Stop When Reasoning Converges: Semantic-Preserving Early Exit for Reasoning Models
Pith reviewed 2026-05-20 12:25 UTC · model grok-4.3
The pith
PUMA stops large reasoning models early by flagging semantic redundancy between successive thought steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Reasoning-level semantic redundancy acts as a complementary early-exit signal to answer-level cues: when successive steps revisit established conclusions instead of adding novel progress, the reasoning trajectory has converged, allowing removal of redundant continuation while keeping both answer accuracy and a coherent reasoning prefix intact.
What carries the argument
PUMA, a plug-and-play framework that combines a lightweight Redundancy Detector with answer-level verification to identify converged reasoning trajectories.
Load-bearing premise
Semantic redundancy between successive steps reliably means the model has finished exploring and self-correcting and will not reach a better answer by continuing.
What would settle it
A test set of problems where models that exit at the first detected redundancy produce measurably lower accuracy than models allowed to continue, especially on instances known to require late self-correction.
Figures


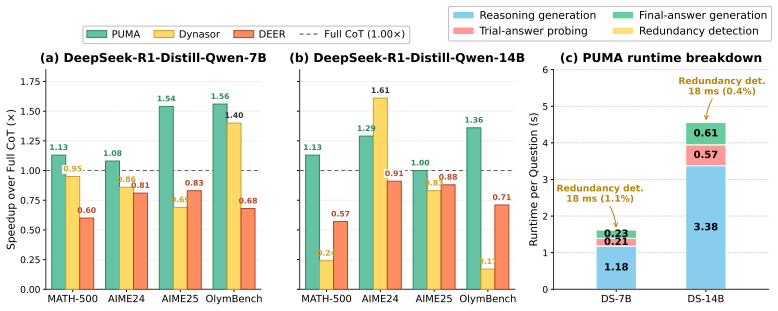


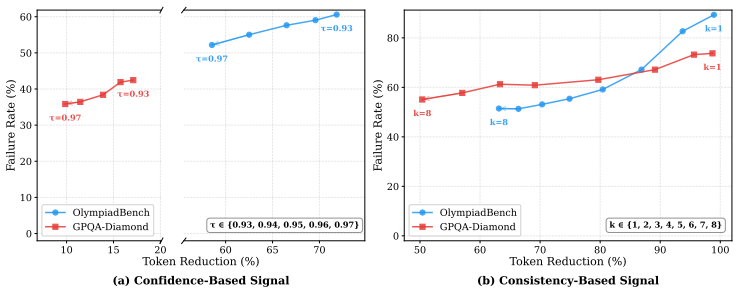


read the original abstract
Large Reasoning Models (LRMs) achieve strong performance by generating long chains of thought (CoT), but often overthink, continuing to reason after a solution has already stabilized and thereby wasting tokens and increasing latency. Existing inference-time early-exit methods rely primarily on answer-level signals, such as confidence or trial-answer consistency, to decide when to stop. However, these signals mainly reflect answer readiness rather than reasoning convergence: they may trigger before the model has finished exploring or self-correcting, causing premature exits that can degrade final-answer accuracy and leave the retained reasoning chain semantically incomplete. We identify reasoning-level semantic redundancy as a complementary signal for semantic-preserving early exit: when successive steps no longer add novel progress and instead revisit established conclusions, the reasoning trajectory has likely converged. Building on this insight, we propose PUMA, a plug-and-play framework that combines a lightweight Redundancy Detector with answer-level verification. The detector flags semantically redundant candidate exits, while verification confirms whether stopping is safe, allowing PUMA to remove redundant continuation while preserving both answer accuracy and a coherent reasoning prefix. Across five LRMs and five challenging reasoning benchmarks, PUMA achieves 26.2% average token reduction while preserving accuracy and retained CoT quality. Additional experiments on code generation, zero-shot vision-language reasoning, and learned stopping-policy internalization further demonstrate that reasoning-level redundancy is a robust, transferable, and learnable signal for efficient reasoning. Our code is available at \url{https://github.com/giovanni-vaccarino/PUMA}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PUMA, a plug-and-play early-exit framework for large reasoning models that detects semantic redundancy between successive CoT steps via a lightweight Redundancy Detector and combines it with answer-level verification to stop generation once the trajectory has converged. The central empirical claim is that this yields a 26.2% average token reduction across five LRMs and five reasoning benchmarks while preserving final-answer accuracy and the semantic quality of the retained reasoning prefix; additional results on code generation, zero-shot vision-language tasks, and learned stopping policies are presented to argue that the redundancy signal is robust and transferable.
Significance. If the core assumption holds, the work provides a practical, reasoning-level complement to existing answer-level early-exit techniques and could meaningfully lower inference cost and latency for overthinking-prone LRMs. The reported token savings are substantial, the plug-and-play design lowers adoption barriers, and the code release supports reproducibility. The extension to non-reasoning tasks broadens the potential impact beyond the primary benchmarks.
major comments (2)
- [Experiments] The central claim that semantic redundancy reliably signals convergence without discarding necessary later self-corrections rests on the Redundancy Detector plus verification pipeline. The manuscript should include a targeted error analysis (e.g., in the Experiments section) of cases where high embedding similarity between steps nevertheless masks incremental logical fixes or exploration that alters the final answer; without such analysis the 26.2% token-reduction figure risks understating accuracy risk on the five benchmarks.
- [Method] Implementation details of the Redundancy Detector (embedding model, similarity metric, step granularity, and threshold selection procedure) are load-bearing for the method's claimed robustness. These choices should be stated explicitly with sensitivity analysis, because small changes in threshold or granularity could alter when redundancy is flagged relative to actual reasoning convergence.
minor comments (2)
- [Abstract] The abstract states aggregate token savings and accuracy preservation but does not name the specific baselines or verification thresholds used; adding one sentence would improve clarity for readers.
- [Figures/Tables] Figure captions and table footnotes should explicitly define the CoT-quality metric used to claim that retained reasoning remains coherent.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We address each major comment below and have made revisions to strengthen the empirical support and methodological transparency of the manuscript.
read point-by-point responses
-
Referee: [Experiments] The central claim that semantic redundancy reliably signals convergence without discarding necessary later self-corrections rests on the Redundancy Detector plus verification pipeline. The manuscript should include a targeted error analysis (e.g., in the Experiments section) of cases where high embedding similarity between steps nevertheless masks incremental logical fixes or exploration that alters the final answer; without such analysis the 26.2% token-reduction figure risks understating accuracy risk on the five benchmarks.
Authors: We agree that a targeted error analysis is valuable for substantiating the central claim. In the revised manuscript we have added Section 4.4, which presents a manual inspection of 150 sampled trajectories across the five benchmarks where the Redundancy Detector reported high similarity yet later steps were produced. We categorize outcomes into (i) cases where verification correctly blocked exit because the final answer changed (87% of samples), (ii) cases where later steps contained only stylistic rephrasing with no answer change, and (iii) rare cases of genuine logical refinement. We report that the verification step prevented accuracy degradation in all but two instances, and we include representative examples in the new section. This analysis supports that the reported 26.2% token reduction does not understate accuracy risk. revision: yes
-
Referee: [Method] Implementation details of the Redundancy Detector (embedding model, similarity metric, step granularity, and threshold selection procedure) are load-bearing for the method's claimed robustness. These choices should be stated explicitly with sensitivity analysis, because small changes in threshold or granularity could alter when redundancy is flagged relative to actual reasoning convergence.
Authors: We concur that explicit details and sensitivity analysis improve reproducibility and demonstrate robustness. Section 3.2 has been expanded to state that the Redundancy Detector uses the all-MiniLM-L6-v2 embedding model, cosine similarity on sentence-level embeddings, sentence granularity within each CoT step, and a threshold of 0.85 chosen via grid search on a 200-example validation split of GSM8K to keep accuracy within 1% of full CoT while maximizing token savings. A new Appendix C now contains sensitivity plots varying the threshold from 0.70 to 0.95 and comparing sentence versus full-step granularity; token reduction remains between 22% and 29% with accuracy variation below 1.2% across all settings. These results confirm stability of the reported gains. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces PUMA as a plug-and-play framework using a Redundancy Detector on semantic similarity between CoT steps plus answer-level verification. No equations or derivations reduce a claimed prediction to a fitted parameter by construction, nor does any load-bearing premise rest on self-citation chains or imported uniqueness theorems. The central insight (semantic redundancy signals convergence) is presented as an empirical observation, with performance claims (26.2% token reduction) tied to external benchmarks rather than internal redefinitions. This matches the default expectation of an independent method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic redundancy between successive reasoning steps indicates that the reasoning trajectory has converged.
invented entities (1)
-
Redundancy Detector
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
PUMA scores the redundancy of step rt by comparing it with the previous k reasoning steps: s(k)t = max cos(f(rj), f(rt)) ... flags rt as a candidate exit when s(k)t > τsim
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
fine-tune Qwen3-Embedding-0.6B with a contrastive objective to distinguish steps that introduce new logical or semantic progress from those that merely restate
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645(8081):633–638, 2025
work page 2025
-
[2]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 24824–24837. Curran Assoc...
work page 2022
-
[4]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Candes, and Tatsunori Hashimoto. s1: Simple test-time scaling. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Lan...
-
[5]
URLhttps://aclanthology.org/2025.emnlp-main.1025/
work page 2025
-
[6]
Towards thinking-optimal scaling of test- time compute for LLM reasoning
Wenkai Yang, Shuming Ma, Yankai Lin, and Furu Wei. Towards thinking-optimal scaling of test- time compute for LLM reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=6ICFqmixlS
work page 2026
-
[7]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[9]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Jiaxuan Gao, Shu Yan, Qixin Tan, lu Yang, Shusheng Xu, Wei Fu, Zhiyu Mei, Kaifeng Lyu, and Yi Wu. How far are we from optimal reasoning efficiency? InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=NhAi1w3s8Z
work page 2026
-
[11]
Tl;dr: Too long, do re-weighting for efficient llm reasoning compression, 2025
Zhong-Zhi Li, Xiao Liang, Zihao Tang, Lei Ji, Peijie Wang, Haotian Xu, Xing W, Haizhen Huang, Weiwei Deng, Yeyun Gong, Zhijiang Guo, Xiao Liu, Fei Yin, and Cheng-Lin Liu. Tl;dr: Too long, do re-weighting for efficient llm reasoning compression, 2025. URLhttps: //arxiv.org/abs/2506.02678
-
[12]
Language agent tree search unifies reasoning, acting, and planning in language models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. In Proceedings of the 41st International Conference on Machine Learning, ICML’24. JMLR.org, 2024. 10
work page 2024
-
[13]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview. net/forum?id=WE_vluYUL-X
work page 2023
-
[14]
Group think: Multiple concurrent reasoning agents collaborating at token level granularity, 2025
Chan-Jan Hsu, Davide Buffelli, Jamie McGowan, Feng-Ting Liao, Yi-Chang Chen, Sattar Vakili, and Da shan Shiu. Group think: Multiple concurrent reasoning agents collaborating at token level granularity, 2025. URLhttps://arxiv.org/abs/2505.11107
-
[15]
Yu Li, Guangfeng Cai, Shengtian Yang, Han Luo, Shuo Han, Xu He, Dong Li, and Lei Feng. Phgpo: Pheromone-guided policy optimization for long-horizon tool planning.arXiv preprint arXiv:2602.13691, 2026
-
[16]
LLM-Based Human-Agent Collaboration and Interaction Systems: A Survey
Henry Peng Zou, Wei-Chieh Huang, Yaozu Wu, Yankai Chen, Chunyu Miao, Hoang Nguyen, Yue Zhou, Weizhi Zhang, Liancheng Fang, Langzhou He, et al. Llm-based human-agent collaboration and interaction systems: A survey.arXiv preprint arXiv:2505.00753, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Do NOT think that much for 2+3=? on the overthinking of long reasoning models
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Do NOT think that much for 2+3=? on the overthinking of long reasoning models. InForty-second International Conference on Machine Learning, 2025. URL https://openreview.net/ forum?id=...
work page 2025
-
[18]
Renliang Sun, Wei Cheng, Dawei Li, Haifeng Chen, and Wei Wang. Stop when enough: Adaptive early-stopping for chain-of-thought reasoning.arXiv preprint arXiv:2510.10103, 2025
-
[19]
LightThinker: Thinking step-by-step compression
Jintian Zhang, Yuqi Zhu, Mengshu Sun, Yujie Luo, Shuofei Qiao, Lun Du, Da Zheng, Huajun Chen, and Ningyu Zhang. LightThinker: Thinking step-by-step compression. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13307– 1332...
-
[20]
Training language models to reason efficiently
Daman Arora and Andrea Zanette. Training language models to reason efficiently. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps: //openreview.net/forum?id=AiZxn84Wdo
work page 2025
-
[21]
O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning
Haotian Luo, Li Shen, Haiying He, Yibo Wang, Shiwei Liu, Wei Li, Naiqiang Tan, Xiaochun Cao, and Dacheng Tao. O1-pruner: Length-harmonizing fine-tuning for o1-like reasoning pruning. In2nd AI for Math Workshop @ ICML 2025, 2025. URL https://openreview. net/forum?id=ioYybCRcyW
work page 2025
-
[22]
C3ot: Generating shorter chain-of- thought without compromising effectiveness
Yu Kang, Xianghui Sun, Liangyu Chen, and Wei Zou. C3ot: Generating shorter chain-of- thought without compromising effectiveness. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24312–24320, 2025
work page 2025
-
[23]
CoT-valve: Length-compressible chain-of-thought tuning
Xinyin Ma, Guangnian Wan, Runpeng Yu, Gongfan Fang, and Xinchao Wang. CoT-valve: Length-compressible chain-of-thought tuning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 6025–6035, Vienna, Austr...
-
[24]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
arXiv preprint arXiv:2502.18600 , year=
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025. 11
-
[26]
Plan and budget: Effective and efficient test-time scaling on reasoning large language models
Junhong Lin, Xinyue Zeng, Jie Zhu, Song Wang, Julian Shun, Jun Wu, and Dawei Zhou. Plan and budget: Effective and efficient test-time scaling on reasoning large language models. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=ctspw4CqbS
work page 2026
-
[27]
Sania Nayab, Giulio Rossolini, Marco Simoni, Andrea Saracino, Giorgio Buttazzo, Nicolamaria Manes, and Fabrizio Giacomelli. Concise thoughts: Impact of output length on llm reasoning and cost.arXiv preprint arXiv:2407.19825, 2024
-
[28]
Token-budget-aware LLM reasoning
Tingxu Han, Zhenting Wang, Chunrong Fang, Shiyu Zhao, Shiqing Ma, and Zhenyu Chen. Token-budget-aware LLM reasoning. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 24842–24855, Vienna, Austria, July 2025. Association for Computational Lingui...
-
[29]
Confidence-coverage gating for early exit
Aaroosh Rustagi, Hsien Xin Peng, Khushal Murthy, Attrey Koul, Ryan Lagasse, and Kevin Zhu. Confidence-coverage gating for early exit. InNeurIPS 2025 Workshop on Efficient Reasoning,
work page 2025
-
[30]
URLhttps://openreview.net/forum?id=Ay7sRmWswq
-
[31]
Efficient test-time scaling via self-calibration
Chengsong Huang, Langlin Huang, Jixuan Leng, Jiacheng Liu, and Jiaxin Huang. Efficient test-time scaling via self-calibration. InNeurIPS 2025 Workshop on Efficient Reasoning, 2025. URLhttps://openreview.net/forum?id=RvMjxGpVOa
work page 2025
-
[32]
Early Stopping Chain-of-thoughts in Large Language Models
Minjia Mao, Bowen Yin, Yu Zhu, and Xiao Fang. Early stopping chain-of-thoughts in large language models.arXiv preprint arXiv:2509.14004, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Entropy After </Think> for reasoning model early exiting
Xi Wang, James McInerney, Lequn Wang, and Nathan Kallus. Entropy after {/Think} for reasoning model early exiting.arXiv preprint arXiv:2509.26522, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Dynamic early exit in reasoning models
Chenxu Yang, Qingyi Si, Yongjie Duan, Zheliang Zhu, Chenyu Zhu, Qiaowei Li, Minghui Chen, Zheng Lin, and Weiping Wang. Dynamic early exit in reasoning models. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=NpU7ZXafRi
work page 2026
-
[35]
Reasoning without self-doubt: More efficient chain-of-thought through certainty probing
Yichao Fu, Junda Chen, Yonghao Zhuang, Zheyu Fu, Ion Stoica, and Hao Zhang. Reasoning without self-doubt: More efficient chain-of-thought through certainty probing. InICLR 2025 Workshop on Foundation Models in the Wild, 2025. URLhttps://openreview.net/forum? id=wpK4IMJfdX
work page 2025
-
[36]
Efficient reasoning for large reasoning language models via certainty-guided reflection suppression
Jiameng Huang, Baijiong Lin, Guhao Feng, Jierun Chen, Di He, and Lu Hou. Efficient reasoning for large reasoning language models via certainty-guided reflection suppression. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31176–31184, 2026
work page 2026
-
[37]
Answer convergence as a signal for early stopping in reasoning
Xin Liu and Lu Wang. Answer convergence as a signal for early stopping in reasoning. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, edi- tors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Pro- cessing, pages 17896–17907, Suzhou, China, November 2025. Association for Computa- tional Linguist...
-
[38]
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=VD-AYtP0dve
work page 2023
-
[39]
Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. Detecting hallucinations in large language models using semantic entropy.Nature, 630(8017):625–630, 2024
work page 2024
-
[40]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embed- ding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Akhiad Bercovich, Itay Levy, Izik Golan, Mohammad Dabbah, Ran El-Yaniv, Omri Puny, Ido Galil, Zach Moshe, Tomer Ronen, Najeeb Nabwani, Ido Shahaf, Oren Tropp, Ehud Karpas, Ran Zilberstein, Jiaqi Zeng, Soumye Singhal, Alexander Bukharin, Yian Zhang, Tugrul Konuk, Ger- ald Shen, Ameya Sunil Mahabaleshwarkar, Bilal Kartal, Yoshi Suhara, Olivier Delalleau, Zi...
-
[43]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. URLhttps://openreview.net/forum?id=7Bywt2mQsCe
work page 2021
-
[44]
American invitational mathematics examination (aime) 2024, 2024
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2024, 2024
work page 2024
-
[45]
American invitational mathematics examination (aime) 2025, 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (aime) 2025, 2025
work page 2025
-
[46]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilin- gual multimodal scientific problems. In Lun-Wei Ku, Andre Martins, and Vivek Sriku- mar, editors,Proceedin...
-
[47]
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.211. URL https://aclanthology.org/2024.acl-long.211/
-
[48]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
work page 2024
-
[49]
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, Hanjie Chen, and Xia Hu. Stop overthinking: A survey on efficient reasoning for large language models.Transactions on Machine Learning Re- search, 2025. ISSN 2835-8856. URLhttps://openreview.net/forum?id=HvoG8SxggZ
work page 2025
-
[50]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms.arXiv preprint arXiv:2505.00127, 2025. 13
-
[51]
Does thinking more always help? mirage of test-time scaling in reasoning models
Soumya Suvra Ghosal, Souradip Chakraborty, Avinash Reddy, Yifu Lu, Mengdi Wang, Dinesh Manocha, Furong Huang, Mohammad Ghavamzadeh, and Amrit Singh Bedi. Does thinking more always help? mirage of test-time scaling in reasoning models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=...
work page 2026
-
[52]
When more is less: Understanding chain-of-thought length in LLMs
Yuyang Wu, Yifei Wang, Tianqi Du, Stefanie Jegelka, and Yisen Wang. When more is less: Understanding chain-of-thought length in LLMs. InWorkshop on Reasoning and Planning for Large Language Models, 2025. URLhttps://openreview.net/forum?id=W8dxn7hBkO
work page 2025
-
[53]
The evolution of thought: Tracking llm overthinking via reasoning dynamics analysis, 2026
Zihao Wei, Liang Pang, Jiahao Liu, Wenjie Shi, Jingcheng Deng, Shicheng Xu, Zenghao Duan, Fei Sun, Huawei Shen, and Xueqi Cheng. The evolution of thought: Tracking llm overthinking via reasoning dynamics analysis, 2026. URLhttps://arxiv.org/abs/2508.17627
-
[54]
L1: Controlling how long a reasoning model thinks with reinforcement learning
Pranjal Aggarwal and Sean Welleck. L1: Controlling how long a reasoning model thinks with reinforcement learning. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=4jdIxXBNve
work page 2025
-
[55]
Bairu Hou, Yang Zhang, Jiabao Ji, Yujian Liu, Kaizhi Qian, Jacob Andreas, and Shiyu Chang. Thinkprune: Pruning long chain-of-thought of LLMs via reinforcement learning.Transactions on Machine Learning Research, 2026. ISSN 2835-8856. URL https://openreview.net/ forum?id=V51gPu1uQD
work page 2026
-
[56]
S-GRPO: Early exit via reinforcement learning in reasoning models
Mz Dai, Chenxu Yang, and Qingyi Si. S-GRPO: Early exit via reinforcement learning in reasoning models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=wNMK5o0Vfg
work page 2026
-
[57]
Making slow thinking faster: Compressing LLM chain-of-thought via step entropy
Zeju Li, Jianyuan Zhong, Ziyang Zheng, Xiangyu Wen, Zhijian Xu, Yingying Cheng, Fan Zhang, and Qiang Xu. Making slow thinking faster: Compressing LLM chain-of-thought via step entropy. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=cGLqQfS5wH
work page 2026
-
[58]
Training large language models to reason in a continuous latent space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason E Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= Itxz7S4Ip3
work page 2025
-
[59]
Semcot: Accelerating chain-of-thought reasoning through semantically-aligned implicit tokens
Yinhan He, Wendy Zheng, Yaochen Zhu, Zaiyi Zheng, Lin Su, Sriram Vasudevan, Qi Guo, Liangjie Hong, and Jundong Li. Semcot: Accelerating chain-of-thought reasoning through semantically-aligned implicit tokens. InThe Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems, 2025. URLhttps://openreview.net/forum?id=1ZuzFUMtx6
work page 2025
-
[60]
LIMO: Less is more for reasoning
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. LIMO: Less is more for reasoning. InSecond Conference on Language Modeling, 2025. URL https: //openreview.net/forum?id=T2TZ0RY4Zk
work page 2025
-
[61]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, YuYue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao ...
work page 2026
-
[62]
Lee, Wen Sun, Wenhao Zhan, and Xuezhou Zhang
Kianté Brantley, Mingyu Chen, Zhaolin Gao, Jason D. Lee, Wen Sun, Wenhao Zhan, and Xuezhou Zhang. Accelerating RL for LLM reasoning with optimal advantage regression. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=T1V8BJO0iG
work page 2026
-
[63]
The benefits of a concise chain of thought on problem-solving in large language models
Matthew Renze and Erhan Guven. The benefits of a concise chain of thought on problem-solving in large language models. In2024 2nd International Conference on Foundation and Large Language Models (FLLM), pages 476–483, 2024. doi: 10.1109/FLLM63129.2024.10852493. 14
-
[64]
Ye Yu, Yaoning Yu, Haibo Jin, and Haohan Wang. PREMISE: Scalable and strategic prompt optimization for efficient mathematical reasoning in large reasoning models. InNeurIPS 2025 Workshop on Efficient Reasoning, 2025. URLhttps://openreview.net/forum?id= 8mI3i9LXj3
work page 2025
-
[65]
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URLhttps: //ope...
work page 2023
-
[66]
Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URLhttps://openreview.net/forum?id=lyaHnHDdZl
work page 2025
-
[67]
Adam Tauman Kalai and Santosh S. Vempala. Calibrated language models must halluci- nate. InProceedings of the 56th Annual ACM Symposium on Theory of Computing, STOC 2024, page 160–171, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400703836. doi: 10.1145/3618260.3649777. URL https://doi.org/10.1145/ 3618260.3649777
-
[68]
NEAT: Neuron-Based Early Exit for Large Reasoning Models
Kang Liu, Yongkang Liu, Xiaocui Yang, Peidong Wang, Wen Zhang, Shi Feng, Yifei Zhang, and Daling Wang. Neat: Neuron-based early exit for large reasoning models.arXiv preprint arXiv:2602.02010, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[69]
Wait, we don’t need to “wait”! removing thinking tokens improves reasoning efficiency
Chenlong Wang, Yuanning Feng, Dongping Chen, Zhaoyang Chu, Ranjay Krishna, and Tianyi Zhou. Wait, we don’t need to “wait”! removing thinking tokens improves reasoning efficiency. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Findings of the Association for Computational Linguistics: EMNLP 2025, pages 7459–7482...
-
[70]
Ömer Faruk Akgül, Yusuf Hakan Kalaycı, Rajgopal Kannan, Willie Neiswanger, and Viktor Prasanna. Lynx: Learning dynamic exits for confidence-controlled reasoning.arXiv preprint arXiv:2512.05325, 2025
-
[71]
Rea- soning models know when they’re right: Probing hidden states for self-verification
Anqi Zhang, Yulin Chen, Jane Pan, Chen Zhao, Aurojit Panda, Jinyang Li, and He He. Rea- soning models know when they’re right: Probing hidden states for self-verification. InSecond Conference on Language Modeling, 2025. URL https://openreview.net/forum?id= O6I0Av7683
work page 2025
-
[72]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview. net/forum?id=nZeVKeeFYf9
work page 2022
-
[73]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machin...
work page 2021
-
[74]
Bill MacCartney.Natural language inference. Stanford University, 2009
work page 2009
-
[75]
Reasoning models can be effective without thinking.arXiv preprint arXiv:2504.09858, 2025
Wenjie Ma, Jingxuan He, Charlie Snell, Tyler Griggs, Sewon Min, and Matei Zaharia. Reasoning models can be effective without thinking.arXiv preprint arXiv:2504.09858, 2025
-
[76]
From generation to judgment: Opportunities and challenges of LLM-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, Kai Shu, Lu Cheng, and Huan Liu. From generation to judgment: Opportunities and challenges of LLM-as-a-judge. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings...
-
[77]
Mateval: a multi-agent discussion framework for advancing open-ended text evaluation
Yu Li, Shenyu Zhang, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, Guilin Qi, and Dehai Min. Mateval: a multi-agent discussion framework for advancing open-ended text evaluation. InInternational Conference on Database Systems for Advanced Applications, pages 415–426. Springer, 2024
work page 2024
-
[78]
Dee: Dual-stage explainable evaluation method for text generation
Shenyu Zhang, Yu Li, Rui Wu, Xiutian Huang, Yongrui Chen, Wenhao Xu, and Guilin Qi. Dee: Dual-stage explainable evaluation method for text generation. InInternational Conference on Database Systems for Advanced Applications, pages 390–401. Springer, 2024
work page 2024
-
[79]
How to configure good in-context sequence for visual question answering
Li Li, Jiawei Peng, Huiyi Chen, Chongyang Gao, and Xu Yang. How to configure good in-context sequence for visual question answering. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26710–26720, June 2024
work page 2024
-
[80]
MVI-Bench: A Comprehensive Benchmark for Evaluating Robustness to Misleading Visual Inputs in LVLMs
Huiyi Chen, Jiawei Peng, Dehai Min, Changchang Sun, Kaijie Chen, Yan Yan, Xu Yang, and Lu Cheng. Mvi-bench: A comprehensive benchmark for evaluating robustness to misleading visual inputs in lvlms.arXiv preprint arXiv:2511.14159, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.