Speaker-Disentangled Remote Speech Detection of Asthma and COPD Exacerbations
Pith reviewed 2026-05-19 19:12 UTC · model grok-4.3
pith:665UGLL6 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{665UGLL6}
Prints a linked pith:665UGLL6 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Adversarial training separates speaker identity from disease signals in speech to improve detection of asthma and COPD exacerbations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
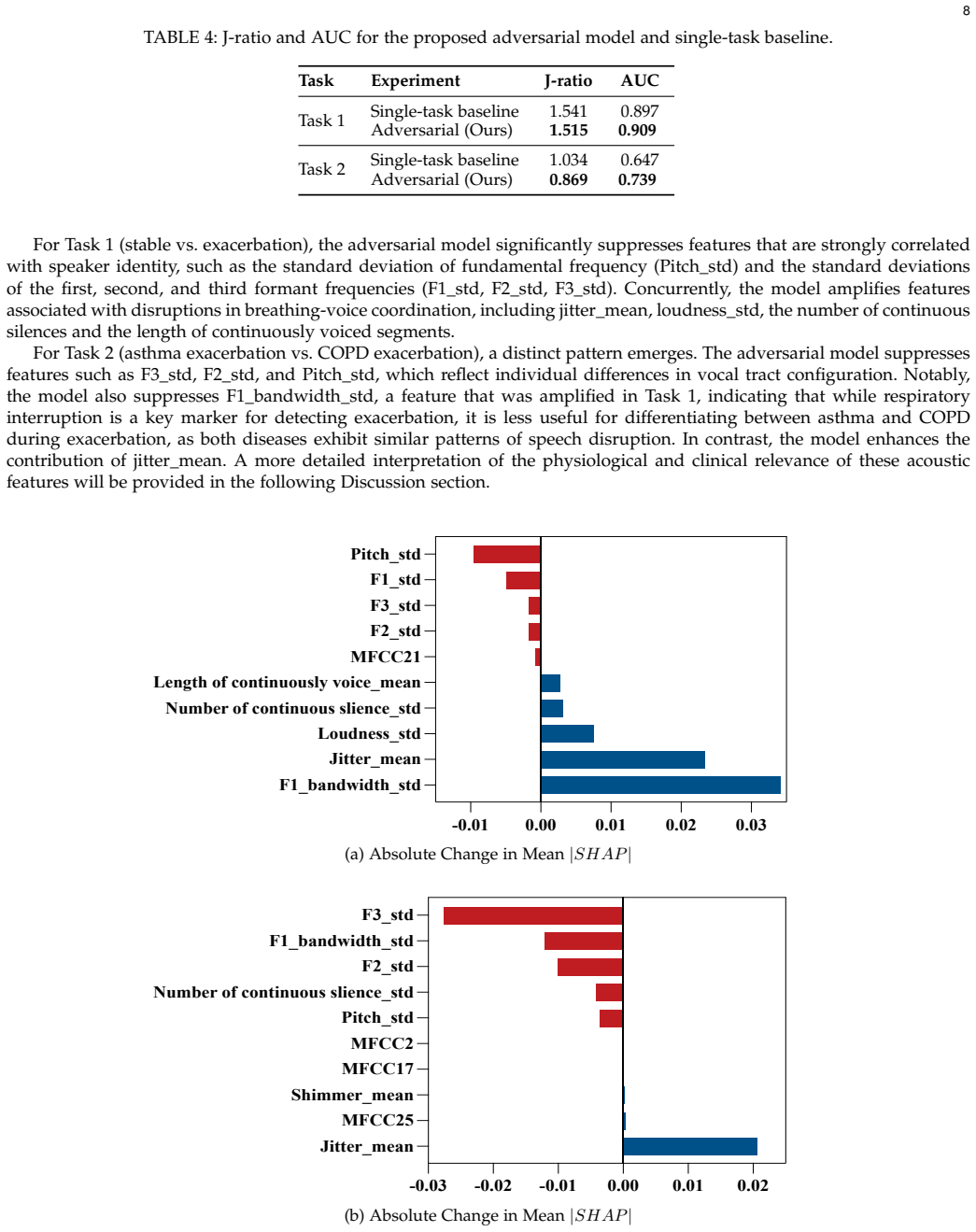
The paper claims that an adversarial learning architecture disentangles pathology-related acoustic patterns from speaker-identifiable attributes. The framework optimizes two clinically hierarchical tasks of respiratory status classification (stable versus exacerbated) and exacerbation type classification (asthma versus COPD) while speaker identity is suppressed through gradient reversal-based adversarial training. On the TACTICAS dataset the method raises AUC from 0.897 to 0.910 on the first task and from 0.674 to 0.793 on the second task, the J-ratio falls, and SHAP analysis shows feature contributions to each task. External validation on the Bridge2AI-Voice dataset confirms consistent gain
What carries the argument
Gradient reversal-based adversarial training applied to a speaker-identification branch that forces the shared acoustic feature extractor to discard speaker cues while retaining pathology cues for the two classification heads.
Load-bearing premise
Gradient reversal successfully removes speaker-identifiable information from the features without lowering accuracy on the disease classification tasks.
What would settle it
If an ablation that removes the gradient reversal layer still produces the reported AUC gains and J-ratio drop, the claim that disentanglement drives the improvement would be falsified.
Figures

read the original abstract
Early detection of exacerbations in asthma and chronic obstructive pulmonary disease (COPD) is important for timely intervention. Speech has emerged as a promising tool for continuous, non-invasive respiratory disease monitoring. However, speech signals inherently carry speaker-identifiable attributes that may dominate model predictions, which may compromise both diagnosis performance and patient privacy. Furthermore, the acoustic features associated with respiratory disease and speaker identity remain unclear in respiratory disease monitoring. We propose an adversarial learning architecture that disentangles pathology-related acoustic patterns from speaker-identifiable attributes. The framework optimizes two clinically hierarchical tasks: (i) respiratory status classification (stable vs. exacerbated) and (ii) exacerbation type classification (asthma exacerbation vs. COPD exacerbation). Speaker identity is suppressed through gradient reversal-based adversarial training. To enhance clinical interpretability, we employ SHapley Additive exPlanations (SHAP) to quantify the contributions of acoustic features to pathology-related predictions versus speaker identity. On the TACTICAS dataset, our method outperforms the single-task baseline across both tasks. For the respiratory status task (stable vs. exacerbated), the AUC improves from 0.897 to 0.910. For the exacerbation type task (asthma exacerbation vs. COPD exacerbation), the AUC increases from 0.674 to 0.793. Concurrently, the J-ratio decreases, confirming effective suppression of speaker information. SHAP analysis reveals the contributions of the acoustic features to both tasks. External validation on the Bridge2AI-Voice dataset further demonstrates consistent performance improvement and reduced speaker dependency, confirming cross-dataset generalizability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adversarial learning architecture to disentangle speaker-identifiable attributes from pathology-related acoustic patterns in speech signals for remote detection of asthma and COPD exacerbations. It optimizes two hierarchical clinical tasks—respiratory status classification (stable vs. exacerbated) and exacerbation type classification (asthma vs. COPD)—using gradient reversal for speaker suppression, employs SHAP for feature contribution analysis, and reports AUC gains plus J-ratio reduction on the TACTICAS dataset with external validation on Bridge2AI-Voice.
Significance. If the disentanglement mechanism holds, the work could meaningfully advance privacy-aware, non-invasive speech-based monitoring of respiratory diseases by reducing speaker bias while improving diagnostic AUC. The hierarchical task design and SHAP interpretability are constructive for clinical translation, and the external validation supports generalizability claims. These elements would strengthen the paper's contribution to biomedical signal processing if supported by rigorous verification.
major comments (2)
- [Abstract / Results] Abstract / Results: The central claim that gradient reversal isolates pathology acoustics from speaker attributes (evidenced by AUC gains of 0.897→0.910 and 0.674→0.793 plus J-ratio decrease) lacks load-bearing support. No ablation compares the full adversarial model against an identical multi-task network without the reversal loss, and no direct test (e.g., speaker classification accuracy on frozen pathology encoder outputs or mutual-information metrics) verifies feature separation quality.
- [Results] Results: The reported performance improvements are presented without statistical significance tests, confidence intervals, or p-values. This undermines the claim of consistent outperformance over the single-task baseline and the assertion of reduced speaker dependency.
minor comments (3)
- [Abstract] Abstract: The J-ratio metric used to confirm speaker suppression is referenced but not defined or derived; include its exact formulation and computation in the methods or results.
- [Methods] Methods: Dataset characteristics (speaker counts, recording durations, demographics, and class balances) for both TACTICAS and Bridge2AI-Voice should be explicitly reported to allow assessment of the external validation and generalizability.
- [Methods] Methods: Full model architecture details, loss weighting, training hyperparameters, and optimization procedure are absent; these are required for reproducibility of the adversarial training setup.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas for improvement in our manuscript. Below, we provide a point-by-point response to the major comments.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract / Results: The central claim that gradient reversal isolates pathology acoustics from speaker attributes (evidenced by AUC gains of 0.897→0.910 and 0.674→0.793 plus J-ratio decrease) lacks load-bearing support. No ablation compares the full adversarial model against an identical multi-task network without the reversal loss, and no direct test (e.g., speaker classification accuracy on frozen pathology encoder outputs or mutual-information metrics) verifies feature separation quality.
Authors: We thank the referee for highlighting this important point regarding the evidential support for the disentanglement claim. The manuscript compares the proposed adversarial framework to a single-task baseline, demonstrating AUC improvements and J-ratio reduction, which we interpret as evidence of effective speaker suppression while enhancing pathology detection. However, we acknowledge that an ablation against a multi-task network without gradient reversal and direct metrics such as speaker classification accuracy or mutual information are not included. To rigorously address this, we will incorporate an ablation study in the revised version, training an identical multi-task architecture without the adversarial loss for comparison. Additionally, we will evaluate speaker identification accuracy using the outputs of the pathology encoder to directly quantify the degree of speaker information suppression. These additions will provide stronger support for the central claim. revision: yes
-
Referee: [Results] Results: The reported performance improvements are presented without statistical significance tests, confidence intervals, or p-values. This undermines the claim of consistent outperformance over the single-task baseline and the assertion of reduced speaker dependency.
Authors: We agree with the referee that the absence of statistical significance testing, confidence intervals, and p-values limits the strength of our performance claims. The current results report point estimates of AUC improvements and J-ratio changes across the TACTICAS and Bridge2AI-Voice datasets. In the revised manuscript, we will add bootstrap-derived 95% confidence intervals for all AUC values and perform appropriate statistical tests, such as the DeLong test for comparing correlated AUCs, to determine if the observed improvements are statistically significant. We will also report p-values for the J-ratio reductions where applicable. This will be included in the Results section and discussed in the context of both tasks. revision: yes
Circularity Check
No circularity: empirical AUC gains and J-ratio from held-out training on distinct datasets
full rationale
The paper proposes an adversarial architecture using gradient reversal to suppress speaker identity while optimizing hierarchical respiratory classification tasks. Reported improvements (AUC 0.897 to 0.910 and 0.674 to 0.793 on TACTICAS, with external validation on Bridge2AI-Voice) and J-ratio decrease are obtained via standard empirical training and evaluation on held-out data. No equations, derivations, or self-citations are present that reduce these metrics to fitted parameters by construction, self-definitional loops, or load-bearing prior work by the same authors. The central claims rest on observable performance differences rather than any reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Adversarial training via gradient reversal can separate speaker identity from pathology-related acoustic features without loss of task-relevant information.
- domain assumption The TACTICAS and Bridge2AI-Voice datasets contain speech samples whose acoustic variations are primarily driven by respiratory status rather than recording conditions or demographics.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employed an adversarial learning framework to disentangle pathology-relevant features from speaker-identifiable attributes... Gradient Reversal Layer (GRL)... Ltotal = Lres − λ Lspk
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chronic obstructive pulmonary disease (copd),
World Health Organization, “Chronic obstructive pulmonary disease (copd),” 2024. [Online]. Available: www.who.int/news-room/fact- sheets/detail/chronic-obstructive-pulmonary-disease-(copd)
work page 2024
-
[2]
A. Ghimire, R. Allison, Y. Lichtemberg, J. J. Vempilly, and V . V . Jain, “A single home visit improves adherence and reduces healthcare utilization in patients with frequent exacerbations of severe asthma and copd,”Respiratory Medicine: X, vol. 3, p. 100026, 2021
work page 2021
-
[3]
C.-L. Tsai, S. K. Griswold, S. Clark, and C. A. Camargo Jr, “Factors associated with frequency of emergency department visits for chronic obstructive pulmonary disease exacerbation,”Journal of general internal medicine, vol. 22, no. 6, pp. 799–804, 2007
work page 2007
-
[4]
R. T. Bhowmik and S. P . Most, “A personalized respiratory disease exacerbation prediction technique based on a novel spatio-temporal machine learning architecture and local environmental sensor networks,”Electronics, vol. 11, no. 16, p. 2562, 2022
work page 2022
-
[5]
Concomitant diagnosis of asthma and copd: a quantitative study in uk primary care,
F. Nissen, D. R. Morales, H. Mullerova, L. Smeeth, I. J. Douglas, and J. K. Quint, “Concomitant diagnosis of asthma and copd: a quantitative study in uk primary care,”Br J Gen Pract, p. bjgp18X699389, 2018
work page 2018
-
[6]
J. Vestbo, S. S. Hurd, A. G. Agustí, P . W. Jones, C. Vogelmeier, A. Anzueto, P . J. Barnes, L. M. Fabbri, F. J. Martinez, M. Nishimuraet al., “Global strategy for the diagnosis, management, and prevention of chronic obstructive pulmonary disease: Gold executive summary,” American journal of respiratory and critical care medicine, vol. 187, no. 4, pp. 347...
work page 2013
-
[7]
Differentiating copd and asthma using quantitative ct imaging and machine learning,
A. Moslemi, K. Kontogianni, J. Brock, S. Wood, F. Herth, and M. Kirby, “Differentiating copd and asthma using quantitative ct imaging and machine learning,”European Respiratory Journal, vol. 60, no. 3, 2022
work page 2022
-
[8]
J. W. Kocks, H. Cao, B. Holzhauer, A. Kaplan, J. M. FitzGerald, K. Kostikas, D. Price, H. K. Reddel, I. Tsiligianni, C. F. Vogelmeier et al., “Diagnostic performance of a machine learning algorithm (asthma/chronic obstructive pulmonary disease [copd] differentiation classification) tool versus primary care physicians and pulmonologists in asthma, copd, an...
work page 2023
-
[9]
T. Xia, J. Han, and C. Mascolo, “Exploring machine learning for audio-based respiratory condition screening: A concise review of databases, methods, and open issues,”Experimental Biology and Medicine, vol. 247, no. 22, pp. 2053–2061, 2022
work page 2053
-
[10]
Automatic selection of the most characterizing features for detecting copd in speech,
L. van Bemmel, W. Harmsen, C. Cucchiarini, and H. Strik, “Automatic selection of the most characterizing features for detecting copd in speech,” inInternational Conference on Speech and Computer. Springer, 2021, pp. 737–748
work page 2021
-
[11]
Developing a multi-feature fusion model for exacerbation classification in asthma and copd,
Y. Yan, L. van Bemmel, F. M. Franssen, S. O. Simons, and V . Urovi, “Developing a multi-feature fusion model for exacerbation classification in asthma and copd,”Computer Methods and Programs in Biomedicine, p. 108796, 2025. 11
work page 2025
-
[12]
W. Mayr, A. Triantafyllopoulos, A. Batliner, B. W. Schuller, and T. M. Berghaus, “Assessing the clinical and functional status of copd patients using speech analysis during and after exacerbation,”International Journal of Chronic Obstructive Pulmonary Disease, pp. 137–147, 2025
work page 2025
-
[13]
S. H. Dumpala, K. Dikaios, S. Rodriguez, R. Langley, S. Rempel, R. Uher, and S. Oore, “Manifestation of depression in speech overlaps with characteristics used to represent and recognize speaker identity,”Scientific Reports, vol. 13, no. 1, p. 11155, 2023
work page 2023
-
[14]
Sine-wave speech and privacy-preserving depression detection,
S. H. Dumpala, R. Uher, S. Matwin, M. Kiefte, and S. Oore, “Sine-wave speech and privacy-preserving depression detection,” inProc. SMM21, Workshop on Speech, Music and Mind, vol. 2021, 2021, pp. 11–15
work page 2021
-
[15]
Privacy sensitive speech analysis using federated learning to assess depression,
S. Bn and S. Abdullah, “Privacy sensitive speech analysis using federated learning to assess depression,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6272–6276
work page 2022
-
[16]
S. Suissa, S. Dell’Aniello, and P . Ernst, “Long-term natural history of chronic obstructive pulmonary disease: severe exacerbations and mortality,”Thorax, vol. 67, no. 11, pp. 957–963, 2012
work page 2012
-
[17]
Machine learning-driven lung sound analysis: Novel methodology for asthma diagnosis,
I. Topaloglu, G. Ozduygu, C. Atasoy, G. Batıhan, D. Serce, G. Inanc, M. O. Güçsav, A. M. Yıldız, T. Tuncer, S. Doganet al., “Machine learning-driven lung sound analysis: Novel methodology for asthma diagnosis,”Advances in Respiratory Medicine, vol. 93, no. 5, p. 32, 2025
work page 2025
-
[18]
Covid-19 cough classification using machine learning and global smartphone recordings,
M. Pahar, M. Klopper, R. Warren, and T. Niesler, “Covid-19 cough classification using machine learning and global smartphone recordings,” Computers in Biology and Medicine, vol. 135, p. 104572, 2021
work page 2021
-
[19]
A. Idrisoglu, A. L. Dallora, A. Cheddad, P . Anderberg, A. Jakobsson, and J. S. Berglund, “Copdvd: Automated classification of chronic obstructive pulmonary disease on a new collected and evaluated voice dataset,”Artificial Intelligence in Medicine, vol. 156, p. 102953, 2024
work page 2024
-
[20]
V . S. Nallanthighal, A. Härmä, and H. Strik, “Detection of copd exacerbation from speech: comparison of acoustic features and deep learning based speech breathing models,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 9097–9101
work page 2022
-
[21]
Assessment of breathing patterns and voice of patients with copd and dysphonia,
K. W˛ eglarz, E. Szczygieł, A. Masło ´ n, and J. Blaut, “Assessment of breathing patterns and voice of patients with copd and dysphonia,” Respiratory Medicine, vol. 240, p. 108012, 2025
work page 2025
-
[22]
N. S. Alghamdi, M. Zakariah, and H. Karamti, “A deep cnn-based acoustic model for the identification of lung diseases utilizing extracted mfcc features from respiratory sounds,”Multimedia Tools and Applications, vol. 83, no. 35, pp. 82 871–82 903, 2024
work page 2024
-
[23]
The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,
F. Eyben, K. R. Scherer, B. W. Schuller, J. Sundberg, E. André, C. Busso, L. Y. Devillers, J. Epps, P . Laukka, S. S. Narayananet al., “The geneva minimalistic acoustic parameter set (gemaps) for voice research and affective computing,”IEEE transactions on affective computing, vol. 7, no. 2, pp. 190–202, 2015
work page 2015
-
[24]
Sustained vowels for pre-vs post-treatment copd classification,
A. Triantafyllopoulos, A. Batliner, W. Mayr, M. Fendler, F. Pokorny, M. Gerczuk, S. Amiriparian, T. Berghaus, and B. Schuller, “Sustained vowels for pre-vs post-treatment copd classification,”arXiv preprint arXiv:2406.06355, 2024
-
[25]
Optimizing mfcc parameters for the automatic detection of respiratory diseases,
Y. Yan, S. O. Simons, L. van Bemmel, L. G. Reinders, F. M. Franssen, and V . Urovi, “Optimizing mfcc parameters for the automatic detection of respiratory diseases,”Applied Acoustics, vol. 228, p. 110299, 2025
work page 2025
-
[26]
Multimodal lung disease classification using deep convolutional neural network,
Z. Tariq, S. K. Shah, and Y. Lee, “Multimodal lung disease classification using deep convolutional neural network,” in2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), 2020, pp. 2530–2537
work page 2020
-
[27]
V . Despotovic, A. Elbéji, K. Fünfgeld, M. Pizzimenti, H. Ayadi, P . V . Nazarov, and G. Fagherazzi, “Digital voice-based biomarker for monitoring respiratory quality of life: findings from the colive voice study,”Biomedical Signal Processing and Control, vol. 96, p. 106555, 2024
work page 2024
-
[28]
Covid-19 detection from respiratory sounds with hierarchical spectrogram transformers,
I. Aytekin, O. Dalmaz, K. Gonc, H. Ankishan, E. U. Saritas, U. Bagci, H. Celik, and T. Çukur, “Covid-19 detection from respiratory sounds with hierarchical spectrogram transformers,”IEEE Journal of Biomedical and Health Informatics, vol. 28, no. 3, pp. 1273–1284, 2024
work page 2024
-
[29]
Towards open respiratory acoustic foundation models: Pretraining and benchmarking,
Y. Zhang, T. Xia, J. Han, Y. Wu, G. Rizos, Y. Liu, M. Mosuily, J. Ch, and C. Mascolo, “Towards open respiratory acoustic foundation models: Pretraining and benchmarking,”Advances in Neural Information Processing Systems, vol. 37, pp. 27 024–27 055, 2024
work page 2024
-
[30]
Telemonitoring for asthma and copd through voice analysis: the tacticas study
“Telemonitoring for asthma and copd through voice analysis: the tacticas study.” [Online]. Available: https://onderzoekmetmensen.nl/en/trial/27652
-
[31]
Extrafine beclomethasone/formoterol in severe copd patients with history of exacerbations,
J. Wedzicha, D. Singh, J. Vestbo, P . Paggiaro, P . Jones, F. Bonnet-Gonod, G. Cohuet, M. Corradi, S. Vezzoli, S. Petruzzelliet al., “Extrafine beclomethasone/formoterol in severe copd patients with history of exacerbations,”Respiratory medicine, vol. 108, no. 8, pp. 1153–1162, 2014
work page 2014
-
[32]
Bridge2AI-Voice: An ethically-sourced, diverse voice dataset linked to health information,
Y. Bensoussan, A. Sigaras, A. Rameau, O. Elemento, M. Powell, D. Dorr, P . Payne, V . Ravitsky, J.-C. Bélisle-Pipon, A. Johnson, R. Bahr, S. Watts, D. Bolser, J. Siu, J. Lerner-Ellis, F. Rudzicz, M. Boyer, S. S. Cruz, Y. Abdel-Aty, T. A. Syed, J. Anibal, S. Aradi, A. S. Martinez, S. Awan, S. Bedrick, A. Bernier, I. Bevers, R. Brito, S. Casalino, J. Costel...
-
[33]
Developing a LeFF Transformer Model for Exacerbated Speech Detection in COPD and Asthma ,
Yuyang Yan and Sami O. Simons and Visara Urovi, “Developing a LeFF Transformer Model for Exacerbated Speech Detection in COPD and Asthma ,” inInterspeech 2025, 2025, pp. 993–997
work page 2025
-
[34]
Incorporating convolution designs into visual transformers,
K. Yuan, S. Guo, Z. Liu, A. Zhou, F. Yu, and W. Wu, “Incorporating convolution designs into visual transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 579–588
work page 2021
-
[35]
Uformer: A general u-shaped transformer for image restoration,
Z. Wang, X. Cun, J. Bao, W. Zhou, J. Liu, and H. Li, “Uformer: A general u-shaped transformer for image restoration,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 17 683–17 693
work page 2022
-
[36]
Speaker-invariant adversarial domain adaptation for emotion recognition,
Y. Yin, B. Huang, Y. Wu, and M. Soleymani, “Speaker-invariant adversarial domain adaptation for emotion recognition,” inProceedings of the 2020 International Conference on Multimodal Interaction, 2020, pp. 481–490
work page 2020
-
[37]
J. Guo, G. Yeung, D. Muralidharan, H. Arsikere, A. Afshan, and A. Alwan, “Speaker verification using short utterances with dnn-based estimation of subglottal acoustic features.” inINTERSPEECH, 2016, pp. 2219–2222
work page 2016
-
[38]
Freevc: Towards high-quality text-free one-shot voice conversion,
J. Li, W. Tu, and L. Xiao, “Freevc: Towards high-quality text-free one-shot voice conversion,” inICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
work page 2023
-
[39]
Robust speaker recognition integrating pitch and wiener filter,
J. Bai, R. Zheng, B. Xu, and S. Zhang, “Robust speaker recognition integrating pitch and wiener filter,” in2004 International Symposium on Chinese Spoken Language Processing. IEEE, 2004, pp. 69–72
work page 2004
-
[40]
R. D. Kent, “Vocal tract acoustics,”Journal of Voice, vol. 7, no. 2, pp. 97–117, 1993
work page 1993
-
[41]
The formant bandwidth as a measure of vowel intelligibility in dysphonic speech,
K. Ishikawa and J. Webster, “The formant bandwidth as a measure of vowel intelligibility in dysphonic speech,”Journal of Voice, vol. 37, no. 2, pp. 173–177, 2023
work page 2023
-
[42]
Time course of the first formant bandwidth,
H. Park, “Time course of the first formant bandwidth,” inAnnual Meeting of the Berkeley Linguistics Society, 2002, pp. 213–224
work page 2002
-
[43]
Effects of asthma on breathing during reading aloud,
B. Wiechern, K. A. Liberty, P . Pattemore, and E. Lin, “Effects of asthma on breathing during reading aloud,”Speech, Language and Hearing, vol. 21, no. 1, pp. 30–40, 2018
work page 2018
-
[44]
A. M. Saeed, N. M. Riad, N. M. Osman, A. N. Khattab, and S. E. Mohammed, “Study of voice disorders in patients with bronchial asthma and chronic obstructive pulmonary disease,”Egyptian Journal of Bronchology, vol. 12, no. 1, pp. 20–26, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.