To MRL or not to MRL: Text Embeddings are Robust to Truncation Without Matryoshka Learning, Except In Heavy Truncation Scenarios
Pith reviewed 2026-05-20 20:12 UTC · model grok-4.3
The pith
Text embeddings from standard models stay competitive when truncated unless reduced by 80 percent or more, so MRL training is often unnecessary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
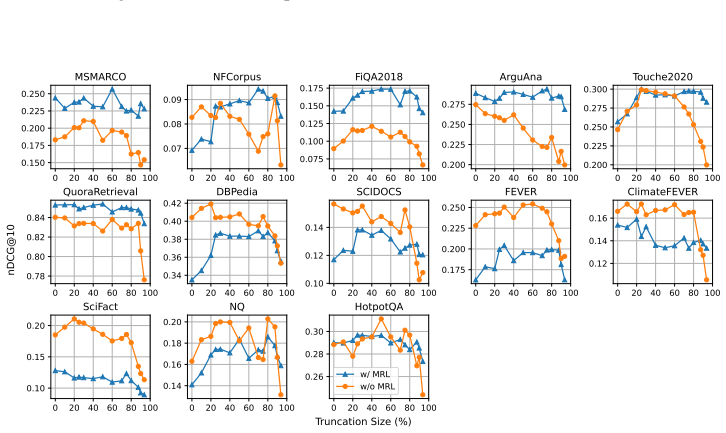
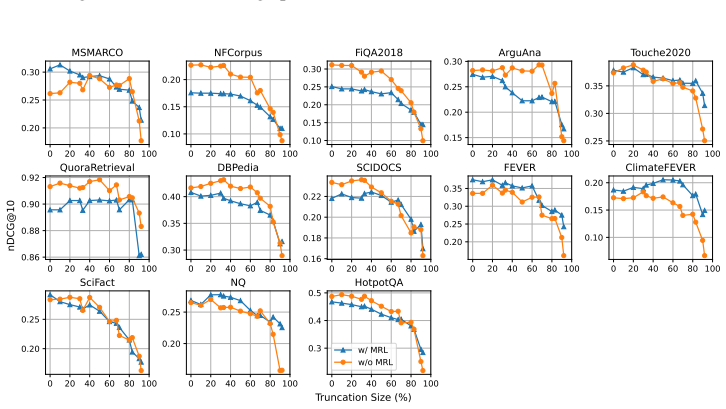
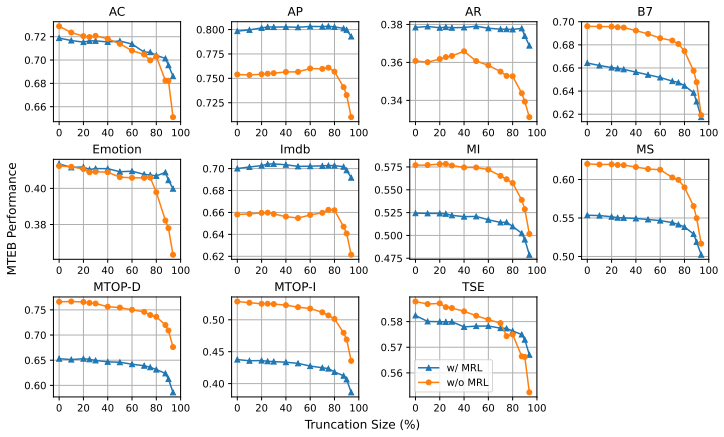
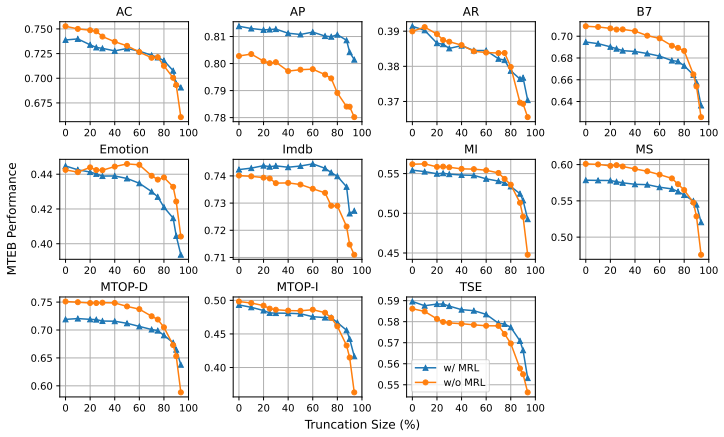
By applying identical truncation schedules from MRL training to models trained with and without MRL, the experiments demonstrate that non-MRL embeddings are competitive with and frequently outperform MRL embeddings on downstream tasks when size reduction stays below 80 percent, indicating that truncation robustness arises from standard embedding training rather than from the MRL procedure itself.
What carries the argument
Identical truncation schedule taken from MRL training and applied to both MRL and non-MRL text embedding vectors.
If this is right
- Standard embedding training suffices for most truncation levels without added MRL cost.
- MRL training becomes relevant only when applications demand very heavy truncation.
- Truncation robustness appears to be a general property of text embeddings rather than something MRL must instill.
- Model selection can prioritize standard objectives when moderate-sized vectors meet needs.
Where Pith is reading between the lines
- Deployers of embedding systems could save training compute by skipping MRL unless extreme size reduction is planned.
- The result invites similar tests on image or multimodal embeddings to check if robustness is modality-specific.
- Practitioners might experiment with even simpler truncation methods on existing models to confirm the pattern holds.
Load-bearing premise
That applying the truncation sizes and method chosen for MRL creates a fair test of whether MRL training itself is needed for robustness.
What would settle it
Finding that non-MRL models underperform MRL models by a large margin at truncation levels below 80 percent reduction on the same tasks would disprove the central result.
Figures



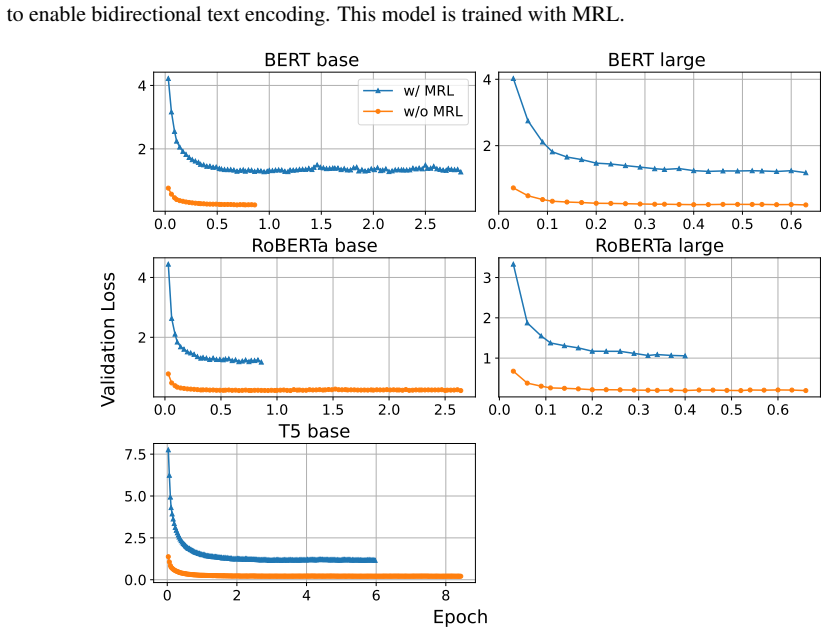
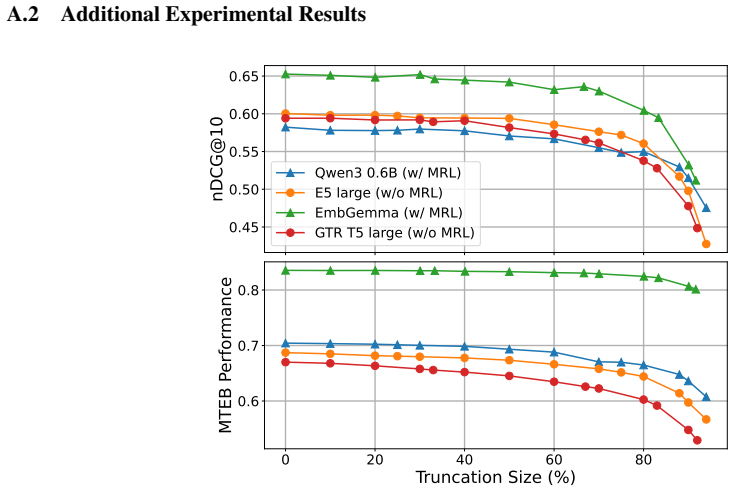
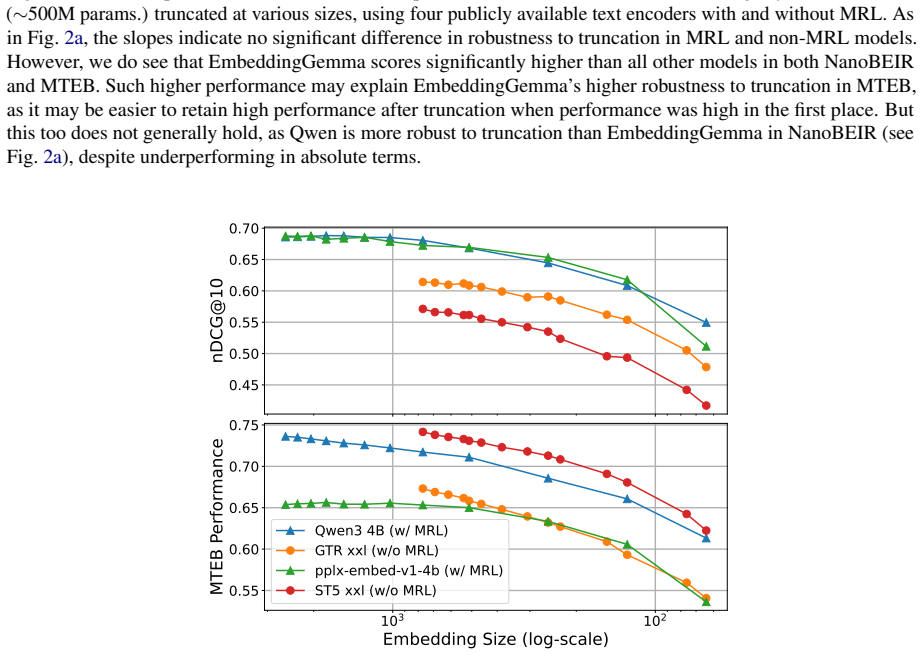






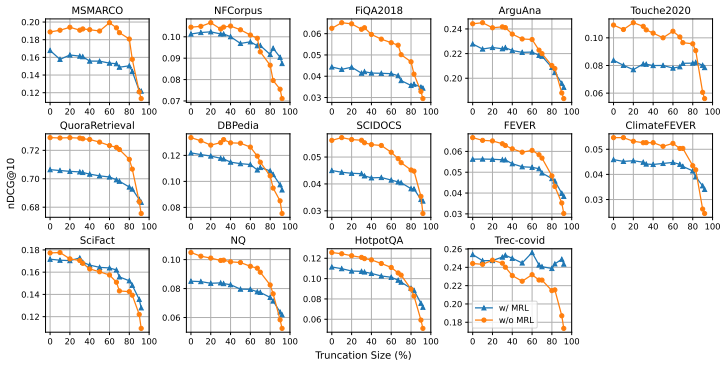





read the original abstract
Matryoshka Representation Learning (MRL) is a widely adopted approach for training text encoders so they provide useful text representations at various sizes, available by simply truncating the resulting vectors at sizes pre-determined at training time. Recent works have shown that randomly truncating text embeddings has minimal impact in downstream performance unless vectors are reduced in size by at least 70%, suggesting that embeddings are already robust to truncation without the use of MRL. However, no prior work has compared random truncation to MRL, so it is unclear how the two methods compare as effective embedding reduction methods. In this paper, we study this by applying the same truncation used by MRL to models trained with and without MRL. Our results across several models and downstream tasks show that, unless heavily truncating embeddings (i.e. reducing their size by at least 80%), truncated embeddings of non-MRL models are competitive with, and often outperform models trained with MRL. This suggests that truncation robustness may not necessarily come from MRL, and that the choice of spending the additional training cost of MRL depends on whether heavy truncation is desired. We make our code available for reproduction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines whether Matryoshka Representation Learning (MRL) is required to produce truncation-robust text embeddings. By applying the identical truncation schedule used during MRL training to both MRL-trained and standard (non-MRL) text encoders across multiple models and downstream tasks, the authors report that non-MRL embeddings remain competitive with—and frequently outperform—MRL embeddings unless the embedding dimension is reduced by at least 80%. The central conclusion is that the extra training cost of MRL is justified only in heavy-truncation regimes.
Significance. If the empirical comparison holds after addressing the noted experimental gaps, the result would have clear practical value for embedding-model training pipelines: it indicates that standard contrastive or masked-language-model training already yields sufficient robustness for moderate truncation, thereby questioning the routine adoption of MRL when only modest size reduction is needed. The work also supplies a useful baseline for future studies on embedding compression and dimensionality.
major comments (2)
- [Section 3 (Experimental Setup) and Section 4 (Results)] The experimental design applies the MRL-derived truncation points (prefix cuts at the sizes chosen during MRL training) directly to non-MRL embeddings without an ablation that tests alternative dimension-selection strategies (e.g., variance-ranked or random selection) at the same target sizes. Because MRL explicitly optimizes nested representations for precisely those cutoffs, the observed competitiveness of non-MRL models could be an artifact of the schedule rather than intrinsic robustness; this directly affects the claim that MRL training itself is not required.
- [Section 4 and associated tables/figures] The abstract and results sections state that non-MRL truncated embeddings “often outperform” MRL models, yet the manuscript provides neither error bars nor statistical significance tests for the pairwise comparisons. Without these, it is difficult to assess whether the reported outperformance is reliable or within the noise of the evaluation.
minor comments (2)
- [Section 3.2] The description of the exact truncation percentages and the corresponding absolute dimensions (e.g., 768 → 128) should be tabulated for each model so readers can reproduce the reduction ratios precisely.
- [Figures 2–4] Figure captions would benefit from explicitly labeling which curves correspond to MRL versus non-MRL models and whether the plotted points reflect mean performance across seeds.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our work. We address the major concerns point by point below and have made revisions to the manuscript to improve clarity and rigor where appropriate.
read point-by-point responses
-
Referee: [Section 3 (Experimental Setup) and Section 4 (Results)] The experimental design applies the MRL-derived truncation points (prefix cuts at the sizes chosen during MRL training) directly to non-MRL embeddings without an ablation that tests alternative dimension-selection strategies (e.g., variance-ranked or random selection) at the same target sizes. Because MRL explicitly optimizes nested representations for precisely those cutoffs, the observed competitiveness of non-MRL models could be an artifact of the schedule rather than intrinsic robustness; this directly affects the claim that MRL training itself is not required.
Authors: We chose to apply the MRL truncation schedule to non-MRL embeddings precisely to perform a controlled comparison at the dimensions for which MRL provides optimized representations. This setup directly tests whether the additional MRL training objective is necessary to achieve good performance at those specific sizes. If non-MRL embeddings perform competitively even when truncated at MRL's chosen cutoffs, it suggests that the robustness is largely intrinsic to standard training rather than dependent on MRL's nested optimization. Alternative selection strategies such as variance-based ranking would address a different question—namely, how to best truncate a fixed non-MRL embedding—rather than whether MRL training is required. We have added a clarifying paragraph in Section 3 of the revised manuscript to better articulate this experimental rationale and its relation to our central claim. revision: partial
-
Referee: [Section 4 and associated tables/figures] The abstract and results sections state that non-MRL truncated embeddings “often outperform” MRL models, yet the manuscript provides neither error bars nor statistical significance tests for the pairwise comparisons. Without these, it is difficult to assess whether the reported outperformance is reliable or within the noise of the evaluation.
Authors: We agree that the lack of error bars and statistical tests limits the strength of the outperformance claims. In the revised manuscript, we have added error bars representing standard deviation across multiple random seeds or evaluation runs to all relevant figures and tables. Additionally, we have included results of statistical significance tests (e.g., paired t-tests) for the key comparisons between MRL and non-MRL at each truncation level. These updates confirm that the reported advantages of non-MRL embeddings in moderate truncation regimes are statistically significant in the majority of cases. revision: yes
Circularity Check
No circularity: empirical comparison without derivation or self-referential structure
full rationale
The paper advances an empirical claim based on direct head-to-head experiments that apply the same truncation schedule to both MRL-trained and non-MRL models across multiple encoders and downstream tasks. No equations, fitted parameters renamed as predictions, or self-definitional steps appear in the abstract or described method. The central result—that non-MRL truncated embeddings remain competitive except under heavy (>80%) truncation—is presented as an observation from those comparisons rather than a quantity derived from prior outputs of the same model. Any self-citations to the original MRL work are external and non-load-bearing; the present study does not invoke uniqueness theorems or ansatzes from the authors' own prior publications to justify its conclusions. The argument is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in machine learning about fair model comparison and downstream task evaluation
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.