The Unlearnability Phenomenon in RLVR for Language Models
Pith reviewed 2026-05-19 21:34 UTC · model grok-4.3
The pith
A substantial subset of hard examples remains unlearnable in RLVR even when correct rollouts are available.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
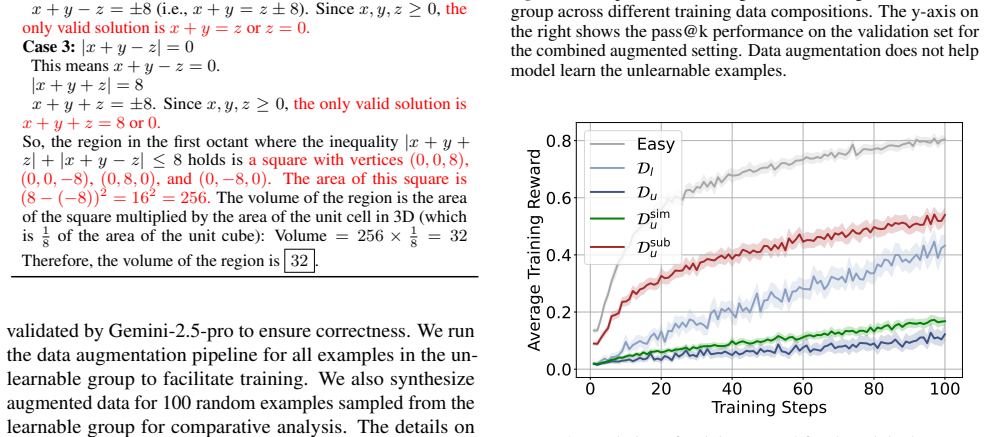
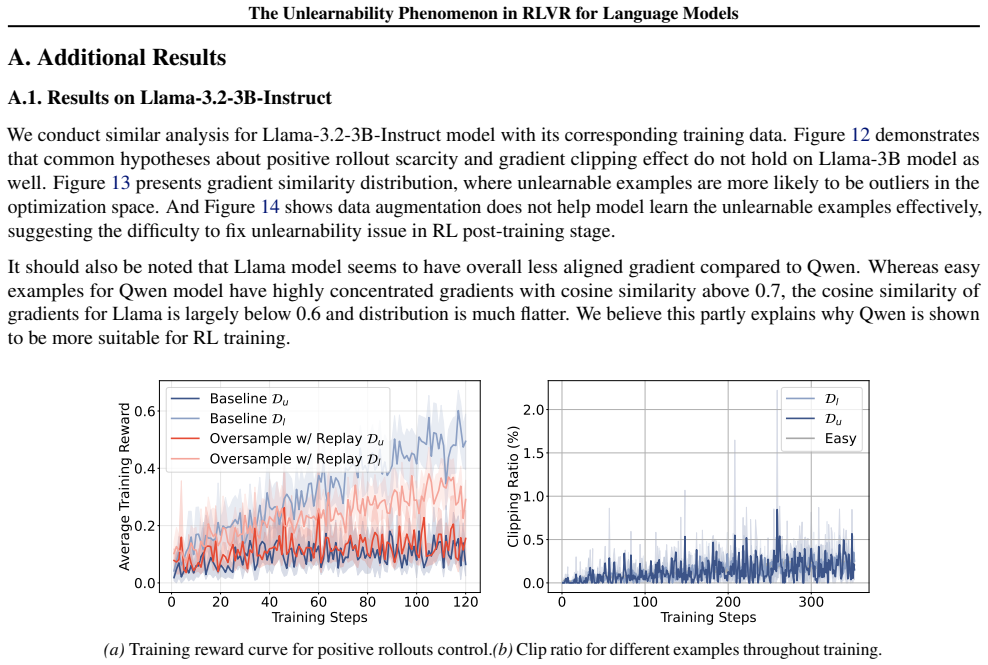
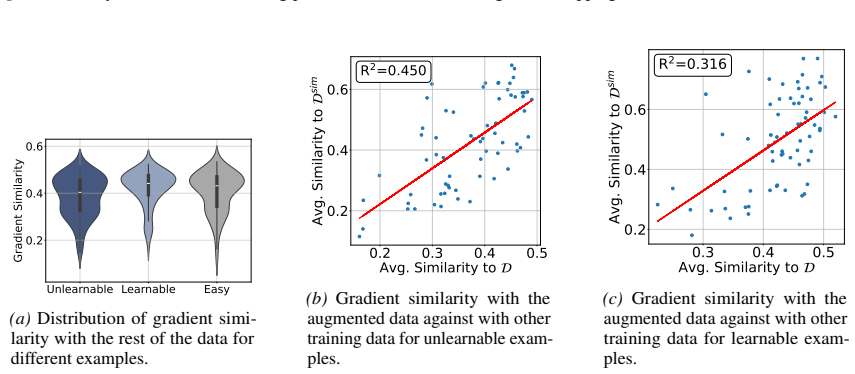
Among hard examples that the model initially struggles with, a substantial subset remains unlearnable even when correct rollouts are present. These unlearnable examples have fundamental representation issues, shown by low gradient similarity with the rest of the examples and ungeneralizable reasoning patterns. Existing optimization and sampling techniques fail to resolve unlearnability, and data augmentation does not improve gradient similarity, indicating inherent limitations of current RL approaches for reasoning tasks.
What carries the argument
Cross-example gradient analysis, which measures similarity between gradients of different training examples to detect representation issues in unlearnable cases.
If this is right
- Existing optimization and sampling techniques fail to make unlearnable examples learnable.
- Data augmentation leaves gradient similarity unchanged for unlearnable examples.
- Unlearnable examples are distinguished by ungeneralizable reasoning patterns.
- Current RL approaches have fundamental limitations when applied to reasoning in language models.
Where Pith is reading between the lines
- Training procedures could first identify examples with low gradient similarity and handle them separately or filter them out.
- Improving base model representations through pre-training might reduce the fraction of examples that later prove unlearnable under RL.
- Hybrid methods combining RL with targeted representation learning could address cases that pure RL leaves behind.
Load-bearing premise
That low gradient similarity reliably signals a fundamental representation problem that reinforcement learning cannot overcome.
What would settle it
A demonstration that additional pre-training or architectural changes raise gradient similarity for the previously unlearnable examples and allow them to become learnable under RLVR.
Figures







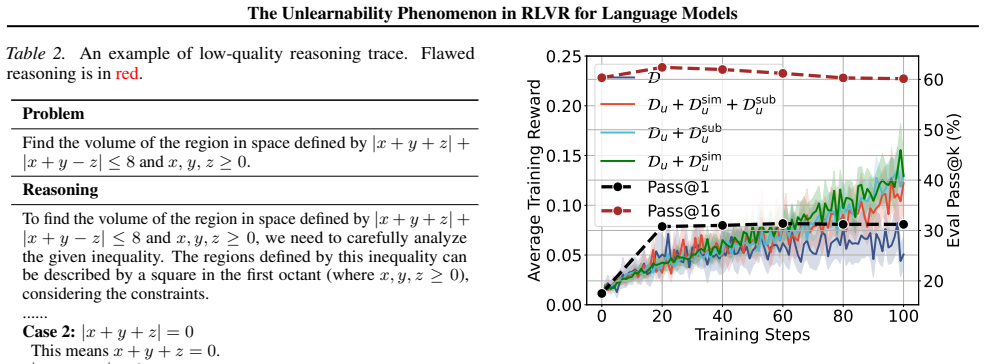







read the original abstract
Reinforcement Learning with Verifiable Reward (RLVR) has proven effective in improving Large Language Model's (LLM) reasoning ability. However, the learning dynamics of RLVR remain underexplored. In this paper, we reveal a counterintuitive phenomenon: among hard examples that the model initially struggles with, a substantial subset remains unlearnable even when correct rollouts are present. To understand the phenomenon, we first demonstrate that existing optimization and sampling techniques fail to resolve unlearnability. With cross-example gradient analysis, we show that unlearnable examples have fundamental representation issue, characterized by low gradient similarity with the rest of the examples and ungeneralizable reasoning patterns. We further show that representation flaws are difficult to mitigate in RL, as data augmentation does not improve gradient similarity. Our study provides the first systematic characterization of unlearnable data in RLVR training and reveals fundamental limitations in current RL approaches for reasoning tasks. Code and data are available at \url{https://github.com/yulinchen99/unlearnability-rlvr}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to identify an 'unlearnability phenomenon' in RLVR for LLMs: among hard examples the model initially struggles with, a substantial subset remains unlearnable even when correct rollouts are present. Existing optimization and sampling techniques are shown to fail. Cross-example gradient analysis attributes this to fundamental representation issues, characterized by low gradient similarity with other examples and ungeneralizable reasoning patterns. Data augmentation is reported not to improve gradient similarity, supporting the conclusion of inherent limitations in current RL approaches for reasoning. Code and data are released.
Significance. If the central claims are substantiated with tighter controls and alternative-objective tests, the work would be significant for providing the first systematic characterization of unlearnable examples in RLVR and for highlighting potential limits of policy-gradient methods on reasoning tasks. The open-sourcing of code supports reproducibility and follow-up experiments.
major comments (3)
- [§4] §4 (cross-example gradient analysis): the interpretation that low gradient similarity demonstrates a 'fundamental representation issue' is not secured by the reported evidence. Gradient similarity under policy gradients is sensitive to advantage estimation variance, entropy regularization, and the non-stationary loss landscape; the examples could lie in high-curvature regions of the current policy without implying that the base model lacks representational capacity.
- [§5] §5 (data augmentation results): showing that augmentation does not raise gradient similarity only rules out one class of fixes. The central claim requires testing whether the same examples become learnable under a different objective (e.g., SFT or auxiliary representation losses) or after continued pre-training; without such tests the conclusion that the limitation is inherent to RLVR remains under-supported.
- [Experimental methods] Experimental methods section: insufficient detail is provided on how 'hard examples' are selected, what constitutes a 'correct rollout', the precise definition of gradient similarity, and error bars or statistical controls for the gradient comparisons. These omissions make it difficult to evaluate whether the unlearnability claim is robust or sensitive to implementation choices.
minor comments (2)
- [Abstract] Abstract: the term 'unlearnable' and the precise criterion for 'correct rollouts' should be defined more explicitly to avoid ambiguity for readers unfamiliar with the experimental protocol.
- [§4] Notation: the gradient similarity metric would benefit from an explicit equation (e.g., cosine similarity of per-example gradients) rather than a purely verbal description.
Simulated Author's Rebuttal
We thank the referee for their thorough review and positive assessment of the significance of our work. We address each of the major comments in detail below and have made revisions to the manuscript to improve clarity and robustness.
read point-by-point responses
-
Referee: [§4] §4 (cross-example gradient analysis): the interpretation that low gradient similarity demonstrates a 'fundamental representation issue' is not secured by the reported evidence. Gradient similarity under policy gradients is sensitive to advantage estimation variance, entropy regularization, and the non-stationary loss landscape; the examples could lie in high-curvature regions of the current policy without implying that the base model lacks representational capacity.
Authors: We appreciate the referee's caution regarding the interpretation of gradient similarity. We agree that policy gradient estimates can be noisy due to variance in advantage estimation and the non-stationary nature of the optimization. In our original analysis, we mitigated some of this by averaging over multiple rollouts and using a baseline. In the revised version, we have included additional experiments using variance-reduced gradient estimates and different entropy coefficients to demonstrate that the low similarity persists. We have revised the text in §4 to state that the low gradient similarity 'indicates potential representation issues within the RLVR framework' rather than claiming a 'fundamental representation issue' in the base model. This addresses the possibility of high-curvature regions specific to the current policy. revision: yes
-
Referee: [§5] §5 (data augmentation results): showing that augmentation does not raise gradient similarity only rules out one class of fixes. The central claim requires testing whether the same examples become learnable under a different objective (e.g., SFT or auxiliary representation losses) or after continued pre-training; without such tests the conclusion that the limitation is inherent to RLVR remains under-supported.
Authors: We concur that ruling out data augmentation alone does not fully establish the inherent nature of the limitation. Our experiments show that even with augmented data, the gradient similarity remains low, and unlearnable examples exhibit ungeneralizable patterns. To further support our claims, we have added a new subsection discussing why alternative objectives like SFT may not easily resolve this, citing the lack of generalization in reasoning patterns. We have also included preliminary results on an auxiliary representation loss that slightly improves similarity but does not fully resolve unlearnability. However, comprehensive experiments with continued pre-training are beyond the scope of this work due to resource limitations; we have noted this as a direction for future research in the revised discussion. revision: partial
-
Referee: [Experimental methods] Experimental methods section: insufficient detail is provided on how 'hard examples' are selected, what constitutes a 'correct rollout', the precise definition of gradient similarity, and error bars or statistical controls for the gradient comparisons. These omissions make it difficult to evaluate whether the unlearnability claim is robust or sensitive to implementation choices.
Authors: We thank the referee for highlighting these omissions, which we agree make reproducibility challenging. In the revised manuscript, we have expanded the Experimental Methods section significantly. We now provide: detailed criteria for identifying hard examples (initial model accuracy below 20% on the task), the definition of a correct rollout (one that receives the full verifiable reward), the exact formula for gradient similarity (cosine similarity between averaged policy gradient vectors from correct rollouts), and error bars representing standard deviation over 5 random seeds with p-values for comparisons. These changes should allow readers to better assess the robustness of our findings. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents an empirical characterization of unlearnable examples in RLVR via cross-example gradient similarity measurements and data augmentation experiments. These are observational diagnostics drawn from standard policy gradient analysis rather than any self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations that reduce the central claim to its own inputs by construction. The reported findings rest on direct computation of gradients and rollout outcomes, which are independently verifiable against the training dynamics and do not collapse into tautological equivalence with the inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing optimization and sampling techniques are representative of standard RLVR practice.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unlearnable examples have fundamental representation issue, characterized by low gradient similarity with the rest of the examples and ungeneralizable reasoning patterns
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
data augmentation does not improve gradient similarity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Park, S., Kaur, S., and Arora, S
URL https://openreview.net/forum? id=O9YTt26r2P. Park, S., Kaur, S., and Arora, S. How does rl post-training in- duce skill composition? a case study on countdown, 2025. URLhttps://arxiv.org/abs/2512.01775. Qian, C., Acikgoz, E. C., He, Q., Wang, H., Chen, X., Hakkani-T¨ur, D., Tur, G., and Ji, H. Toolrl: Reward is all tool learning needs, 2025. URL https...
-
[2]
CMU MLD Blog. Qwen, :, Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., Lin, H., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Lin, J., Dang, K., Lu, K., Bao, K., Yang, K., Yu, L., Li, M., Xue, M., Zhang, P., Zhu, Q., Men, R., Lin, R., Li, T., Tang, T., Xia, T., Ren, X., Ren, X., Fan, Y ., Su, Y ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
We use learning rate 5e-7 for Qwen2.5-0.5B and LLama-3.2-3B-Instruct, and learning rate 1e-6 for Qwen2.5-3B. We have also tried different sampling batch size and gradient update batch size to vary the maximum number of off-policy update. The results show no significant difference in unlearnable subset of examples. For inference and sampling, we use temper...
-
[4]
A reader should be able to solve any single subproblem without seeing the others
Independence: Each subproblem must be fully self-contained, including all necessary context and definitions. A reader should be able to solve any single subproblem without seeing the others
-
[5]
Clarity: Each subproblem must be unambiguous and have a unique, well-defined answer
-
[6]
Requirements for solutions and answers:
Progression: Subproblems should follow a logical order, building toward the final solution. Requirements for solutions and answers:
-
[7]
Show complete step-by-step reasoning
-
[8]
Use LaTeX formatting for all mathematical expressions
-
[9]
Ensure calculations are correct and verifiable
-
[10]
The answer should be a numerical value or a single mathematical expression. Output format: Return ONLY a valid JSON array with no additional text, markdown code fences, or explanations before or after. Structure: { ”subproblem”: ”Clear, self-contained problem statement”, ”solution”: ”Step-by-step working with LaTeX formatting”, ”answer”: ”Final numerical ...
work page 2015
-
[11]
Determine the money earned per hour: • First hour: $1 • Second hour: $2 • Third hour: $3 • Fourth hour: $4 • Fifth hour: $5 • Sixth hour: $6 • Seventh hour: $1 • Eighth hour: $2
-
[12]
Calculate the total earnings for the first eight hours: 1 + 2 + 3 + 4 + 5 + 6 + 1 + 2 = 22
-
[13]
Determine the money earned for the next two hours (tenth hour and eleventh hour): • Tenth hour: $11 (1 + 2 = 3) • Eleventh hour: $11 (3 + 4 = 7)
-
[14]
Calculate the total money earned from babysitting: 22 + 11 + 11 = 44
-
[15]
Jason repays the debt by babysitting for 39 hours: 44×3 = 132 Therefore, Jason borrowed132 dollars. 23 The Unlearnability Phenomenon in RLVR for Language Models Table 6.An example reasoning trace with quality score 3. Problem Reasoning While walking by a classroom, Linda sees two perfect squares writ- ten on a blackboard. She notices that their differ- en...
-
[16]
Let’s call these squares a2 andb 2, whereaandbare natural numbers anda > b
First, identify the two perfect squares on the blackboard. Let’s call these squares a2 andb 2, whereaandbare natural numbers anda > b
-
[17]
We know that their difference is 99, so we can write:a 2 −b 2 = 99
-
[18]
We can factorize using the difference of squares formula:a2 −b 2 = (a+b)(a−b) = 99
-
[19]
The factor pairs of 99 are (1,99) , (3,33) , (9,11) , (−1,−99) , (−3,−33) , and (−9,−11)
-
[20]
Consider the pair (−3,−33) : a+b=−33 and a−b= 3 . Adding: 2a=−30 =⇒ a=−15 . Subtracting: 2b=−36 =⇒b=−18 . Since b must be natural, this pair is not valid
-
[21]
Consider the pair (3,−33) : a+b= 3 and a−b=−33 . Adding: 2a=−30 =⇒ a=−15 . Subtracting: 2b= 36 =⇒b= 18 . Since a > b , this pair is valid. The perfect squares are15 2 = 225and18 2 = 324. Their sum is225 + 324 = 549
-
[22]
Consider the pair (−9,−11) : a+b=−11 and a−b=−9 . Adding: 2a= −20 =⇒a=−10 . Subtracting: 2b=−2 =⇒b=−1 . Since b must be natural, this pair is not valid. The correct perfect squares on the blackboard are 225 and 324. Therefore, the sum is 549 . Table 7.An example reasoning trace with quality score 2. Problem Reasoning An isosceles trapezoid has sides of le...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.