CAST: Causal Anchored Simplex Transport for Distribution-Valued Time Series
Pith reviewed 2026-05-19 19:32 UTC · model grok-4.3
pith:2ABKKND4 Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{2ABKKND4}
Prints a linked pith:2ABKKND4 badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
CAST uses causal context to retrieve non-aliased successors then anchors and transports them on the simplex to forecast distribution time series.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
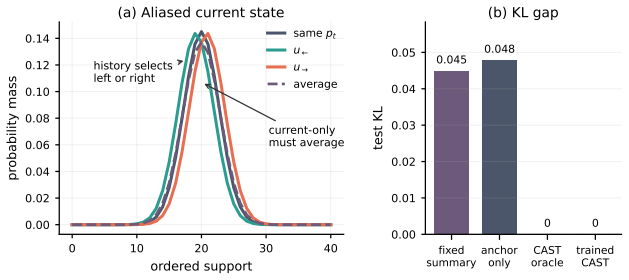
CAST is a successor-local operator that retrieves empirical successors from causal context, stabilizes them with a persistence anchor, and applies a bounded local stochastic transport on ordered supports; every stage preserves the simplex by construction. The operator class contains the regime-aware Bayes successor. For ordered supports an additional Pinsker separation holds whenever the transported successor lies outside the no-transport anchor hull. Any forecaster depending only on an aliased summary incurs an irreducible weighted Jensen-Shannon excess-risk lower bound.
What carries the argument
The Causal Anchored Simplex Transport operator, which retrieves empirical successors from causal context, stabilizes them via persistence anchoring, and performs bounded stochastic transport on ordered supports to produce simplex-preserving forecasts.
If this is right
- Any forecaster relying solely on an aliased summary of the current distribution incurs a positive weighted Jensen-Shannon excess-risk lower bound.
- The CAST hypothesis class contains the regime-aware Bayes successor for the underlying transition kernels.
- When supports are ordered, an extra Pinsker separation bound applies to transported points lying outside the no-transport anchor hull.
- Component ablations and synthetic aliasing tests isolate the contribution of causal retrieval and anchoring to the observed gains.
- The method applies directly to compositional data arising in ecology, energy, mobility, and queueing systems.
Where Pith is reading between the lines
- Data pipelines for distribution-valued series should prioritize collection of causal context variables to enable disambiguation of regimes.
- Domains with naturally ordered supports, such as severity profiles or occupancy fractions, are likely to see the largest benefit from the transport stage.
- The aliasing lower bound supplies a diagnostic: persistent high error on identical distributions may indicate hidden regime structure that context-aware methods can exploit.
- Adaptive tuning of anchor strength or transport radius from data could further reduce the gap to the Bayes successor in non-stationary settings.
Load-bearing premise
Causal context must suffice to retrieve non-aliased empirical successors and supports must be ordered so that Pinsker separation holds when the transported successor falls outside the no-transport anchor hull.
What would settle it
A controlled experiment with deliberately aliased transitions in which a forecaster given only the current distribution exhibits the predicted weighted Jensen-Shannon excess risk while CAST does not.
Figures





read the original abstract
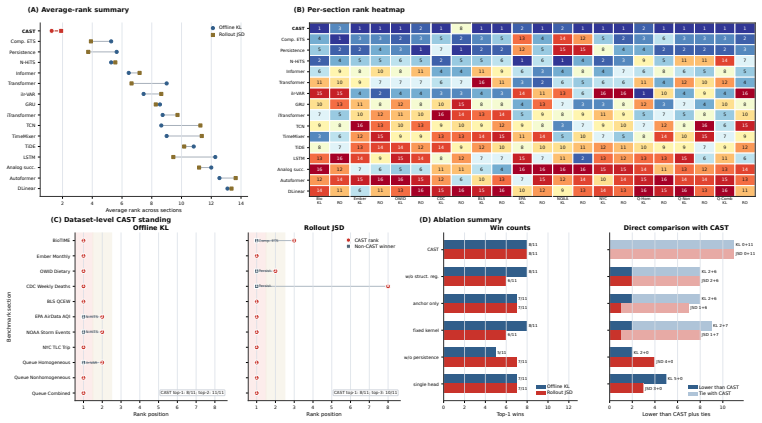
Many decision-facing stochastic systems are observed through aggregate distributions rather than scalar trajectories: queue occupancies, mobility shares, public-health mixtures, generation-source shares, ecological compositions, and air-quality severity profiles all live on the probability simplex and evolve over time. We study causal (online) forecasting for these distribution-valued time series and argue that the transition operator itself should be structured around the simplex. We introduce CAST (Causal Anchored Simplex Transport), a successor-local operator that (i) retrieves empirical successors from causal context, (ii) stabilizes them with a persistence anchor, and (iii) applies a bounded local stochastic transport on ordered supports; every stage preserves the simplex by construction. We identify a structural failure mode, latent transition-kernel aliasing, where similar observed distributions evolve differently under different contextual regimes, and prove that any forecaster depending only on an aliased summary incurs an irreducible weighted Jensen-Shannon excess-risk lower bound, while the CAST hypothesis class contains the regime-aware Bayes successor; for ordered supports an additional Pinsker separation holds whenever the transported successor lies outside the no-transport anchor hull. On eleven public and simulated benchmarks spanning ecology, energy, diet, mortality, employment, air quality, severe weather, mobility, and G/G/1, G_t/G/1 queue occupancy, CAST attains the best average rank on both one-step KL (1.27) and autoregressive rollout JSD (1.91), winning 8/11 sections on each metric against a broad statistical, compositional, recurrent, convolutional, and Transformer baseline set, and top-2 on all 11 sections for offline KL. Component ablations and a controlled synthetic aliasing experiment corroborate the theory.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAST (Causal Anchored Simplex Transport), a successor-local operator for causal online forecasting of distribution-valued time series on the probability simplex. It retrieves empirical successors from causal context, stabilizes them via a persistence anchor, and applies bounded local stochastic transport on ordered supports, with all stages preserving the simplex. The central theoretical claims are that latent transition-kernel aliasing incurs an irreducible weighted Jensen-Shannon excess-risk lower bound for any forecaster using only an aliased summary, while the CAST hypothesis class contains the regime-aware Bayes successor; for ordered supports an additional Pinsker separation holds when the transported successor lies outside the no-transport anchor hull. Empirically, CAST achieves the best average rank on one-step KL (1.27) and autoregressive rollout JSD (1.91), winning 8/11 sections on each metric across eleven benchmarks from ecology, energy, diet, mortality, employment, air quality, severe weather, mobility, and queueing systems, against statistical, compositional, recurrent, convolutional, and Transformer baselines.
Significance. If the theoretical guarantees hold and extend appropriately, the work provides a principled simplex-structured approach to distribution time series forecasting that explicitly addresses regime-dependent aliasing, a structural failure mode not commonly isolated in prior compositional or recurrent models. The explicit containment of the regime-aware Bayes successor and the derivation of an aliasing lower bound are notable strengths, as is the empirical demonstration of consistent top performance and component ablations on a diverse benchmark suite. These elements could influence forecasting practice in aggregate-data domains such as public health, mobility, and environmental monitoring, provided the ordered-support assumption is reconciled with the categorical benchmarks used.
major comments (2)
- [Abstract / Theoretical claims] Abstract and theoretical analysis: The aliasing lower-bound and Pinsker separation results are stated to require ordered supports ('for ordered supports an additional Pinsker separation holds whenever the transported successor lies outside the no-transport anchor hull'), yet the eleven benchmarks explicitly include unordered categorical distributions such as mobility shares, diet compositions, employment categories, and air-quality profiles. If the local stochastic transport step is applied without an explicit ordering (or with arbitrary ordering), the separation guarantee does not transfer, leaving the claim that CAST avoids the aliasing lower bound dependent on an unstated extension or solely on the empirical method. This gap is load-bearing for interpreting the theoretical contribution relative to the reported wins.
- [Empirical evaluation] Empirical evaluation section: The reported average ranks (KL 1.27, JSD 1.91) and win counts (8/11 sections) rest on eleven datasets whose selection criteria, preprocessing steps, handling of support ordering, and statistical significance testing are not detailed. Without these, it is difficult to assess whether the benchmark wins are robust to the unordered-support issue raised above or to variations in how causal context is retrieved.
minor comments (1)
- [Method definition] Notation for the persistence anchor and transport operator could be clarified with an explicit equation reference to show how simplex preservation is enforced at each stage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope of our theoretical results and the presentation of the empirical evaluation. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Theoretical claims] Abstract and theoretical analysis: The aliasing lower-bound and Pinsker separation results are stated to require ordered supports ('for ordered supports an additional Pinsker separation holds whenever the transported successor lies outside the no-transport anchor hull'), yet the eleven benchmarks explicitly include unordered categorical distributions such as mobility shares, diet compositions, employment categories, and air-quality profiles. If the local stochastic transport step is applied without an explicit ordering (or with arbitrary ordering), the separation guarantee does not transfer, leaving the claim that CAST avoids the aliasing lower bound dependent on an unstated extension or solely on the empirical method. This gap is load-bearing for interpreting the theoretical contribution relative to the reported wins.
Authors: We appreciate the referee pointing out this distinction. The core theoretical contributions—the weighted Jensen-Shannon excess-risk lower bound for aliased summaries and the containment of the regime-aware Bayes successor within the CAST hypothesis class—hold for general (possibly unordered) supports and do not rely on the ordered-support assumption. The additional Pinsker separation is explicitly qualified as holding only for ordered supports. For the categorical benchmarks, the local stochastic transport step is either bypassed or performed after imposing a fixed but arbitrary category ordering; performance improvements in those cases derive primarily from the empirical successor retrieval and persistence anchor. We will revise the abstract, theoretical section, and empirical discussion to separate the general results from the ordered-support extension and to document the handling of unordered supports, thereby clarifying that the aliasing-avoidance claim is not dependent on the Pinsker result. revision: partial
-
Referee: [Empirical evaluation] Empirical evaluation section: The reported average ranks (KL 1.27, JSD 1.91) and win counts (8/11 sections) rest on eleven datasets whose selection criteria, preprocessing steps, handling of support ordering, and statistical significance testing are not detailed. Without these, it is difficult to assess whether the benchmark wins are robust to the unordered-support issue raised above or to variations in how causal context is retrieved.
Authors: We agree that additional documentation is required for reproducibility and to address robustness concerns. In the revised manuscript we will expand the empirical evaluation section with: (i) explicit selection criteria and public sources for each of the eleven benchmarks, (ii) preprocessing details including support construction and ordering decisions (or lack thereof) for categorical versus ordered data, (iii) the precise procedure used to retrieve causal context windows, and (iv) statistical significance tests (paired Wilcoxon signed-rank tests with Holm correction) comparing CAST against baselines. A new paragraph will also discuss the application of CAST components to unordered supports. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines CAST as a successor-local operator with three explicit stages (retrieve empirical successors from causal context, stabilize with persistence anchor, apply bounded local stochastic transport on ordered supports) that preserve the simplex by construction. It proves an irreducible weighted JSD excess-risk lower bound for any forecaster depending only on an aliased summary and shows that the CAST hypothesis class contains the regime-aware Bayes successor. These steps are presented as independent mathematical results rather than reductions to fitted parameters or self-referential definitions. No equations in the provided abstract or description equate a claimed prediction to its own inputs by construction, and the empirical results on eleven benchmarks are reported separately from the theoretical containment claim. The ordered-support assumption for the additional Pinsker separation is an applicability condition, not a circularity in the derivation itself.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (Latent-kernel aliasing lower bound) … inf q ∑ πz KL(uz ∥ q) = JS_π(u1,…,uK) > 0
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
bounded local stochastic transport … on ordered supports; … Pinsker separation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Michael Mitzenmacher and Rana Shahout. Queueing, predictions, and large language models: Challenges and open problems.Stochastic Systems, 15(3):195–219, 2025. doi: 10.1287/stsy.2025.0106
-
[2]
New York City Taxi and Limousine Commission. TLC Trip Record Data. https://www.nyc.gov/ site/tlc/about/tlc-trip-record-data.page, 2025. Accessed 2026-05-05
work page 2025
-
[3]
John Aitchison. The statistical analysis of compositional data.Journal of the Royal Statistical Society: Series B (Methodological), 44(2):139–160, 1982. doi: 10.1111/j.2517-6161.1982.tb01195.x
-
[4]
Chapman and Hall, London, 1986
John Aitchison.The Statistical Analysis of Compositional Data. Chapman and Hall, London, 1986
work page 1986
- [5]
- [6]
-
[7]
doi: 10.1016/j.ijforecast.2016.11.008
-
[8]
Compositional V ARIMA time series
Carles Barceló-Vidal, Lucía Aguilar, and Josep Antoni Martín-Fernández. Compositional V ARIMA time series. InCompositional Data Analysis: Theory and Applications, pages 87–103. John Wiley & Sons,
-
[9]
doi: 10.1002/9781119976462.ch7
-
[10]
Chao Zhang, Piotr Kokoszka, and Alexander Petersen. Wasserstein autoregressive models for density time series.Journal of Time Series Analysis, 43(1):30–52, 2022. doi: 10.1111/jtsa.12590
-
[11]
Wasserstein multivariate auto-regressive models for modeling distributional time series, 2022
Yiye Jiang and Jérémie Bigot. Wasserstein multivariate auto-regressive models for modeling distributional time series, 2022
work page 2022
-
[12]
Bellemare, Will Dabney, and Rémi Munos
Marc G. Bellemare, Will Dabney, and Rémi Munos. A distributional perspective on reinforcement learning. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 449–458. PMLR, 2017
work page 2017
-
[13]
Xiaocheng Li, Huaiyang Zhong, and Margaret L. Brandeau. Quantile markov decision processes.Opera- tions Research, 70(3):1428–1447, 2022. doi: 10.1287/opre.2021.2123
-
[14]
Risk-sensitive and robust decision-making: A CVaR optimization approach
Yinlam Chow, Aviv Tamar, Shie Mannor, and Marco Pavone. Risk-sensitive and robust decision-making: A CVaR optimization approach. InAdvances in Neural Information Processing Systems, volume 28, pages 1522–1530, 2015
work page 2015
-
[15]
Distributionally robust convex optimization
Wolfram Wiesemann, Daniel Kuhn, and Melvyn Sim. Distributionally robust convex optimization. Operations Research, 62(6):1358–1376, 2014. doi: 10.1287/opre.2014.1314
-
[16]
D. V . Lindley. The theory of queues with a single server.Mathematical Proceedings of the Cambridge Philosophical Society, 48(2):277–289, 1952. doi: 10.1017/S0305004100027638
-
[17]
Cambridge University Press, 2013
Mor Harchol-Balter.Performance Modeling and Design of Computer Systems: Queueing Theory in Action. Cambridge University Press, 2013
work page 2013
-
[18]
Sergio Palomo and Jamol Pender. Learning lindley’s recursion. InProceedings of the 2020 Winter Simulation Conference, pages 644–655, 2020. doi: 10.1109/WSC48552.2020.9384121
-
[19]
Transformer-based next-step prediction for queue length distribution
Jieqi Di, Jiecheng Lu, Runhua Wu, and Yuwei Zhou. Transformer-based next-step prediction for queue length distribution. InNeurIPS 2025 Workshop on Mathematical Foundations and Operational Integration of Machine Learning for Uncertainty-Aware Decision-Making, 2025. URL https://openreview.net/ forum?id=ErSFgi45jD. Published on OpenReview
work page 2025
-
[20]
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. DeepAR: Probabilistic forecasting with autoregressive recurrent networks.International Journal of Forecasting, 36(3):1181–1191, 2020. doi: 10.1016/j.ijforecast.2019.07.001. 10
-
[21]
Arik, Nicolas Loeff, and Tomas Pfister
Bryan Lim, Sercan O. Arik, Nicolas Loeff, and Tomas Pfister. Temporal fusion transformers for inter- pretable multi-horizon time series forecasting.International Journal of Forecasting, 37(4):1748–1764,
-
[22]
doi: 10.1016/j.ijforecast.2021.03.012
-
[23]
Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio
Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. InInternational Conference on Learning Representations, 2020
work page 2020
-
[25]
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11106–11115, 2021. doi: 10.1609/aaai. v35i12.17325
-
[26]
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. InAdvances in Neural Information Processing Systems, volume 34, pages 22419–22430, 2021
work page 2021
-
[27]
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. InProceedings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 27268–27286. PMLR, 2022
work page 2022
-
[28]
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 11121–11128, 2023. doi: 10.1609/aaai.v37i9.26317
-
[29]
Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam
Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InInternational Conference on Learning Representations, 2023
work page 2023
-
[30]
TimesNet: Tem- poral 2d-variation modeling for general time series analysis
Haixu Wu, Tengge Hu, Yong Liu, Hang Zhou, Jianmin Wang, and Mingsheng Long. TimesNet: Tem- poral 2d-variation modeling for general time series analysis. InInternational Conference on Learning Representations, 2023
work page 2023
-
[31]
Yunhao Zhang and Junchi Yan. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting. InInternational Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=vSVLM2j9eie
work page 2023
-
[32]
Abhimanyu Das, Weihao Kong, Andrew Leach, Shaan Mathur, Rajat Sen, and Rose Yu. Long-term forecasting with TiDE: Time-series dense encoder.Transactions on Machine Learning Research, 2023. URLhttps://openreview.net/forum?id=pCbC3aQB5W
work page 2023
-
[33]
Si-An Chen, Chun-Liang Li, Nathanael C. Yoder, Sercan O. Arik, and Tomas Pfister. TSMixer: An all-MLP architecture for time series forecasting.Transactions on Machine Learning Research, 2023. URL https://openreview.net/forum?id=wbpxTuXgm0
work page 2023
-
[34]
ARM: Refining multivariate forecasting with adaptive temporal- contextual learning
Jiecheng Lu, Xu Han, and Shihao Yang. ARM: Refining multivariate forecasting with adaptive temporal- contextual learning. InInternational Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=JWpwDdVbaM
work page 2024
-
[35]
iTrans- former: Inverted transformers are effective for time series forecasting
Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, and Mingsheng Long. iTrans- former: Inverted transformers are effective for time series forecasting. InInternational Conference on Learning Representations, 2024
work page 2024
-
[36]
TimeXer: Empowering transformers for time series forecasting with exogenous variables
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Guo Qin, Haoran Zhang, Yong Liu, Yunzhong Qiu, Jianmin Wang, and Mingsheng Long. TimeXer: Empowering transformers for time series forecasting with exogenous variables. InAdvances in Neural Information Processing Systems, volume 37, 2024. URL https://openreview.net/forum?id=l3MOy7AydX
work page 2024
-
[37]
Jiecheng Lu, Xu Han, Yan Sun, and Shihao Yang. CATS: Enhancing multivariate time series forecasting by constructing auxiliary time series as exogenous variables. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research. PMLR,
-
[38]
URLhttps://openreview.net/forum?id=1lDAGDe0UR. 11
-
[39]
TimeMixer: Decomposable multiscale mixing for time series forecasting
Shiyu Wang, Haixu Wu, Xiaoming Shi, Tengge Hu, Huakun Luo, Lintao Ma, James Zhang, and Jun Zhou. TimeMixer: Decomposable multiscale mixing for time series forecasting. InInternational Conference on Learning Representations, 2024
work page 2024
-
[40]
W A VE: Weighted autoregressive varying gate for time series forecasting
Jiecheng Lu, Xu Han, Yan Sun, and Shihao Yang. W A VE: Weighted autoregressive varying gate for time series forecasting. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research. PMLR, 2025. URL https://openreview.net/forum? id=Qqn5ktBUxH
work page 2025
-
[41]
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Türkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, Jasper Zschiegner, Danielle C. Maddix, Hao Wang, Michael W. Mahoney, Kari Torkkola, Andrew Gordon Wilson, Michael Bohlke-Schneider, and Yuyang Wang. Chronos: Learning the langu...
work page 2024
-
[42]
HyperMLP: An integrated perspective for sequence modeling, 2026
Jiecheng Lu and Shihao Yang. HyperMLP: An integrated perspective for sequence modeling, 2026
work page 2026
-
[43]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research. PMLR, 2024
work page 2024
-
[44]
StretchTime: Adaptive time series forecasting via symplectic attention, 2026
Yubin Kim, Viresh Pati, Jevon Twitty, Vinh Pham, Shihao Yang, and Jiecheng Lu. StretchTime: Adaptive time series forecasting via symplectic attention, 2026
work page 2026
-
[45]
Ziyue Wang and Yuko Araki. Functional time series forecasting of distributions: A koopman-wasserstein approach.Behaviormetrika, 2025. doi: 10.1007/s41237-025-00278-1
-
[46]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems, volume 26, pages 2292–2300, 2013
work page 2013
-
[47]
Computational optimal transport: With applications to data science
Gabriel Peyré and Marco Cuturi. Computational optimal transport: With applications to data science. Foundations and Trends in Machine Learning, 11(5–6):355–607, 2019. doi: 10.1561/2200000073
-
[48]
In-context time series predictor
Jiecheng Lu, Yan Sun, and Shihao Yang. In-context time series predictor. InInternational Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=dCcY2pyNIO
work page 2025
-
[49]
Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y . Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen. Time-LLM: Time series forecasting by reprogram- ming large language models. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Unb5CVPtae
work page 2024
-
[50]
Jiecheng Lu and Shihao Yang. Free energy mixer. InInternational Conference on Learning Representations,
-
[51]
URLhttps://openreview.net/forum?id=vjQnKToCnV
-
[52]
Unified training of universal time series forecasting transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research. PMLR, 2024
work page 2024
-
[53]
Viresh Pati, Yubin Kim, Vinh Pham, Jevon Twitty, Shihao Yang, and Jiecheng Lu. CAPS: Unifying attention, recurrence, and alignment in transformer-based time series forecasting, 2026
work page 2026
-
[54]
Transformers are RNNs: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5156–5165. PMLR, 2020
work page 2020
-
[55]
Rethinking attention with performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy Colwell, and Adrian Weller. Rethinking attention with performers. InInternational Conference on Learning Representations,
-
[56]
URLhttps://openreview.net/forum?id=Ua6zuk0WRH
-
[57]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst Conference on Language Modeling, 2024. URLhttps://openreview.net/forum?id=tEYskw1VY2
work page 2024
-
[58]
Gated linear attention transformers with hardware-efficient training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, and Yoon Kim. Gated linear attention transformers with hardware-efficient training. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research. PMLR, 2024. 12
work page 2024
-
[59]
Jiecheng Lu and Shihao Yang. Linear transformers as V AR models: Aligning autoregressive attention mechanisms with autoregressive forecasting. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research. PMLR, 2025. URL https://openreview.net/forum?id=SxJUV9mnyt
work page 2025
-
[60]
Retentive network: A successor to Transformer for large language models, 2023
Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to Transformer for large language models, 2023
work page 2023
-
[61]
ZeroS: Zero-sum linear attention for efficient transformers
Jiecheng Lu, Xu Han, Yan Sun, Viresh Pati, Yubin Kim, Siddhartha Somani, and Shihao Yang. ZeroS: Zero-sum linear attention for efficient transformers. InAdvances in Neural Information Processing Systems, volume 38, 2025. URLhttps://openreview.net/forum?id=Ms6IXbfzzX. Spotlight
work page 2025
-
[62]
Recurrent marked temporal point processes: Embedding event history to vector
Nan Du, Hanjun Dai, Rakshit Trivedi, Utkarsh Upadhyay, Manuel Gomez-Rodriguez, and Le Song. Recurrent marked temporal point processes: Embedding event history to vector. InProceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1555–1564,
-
[63]
doi: 10.1145/2939672.2939875
-
[64]
Hongyuan Mei and Jason M. Eisner. The neural hawkes process: A neurally self-modulating multivariate point process. InAdvances in Neural Information Processing Systems, volume 30, pages 6754–6764, 2017
work page 2017
-
[65]
Neural temporal point processes: A review
Oleksandr Shchur, Ali Caner Türkmen, Tim Januschowski, and Stephan Günnemann. Neural temporal point processes: A review. InProceedings of the Thirtieth International Joint Conference on Artificial Intelligence, pages 4585–4593, 2021. doi: 10.24963/ijcai.2021/623
-
[66]
George Sugihara and Robert M. May. Nonlinear forecasting as a way of distinguishing chaos from measurement error in time series.Nature, 344:734–741, 1990. doi: 10.1038/344734a0
-
[67]
Maria Dornelas, Laura H. Antão, Amanda E. Bates, et al. BioTIME 2.0: Expanding and improving a database of biodiversity time series.Global Ecology and Biogeography, 34(5):e70003, 2025. doi: 10.1111/geb.70003
-
[68]
Ember. Monthly Electricity Data. https://ember-energy.org/data/data-product/ monthly-electricity-data, 2026. Monthly full-release long-format CSV and Ember Electricity Data Methodology; accessed 2026-04-15
work page 2026
-
[69]
Diet compositions.Our World in Data, 2023
Hannah Ritchie, Pablo Rosado, and Max Roser. Diet compositions.Our World in Data, 2023. https: //ourworldindata.org/diet-compositions
work page 2023
-
[70]
Weekly Provisional Counts of Deaths by State and Select Causes, 2020–2023
National Center for Health Statistics. Weekly Provisional Counts of Deaths by State and Select Causes, 2020–2023. https://data.cdc.gov/d/muzy-jte6, 2023. Centers for Disease Control and Prevention; accessed 2026-04-15
work page 2020
-
[71]
U.S. Bureau of Labor Statistics. Quarterly Census of Employment and Wages. https://www.bls.gov/ cew/, 2026. Annual singlefile CSV data files for 2010–2024; accessed 2026-04-15
work page 2026
-
[72]
Environmental Protection Agency
U.S. Environmental Protection Agency. AirData Daily AQI by County.https://aqs.epa.gov/aqsweb/ airdata/download_files.html, 2026. Daily AQI by county CSV ZIP files for 2000–2024; accessed 2026-04-15
work page 2026
-
[73]
NOAA National Centers for Environmental Information. Storm Events Database. https://www.ncei. noaa.gov/stormevents/, 2026. Storm Events details CSV files for 2000–2024; accessed 2026-04-15. 13 A Theory: Full Proofs and Supporting Results We give the full proofs of the three main theorems stated in Section 4, together with approximation, retrieval-consiste...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.