AIM: Adversarial Information Masking for Faithfulness Evaluation of Saliency Maps
Pith reviewed 2026-05-19 20:20 UTC · model grok-4.3
pith:NQZJRTWS Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{NQZJRTWS}
Prints a linked pith:NQZJRTWS badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
AIM uses adversarial feature replacement to evaluate saliency map faithfulness with less masking bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AIM replaces selected features with values from an adversarial counterpart of the input and compares degradation under complementary masking orders, yielding lower random-attribution bias and more stable faithfulness rankings than zero or interpolation masking while revealing modality-dependent differences between signed and unsigned attributions.
What carries the argument
Adversarial Information Masking (AIM), a saliency-guided framework that performs feature replacement using an adversarial counterpart of the input to isolate the effect of the saliency ordering from masking artifacts.
If this is right
- Random-attribution bias drops compared with zero and interpolation masking across the tested modalities.
- Rankings of explanation methods by faithfulness become more stable under the new evaluation.
- Signed and unsigned attributions show different reliability patterns that vary by image, audio, or EEG data.
- The method supplies a concrete way to check both saliency-map quality and masking-operator reliability in one procedure.
Where Pith is reading between the lines
- Teams working on safety-critical models could adopt AIM to decide which saliency technique to deploy for a given data type.
- The same adversarial-replacement idea might be tested on other post-hoc interpretation tools such as concept activation vectors.
- Generating the adversarial counterpart without task-specific tuning would make the approach easier to apply across new domains.
Load-bearing premise
An adversarial counterpart of the input can be generated so that replacing the chosen features removes predictive information without introducing new confounding artifacts or residual signals.
What would settle it
A controlled test in which AIM-masked inputs still produce large performance changes that cannot be attributed to the saliency order, or in which the adversarial replacement visibly reintroduces predictive information detectable by the model.
Figures


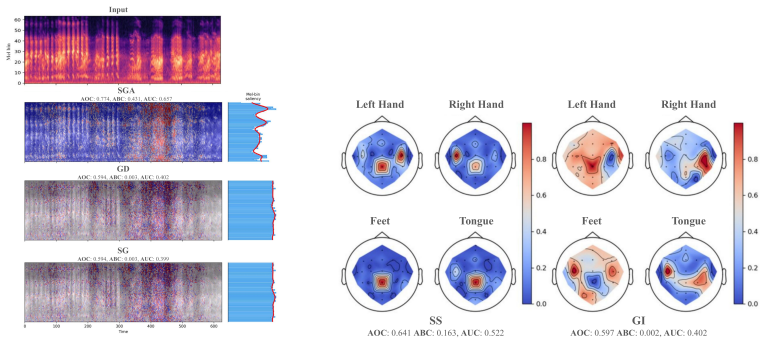
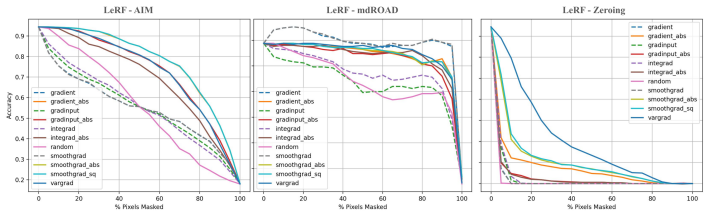
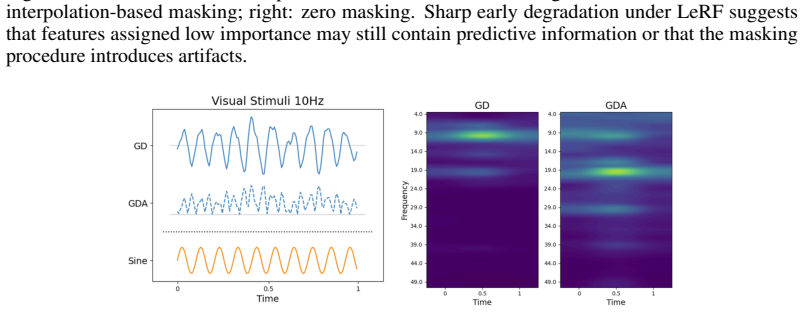
read the original abstract
Post-hoc saliency methods are widely used to interpret deep neural networks, but their faithfulness is difficult to evaluate reliably. Existing evaluations mask features according to saliency-induced feature ordering and measure performance degradation, but this degradation can be confounded by the masking operator: zero masking may create out-of-distribution artifacts, while interpolation-based masking may preserve residual predictive information. We propose Adversarial Information Masking (AIM), a saliency-guided adversarial feature replacement framework for evaluating both saliency-map faithfulness and masking-operator reliability. AIM replaces selected features with values from an adversarial counterpart of the input and compares degradation under complementary masking orders. We assess reliability using random-attribution bias and stability of explanation-method faithfulness rankings. Experiments on image, audio, and EEG tasks suggest that AIM reduces masking-induced bias compared with zero and interpolation-based masking, while revealing modality-dependent differences between signed and unsigned attributions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adversarial Information Masking (AIM), a saliency-guided framework that replaces selected input features with values drawn from an adversarially generated counterpart to evaluate post-hoc saliency map faithfulness. It contrasts performance degradation under complementary masking orders against zero-masking and interpolation baselines, measuring reliability via random-attribution bias and stability of explanation-method rankings. Experiments on image, audio, and EEG tasks are reported to show reduced masking-induced bias and modality-dependent differences between signed and unsigned attributions.
Significance. If the central claim holds, AIM would address a recognized weakness in faithfulness evaluation by providing a masking operator that more cleanly isolates the removal of predictive information. The multi-modal scope is a positive feature that could reveal domain-specific behaviors of saliency methods. The work would be of moderate significance to the interpretability community provided the adversarial replacement step is shown to avoid residual signals or new artifacts.
major comments (2)
- [Method] The generation procedure for the adversarial counterpart (optimization target, constraints, and stopping criteria) is described at a high level only. This is load-bearing for the central claim because any leakage of predictive information or introduction of confounding artifacts would render the reported reduction in random-attribution bias and the stability comparisons inconclusive relative to the zero and interpolation baselines.
- [Experiments] No quantitative results, error bars, dataset sizes, or statistical tests are supplied in the abstract or summary of experiments. Without these details it is impossible to judge the magnitude or reliability of the claimed bias reduction and ranking stability across the three modalities.
minor comments (2)
- [Method] Clarify the precise definition of 'complementary masking orders' and how they are constructed for each modality.
- The distinction between signed and unsigned attributions should be formalized with explicit notation or equations to avoid ambiguity when discussing modality-dependent differences.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We respond to each major comment in turn and describe the changes we will make to the manuscript.
read point-by-point responses
-
Referee: [Method] The generation procedure for the adversarial counterpart (optimization target, constraints, and stopping criteria) is described at a high level only. This is load-bearing for the central claim because any leakage of predictive information or introduction of confounding artifacts would render the reported reduction in random-attribution bias and the stability comparisons inconclusive relative to the zero and interpolation baselines.
Authors: We concur that the adversarial counterpart generation is described at a high level in the current version. Since this is central to validating the reduction in bias, we will revise the method description to include full details on the optimization target, constraints, and stopping criteria. This will allow readers to assess potential issues with leakage or artifacts more thoroughly. revision: yes
-
Referee: [Experiments] No quantitative results, error bars, dataset sizes, or statistical tests are supplied in the abstract or summary of experiments. Without these details it is impossible to judge the magnitude or reliability of the claimed bias reduction and ranking stability across the three modalities.
Authors: The referee correctly notes the absence of quantitative details in the abstract and experiment summary. We will update these sections in the revised manuscript to include representative quantitative results, error bars, dataset sizes, and information on statistical tests supporting the bias reduction and stability claims. revision: yes
Circularity Check
No circularity in AIM derivation; new masking operator and evaluation are independent of inputs
full rationale
The paper introduces Adversarial Information Masking (AIM) to address confounding in existing saliency faithfulness evaluations by replacing masked features with values from an adversarially generated counterpart input. This is presented as a novel framework compared against zero and interpolation baselines, with reliability assessed via random-attribution bias and ranking stability across image, audio, and EEG experiments. No derivation step reduces by construction to a fitted parameter, self-definition, or load-bearing self-citation; the central proposal and empirical claims rest on the explicit design of the replacement operator and direct task evaluations rather than presupposing outcomes from prior fitted results or renamed patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Visualizing and understanding convolutional networks
Matthew D Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In European Conference on Computer Vision (ECCV), pages 818–833. Springer, 2014
work page 2014
-
[2]
Wojciech Samek, Alexander Binder, Gregoire Montavon, Sebastian Lapuschkin, and Klaus- Robert Muller. Evaluating the visualization of what a deep neural network has learned.IEEE Transactions on Neural Networks and Learning Systems, 28(11):2660–2673, 2016
work page 2016
-
[3]
A unified approach to interpreting model predictions
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[4]
Towards better understanding of gradient-based attribution methods for Deep Neural Networks
Marco Ancona, Enea Ceolini, Cengiz Oztireli, and Markus Gross. Towards better under- standing of gradient-based attribution methods for deep neural networks.arXiv preprint arXiv:1711.06104, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Bryce Goodman and Seth Flaxman. European union regulations on algorithmic decision-making and a “right to explanation”.AI Magazine, 38(3):50–57, 2017
work page 2017
-
[6]
Debugging machine learning models
Gabriel Cadamuro, Ran Gilad-Bachrach, and Xiaojin Zhu. Debugging machine learning models. InICML Workshop on Reliable Machine Learning in the Wild, volume 103, 2016
work page 2016
-
[7]
Debugging tests for model explanations.arXiv preprint arXiv:2011.05429, 2020
Julius Adebayo, Michael Muelly, Ilaria Liccardi, and Been Kim. Debugging tests for model explanations.arXiv preprint arXiv:2011.05429, 2020
-
[8]
Learning important features through propagating activation differences
Avanti Shrikumar, Peyton Greenside, and Anshul Kundaje. Learning important features through propagating activation differences. InInternational Conference on Machine Learning, pages 3145–3153. PMLR, 2017
work page 2017
-
[9]
Post hoc explanations may be ineffective for detecting unknown spurious correlation
Julius Adebayo, Michael Muelly, Harold Abelson, and Been Kim. Post hoc explanations may be ineffective for detecting unknown spurious correlation. InInternational Conference on Learning Representations, 2022
work page 2022
-
[10]
Deep learning-based electroencephalography analysis: a systematic review
Yannick Roy, Hubert Banville, Isabela Albuquerque, Alexandre Gramfort, Tiago H Falk, and Jocelyn Faubert. Deep learning-based electroencephalography analysis: a systematic review. Journal of Neural Engineering, 16(5):051001, 2019
work page 2019
-
[11]
Erico Tjoa and Cuntai Guan. A survey on explainable artificial intelligence (xai): Toward medical xai.IEEE Transactions on Neural Networks and Learning Systems, 32(11):4793–4813, 2020
work page 2020
-
[12]
Matt: A manifold attention network for eeg decoding
Yue-Ting Pan, Jing-Lun Chou, and Chun-Shu Wei. Matt: A manifold attention network for eeg decoding. InAdvances in Neural Information Processing Systems, volume 35, pages 31116–31129, 2022
work page 2022
-
[13]
Blair Bilodeau, Natasha Jaques, Pang Wei Koh, and Been Kim. Impossibility theorems for feature attribution.Proceedings of the National Academy of Sciences, 121(2):e2304406120, 2024
work page 2024
-
[14]
Harshay Shah, Prateek Jain, and Praneeth Netrapalli. Do input gradients highlight discriminative features? InAdvances in Neural Information Processing Systems, volume 34, pages 2046–2059, 2021
work page 2046
-
[15]
On the (in)fidelity and sensitivity of explanations
Chih-Kuan Yeh, Cheng-Yu Hsieh, Arun Suggala, David I Inouye, and Pradeep K Ravikumar. On the (in)fidelity and sensitivity of explanations. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[16]
Cheng-Yu Hsieh, Chih-Kuan Yeh, Xuanqing Liu, Pradeep Ravikumar, Seungyeon Kim, Sanjiv Kumar, and Cho-Jui Hsieh. Evaluations and methods for explanation through robustness analysis.arXiv preprint arXiv:2006.00442, 2020
-
[17]
Evaluating post-hoc explanations for graph neural networks via robustness analysis
Junfeng Fang, Wei Liu, Yuan Gao, Zemin Liu, An Zhang, Xiang Wang, and Xiangnan He. Evaluating post-hoc explanations for graph neural networks via robustness analysis. InAdvances in Neural Information Processing Systems, volume 36, 2024. 10
work page 2024
-
[18]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. In International Conference on Machine Learning, pages 3319–3328. PMLR, 2017
work page 2017
-
[19]
The (un)reliability of saliency methods
Pieter-Jan Kindermans, Sara Hooker, Julius Adebayo, Maximilian Alber, Kristof T Schütt, Sven Dähne, Dumitru Erhan, and Been Kim. The (un)reliability of saliency methods. InExplainable AI: Interpreting, Explaining and Visualizing Deep Learning, pages 267–280. Springer, 2019
work page 2019
-
[20]
Sanity checks for saliency maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, and Been Kim. Sanity checks for saliency maps. InAdvances in Neural Information Processing Systems, volume 31, 2018
work page 2018
-
[21]
Akshay Sujatha Ravindran and Jose Contreras-Vidal. An empirical comparison of deep learning explainability approaches for eeg using simulated ground truth.Scientific Reports, 13(1):17709, 2023
work page 2023
-
[22]
Real time image saliency for black box classifiers
Piotr Dabkowski and Yarin Gal. Real time image saliency for black box classifiers. InAdvances in Neural Information Processing Systems, volume 30, 2017
work page 2017
-
[23]
Evaluating feature importance estimates.arXiv preprint arXiv:1806.10758, 2018
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. Evaluating feature importance estimates.arXiv preprint arXiv:1806.10758, 2018
-
[24]
Yao Rong, Tobias Leemann, Vadim Borisov, Gjergji Kasneci, and Enkelejda Kasneci. A consis- tent and efficient evaluation strategy for attribution methods.arXiv preprint arXiv:2202.00449, 2022
-
[25]
Sanity checks for saliency metrics
Richard Tomsett, Dan Harborne, Supriyo Chakraborty, Prudhvi Gurram, and Alun Preece. Sanity checks for saliency metrics. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 6021–6029, 2020
work page 2020
-
[26]
Lennart Brocki and Neo Christopher Chung. Fidelity of interpretability methods and perturba- tion artifacts in neural networks.arXiv preprint arXiv:2203.02928, 2022
-
[27]
Geometric remove-and-retrain (goar): Coordinate-invariant explainable ai assessment
Yong-Hyun Park, Junghoon Seo, Bomseok Park, Seongsu Lee, and Junghyo Jo. Geometric remove-and-retrain (goar): Coordinate-invariant explainable ai assessment. InXAI in Action: Past, Present, and Future Applications. Springer, 2023
work page 2023
-
[28]
Hugues Turbé, Mina Bjelogrlic, Christian Lovis, and Gianmarco Mengaldo. Evaluation of post-hoc interpretability methods in time-series classification.Nature Machine Intelligence, 5 (3):250–260, 2023
work page 2023
-
[29]
Explaining and Harnessing Adversarial Examples
Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversar- ial examples.arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
Xiao Zhang and Dongrui Wu. On the vulnerability of cnn classifiers in eeg-based bcis.IEEE Transactions on Neural Systems and Rehabilitation Engineering, 27(5):814–825, 2019
work page 2019
-
[31]
Laura Nieradzik, Heike Stephani, and Jan Keuper. Reliable evaluation of attribution maps in cnns: A perturbation-based approach.International Journal of Computer Vision, 133: 2392–2409, 2025. doi: 10.1007/s11263-024-02282-6
-
[32]
Toward the applica- tion of xai methods in eeg-based systems.arXiv preprint arXiv:2210.06554, 2022
Andrea Apicella, Francesco Isgrò, Andrea Pollastro, and Roberto Prevete. Toward the applica- tion of xai methods in eeg-based systems.arXiv preprint arXiv:2210.06554, 2022
-
[33]
Jian Cui, Liqiang Yuan, Zhaoxiang Wang, Ruilin Li, and Tianzi Jiang. Towards best practice of interpreting deep learning models for eeg-based brain computer interfaces.Frontiers in Computational Neuroscience, 17:1232925, 2023
work page 2023
-
[34]
Juan Manuel Mayor Torres, Sara Medina-DeVilliers, Tessa Clarkson, Matthew D Lerner, and Giuseppe Riccardi. Evaluation of interpretability for deep learning algorithms in eeg emotion recognition: A case study in autism.Artificial Intelligence in Medicine, 143:102545, 2023
work page 2023
-
[35]
Journal of the Franklin Institute , year =
Sören Becker, Johanna Vielhaben, Marcel Ackermann, Klaus-Robert Müller, Sebastian La- puschkin, and Wojciech Samek. Audiomnist: Exploring explainable artificial intelligence for audio analysis on a simple benchmark.Journal of the Franklin Institute, 361(1):418–428, 2024. doi: 10.1016/j.jfranklin.2023.11.038. 11
-
[36]
Metrics for saliency map evaluation of deep learning explanation methods, 2022
Thibault Gomez, Thomas Fréour, and Harold Mouchère. Metrics for saliency map evaluation of deep learning explanation methods, 2022
work page 2022
-
[37]
Mykyta Skliarov, Radwa El Shawi, Chedia Dhaoui, et al. A comparative evaluation of explainability techniques for image data.Scientific Reports, 15:41898, 2025. doi: 10.1038/s41598-025-25839-y
-
[38]
F-fidelity: A robust framework for faithfulness evaluation of explainable ai
Xu Zheng, Farhad Shirani, Zhuomin Chen, Chaohao Lin, Wei Cheng, Wenbo Guo, and Dong- sheng Luo. F-fidelity: A robust framework for faithfulness evaluation of explainable ai. In International Conference on Learning Representations, 2025. Poster
work page 2025
-
[39]
Avinash Kumar Singh, Guillermo Sahonero-Alvarez, Mufti Mahmud, and Luigi Bianchi. To- wards bridging the gap between computational intelligence and neuroscience in brain-computer interfaces.Frontiers in Neuroinformatics, 15:699840, 2021
work page 2021
-
[40]
Param Rajpura, Hubert Cecotti, and Yogesh Kumar Meena. Explainable artificial intelligence approaches for brain-computer interfaces: A review and design space.Journal of Neural Engineering, 2024
work page 2024
-
[41]
Towards Deep Learning Models Resistant to Adversarial Attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks.arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
A benchmark for inter- pretability methods in deep neural networks
Sara Hooker, Dumitru Erhan, Pieter-Jan Kindermans, and Been Kim. A benchmark for inter- pretability methods in deep neural networks. InNeurIPS, 2019
work page 2019
-
[43]
Towards robust evaluation of explainable artificial intelligence methods
Andrea Apicella et al. Towards robust evaluation of explainable artificial intelligence methods. Pattern Recognition Letters, 2022
work page 2022
-
[44]
On the evaluation of saliency methods
Lukasz Brocki and Ngan Chung. On the evaluation of saliency methods. InICLR Workshop, 2022
work page 2022
-
[45]
Explaining deep learning models: A comprehensive survey.IEEE Transac- tions, 2023
Zhiyong Cui et al. Explaining deep learning models: A comprehensive survey.IEEE Transac- tions, 2023
work page 2023
-
[46]
Clemens Brunner, Robert Leeb, Gernot R Müller-Putz, Alois Schlögl, and Gert Pfurtscheller. Bci competition 2008–graz data set a.Institute for Knowledge Discovery (Laboratory of Brain-Computer Interfaces), Graz University of Technology, 2008
work page 2008
-
[47]
Bci challenge: Event-related negativity dataset, 2014
Jérémie Mattout and K Kan. Bci challenge: Event-related negativity dataset, 2014. URL https://www.kaggle.com/c/inria-bci-challenge. Kaggle dataset
work page 2014
-
[48]
Victor Martinez-Cagigal, Enrique Santamaria-Vazquez, and Roberto Hornero. A multi-modal dataset for steady-state visual evoked potential-based brain-computer interfaces.MAMEM SSVEP Dataset, 2007
work page 2007
-
[49]
Karol J. Piczak. Esc: Dataset for environmental sound classification. InACM Multimedia, 2015
work page 2015
- [50]
-
[51]
Parkhi, Andrea Vedaldi, and Andrew Zisserman
Omkar M. Parkhi, Andrea Vedaldi, and Andrew Zisserman. Cats and dogs. InCVPR, 2012
work page 2012
-
[52]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2009
work page 2009
-
[53]
S. Bhuvaji, A. Kadam, P. Bhumkar, and S. Dedge. Brain tumor classification (mri). Kaggle, 2020
work page 2020
-
[54]
Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. InarXiv preprint arXiv:1312.6034, 2013. 12
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[55]
SmoothGrad: removing noise by adding noise
Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda Viégas, and Martin Wattenberg. Smooth- grad: removing noise by adding noise. InarXiv preprint arXiv:1706.03825, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[56]
Sebastian Bach et al. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation.PLOS ONE, 2015
work page 2015
-
[57]
Towards better understanding of gradient-based attribution methods
Marco Ancona et al. Towards better understanding of gradient-based attribution methods. In ICLR, 2018
work page 2018
-
[58]
Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. InICCV, 2017
work page 2017
-
[59]
Grad-cam++: Improved visual explanations for deep convolutional networks
Aditya Chattopadhyay et al. Grad-cam++: Improved visual explanations for deep convolutional networks. InWACV, 2018
work page 2018
-
[60]
Score-cam: Score-weighted visual explanations for convolutional neural net- works
Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-cam: Score-weighted visual explanations for convolutional neural net- works. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 111–119, 2020. doi: 10.1109/CVPRW50498.2020.00020
-
[61]
Daniel Omeiza, Skyler Speakman, Celia Cintas, and Komminist Weldermariam. Smooth grad- cam++: An enhanced inference level visualization technique for deep convolutional neural network models.arXiv preprint arXiv:1908.01224, 2019
-
[62]
Gert Pfurtscheller, Clemens Brunner, Alois Schlögl, and F. H. Lopes da Silva. Mu rhythm (de)synchronization and eeg single-trial classification of different motor imagery tasks.Neu- roImage, 31(1):153–159, 2006
work page 2006
-
[63]
TIMING: Temporality-aware integrated gradients for time series explanation
Hyeongwon Jang, Changhun Kim, and Eunho Yang. TIMING: Temporality-aware integrated gradients for time series explanation. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=qOgKMqv9T7
work page 2025
-
[64]
Robust learning from corrupted eeg with self-supervised learning.NeuroImage, 251: 118994, 2022
Hubert Banville, Omar Chehab, Aapo Hyvarinen, Denis-Alexandre Engemann, and Alexandre Gramfort. Robust learning from corrupted eeg with self-supervised learning.NeuroImage, 251: 118994, 2022
work page 2022
-
[65]
Stephan Leske and Sarang S. Dalal. Reducing power line noise in eeg and meg data via spectrum interpolation.NeuroImage, 189:763–776, 2019
work page 2019
-
[66]
Biyu J. He. Scale-free brain activity: past, present, and future.Trends in Cognitive Sciences, 18 (9):480–487, 2014
work page 2014
-
[67]
Thomas Donoghue, Matthijs Haller, Erik J Peterson, Paroma Varma, Padraig Sebastian, Ruijie Gao, Takashi Noto, Antonio H Lara, Jonathan D Wallis, Robert T Knight, et al. Parameterizing neural power spectra into periodic and aperiodic components.Nature Neuroscience, 23(12): 1655–1665, 2020
work page 2020
-
[68]
Multipoint fractional brownian bridge: construction and applications
Tobias Friedrich and et al. Multipoint fractional brownian bridge: construction and applications. Stochastic Processes and their Applications, 2020
work page 2020
-
[69]
Jan Beran.Long-memory processes: probabilistic properties and statistical methods. Springer, 2013
work page 2013
-
[70]
N. Kannathal and et al. Analysis of eeg signals using fractal dimension.Biomedical Signal Processing and Control, 2005
work page 2005
-
[71]
Benoit B. Mandelbrot and John W. Van Ness. Fractional brownian motions, fractional noises and applications.SIAM Review, 10(4):422–437, 1968
work page 1968
-
[72]
Robert B. Davies and D. S. Harte. Tests for hurst effect.Biometrika, 74(1):95–101, 1987
work page 1987
-
[73]
Simulation of fractional brownian motion.Master’s thesis, University of Twente, 2004
Ton Dieker. Simulation of fractional brownian motion.Master’s thesis, University of Twente, 2004. 13
work page 2004
-
[74]
Vernon J. Lawhern and et al. Eegnet: A compact convolutional neural network for eeg-based bcis.Journal of Neural Engineering, 2018
work page 2018
-
[75]
Spatial component-wise convolutional network (sccnet) for motor-imagery eeg classification
Chun-Shu Wei, Toshiaki Koike-Akino, and Ye Wang. Spatial component-wise convolutional network (sccnet) for motor-imagery eeg classification. InProceedings of the 9th International IEEE/EMBS Conference on Neural Engineering (NER), pages 328–331. IEEE, 2019
work page 2019
-
[76]
Interpretable cnn for eeg.IEEE TBME, 2022
Zhiyuan Cui and et al. Interpretable cnn for eeg.IEEE TBME, 2022. A Appendix A.1 Compute Resources All experiments were conducted on GPU-based workstations. The main experiments were run using NVIDIA RTX 4090 GPUs with CUDA acceleration. For each dataset–model–masking configuration, we generated post-hoc saliency maps, constructed MoRF and LeRF masking or...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.