Mind the Gap: Learning Modality-Agnostic Representations with a Cross-Modality UNet
Pith reviewed 2026-05-19 21:47 UTC · model grok-4.3
pith:I3SUNKSA Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{I3SUNKSA}
Prints a linked pith:I3SUNKSA badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
A compact encoder-decoder network learns modality-agnostic representations while retaining identity-related information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
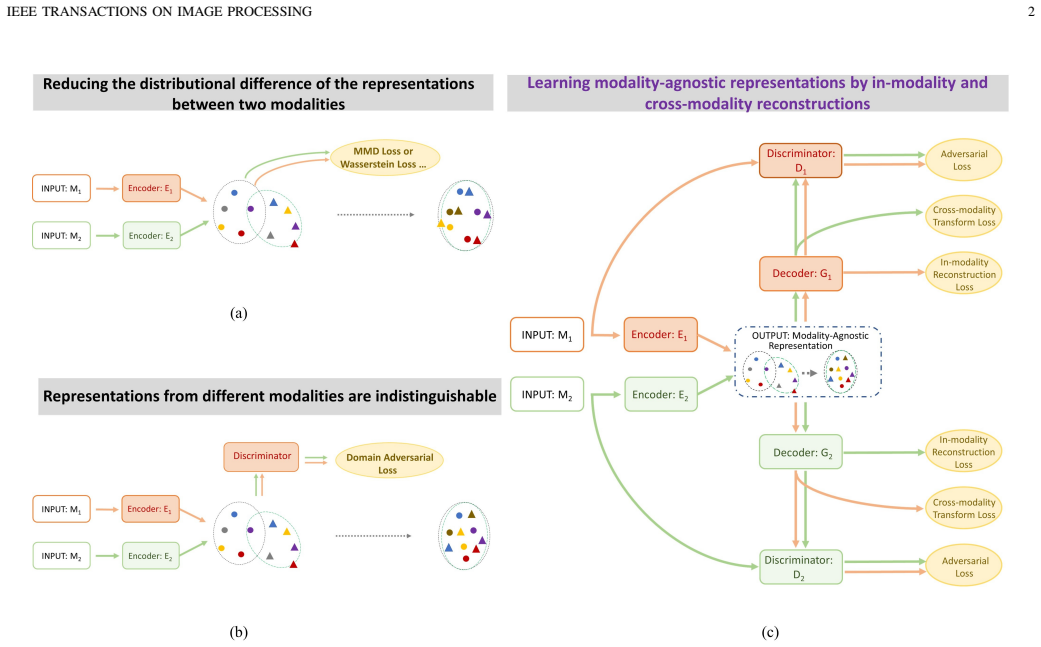
The authors claim that their cmUNet achieves modality-agnostic representations by performing cross-modality transformation and in-modality reconstruction, enhanced by an adversarial or perceptual loss that promotes indistinguishability in the original sample space, allowing better retention of identity information than previous approaches and leading to superior cross-modality matching results.
What carries the argument
cmUNet, a compact encoder-decoder neural module that learns modality-agnostic representations through cross-modality transformation and in-modality reconstruction.
If this is right
- Cross-modality person re-identification and heterogeneous face recognition achieve higher accuracy than prior methods.
- Matching performance stays stable even when explicit modality transfers are difficult or impossible.
- Robustness to occlusions indicates successful bridging of the modality gap.
- The same module improves performance on Raman-infrared spectrum matching tasks.
Where Pith is reading between the lines
- The same transformation-plus-reconstruction pattern could be tested on additional modality pairs such as audio-visual or text-image data.
- Real-time biometric systems might incorporate the module to handle mixed sensor inputs without retraining separate pipelines.
- Datasets with systematic partial occlusions could be used to quantify how well the occlusion-robustness indicator predicts overall gap-bridging success.
Load-bearing premise
That cross-modality transformation combined with in-modality reconstruction and adversarial loss can retain discriminant identity information without the drawbacks of prior distributional alignment or transfer methods, and that robustness to occlusions reliably indicates successful modality-gap bridging.
What would settle it
Controlled experiments in which matching accuracy of the proposed method is compared against distributional-alignment baselines under increasing levels of occlusion; if accuracy does not remain higher, the claim that identity information is better retained would be undermined.
Figures









read the original abstract
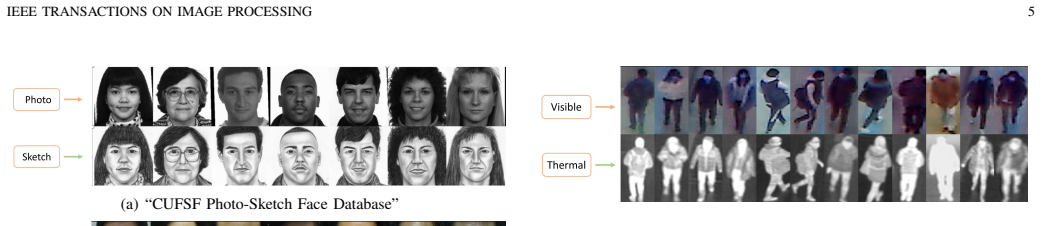
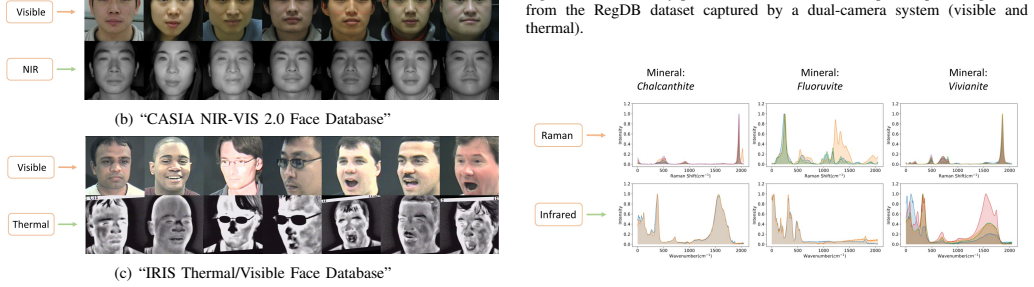
Cross-modality recognition has many important applications in science, law enforcement and entertainment. Popular methods to bridge the modality gap include reducing the distributional differences of representations of different modalities, learning indistinguishable representations or explicit modality transfer. The first two approaches suffer from the loss of discriminant information while removing the modality-specific variations. The third one heavily relies on the successful modality transfer, could face catastrophic performance drop when explicit modality transfers are not possible or difficult. To tackle this problem, we proposed a compact encoder-decoder neural module (cmUNet) to learn modality-agnostic representations while retaining identity-related information. This is achieved through cross-modality transformation and in-modality reconstruction, enhanced by an adversarial/perceptual loss which encourages indistinguishability of representations in the original sample space. For cross-modality matching, we propose MarrNet where cmUNet is connected to a standard feature extraction network which takes as inputs the modality-agnostic representations and outputs similarity scores for matching. We validated our method on five challenging tasks, namely Raman-infrared spectrum matching, cross-modality person re-identification and heterogeneous (photo-sketch, visible-near infrared and visible-thermal) face recognition, where MarrNet showed superior performance compared to state-of-the-art methods. Furthermore, it is observed that a cross-modality matching method could be biased to extract discriminant information from partial or even wrong regions, due to incompetence of dealing with modality gaps, which subsequently leads to poor generalization. We show that robustness to occlusions can be an indicator of whether a method can well bridge the modality gap.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes cmUNet, a compact encoder-decoder architecture, to learn modality-agnostic representations via cross-modality transformation paired with in-modality reconstruction, regularized by adversarial and perceptual losses that promote indistinguishability in the original sample space. This module is embedded in MarrNet, which connects the learned representations to a standard feature extractor for producing similarity scores in cross-modality matching. The authors report superior performance relative to state-of-the-art methods across five tasks (Raman-infrared spectrum matching, cross-modality person re-identification, and heterogeneous face recognition in photo-sketch, visible-NIR, and visible-thermal settings) and propose occlusion robustness as a diagnostic for successful modality-gap bridging.
Significance. If the empirical results and the claimed preservation of identity information hold under detailed scrutiny, the work offers a practical route to cross-modality recognition that sidesteps both the discriminant-information loss of distributional-alignment techniques and the failure modes of explicit transfer. The multi-task evaluation and the occlusion-robustness diagnostic are constructive contributions that could influence biometric and scientific imaging pipelines.
major comments (2)
- [§3] §3 (cmUNet architecture and loss formulation): The manuscript correctly notes that explicit modality-transfer methods can suffer catastrophic drops when the source-to-target mapping is ill-posed. However, cmUNet itself performs an internal cross-modality transformation. No equation, proof sketch, or targeted ablation demonstrates why the added in-modality reconstruction plus adversarial/perceptual loss renders this transformation immune to the same failure mode when identity cues are modality-specific. This distinction is load-bearing for the central claim that modality-agnostic representations are obtained without the losses of prior alignment or transfer methods.
- [§4] §4 and associated tables (quantitative results): The abstract and experimental claims assert superior performance on five tasks, yet the manuscript supplies no error bars, statistical significance tests, or ablations that isolate the contribution of the reconstruction and adversarial terms. If the reported gains rest primarily on the full model without controls that remove the cross-modality path, the evidence that discriminant identity information is retained remains only moderately supported.
minor comments (2)
- [Abstract] The abstract would be strengthened by a single sentence summarizing the primary quantitative metric and the magnitude of improvement over the strongest baseline.
- [Figure 1] Figure 1 (architecture diagram) should explicitly label the cross-modality and in-modality paths and the point at which the adversarial loss is applied.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work's potential impact and for the constructive major comments. We address each point below, providing clarifications and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (cmUNet architecture and loss formulation): The manuscript correctly notes that explicit modality-transfer methods can suffer catastrophic drops when the source-to-target mapping is ill-posed. However, cmUNet itself performs an internal cross-modality transformation. No equation, proof sketch, or targeted ablation demonstrates why the added in-modality reconstruction plus adversarial/perceptual loss renders this transformation immune to the same failure mode when identity cues are modality-specific. This distinction is load-bearing for the central claim that modality-agnostic representations are obtained without the losses of prior alignment or transfer methods.
Authors: We value this comment as it highlights a crucial aspect of our design. The in-modality reconstruction serves as a regularizer that ensures the latent representation captures identity information independently of the modality transformation. By requiring the decoder to reconstruct the input from the latent code in the original modality, we enforce retention of discriminant features. The adversarial and perceptual losses then facilitate the cross-modality mapping without discarding this information. This combination differentiates our approach from pure transfer methods, which lack the reconstruction anchor. We will include a more formal description of this rationale, along with any necessary equations or conceptual proof sketch, in the revised §3. We also plan to add a targeted ablation study to empirically demonstrate the role of the in-modality path. revision: partial
-
Referee: [§4] §4 and associated tables (quantitative results): The abstract and experimental claims assert superior performance on five tasks, yet the manuscript supplies no error bars, statistical significance tests, or ablations that isolate the contribution of the reconstruction and adversarial terms. If the reported gains rest primarily on the full model without controls that remove the cross-modality path, the evidence that discriminant identity information is retained remains only moderately supported.
Authors: We agree that additional statistical analysis and ablations would enhance the robustness of our claims. In the revised manuscript, we will report error bars from repeated experiments and include p-values from appropriate statistical tests to validate the superiority over baselines. Moreover, we will present ablation studies that systematically remove the reconstruction loss, the adversarial loss, and the cross-modality transformation path to isolate their effects on performance and identity preservation. These revisions will provide stronger support for the claim that our method retains discriminant identity information. revision: yes
Circularity Check
No significant circularity in proposed architecture and empirical results
full rationale
The paper introduces a novel compact encoder-decoder module (cmUNet) that performs cross-modality transformation and in-modality reconstruction, augmented by adversarial/perceptual loss, then connects it to a feature extractor (MarrNet) for matching. Claims of modality-agnostic representations that retain identity information are supported directly by the architecture definition and by reported superior performance on five external tasks (Raman-IR, person re-ID, heterogeneous face recognition). No load-bearing step reduces by construction to a fitted input, self-defined quantity, or prior self-citation chain; the derivation is self-contained as a new proposal tested against benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Adversarial loss weighting
- cmUNet architecture hyperparameters
axioms (1)
- domain assumption Neural networks can simultaneously remove modality-specific variation and preserve identity-related information.
invented entities (2)
-
cmUNet
no independent evidence
-
MarrNet
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Matching forensic sketches to mug shot photos,
B. Klare, Z. Li, and A. K. Jain, “Matching forensic sketches to mug shot photos,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 33, pp. 639–646, Mar. 2011
work page 2011
-
[2]
Composite sketch recognition via deep network - a transfer learning approach,
P. Mittal, M. Vatsa, and R. Singh, “Composite sketch recognition via deep network - a transfer learning approach,” inProc. Int. Conf. Biometrics. (ICB), 2015, pp. 251–256
work page 2015
-
[3]
J. Lu, V . E. Liong, and J. Zhou, “Simultaneous local binary feature learning and encoding for homogeneous and heterogeneous face recog- nition,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 40, pp. 1979–1993, Aug. 2018
work page 1979
-
[4]
Face sketch synthesis and recognition,
X. Tang and X. Wang, “Face sketch synthesis and recognition,” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2003, pp. 687–694 vol.1
work page 2003
-
[5]
A nonlinear approach for face sketch synthesis and recognition,
Q. Liu, X. Tang, H. Jin, H. Lu, and S. Ma, “A nonlinear approach for face sketch synthesis and recognition,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2005, pp. 1005–1010
work page 2005
-
[6]
Face photo-sketch synthesis and recognition,
X. Wang and X. Tang, “Face photo-sketch synthesis and recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 31, pp. 1955–1967, Nov. 2009
work page 1955
-
[7]
Graphical representation for heterogeneous face recognition,
C. Peng, X. Gao, N. Wang, and J. Li, “Graphical representation for heterogeneous face recognition,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, pp. 301–312, Feb. 2017
work page 2017
-
[8]
Identity-aware cyclegan for face photo-sketch synthesis and recognition,
Y . Fang, W. Deng, J. Du, and J. Hu, “Identity-aware cyclegan for face photo-sketch synthesis and recognition,”Pattern Recognit., vol. 102, p. 107249, Jan. 2020
work page 2020
-
[9]
Iterative local re-ranking with attribute guided synthesis for face sketch recognition,
D. Liu, X. Gao, N. Wang, C. Peng, and J. Li, “Iterative local re-ranking with attribute guided synthesis for face sketch recognition,”Pattern Recognit., vol. 109, p. 107579, Aug. 2020
work page 2020
-
[10]
Wasserstein cnn: Learning invariant features for nir-vis face recognition,
R. He, X. Wu, Z. Sun, and T. Tan, “Wasserstein cnn: Learning invariant features for nir-vis face recognition,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 41, pp. 1761–1773, July. 2019
work page 2019
-
[11]
Dvg-face: Dual variational generation for heterogeneous face recognition,
C. Fu, X. Wu, Y . Hu, H. Huang, and R. He, “Dvg-face: Dual variational generation for heterogeneous face recognition,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, pp. 2938–2952, June. 2022
work page 2022
-
[12]
Iris thermal/visible face database
Riad I. Hammoud., “Iris thermal/visible face database.” http:// vcipl-okstate.org/pbvs/bench/index.html
-
[13]
Y . Zhang and H. Wang, “Diverse embedding expansion network and low-light cross-modality benchmark for visible-infrared person re- identification,” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2023, pp. 2153–2162
work page 2023
-
[14]
Towards a unified middle modality learning for visible-infrared person re-identification,
Y . Zhang, Y . Yan, Y . Lu, and H. Wang, “Towards a unified middle modality learning for visible-infrared person re-identification,” inProc. ACM Int. Conf. Multimedia(ACM MM), Oct, 2021, pp. 788–796, 2021
work page 2021
-
[15]
Fmcnet: Feature-level modality compensation for visible-infrared person re-identification,
Q. Zhang, C. Lai, J. Liu, N. Huang, and J. Han, “Fmcnet: Feature-level modality compensation for visible-infrared person re-identification,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2022, pp. 7349–7358
work page 2022
-
[16]
Rethinking maximum mean discrepancy for visual domain adaptation,
W. Wang, H. Li, Z. Ding, F. Nie, J. Chen, X. Dong, and Z. Wang, “Rethinking maximum mean discrepancy for visual domain adaptation,” IEEE Trans. Neural Netw. Learn. Syst., vol. 34, pp. 264–277, Jan. 2023
work page 2023
-
[17]
Adversarial dis- criminative domain adaptation,
E. Tzeng, J. Hoffman, K. Saenko, and T. Darrell, “Adversarial dis- criminative domain adaptation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2017, pp. 7167–7176
work page 2017
-
[18]
Deep convolutional neural networks for Raman spectrum recognition: A unified solution,
J. Liu, M. Osadchy, L. Ashton, M. Foster, C. J. Solomon, and S. J. Gibson, “Deep convolutional neural networks for Raman spectrum recognition: A unified solution,”Analyst, vol. 142, pp. 4067–4074, Nov. 2017
work page 2017
-
[19]
L. Liu, M. Ji, and M. Buchroithner, “Transfer learning for soil spec- troscopy based on convolutional neural networks and its application in soil clay content mapping using hyperspectral imagery,”Sensors (Switzerland), vol. 18, 2018
work page 2018
-
[20]
Deep learning-based component identification for the Raman spectra of mixtures,
X. Fan, W. Ming, H. Zeng, Z. Zhang, and H. Lu, “Deep learning-based component identification for the Raman spectra of mixtures,”Analyst, vol. 144, pp. 1789–1798, 2019
work page 2019
-
[21]
Rapid identification of pathogenic bacteria using Raman spectroscopy and deep learning,
C. S. Ho, N. Jean, C. A. Hogan, L. Blackmon, S. S. Jeffrey, M. Holodniy, N. Banaei, A. A. Saleh, S. Ermon, and J. Dionne, “Rapid identification of pathogenic bacteria using Raman spectroscopy and deep learning,” Nat. Commun., vol. 10, Oct. 2019
work page 2019
-
[22]
C. Carlomagno, D. Bertazioli, A. Gualerzi, S. Picciolini, P. Banfi, A. Lax, E. Messina, J. Navarro, L. Bianchi, A. Caronni,et al., “Covid- 19 salivary raman fingerprint: innovative approach for the detection of current and past sars-cov-2 infections,”Sci. Rep., vol. 11, no. 1, pp. 1– 13, 2021
work page 2021
-
[23]
K. Ember, F. Daoust, M. Mahfoud, F. Dallaire, E. Z. Ahmad, T. Tran, A. Plante, M.-K. Diop, T. Nguyen, A. St-Georges-Robillard,et al., “Saliva-based detection of covid-19 infection in a real-world setting us- ing reagent-free raman spectroscopy and machine learning,”J. Biomed. Opt., vol. 27, no. 2, p. 025002, 2022
work page 2022
-
[24]
F. Lussier, D. Missirlis, J. P. Spatz, and J. F. Masson, “Machine- Learning-Driven Surface-Enhanced Raman Scattering Optophysiology Reveals Multiplexed Metabolite Gradients Near Cells,”ACS Nano, 2019
work page 2019
-
[25]
S. D. Krauß, R. Roy, H. K. Yosef, T. Lechtonen, S. F. El-Mashtoly, K. Gerwert, and A. Mosig, “Hierarchical deep convolutional neural networks combine spectral and spatial information for highly accu- rate raman-microscopy-based cytopathology,”J. Biophotonics, vol. 11, no. 10, p. e201800022, 2018
work page 2018
-
[26]
Using deep learning to predict soil properties from regional spectral data,
J. Padarian, B. Minasny, and A. B. McBratney, “Using deep learning to predict soil properties from regional spectral data,”Geoderma Regional, vol. 16, p. e00198, 2019
work page 2019
-
[27]
F. Hu, M. Zhou, P. Yan, D. Li, W. Lai, K. Bian, and R. Dai, “Identifica- tion of mine water inrush using laser-induced fluorescence spectroscopy combined with one-dimensional convolutional neural network,”RSC Advances, vol. 9, pp. 7673–7679, 2019. IEEE TRANSACTIONS ON IMAGE PROCESSING 15
work page 2019
-
[28]
Dynamic spectrum matching with one-shot learning,
J. Liu, S. J. Gibson, J. Mills, and M. Osadchy, “Dynamic spectrum matching with one-shot learning,”Chemom. Intell. Lab. Syst., vol. 184, pp. 175 – 181, Dec. 2018
work page 2018
-
[29]
Unsupervised domain adaptation by backpropagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by backpropagation,” inProc.Int. Conf. Machine. Learning. (ICML), June. 2015, pp. 1180–1189
work page 2015
-
[30]
Few-shot ad- versarial domain adaptation,
S. Motiian, Q. Jones, S. Iranmanesh, and G. Doretto, “Few-shot ad- versarial domain adaptation,” inProc. Adv. Neural Inf. Process. Syst. (NIPS), vol. 30, 2017
work page 2017
-
[31]
Adversarial feature augmentation for unsupervised domain adaptation,
R. V olpi, P. Morerio, S. Savarese, and V . Murino, “Adversarial feature augmentation for unsupervised domain adaptation,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2018, pp. 5495– 5504
work page 2018
-
[32]
Cross-modality person re-identification with generative adversarial training,
P. Dai, R. Ji, H. Wang, Q. Wu, and Y . Huang, “Cross-modality person re-identification with generative adversarial training,” inProc. Int. Join. Conf. Artif. Intel. (IJCAI), Aug. 2018, pp. 677–683, 7 2018
work page 2018
-
[33]
Neural style transfer: A review,
Y . Jing, Y . Yang, Z. Feng, J. Ye, Y . Yu, and M. Song, “Neural style transfer: A review,”IEEE Trans. Vis. Comput. Graph., vol. 26, pp. 3365– 3385, Nov. 2019
work page 2019
-
[34]
Deep learning for text style transfer: A survey,
D. Jin, Z. Jin, Z. Hu, O. Vechtomova, and R. Mihalcea, “Deep learning for text style transfer: A survey,”Comput. Linguist., vol. 48, pp. 155– 205, Apr. 2022
work page 2022
-
[35]
Q.-Y . Jiang and W.-J. Li, “Deep cross-modal hashing,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2017, pp. 3232–3240
work page 2017
-
[36]
Learning the best pooling strategy for visual semantic embedding,
J. Chen, H. Hu, H. Wu, Y . Jiang, and C. Wang, “Learning the best pooling strategy for visual semantic embedding,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2021, pp. 15789– 15798
work page 2021
-
[37]
Dense events grounding in video,
P. Bao, Q. Zheng, and Y . Mu, “Dense events grounding in video,” in Proc. AAAI Conf. Artif. Intell. (AAAI), 2021, pp. 920–928
work page 2021
-
[38]
Negative sample matters: A renaissance of metric learning for temporal grounding,
Z. Wang, L. Wang, T. Wu, T. Li, and G. Wu, “Negative sample matters: A renaissance of metric learning for temporal grounding,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2022, pp. 2613–2623
work page 2022
-
[39]
Infrared-visible cross-modal person re-identification with an x modality,
D. Li, X. Wei, X. Hong, and Y . Gong, “Infrared-visible cross-modal person re-identification with an x modality,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2020, pp. 4610–4617
work page 2020
-
[40]
Cm-nas: Cross- modality neural architecture search for visible-infrared person re- identification,
C. Fu, Y . Hu, X. Wu, H. Shi, T. Mei, and R. He, “Cm-nas: Cross- modality neural architecture search for visible-infrared person re- identification,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2021, pp. 11823–11832
work page 2021
-
[41]
Non-autoregressive coarse-to- fine video captioning,
B. Yang, Y . Zou, F. Liu, and C. Zhang, “Non-autoregressive coarse-to- fine video captioning,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2021, pp. 3119–3127
work page 2021
-
[42]
Augmented partial mutual learning with frame masking for video captioning,
K. Lin, Z. Gan, and L. Wang, “Augmented partial mutual learning with frame masking for video captioning,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2021, pp. 2047–2055
work page 2021
-
[43]
Audio-oriented multimodal machine comprehension via dynamic inter- and intra-modality attention,
Z. Huang, F. Liu, X. Wu, S. Ge, H. Wang, W. Fan, and Y . Zou, “Audio-oriented multimodal machine comprehension via dynamic inter- and intra-modality attention,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2021, pp. 13098–13106
work page 2021
-
[44]
W. Yu, H. Xu, Z. Yuan, and J. Wu, “Learning modality-specific representations with self-supervised multi-task learning for multimodal sentiment analysis,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2021, pp. 10790–10797
work page 2021
-
[45]
Multi- modal multi-label emotion recognition with heterogeneous hierarchical message passing,
D. Zhang, X. Ju, W. Zhang, J. Li, S. Li, Q. Zhu, and G. Zhou, “Multi- modal multi-label emotion recognition with heterogeneous hierarchical message passing,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2021, pp. 14338–14346
work page 2021
-
[46]
Heterogeneous face recog- nition from local structures of normalized appearance,
S. Liao, D. Yi, Z. Lei, R. Qin, and S. Z. Li, “Heterogeneous face recog- nition from local structures of normalized appearance,” inAdvances in Biometrics(M. Tistarelli and M. S. Nixon, eds.), (Berlin, Heidelberg), pp. 209–218, Springer Berlin Heidelberg, 2009
work page 2009
-
[47]
Evaluation of face recognition system in heterogeneous environments (visible vs nir),
D. Goswami, C. H. Chan, D. Windridge, and J. Kittler, “Evaluation of face recognition system in heterogeneous environments (visible vs nir),” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2011, pp. 2160– 2167
work page 2011
-
[48]
Inter-modality face recognition,
D. Lin and X. Tang, “Inter-modality face recognition,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2006, pp. 13–26
work page 2006
-
[49]
Joint feature selection and subspace learning for cross-modal retrieval,
K. Wang, R. He, L. Wang, W. Wang, and T. Tan, “Joint feature selection and subspace learning for cross-modal retrieval,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, pp. 2010–2023, Oct. 2016
work page 2010
-
[50]
Syncretic modality collabora- tive learning for visible infrared person re-identification,
Z. Wei, X. Yang, N. Wang, and X. Gao, “Syncretic modality collabora- tive learning for visible infrared person re-identification,” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2021, pp. 225–234
work page 2021
-
[51]
Learning with twin noisy labels for visible-infrared person re-identification,
M. Yang, Z. Huang, P. Hu, T. Li, J. Lv, and X. Peng, “Learning with twin noisy labels for visible-infrared person re-identification,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2022, pp. 14308–14317
work page 2022
-
[52]
Neural feature search for rgb-infrared person re-identification,
Y . Chen, L. Wan, Z. Li, Q. Jing, and Z. Sun, “Neural feature search for rgb-infrared person re-identification,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2021, pp. 587–597
work page 2021
-
[53]
End-to-end photo- sketch generation via fully convolutional representation learning,
L. Zhang, L. Lin, X. Wu, S. Ding, and L. Zhang, “End-to-end photo- sketch generation via fully convolutional representation learning,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2015, pp. 627–634
work page 2015
-
[54]
Back projection: An effective postprocessing method for gan-based face sketch synthesis,
N. Wang, W. Zha, J. Li, and X. Gao, “Back projection: An effective postprocessing method for gan-based face sketch synthesis,”Pattern Recognit. Letters., vol. 107, pp. 59–65, May. 2018
work page 2018
-
[55]
Unsupervised facial geometry learning for sketch to photo synthesis,
H. Kazemi, F. Taherkhani, and N. M. Nasrabadi, “Unsupervised facial geometry learning for sketch to photo synthesis,” inProc. Int. Conf. Biometrics. Special. Interest Group. (BIOSIG), 2018, pp. 1–5
work page 2018
-
[56]
High-quality facial photo-sketch syn- thesis using multi-adversarial networks,
L. Wang, V . Sindagi, and V . Patel, “High-quality facial photo-sketch syn- thesis using multi-adversarial networks,” inProc. Int. Conf. Automatic. Face & Gesture. Recognit. (FG), 2018, pp. 83–90
work page 2018
-
[57]
Fully convolutional networks for semantic segmentation,
E. Shelhamer, J. Long, and T. Darrell, “Fully convolutional networks for semantic segmentation,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 39, pp. 640–651, Apr. 2017
work page 2017
-
[58]
Unpaired image-to- image translation using cycle-consistent adversarial networks,
J.-Y . Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to- image translation using cycle-consistent adversarial networks,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2017, pp. 2223–2232
work page 2017
-
[59]
The power of databases: the rruff project,
B. Lafuente, R. T. Downs, H. Yang, and N. Stone, “The power of databases: the rruff project,”Highlights. Minera. Crystallography., pp. 1–30, Jan. 2016
work page 2016
-
[60]
Bayesian triplet loss: Uncertainty quantification in image retrieval,
F. Warburg, M. Jørgensen, J. Civera, and S. Hauberg, “Bayesian triplet loss: Uncertainty quantification in image retrieval,” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2021, pp. 12138–12148
work page 2021
-
[61]
Image-to-image transla- tion with conditional adversarial networks,
P. Isola, J.-Y . Zhu, T. Zhou, and A. A. Efros, “Image-to-image transla- tion with conditional adversarial networks,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2017, pp. 1125–1134
work page 2017
-
[62]
Discriminative shared transform learning for sketch to image matching,
S. Nagpal, M. Singh, R. Singh, and M. Vatsa, “Discriminative shared transform learning for sketch to image matching,”Pattern Recognit., vol. 114, p. 107815, Jan. 2021
work page 2021
-
[63]
C. Reale, N. M. Nasrabadi, H. Kwon, and R. Chellappa, “Seeing the forest from the trees: A holistic approach to near-infrared heterogeneous face recognition,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recog- nit. (CVPR), June. 2016, pp. 320–328
work page 2016
-
[64]
Heterogeneous face recognition with cnns,
S. Saxena and J. Verbeek, “Heterogeneous face recognition with cnns,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2016, pp. 483–491
work page 2016
-
[65]
J. Lezama, Q. Qiu, and G. Sapiro, “Not afraid of the dark: Nir-vis face recognition via cross-spectral hallucination and low-rank embedding,” Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2016, pp. 6807–6816
work page 2016
-
[66]
Transferring deep representa- tion for nir-vis heterogeneous face recognition,
X. Liu, L. Song, X. Wu, and T. Tan, “Transferring deep representa- tion for nir-vis heterogeneous face recognition,” in2016 International Conference on Biometrics (ICB), pp. 1–8, 2016
work page 2016
-
[67]
Dlface: Deep local descriptor for cross-modality face recognition,
C. Peng, N. Wang, J. Li, and X. Gao, “Dlface: Deep local descriptor for cross-modality face recognition,”Pattern Recognit., vol. 90, pp. 161– 171, 2019
work page 2019
-
[68]
Cross-spectral face hallucination via disentangling independent factors,
B. Duan, C. Fu, Y . Li, X. Song, and R. He, “Cross-spectral face hallucination via disentangling independent factors,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2020, pp. 7927– 7935
work page 2020
-
[69]
Residual compensation networks for heterogeneous face recognition,
Z. Deng, X. Peng, and Y . Qiao, “Residual compensation networks for heterogeneous face recognition,”Proc. AAAI Conf. Artif. Intell. (AAAI), 2019, pp. 8239–8246
work page 2019
-
[70]
Mutual component convolutional neural networks for heterogeneous face recognition,
Z. Deng, X. Peng, Z. Li, and Y . Qiao, “Mutual component convolutional neural networks for heterogeneous face recognition,”IEEE Trans. Image Process., vol. 28, pp. 3102–3114, June. 2019
work page 2019
-
[71]
Disentangled variational representation for heterogeneous face recognition,
X. Wu, H. Huang, V . M. Patel, R. He, and Z. Sun, “Disentangled variational representation for heterogeneous face recognition,”Proc. AAAI Conf. Artif. Intell. (AAAI), 2019, pp. 9005–9012
work page 2019
-
[72]
Discover cross-modality nuances for visible-infrared person re- identification,
Q. Wu, P. Dai, J. Chen, C.-W. Lin, Y . Wu, F. Huang, B. Zhong, and R. Ji, “Discover cross-modality nuances for visible-infrared person re- identification,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2021, pp. 4330–4339
work page 2021
-
[73]
Channel augmented joint learning for visible-infrared recognition,
M. Ye, W. Ruan, B. Du, and M. Z. Shou, “Channel augmented joint learning for visible-infrared recognition,” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2021, pp. 13567–13576
work page 2021
-
[74]
J. Liu, Y . Sun, F. Zhu, H. Pei, Y . Yang, and W. Li, “Learning memory-augmented unidirectional metrics for cross-modality person re- IEEE TRANSACTIONS ON IMAGE PROCESSING 16 identification,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2022, pp. 19366–19375
work page 2022
-
[75]
H. Lu, X. Zou, and P. Zhang, “Learning progressive modality-shared transformers for effective visible-infrared person re-identification,”Proc. AAAI Conf. Artif. Intell. (AAAI), 2023, pp. 1835–1843
work page 2023
-
[76]
J. Shi, Y . Zhang, X. Yin, Y . Xie, Z. Zhang, J. Fan, Z. Shi, and Y . Qu, “Dual pseudo-labels interactive self-training for semi-supervised visible- infrared person re-identification,” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2023, pp. 11218–11228
work page 2023
-
[77]
The casia nir-vis 2.0 face database,
S. Z. Li, D. Yi, Z. Lei, and S. Liao, “The casia nir-vis 2.0 face database,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), June. 2013, pp. 348–353
work page 2013
-
[78]
Rgb-infrared cross- modality person re-identification,
A. Wu, W.-S. Zheng, H.-X. Yu, S. Gong, and J. Lai, “Rgb-infrared cross- modality person re-identification,” inProc. IEEE Int. Conf. Compute. Vis. (ICCV), Oct. 2017, pp. 5380–5389
work page 2017
-
[79]
Visualizing deep similarity networks,
A. Stylianou, R. Souvenir, and R. Pless, “Visualizing deep similarity networks,” inProc. Winter. Appl. Comput. Vis. (WACV), Jun, 2019, pp. 2029–2037
work page 2019
-
[80]
Simswap: An efficient framework for high fidelity face swapping,
R. Chen, X. Chen, B. Ni, and Y . Ge, “Simswap: An efficient framework for high fidelity face swapping,” inProc. ACM Int. Conf. Multime- dia(ACM MM), Oct, 2020, pp. 2003–2011. APPENDIX A. Implementation Details of the Compared Methods
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.