Soap2Soap: Long Cinematic Video Remaking via Multi-Agent Collaboration
Pith reviewed 2026-05-20 13:12 UTC · model grok-4.3
The pith
A multi-agent framework with screenplay anchors and visual references keeps identity and narrative intact across long video remakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
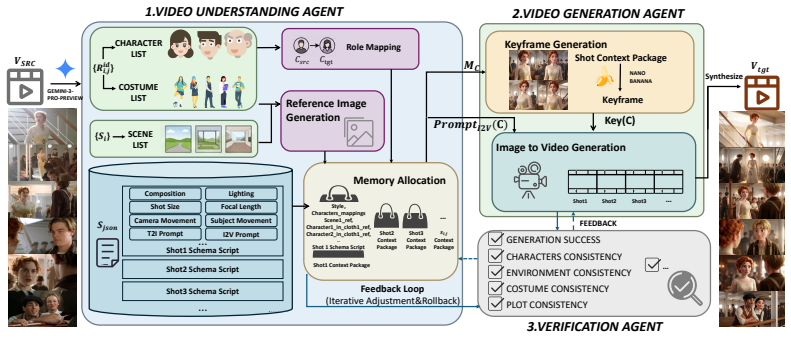
Soap2Soap is a multi-agent framework that enforces long-term language-visual consistency in long-horizon video-to-video cinematic remaking through a Dual-Bridge Consistency mechanism consisting of a scene-aware JSON screenplay as persistent semantic backbone and dynamically allocated visual reference anchors at scene and shot levels, together with batch keyframe consistency via grid-based joint generation and closed-loop verification that audits identity, stability, and alignment to trigger selective regeneration.
What carries the argument
Dual-Bridge Consistency mechanism that pairs a persistent scene-aware JSON screenplay with dynamically allocated scene- and shot-level visual reference anchors, reinforced by grid-based batch keyframe generation and closed-loop verification.
If this is right
- Long-horizon video-to-video remaking tasks can preserve character identity and motion choreography across hundreds of shots without model retraining.
- Compounding drift is reduced by enforcing language-visual consistency before and during synthesis rather than after.
- Narrative fidelity and scene stability improve in stylization or actor-replacement scenarios for complete films or series.
- Closed-loop verification enables selective regeneration that raises overall alignment without regenerating entire videos.
Where Pith is reading between the lines
- The same persistent-backbone pattern could be tested on long-form text-to-video or audio generation to see whether semantic drift is similarly controlled.
- Replacing the grid-based batch step with newer latent-space sharing methods might reduce verification calls further.
- Applying the framework to unscripted footage such as documentaries would test whether the JSON screenplay assumption still holds outside tightly plotted narratives.
Load-bearing premise
A persistent scene-aware JSON screenplay together with scene- and shot-level visual anchors plus batch keyframe generation can stop compounding identity drift, background mutation, and semantic erosion in long sequences without retraining the base model.
What would settle it
Run the full pipeline on a multi-hundred-shot sequence and check whether the same character retains matching face, clothing, and pose across every shot when the camera viewpoint changes substantially.
Figures













read the original abstract
We study series-level cinematic remaking, a long-horizon video-to-video generation problem that localizes full episodes or films via stylization or actor replacement while strictly preserving narrative structure, motion choreography, and character identity across hundreds of shots. Existing video generation and editing pipelines often break down in this regime due to compounding identity drift, background mutation, and semantic erosion under large camera motions and viewpoint changes. We propose Soap2Soap, a multi-agent framework that enforces long-term language-visual consistency through a Dual-Bridge Consistency mechanism: a scene-aware JSON screenplay serving as a persistent semantic backbone, and dynamically allocated visual reference anchors at both scene and shot levels. To suppress drift before video synthesis, we introduce batch keyframe consistency, jointly generating multiple keyframes in a shared latent context via a grid-based formulation. A closed-loop verification agent further audits identity, stability, and alignment to trigger selective regeneration. Experiments on SoapBench demonstrate strong improvements over commercial video generation APIs in long-term consistency and narrative fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Soap2Soap, a multi-agent framework for series-level cinematic remaking that performs long-horizon video-to-video generation while preserving narrative structure, motion choreography, and character identity across hundreds of shots. It proposes a Dual-Bridge Consistency mechanism consisting of a persistent scene-aware JSON screenplay as semantic backbone together with dynamically allocated scene- and shot-level visual reference anchors; this is augmented by batch keyframe consistency realized through a grid-based formulation that jointly generates multiple keyframes in a shared latent context, plus a closed-loop verification agent that audits identity, stability, and alignment to trigger selective regeneration. Experiments on the introduced SoapBench benchmark report quantitative gains in long-term consistency and narrative fidelity relative to commercial video generation APIs.
Significance. If the reported gains hold, the work constitutes a practical engineering advance in training-free long-horizon video editing and remaking. The combination of persistent language-visual bridges with batch generation and closed-loop verification offers a concrete approach to suppressing identity drift and semantic erosion without model retraining, which could directly benefit film localization, actor replacement, and extended narrative synthesis pipelines. The presence of implementation details, component-isolating ablation tables, and metrics on identity consistency, background stability, and narrative alignment strengthens the contribution.
minor comments (3)
- [§4.2] §4.2 (Ablation Studies): the table isolating the Dual-Bridge and batch-keyframe components reports absolute metric deltas but does not include variance across multiple random seeds; adding standard deviations would clarify whether the observed gains are robust.
- [Figure 4] Figure 4 (Grid-based keyframe visualization): the shared latent context is illustrated but the precise mechanism by which cross-keyframe attention is restricted to the grid layout is not annotated; a supplementary diagram or equation would improve reproducibility.
- [§3.3] §3.3 (Closed-loop verification): the decision thresholds for triggering regeneration are described qualitatively; providing the exact numerical criteria or pseudocode would aid readers attempting to re-implement the agent.
Simulated Author's Rebuttal
We thank the referee for the positive and constructive summary of our work on Soap2Soap. The recommendation for minor revision is appreciated, and we will incorporate any editorial or minor clarifications in the revised manuscript. As no specific major comments were enumerated in the report, we provide a brief overall response below.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an engineering framework (multi-agent collaboration with Dual-Bridge Consistency via scene-aware JSON screenplay and visual anchors, batch keyframe grid generation, and closed-loop verification) for long-horizon video-to-video remaking. Claims rest on descriptive system architecture, implementation details, ablation tables isolating components, and quantitative metrics on SoapBench against commercial APIs. No equations, fitted parameters renamed as predictions, self-definitional reductions, or load-bearing self-citations that collapse the central consistency claims back to unverified inputs were present. The derivation chain is self-contained through explicit component design and external empirical validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing video generation models can be guided by persistent text screenplays and visual reference anchors to reduce drift over long sequences.
invented entities (2)
-
Dual-Bridge Consistency mechanism
no independent evidence
-
Batch keyframe consistency via grid-based formulation
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Dual-Bridge Consistency mechanism: a scene-aware JSON screenplay serving as a persistent semantic backbone, and dynamically allocated visual reference anchors at both scene and shot levels... batch keyframe consistency, jointly generating multiple keyframes in a shared latent context via a grid-based formulation. A closed-loop verification agent further audits...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
grid joint synthesis strategy... 2×2 or 3×3 grid... all sub-images share attention within the same generation context
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, and Dominik Lorenz. Stable video diffusion: Scaling latent video diffusion models to large datasets.ArXiv, abs/2311.15127,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://api.semanticscholar.org/CorpusID:265312551
-
[3]
ByteDance. Seedance 2.0, 2026. URL https://seed.bytedance.com/en/seedance2_0. Accessed: Mar 2026
work page 2026
-
[4]
Jun Chen, Deyao Zhu, Kilichbek Haydarov, Xiang Li, and Mohamed Elhoseiny. Video chatcaptioner: Towards enriched spatiotemporal descriptions.arXiv preprint arXiv:2304.04227, 2023
-
[5]
Sihan Chen, Handong Li, Qunbo Wang, Zijia Zhao, Mingzhen Sun, Xinxin Zhu, and Jing Liu. Vast: A vision-audio-subtitle-text omni-modality foundation model and dataset.Advances in Neural Information Processing Systems, 36:72842–72866, 2023
work page 2023
-
[6]
Transanimate: Taming layer diffusion to generate rgba video
Xuewei Chen, Zhimin Chen, and Yiren Song. Transanimate: Taming layer diffusion to generate rgba video. arXiv preprint arXiv:2503.17934, 2025
-
[7]
Ayushman Das, Shu-Ching Chen, Mei-Ling Shyu, and Saad Sadiq. Enabling synergistic knowledge sharing and reasoning in large language models with collaborative multi-agents. In2023 IEEE 9th International Conference on Collaboration and Internet Computing (CIC), pages 92–98. IEEE, 2023
work page 2023
-
[8]
Guian Fang, Yuchao Gu, and Mike Zheng Shou. Frameprompt: In-context controllable animation with zero structural changes.ArXiv, abs/2506.17301, 2025. URL https://api.semanticscholar.org/ CorpusID:280000000
-
[9]
Adaworld: Learning adaptable world models with latent actions.arXiv preprint arXiv:2503.18938, 2025
Shenyuan Gao, Siyuan Zhou, Yilun Du, Jun Zhang, and Chuang Gan. Adaworld: Learning adaptable world models with latent actions, 2025. URLhttps://arxiv.org/abs/2503.18938
-
[10]
Gemini 3 flash image (nano banana 2), 2026
Google. Gemini 3 flash image (nano banana 2), 2026. URL https://ai.google.dev/models/gemini. Developer documentation. Accessed: Mar 2026
work page 2026
-
[11]
Gemini 3 flash: Frontier intelligence built for speed, 2025
Google DeepMind. Gemini 3 flash: Frontier intelligence built for speed, 2025. URL https://deepmind. google/models/gemini/flash/. Model card. Accessed: Mar 2026
work page 2025
-
[12]
Veo 3: Video generation model with native audio, 2025
Google DeepMind. Veo 3: Video generation model with native audio, 2025. URL https://deepmind. google/technologies/veo/. Technical report. Accessed: Mar 2026
work page 2025
-
[13]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Yaohui Wang, Y . Qiao, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning.ArXiv, abs/2307.04725,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URLhttps://api.semanticscholar.org/CorpusID:259501509
-
[15]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion, 2025. URLhttps://arxiv.org/abs/2506.08009
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
VACE: All-in-One Video Creation and Editing
Zeyinzi Jiang, Zhen Han, Chaojie Mao, Jingfeng Zhang, Yulin Pan, and Yu Liu. Vace: All-in-one video creation and editing.ArXiv, abs/2503.07598, 2025. URL https://api.semanticscholar.org/ CorpusID:276928131
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Language repository for long video understanding
Kumara Kahatapitiya, Kanchana Ranasinghe, Jongwoo Park, and Michael S Ryoo. Language repository for long video understanding. InFindings of the Association for Computational Linguistics: ACL 2025, pages 5627–5646, 2025
work page 2025
-
[18]
Seeing the unseen: Visual metaphor captioning for videos.ArXiv, abs/2406.04886, 1, 2024
Abisek Rajakumar Kalarani, Pushpak Bhattacharyya, and Sumit Shekhar. Seeing the unseen: Visual metaphor captioning for videos.ArXiv, abs/2406.04886, 1, 2024
-
[19]
Wonkyun Kim, Changin Choi, Wonseok Lee, and Wonjong Rhee. An image grid can be worth a video: Zero-shot video question answering using a vlm.IEEE Access, 12:193057–193075, 2024
work page 2024
-
[20]
Theory of mind for multi-agent collaboration via large language models
Huao Li, Yu Chong, Simon Stepputtis, Joseph P Campbell, Dana Hughes, Charles Lewis, and Katia Sycara. Theory of mind for multi-agent collaboration via large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 180–192, 2023
work page 2023
-
[21]
Yuanhang Li, Yiren Song, Junzhe Bai, Xinran Liang, Hu Yang, Libiao Jin, and Qi Mao. Ic-effect: Precise and efficient video effects editing via in-context learning.ArXiv, abs/2512.15635, 2025. URL https://api.semanticscholar.org/CorpusID:283920206. 11
-
[22]
Han Lin, Abhaysinh Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi- scene video generation via llm-guided planning.ArXiv, abs/2309.15091, 2023. URL https://api. semanticscholar.org/CorpusID:262825203
-
[23]
Mm-vid: Advancing video understanding with gpt-4v (ision)
Kevin Lin, Faisal Ahmed, Linjie Li, Chung-Ching Lin, Ehsan Azarnasab, Zhengyuan Yang, Jianfeng Wang, Lin Liang, Zicheng Liu, Yumao Lu, et al. Mm-vid: Advancing video understanding with gpt-4v (ision). arXiv preprint arXiv:2310.19773, 2023
-
[24]
Vlog: Video-language models by generative retrieval of narration vocabulary
Kevin Qinghong Lin and Mike Zheng Shou. Vlog: Video-language models by generative retrieval of narration vocabulary. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3218–3228, 2025
work page 2025
-
[25]
Follow-your-click: Open-domain regional image animation via motion prompts
Yue Ma, Yin-Yin He, Hongfa Wang, Andong Wang, Leqi Shen, Chenyang Qi, Jixuan Ying, Chengfei Cai, Zhifeng Li, Heung yeung Shum, Wei Liu, and Qifeng Chen. Follow-your-click: Open-domain regional image animation via motion prompts. InAAAI Conference on Artificial Intelligence, 2025. URL https://api.semanticscholar.org/CorpusID:277751109
work page 2025
-
[26]
Screenwriter: Automatic screenplay generation and movie summarisation
Louis Mahon and Mirella Lapata. Screenwriter: Automatic screenplay generation and movie summarisation. arXiv preprint arXiv:2410.19809, 2024
-
[27]
Morevqa: Exploring modular reasoning models for video question answering
Juhong Min, Shyamal Buch, Arsha Nagrani, Minsu Cho, and Cordelia Schmid. Morevqa: Exploring modular reasoning models for video question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13235–13245, 2024
work page 2024
-
[28]
Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis
Juan Diego Ortega, Neslihan Kose, Paola Natalia Cañas, Min-An Chao, Alexander Unnervik, Marcos Nieto, Oihana Otaegui, and Luis Salgado. Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis. InECCV Workshops, 2020. URL https://api.semanticscholar. org/CorpusID:221341025
work page 2020
-
[29]
Bo Pan, Jiaying Lu, Ke Wang, Li Zheng, Zhen Wen, Yingchaojie Feng, Minfeng Zhu, and Wei Chen. Agentcoord: Visually exploring coordination strategy for llm-based multi-agent collaboration.Computers & graphics, page 104338, 2025
work page 2025
-
[30]
Long-context state-space video world models.ArXiv, abs/2505.20171, 2025
Ryan Po, Yotam Nitzan, Richard Zhang, Berlin Chen, Tri Dao, Eli Shechtman, Gordon Wetzstein, and Xun Huang. Long-context state-space video world models.ArXiv, abs/2505.20171, 2025. URL https://api.semanticscholar.org/CorpusID:278911218
-
[31]
Modeling by shortest data description.Automatica, 14(5):465–471, 1978
Jorma Rissanen. Modeling by shortest data description.Automatica, 14(5):465–471, 1978
work page 1978
-
[32]
Runway. Introducing runway gen-4. https://runwayml.com/research/ introducing-runway-gen-4, 2025. Accessed: 2026-03-06
work page 2025
-
[33]
Worldwander: Bridging egocentric and exocentric worlds in video generation,
Quanjian Song, Yiren Song, Kelly Peng, Yuan Gao, and Mike Zheng Shou. Worldwander: Bridging egocentric and exocentric worlds in video generation.arXiv preprint arXiv:2511.22098, 2025
-
[34]
Processpainter: Learn painting process from sequence data.arXiv preprint arXiv:2406.06062, 2024
Yiren Song, Shijie Huang, Chen Yao, Xiaojun Ye, Hai Ci, Jiaming Liu, Yuxuan Zhang, and Mike Zheng Shou. Processpainter: Learn painting process from sequence data.arXiv preprint arXiv:2406.06062, 2024
-
[35]
Mitty: Diffusion-based human-to-robot video generation.arXiv preprint arXiv:2512.17253, 2025
Yiren Song, Cheng Liu, Weijia Mao, and Mike Zheng Shou. Mitty: Diffusion-based human-to-robot video generation.arXiv preprint arXiv:2512.17253, 2025
-
[36]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888– 11898, 2023
work page 2023
-
[37]
Yunlong Tang, Jing Bi, Siting Xu, Luchuan Song, Susan Liang, Teng Wang, Daoan Zhang, Jie An, Jingyang Lin, Rongyi Zhu, et al. Video understanding with large language models: A survey.IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[38]
Kling Team, Jialu Chen, Yuanzheng Ci, Xiangyu Du, Zipeng Feng, Kun Gai, Sainan Guo, Feng Han, Jingbin He, Kang He, et al. Kling-omni technical report.arXiv preprint arXiv:2512.16776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms.arXiv preprint arXiv:2501.06322, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Xiaofeng Meng, Ningying Zhang, Pandeng Li, Ping Wu, Ruihang Chu, Rui Feng, Shiwei Zhang, Siyang Sun, Tao Fang, Tianxing Wang...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Qinghe Wang, Xiaoyu Shi, Baolu Li, Weikang Bian, Quande Liu, Huchuan Lu, Xintao Wang, Pengfei Wan, Kun Gai, and Xu Jia. Multishotmaster: A controllable multi-shot video generation framework.arXiv preprint arXiv:2512.03041, 2025
-
[42]
Zhenhailong Wang, Shaoguang Mao, Wenshan Wu, Tao Ge, Furu Wei, and Heng Ji. Unleashing the emergent cognitive synergy in large language models: A task-solving agent through multi-persona self- collaboration. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
work page 2024
-
[43]
Video models are zero-shot learners and reasoners
Thaddaus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners.ArXiv, abs/2509.20328, 2025. URLhttps://api.semanticscholar.org/CorpusID:281505752
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
HunyuanVideo 1.5 Technical Report
Bing Wu, Chang Zou, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Jack Peng, Jianbing Wu, Jiangfeng Xiong, Jie Jiang, Linus, Patrol, Peizhen Zhang, Peng Chen, Penghao Zhao, Qi Tian, Songtao Liu, Weijie Kong, Weiyan Wang, Xiao He, Xin Li, Xinchi Deng, Xuefei Zhe, Yang Li, Yanxin Long, Yuanbo Peng, Yue Wu, Yuhong Liu, Zhenyu Wang, Zuozhuo Dai, Bo Peng, Coo...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Wynne Hsu, Ying Shan, Xiaohu Qie, and Mike Zheng Shou. Tune-a-video: One-shot tuning of image diffusion models for text-to-video generation.2023 IEEE/CVF International Conference on Computer Vision (ICCV), pages 7589–7599,
work page 2023
-
[46]
URLhttps://api.semanticscholar.org/CorpusID:254974187
-
[47]
Automated movie generation via multi-agent cot planning.arXiv preprint arXiv:2503.07314, 2025
Weijia Wu, Zeyu Zhu, and Mike Zheng Shou. Automated movie generation via multi-agent cot planning. arXiv preprint arXiv:2503.07314, 2025
-
[48]
Mocha:end-to-end video character replacement without structural guidance, 2026
Zhengbo Xu, Jie Ma, Ziheng Wang, Zhan Peng, Jun Liang, and Jing Li. Mocha:end-to-end video character replacement without structural guidance, 2026. URLhttps://arxiv.org/abs/2601.08587
-
[49]
Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces, 2025
Zhenran Xu, Longyue Wang, Jifang Wang, Zhouyi Li, Senbao Shi, Xue Yang, Yiyu Wang, Baotian Hu, Jun Yu, and Min Zhang. Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces, 2025. URLhttps://arxiv.org/abs/2501.12909
-
[50]
Wenhao Yan, Sheng Ye, Zhuoyi Yang, Jiayan Teng, ZhenHui Dong, Kairui Wen, Xiaotao Gu, Yong-Jin Liu, and Jie Tang. Scail: Towards studio-grade character animation via in-context learning of 3d-consistent pose representations, 2026. URLhttps://arxiv.org/abs/2512.05905
-
[51]
Pei Yang, Hai Ci, Yiren Song, and Mike Zheng Shou. X-humanoid: Robotize human videos to generate humanoid videos at scale.arXiv preprint arXiv:2512.04537, 2025
-
[52]
Coagent: Collaborative planning and consistency agent for coherent video generation, 2025
Qinglin Zeng, Kaitong Cai, Ruiqi Chen, Qinhan Lv, and Keze Wang. Coagent: Collaborative planning and consistency agent for coherent video generation, 2025. URLhttps://arxiv.org/abs/2512.22536
-
[53]
Eventhallusion: Diagnosing event hallucinations in video llms.arXiv preprint arXiv:2409.16597, 2024
Jiacheng Zhang, Yang Jiao, Shaoxiang Chen, Na Zhao, Zhiyu Tan, Hao Li, Xingjun Ma, and Jingjing Chen. Eventhallusion: Diagnosing event hallucinations in video llms.arXiv preprint arXiv:2409.16597, 2024
-
[54]
Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2025
Kaiwen Zhang, Liming Jiang, Angtian Wang, Jacob Zhiyuan Fang, Tiancheng Zhi, Qing Yan, Hao Kang, Xin Lu, and Xingang Pan. Storymem: Multi-shot long video storytelling with memory.arXiv preprint arXiv:2512.19539, 2025. 13
-
[55]
Anime: Adaptive multi-agent planning for long animation generation, 2025
Lisai Zhang, Baohan Xu, Siqian Yang, Mingyu Yin, Jing Liu, Chao Xu, Siqi Wang, Yidi Wu, Yuxin Hong, Zihao Zhang, Yanzhang Liang, and Yudong Jiang. Anime: Adaptive multi-agent planning for long animation generation, 2025. URLhttps://arxiv.org/abs/2508.18781
-
[56]
Frame context packing and drift prevention in next-frame-prediction video diffusion models
Lvmin Zhang, Shengqu Cai, Muyang Li, Gordon Wetzstein, and Maneesh Agrawala. Frame context packing and drift prevention in next-frame-prediction video diffusion models. 2025. URL https: //api.semanticscholar.org/CorpusID:277857265
work page 2025
-
[57]
Learning video representations from large language models
Yue Zhao, Ishan Misra, Philipp Krähenbühl, and Rohit Girdhar. Learning video representations from large language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6586–6597, 2023. 14 Appendix The appendix is organized as follows:
work page 2023
-
[58]
Section A: User Study- We provide details of our user study protocol for evaluating series-level cinematic remaking, including the evaluation criteria, compared methods, questionnaire design, and preference results
-
[59]
Section B: Multi-Agent System Implementation Details- We provide comprehensive implementa- tion details of our three collaborative agents: (1) Video Understanding Agent for structured screenplay generation and character tracking, (2) Video Generation Agent for anchor-driven keyframe and video synthesis, and (3) Verification Agent for closed-loop quality a...
-
[60]
Section C: Output JSON Format- We present the structured output format from our video under- standing module, demonstrating comprehensive JSON examples including top-level organization, character roster structure, and shot-level analysis with technical cinematic parameters and narrative descriptions
-
[61]
Section D: Grid Joint Synthesis Visualization- We demonstrate our grid joint synthesis strategy for improving intra-scene consistency, including2×2and3×3grid generation examples
-
[62]
Section E: More Keyframe Results- We present 7 additional comprehensive visual comparisons across videos ranging from 14 to over 40 shots, providing keyframe-by-keyframe analysis that demonstrates the visual fidelity and consistency of our generation results. A User Study We conduct a user study to complement automated evaluations and assess perceptual qu...
work page 1920
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.