Factorized Latent Dynamics for Video JEPA: An Empirical Study of Auxiliary Objectives
Pith reviewed 2026-05-20 14:34 UTC · model grok-4.3
The pith
Factorizing Video-JEPA latents into appearance and dynamics subspaces improves performance on appearance and temporal tasks with minimal impact on motion tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
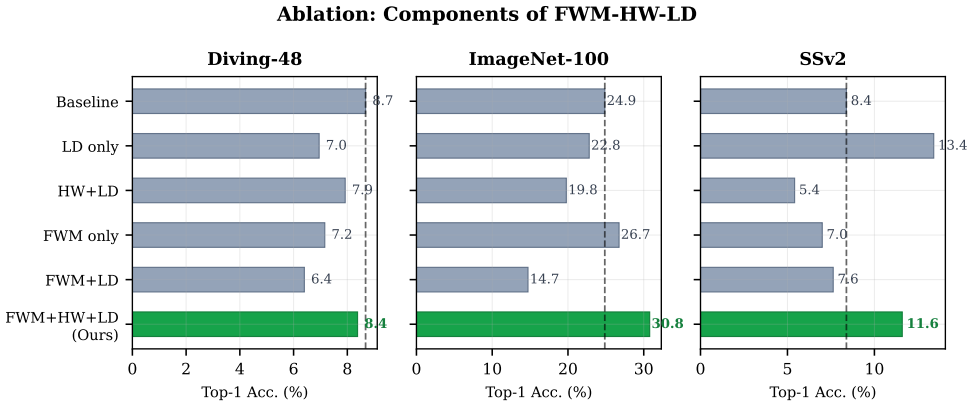
The paper claims that FWM-HW-LD, which separates the latent representation into appearance and dynamics subspaces and applies hard-region weighting to both JEPA prediction errors and latent dynamics errors, leads to improvements of 5.92 percentage points on ImageNet-100 and 3.21 on Something-Something V2 in the mixed-dataset pretraining regime, while staying within 0.30 points on Diving-48 compared to the baseline.
What carries the argument
Factorized World-Model with Hard-Region-Weighted Latent Dynamics (FWM-HW-LD), which splits the latent space into separate appearance and dynamics components and weights errors from hard regions during training.
If this is right
- Many auxiliary objectives in Video-JEPA exhibit capacity trade-offs across different downstream tasks.
- Latent factorization into appearance and dynamics subspaces helps mitigate these trade-offs.
- Hard-region weighting applied to both prediction and dynamics errors boosts performance in mixed data settings.
- The approach maintains strong performance on fine-grained motion tasks while gaining on appearance and reasoning benchmarks.
Where Pith is reading between the lines
- Similar factorization techniques might help in other self-supervised learning frameworks beyond JEPA.
- Testing this method on larger datasets could reveal if the benefits scale up.
- Combining this with other objectives might further reduce the observed trade-offs.
Load-bearing premise
The performance gains are specifically due to the latent factorization and hard-region weighting rather than differences in training procedures or random variations.
What would settle it
Replicating the experiments with identical training settings except removing the factorization and hard weighting components, and observing no similar gains, would support the claim; the opposite result would falsify it.
Figures


read the original abstract
Joint-Embedding Predictive Architectures (JEPA) are a promising framework for self-supervised video representation learning, yet the behavior of auxiliary objectives in small-scale Video-JEPA training is not well characterized. We report a small-scale empirical study of 18 auxiliary objective variants for Video-JEPA across two pretraining regimes: single-dataset (UCF-101) and mixed-dataset (UCF-101 + Something-Something V2 + ImageNet-100). We evaluate frozen representations on three complementary benchmarks: Diving-48 (fine-grained motion), SomethingSomething V2 (temporal reasoning), and ImageNet-100 (appearance). Our experiments suggest that many auxiliary objectives exhibit capacity trade-offs: gains on one downstream capability often coincide with degradation on another. We then study FWM-HW-LD (Factorized World-Model with Hard-Region-Weighted Latent Dynamics), a training-time objective that separates the latent representation into appearance and dynamics subspaces and applies hard-region weighting to both JEPA prediction errors and latent dynamics errors. In our mixed-dataset setting, FWM-HW-LD improves ImageNet-100 by +5.92 and SSv2 by +3.21 percentage points relative to the reference baseline, while remaining within 0.30 percentage points on Diving-48. These results indicate that latent factorization is a useful direction for studying auxiliary-objective trade-offs in Video-JEPA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a small-scale empirical study of 18 auxiliary objective variants for Video-JEPA under single-dataset (UCF-101) and mixed-dataset (UCF-101 + SSv2 + ImageNet-100) pretraining. It introduces FWM-HW-LD, which factorizes latents into appearance and dynamics subspaces and applies hard-region weighting to both JEPA prediction and latent dynamics losses. In the mixed-dataset regime, FWM-HW-LD is reported to improve ImageNet-100 by +5.92 pp and SSv2 by +3.21 pp while staying within 0.30 pp on Diving-48 relative to a reference baseline, suggesting latent factorization helps manage capacity trade-offs across appearance, temporal reasoning, and fine-grained motion tasks.
Significance. If the reported gains are robust, the work provides a useful empirical reference for auxiliary-objective design in Video-JEPA, particularly the value of explicit appearance/dynamics factorization plus hard-region weighting for balancing downstream capabilities. The systematic comparison of 18 variants on complementary benchmarks (Diving-48, SSv2, ImageNet-100) could help future studies avoid unintended trade-offs in small-scale video self-supervision.
major comments (2)
- [Abstract] Abstract: The central empirical claim states precise improvements (+5.92 pp on ImageNet-100, +3.21 pp on SSv2) as single-point estimates. No error bars, standard deviations across runs, number of random seeds, or statistical significance tests are mentioned, leaving open the possibility that the deltas arise from training stochasticity rather than the latent factorization and hard-region weighting.
- [Abstract / Results] The attribution of gains specifically to FWM-HW-LD (latent factorization plus hard-region weighting of JEPA and dynamics losses) requires that all other training factors (initialization, data ordering, optimizer state) are identical to the reference baseline. The manuscript provides no description of such controls or ablation isolating these components from other unstated procedural differences.
minor comments (2)
- The abstract introduces the acronym FWM-HW-LD with its expansion, but subsequent sections should consistently use the full name on first mention in the main text for clarity.
- Consider adding a table summarizing all 18 auxiliary objectives with their key design choices (factorization, weighting, etc.) to make the experimental design easier to follow.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study. We address the two major comments below regarding statistical reporting and experimental controls. Revisions will be incorporated to improve clarity and robustness without altering the core findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim states precise improvements (+5.92 pp on ImageNet-100, +3.21 pp on SSv2) as single-point estimates. No error bars, standard deviations across runs, number of random seeds, or statistical significance tests are mentioned, leaving open the possibility that the deltas arise from training stochasticity rather than the latent factorization and hard-region weighting.
Authors: We acknowledge that the reported deltas are presented as single-point estimates without accompanying measures of variability. Our study systematically compared 18 auxiliary objective variants under fixed computational budgets, which limited repeated runs. To strengthen the claims, the revised manuscript will include results averaged over three random seeds for the baseline and FWM-HW-LD variants, along with standard deviations and error bars on the key tables and in the abstract. revision: yes
-
Referee: [Abstract / Results] The attribution of gains specifically to FWM-HW-LD (latent factorization plus hard-region weighting of JEPA and dynamics losses) requires that all other training factors (initialization, data ordering, optimizer state) are identical to the reference baseline. The manuscript provides no description of such controls or ablation isolating these components from other unstated procedural differences.
Authors: All variants, including the reference baseline and FWM-HW-LD, were trained using an identical codebase, the same data loading and preprocessing pipeline, fixed hyperparameters, and consistent initialization procedures. Only the auxiliary objective formulation differs. We agree that explicit documentation of these controls is necessary for reproducibility. The revision will add a dedicated paragraph in the experimental setup section confirming that training factors were held constant and describing the seed handling and optimizer state management. revision: yes
Circularity Check
No circularity: purely empirical comparisons with no derivation chain
full rationale
The manuscript is an empirical study that trains Video-JEPA variants with 18 auxiliary-objective configurations and reports downstream accuracies on three benchmarks. No mathematical derivation, uniqueness theorem, or first-principles prediction is claimed; the central results are direct experimental deltas (e.g., +5.92 pp on ImageNet-100) obtained by comparing each variant against a fixed reference baseline under the same training regime. Because there is no load-bearing equation or fitted quantity that reduces to itself by construction, and no self-citation is invoked to justify a theoretical step, the work is self-contained against external benchmarks and exhibits no circularity.
Axiom & Free-Parameter Ledger
invented entities (1)
-
FWM-HW-LD objective
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FWM-HW-LD ... separates the latent representation into appearance and dynamics subspaces and applies hard-region weighting to both JEPA prediction errors and latent dynamics errors
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lstatic = E[|Z_app(t+1) − Z_app(t)|]; Lorth = 1/N ||C^T_Zapp C_Zdyn||^2_F
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ViViT: A video vision transformer
Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lu ˇci´c, and Cordelia Schmid. ViViT: A video vision transformer. InICCV, 2021. 2
work page 2021
-
[2]
Self-supervised learning from images with a joint-embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bo- janowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. InCVPR, 2023. 1, 2
work page 2023
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Gar- rido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zho- lus, Yann LeCun, Michael Rabbat, and Nicolas Ballas. V- JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
BEiT: Bert pre-training of image transformers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEiT: Bert pre-training of image transformers. InICLR, 2022. 2
work page 2022
-
[5]
VI- CReg: Variance-invariance-covariance regularization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. VI- CReg: Variance-invariance-covariance regularization for self-supervised learning. InICLR, 2022. 2
work page 2022
-
[6]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nico- las Ballas. V-JEPA: Video joint embedding predictive archi- tecture.arXiv preprint arXiv:2404.08471, 2024. 1, 2, 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Is space-time attention all you need for video understanding? InICML, 2021
Gedas Bertasius, Heng Wang, and Lorenzo Torresani. Is space-time attention all you need for video understanding? InICML, 2021. 2
work page 2021
-
[8]
Unsupervised learn- ing of visual features by contrasting cluster assignments
Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Pi- otr Bojanowski, and Armand Joulin. Unsupervised learn- ing of visual features by contrasting cluster assignments. In NeurIPS, 2020. 2
work page 2020
-
[9]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, 2021. 2
work page 2021
-
[10]
Quo vadis, action recognition? a new model and the kinetics dataset
Jo ˜ao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. InCVPR,
-
[11]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Ge- offrey Hinton. A simple framework for contrastive learning of visual representations. InICML, 2020. 2
work page 2020
-
[12]
Improved baselines with momentum contrastive learning,
Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning,
-
[13]
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Antonino Furnari, Jian Ma, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, and Michael Wray. Rescaling egocentric vision: Collection, pipeline and challenges for EPIC-KITCHENS-100.Inter- national Journal of Computer Vision, 2022. 2
work page 2022
-
[14]
Carl Doersch, Abhinav Gupta, and Alexei A. Efros. Unsu- pervised visual representation learning by context prediction. InICCV, 2015. 2
work page 2015
-
[15]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021. 2, 4 8
work page 2021
-
[16]
Multiscale vision transformers
Haoqi Fan, Bo Xiong, Karttikeya Mangalam, Yanghao Li, Zhicheng Yan, Jitendra Malik, and Christoph Feichtenhofer. Multiscale vision transformers. InICCV, 2021. 2
work page 2021
-
[17]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In ICCV, 2019. 2
work page 2019
-
[18]
Masked autoencoders as spatiotemporal learners
Christoph Feichtenhofer, Haoqi Fan, Yanghao Li, and Kaim- ing He. Masked autoencoders as spatiotemporal learners. In NeurIPS, 2022. 2
work page 2022
-
[19]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The “something something” video database for learning and evaluating visual common sense. InICCV, 2017. 1, 2, 4, 5
work page 2017
-
[20]
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre H. Richemond, Elena Buchatskaya, Carl Do- ersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Moham- mad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R´emi Munos, and Michal Valko. Bootstrap your own latent: A new approach to self-supervised learning. InNeurIPS, 2020. 2
work page 2020
-
[21]
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and Jos ´e Lezama. Siamese masked autoencoders. InNeurIPS, 2024. 2
work page 2024
-
[22]
Self- supervised co-training for video representation learning
Tengda Han, Weidi Xie, and Andrew Zisserman. Self- supervised co-training for video representation learning. In NeurIPS, 2020. 2, 4
work page 2020
-
[23]
Momentum contrast for unsupervised visual rep- resentation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual rep- resentation learning. InCVPR, 2020. 2
work page 2020
-
[24]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InCVPR, 2022. 1, 2, 3
work page 2022
-
[25]
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner.β-V AE: Learning basic visual concepts with a constrained variational framework. InICLR, 2017. 2
work page 2017
-
[26]
Learning deep representations by mutual informa- tion estimation and maximization
R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual informa- tion estimation and maximization. InICLR, 2019. 2
work page 2019
-
[27]
Diederik P. Kingma and Max Welling. Auto-encoding vari- ational bayes. InICLR, 2014. 2
work page 2014
-
[28]
Cycle-contrast for self-supervised video representation learning
Quan Kong, Wen Wei, Ziwei Deng, Tomoo Yoshinaga, and Tomokazu Murakami. Cycle-contrast for self-supervised video representation learning. InNeurIPS, 2020. 2, 4
work page 2020
-
[29]
A path towards autonomous machine intelli- gence, 2022
Yann LeCun. A path towards autonomous machine intelli- gence, 2022. Open review essay. 1, 2
work page 2022
-
[30]
Resound: To- wards action recognition without representation bias
Yingwei Li, Yi Li, and Nuno Vasconcelos. Resound: To- wards action recognition without representation bias. In ECCV, 2018. 1, 2, 5
work page 2018
-
[31]
Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, and Han Hu. Video swin transformer. InCVPR,
-
[32]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019. 4
work page 2019
-
[33]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics
Luc Maes, Quentin Le Lidec, Damien Scieur, Yann Le- Cun, and Randall Balestriero. LeJEPA: Stable joint- embedding predictive architectures with sketched-isotropic- Gaussian regularization.arXiv preprint arXiv:2511.08544,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Lawrence Zitnick, and Martial Hebert
Ishan Misra, C. Lawrence Zitnick, and Martial Hebert. Shuf- fle and learn: Unsupervised learning using temporal order verification. InECCV, 2016. 2
work page 2016
-
[35]
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mido Assran, Koustuv Sinha, Mike Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-JEPA 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026. 2
-
[36]
Unsupervised learning of visual representations by solving jigsaw puzzles
Mehdi Noroozi and Paolo Favaro. Unsupervised learning of visual representations by solving jigsaw puzzles. InECCV,
-
[37]
Repre- sentation learning with contrastive predictive coding, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Repre- sentation learning with contrastive predictive coding, 2018. 2
work page 2018
-
[38]
Videomoco: Contrastive video representation learning with temporally adversarial examples
Tian Pan, Yibing Song, Tianyu Yang, Wenhao Jiang, and Wei Liu. Videomoco: Contrastive video representation learning with temporally adversarial examples. InCVPR, 2021. 2
work page 2021
-
[39]
Learning features by watching ob- jects move
Deepak Pathak, Ross Girshick, Piotr Doll ´ar, Trevor Darrell, and Bharath Hariharan. Learning features by watching ob- jects move. InCVPR, 2017. 2, 3
work page 2017
-
[40]
Broaden Your Views for Self-Supervised Video Learning
Adri `a Recasens, Pauline Luc, Jean-Baptiste Alayrac, Luyu Wang, Florian Strub, Corentin Tallec, Mateusz Malinowski, Viorica P ˘atr˘aucean, Florent Altch ´e, Michal Valko, Jean- Bastien Grill, Aaron van den Oord, and Andrew Zisserman. Broaden Your Views for Self-Supervised Video Learning. In ICCV, 2021. 2, 4
work page 2021
-
[41]
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet large scale visual recognition chal- lenge. InInternational Journal of Computer Vision, 2015. 2, 4, 5
work page 2015
-
[42]
UCF101: A dataset of 101 human actions classes from videos in the wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. UCF101: A dataset of 101 human actions classes from videos in the wild. InCRCV-TR-12-01, 2012. 2, 4
work page 2012
-
[43]
Videobert: A joint model for video and language representation learning
Chen Sun, Austin Myers, Carl V ondrick, Kevin Murphy, and Cordelia Schmid. Videobert: A joint model for video and language representation learning. InICCV, 2019. 2
work page 2019
-
[44]
Con- trastive multiview coding
Yonglong Tian, Dilip Krishnan, and Phillip Isola. Con- trastive multiview coding. InECCV, 2020. 2
work page 2020
-
[45]
VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InNeurIPS, 2022. 1, 2, 3
work page 2022
-
[46]
A closer look at spatiotemporal convolutions for action recognition
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. InCVPR, 2018. 2
work page 2018
-
[47]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InNeurIPS, 2017. 2
work page 2017
-
[48]
VideoMAE V2: 9 Scaling video masked autoencoders with dual masking
Limin Wang, Bingkun Huang, Zhiyu Zhao, Zhan Tong, Yi- nan He, Yi Wang, Yali Wang, and Yu Qiao. VideoMAE V2: 9 Scaling video masked autoencoders with dual masking. In CVPR, 2023. 2
work page 2023
-
[49]
SimMIM: A simple framework for masked image modeling
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. SimMIM: A simple framework for masked image modeling. InCVPR, 2022. 2
work page 2022
-
[50]
Self-supervised spatiotemporal learning via video clip order prediction
Dejing Xu, Jun Xiao, Zhou Zhao, Jian Shao, Di Xie, and Yueting Zhuang. Self-supervised spatiotemporal learning via video clip order prediction. InCVPR, 2019. 2
work page 2019
-
[51]
Video representa- tion learning using discriminative pooling
Shen Yan, Xuehan Xiong, Anurag Arnab, Zhicheng Lu, Mi Zhang, Chen Sun, and Cordelia Schmid. Video representa- tion learning using discriminative pooling. InCVPR, 2022. 2
work page 2022
-
[52]
Why and how auxiliary tasks improve JEPA rep- resentations.arXiv preprint arXiv:2509.12249, 2025
Jiacan Yu, Siyi Chen, Mingrui Liu, Nono Horiuchi, Vladimir Braverman, Zicheng Xu, Dan Haramati, and Randall Balestriero. Why and how auxiliary tasks improve JEPA rep- resentations.arXiv preprint arXiv:2509.12249, 2025. 1, 2, 8
-
[53]
Barlow twins: Self-supervised learning via redundancy reduction
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and St´ephane Deny. Barlow twins: Self-supervised learning via redundancy reduction. InICML, 2021. 2 10 A. Pseudocode for Key Methods Algorithm 1 summarizes the standard V-JEPA training loop. Algorithm 2 describes FWM-HW-LD, which extends the baseline with hard-weighted prediction, factorization losses, and ...
work page 2021
-
[54]
The 60% SSv2 weight reflects our explicit goal of strength- ening temporal reasoning
so that the same data pipeline handles all three sources. The 60% SSv2 weight reflects our explicit goal of strength- ening temporal reasoning. Mask sampling.The default V-JEPA mask is a multi- block spatiotemporal tube. For Motion-Guided Masking, we compute per-frame motion energy as the mean L1 dif- ference between consecutive frames at the patch level,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.