A. FiLM: visual reasoning with a general conditioning layer. InProceedings of the Thirty-Second AAAI Conference on Artificial In- telligence, AAAI’18/IAAI’18/EAAI’18. AAAI Press,
work page 2019
-
[18]
URL https://doi.org/10.1609/aaai. v32i1.11671. 13 StAD: Stein Amortized Divergence Persson, D., Cortinovis, A., and Kressner, D. Improved variants of the Hutch++ algorithm for trace estimation. SIAM Journal on Matrix Analysis and Applications, 43 (3):1162–1185, 2022. URL https://doi.org/10. 1137/21M1447623. Ranganath, R., Tran, D., Altosaar, J., and Blei,...
-
[19]
cc/paper_files/paper/2016/file/ d947bf06a885db0d477d707121934ff8- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2016/file/ d947bf06a885db0d477d707121934ff8- Paper.pdf. Raonic, B., Mishra, S., and Lanthaler, S. Towards a cer- tificate of trust: Task-aware OOD detection for scientific AI. In V ondrick, C. (ed.),14th International Conference on Learning Representations, April 2026. URL https: //openreview.net/forum...
work page 2016
-
[20]
URL https://openreview.net/forum? id=FbssShlI4N. Riabiz, M., Chen, W. Y ., Cockayne, J., Swietach, P., Niederer, S. A., Mackey, L., and Oates, C. J. Optimal thinning of MCMC output.Journal of the Royal Sta- tistical Society Series B: Statistical Methodology, 84(4): 1059–1081, April 2022. URL https://doi.org/ 10.1111/rssb.12503. Robbins, H. E. An empirical...
-
[21]
Fundamentals of Enzyme Kinetics: Michaelis-Menten and Non-Michaelis- Type (Atypical) Enzyme Kinetics
URL https://doi.org/10.1007/978-1- 4612-0919-5_26. Ronneberger, O., Fischer, P., and Brox, T. U-Net: Convolu- tional networks for biomedical image segmentation. In Navab, N., Hornegger, J., Wells, W. M., and Frangi, A. F. (eds.),Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, volume 9351 ofLecture Notes in Computer Science, pp. 2...
-
[22]
cc/paper_files/paper/2025/file/ d79ac139911df25d27f14bbf008deaee- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2025/file/ d79ac139911df25d27f14bbf008deaee- Paper-Conference.pdf. Saibaba, A. K., Alexanderian, A., and Ipsen, I. C. Ran- domized matrix-free trace and log-determinant esti- mators.Numerische Mathematik, 137:353–395, Oc- tober 2017. URL https://doi.org/10.1007/ s00211-017-0880-z. Salimans, T. and Ho, ...
-
[23]
URL https://openreview.net/forum? id=WNzy9bRDvG. Song, Y . and Ermon, S. Generative modeling by estimating gradients of the data distribution. In Wallach, H. M., Larochelle, H., Beygelzimer, A., d’Alch´e-Buc, F., Fox, E. B., and Garnett, R. (eds.), Advances in Neural Information Processing Systems, volume 32, pp. 11895–11907. Curran Associates, Inc.,
-
[24]
cc/paper_files/paper/2019/file/ 3001ef257407d5a371a96dcd947c7d93- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 3001ef257407d5a371a96dcd947c7d93- Paper.pdf. Song, Y . and Ermon, S. Improved techniques for training score-based generative models. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in Neural Information Processing Systems, volume 33, pp. 12438–12448. Cur...
work page 2019
-
[25]
cc/paper_files/paper/2020/file/ 92c3b916311a5517d9290576e3ea37ad- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 92c3b916311a5517d9290576e3ea37ad- Paper.pdf. Song, Y ., Durkan, C., Murray, I., and Ermon, S. Max- imum likelihood training of score-based diffusion models. In Ranzato, M., Beygelzimer, A., Dauphin, Y ., Liang, P., and Vaughan, J. W. (eds.),Advances in Neural Information Processing Systems, ...
work page 2020
-
[26]
A note on the evaluation of generative models
URL https://proceedings.mlr.press/ v202/song23a.html. Stein, C. A bound for the error in the normal approxima- tion to the distribution of a sum of dependent random variables. In Le Cam, L. M., Neyman, J., and Scott, E. L. (eds.),Proceedings of the sixth Berkeley sympo- sium on mathematical statistics and probability, volume 2: Probability theory, volume ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3847/1538-4357/ae0936 1972
-
[27]
Zheng, Q., Le, M., Shaul, N., Lipman, Y ., Grover, A., and Chen, R
URL https://proceedings.mlr.press/ v267/yun25a.html. Zheng, Q., Le, M., Shaul, N., Lipman, Y ., Grover, A., and Chen, R. T. Q. Guided flows for generative modeling and decision making.preprint, November 2023. URL https://arxiv.org/abs/2311.13443. Zhou, M., Zheng, H., Wang, Z., Yin, M., and Huang, H. Score identity distillation: Exponentially fast distilla...
-
[28]
Zhou, M., Gu, Y ., Zheng, H., Song, L., He, G., Zhang, Y ., Hu, W., and Yang, Y
URL https://proceedings.mlr.press/ v235/zhou24x.html. Zhou, M., Gu, Y ., Zheng, H., Song, L., He, G., Zhang, Y ., Hu, W., and Yang, Y . Score distillation of flow matching models.preprint, September 2025. URL https:// arxiv.org/abs/2509.25127. A. Stein class conditions The boundary condition for the Stein class (Liu & Wang, 2016; Gorham & Mackey, 2017; Ba...
-
[29]
and mean flow (Geng et al., 2025), that were devel- oped for faster sampling under diffusion and flow-based models. Of these formulations, the TrigFlow continuous- time consistency model (Lu & Song, 2025) is a particularly natural fit forStAD. 18 StAD: Stein Amortized Divergence Lu & Song (2025) introduce TrigFlow, that optimises the objective L(θ) =E t E...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.