Architecture Dependent Temporal Observability Under Deployment Interference in Edge Inference Systems
Pith reviewed 2026-05-19 22:01 UTC · model grok-4.3
The pith
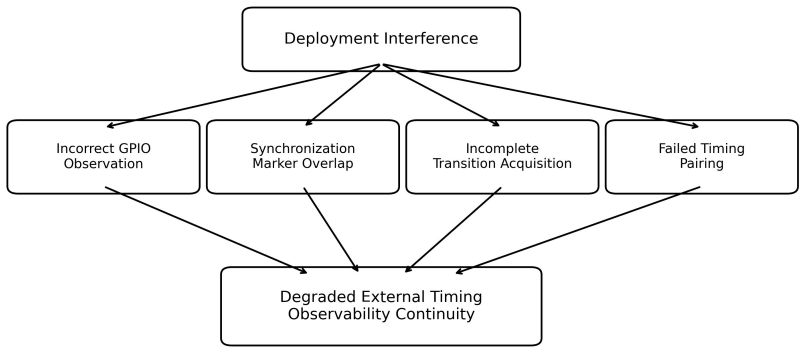
Deployment interference can corrupt both inference timing and the software that measures it, independently.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
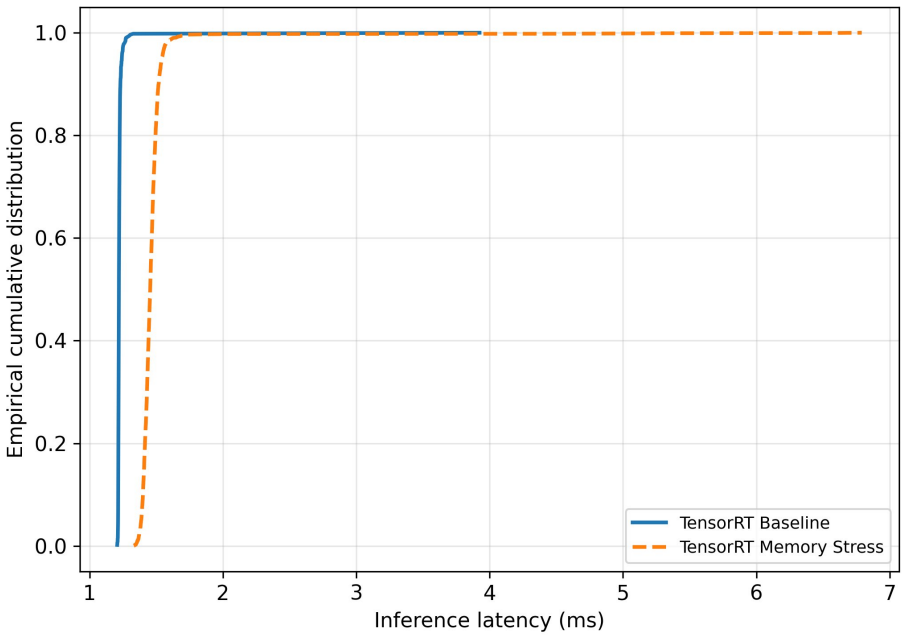
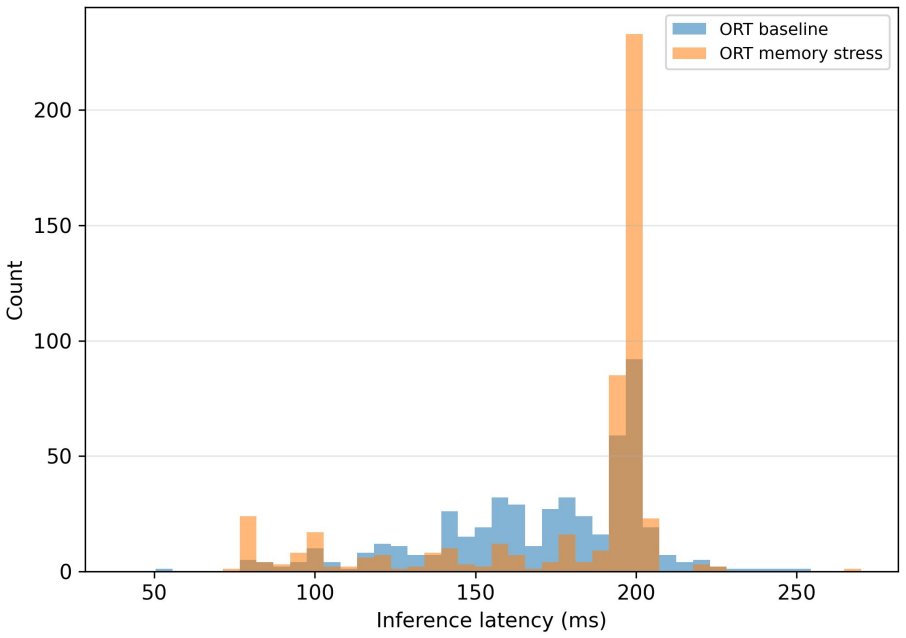
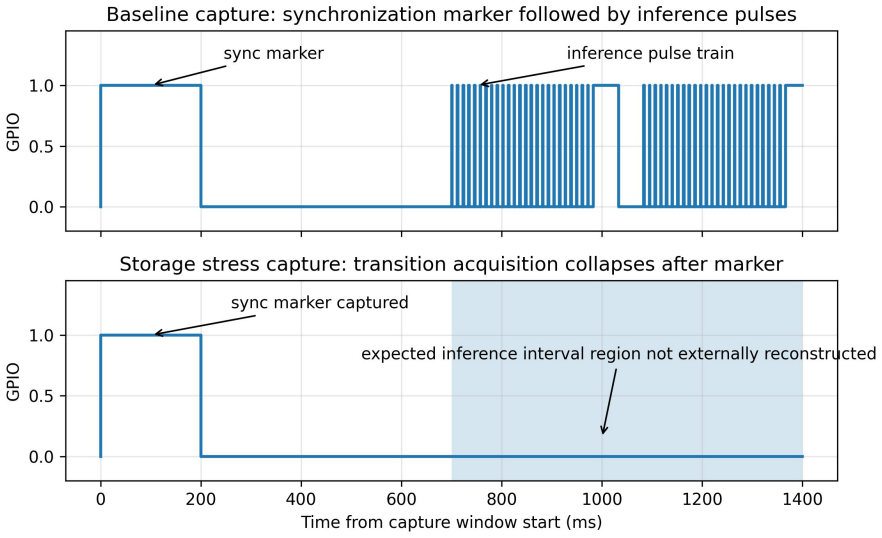
Timing observability is itself an interference-sensitive resource, and summary statistics from a single timing source can hide failure modes an independent external observer makes visible. In 35 paired runs, TensorRT baselines cluster tightly while ONNX Runtime baselines are multimodal; memory pressure inflates TensorRT P99 and collapses one ONNX run into a fixed 198 ms regime; storage stress produces complete software logs alongside three distinct external timing failures that the runtime never reports.
What carries the argument
Paired comparison of software-reported inference timing against external GPIO interval captures from a Saleae Logic Pro 8 logic analyzer on NVIDIA Jetson Orin Nano.
If this is right
- Software-only latency summaries are insufficient to certify correct behavior under realistic deployment interference.
- TensorRT and ONNX Runtime respond to the same stresses with qualitatively different timing structures, so architecture-specific observability checks are required.
- Complete software logs can coexist with total external timing loss, meaning runtime success reports alone do not guarantee observable execution.
- Light memory pressure and storage writeback each surface distinct hidden failure modes that internal metrics miss.
Where Pith is reading between the lines
- Production edge deployments may need independent hardware timing channels as a standard safeguard rather than optional diagnostics.
- Benchmark suites that rely solely on internal timers risk publishing optimistic results that do not survive contact with real interference.
- The same independence between reported and observed timing could appear in other monitoring layers such as network or power telemetry.
Load-bearing premise
The logic analyzer's GPIO captures supply a reliable external ground truth unaffected by the deployment stresses that corrupt software timing reports.
What would settle it
A replication under storage or memory stress in which every external GPIO interval exactly matches the corresponding software-reported latency with no missing transitions, no fixed-regime collapses, and no acquisition failures.
Figures



read the original abstract
Edge inference systems are typically evaluated with software-reported latency collected under controlled conditions. We argue, and demonstrate empirically, that deployment interference can corrupt not only the inference timing being measured but the timing observability infrastructure that measures it, and that the two failures can occur independently. We pair software-reported timing with externally observable GPIO intervals captured by a Saleae Logic Pro 8 logic analyzer on an NVIDIA Jetson Orin Nano, running MobileNetV2 under two inference architectures (TensorRT FP16 GPU and ONNX Runtime CPU) across baseline, light memory pressure, and storage writeback stress. Across 35 paired capture runs (3500 samples) plus 3 storage-stress runs where external pairing failed (300 software-only samples), we observe three findings the software-only view does not surface. (1) The two architectures differ not only in mean latency but in distributional structure: TensorRT baseline clusters tightly near 1.23 ms (run-mean SD 15 us) while ORT CPU baseline is multimodal with run-mean SD 31.8 ms. (2) Light memory pressure inflates TensorRT P99 from 1.28 ms to 1.61 ms, while one of five ORT memory-stress runs collapses into a deterministic 198 ms regime rather than uniformly inflating variance. (3) All three TensorRT storage-stress runs produce complete software timing logs (100/100 iterations) alongside externally observable timing failures of three different kinds (full post-marker collapse, ~40% transition loss, and complete acquisition failure) -- while the runtime reports normal completion in every case. We claim, narrowly, that timing observability is itself an interference-sensitive resource, and that summary statistics from a single timing source can hide failure modes an independent external observer makes visible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript empirically demonstrates that deployment interference in edge inference systems can corrupt timing observability independently of the inference timing itself. On an NVIDIA Jetson Orin Nano running MobileNetV2 under TensorRT FP16 GPU and ONNX Runtime CPU architectures, the authors pair software-reported latency with external GPIO interval captures from a Saleae Logic Pro 8 logic analyzer across baseline, light memory pressure, and storage writeback conditions. From 35 paired runs (3500 samples) and 3 additional storage-stress runs (300 software-only samples), they report three findings invisible to software-only views: (1) architecture-dependent distributional structure in baseline latency, (2) non-uniform effects of memory pressure including a deterministic collapse in one ORT run, and (3) complete software timing logs (100/100 iterations) alongside three distinct external failure modes (post-marker collapse, ~40% transition loss, acquisition failure) under storage stress.
Significance. If the central empirical observations hold, the work provides concrete evidence that single-source software timing metrics can mask interference-induced observability failures in edge systems, with direct implications for reliable benchmarking and monitoring of deployed inference. The study is strengthened by its use of paired captures, explicit sample counts, and identification of multiple distinct external failure modes rather than relying on fitted models or self-referential predictions.
major comments (2)
- [Experimental methodology (storage-stress runs)] Experimental methodology (storage-stress runs description): the claim that external GPIO intervals constitute an independent, uncorrupted ground truth is load-bearing for the central finding that software reports normal completion while external captures reveal failures. No control isolating the capture path (e.g., non-inference GPIO toggles under identical storage writeback) is described, leaving open the possibility that USB bus contention or GPIO controller delays on the Jetson could induce correlated artifacts in the Saleae captures rather than revealing independent observability corruption.
- [Results (storage-stress runs)] Results on storage-stress runs (the three distinct external failure modes): while the paper reports complete software logs alongside external failures in all three TensorRT runs, the absence of statistical tests or controls for confounding variables (as noted in the abstract's sample counts) weakens the support for the claim that these are distinct, interference-specific failure modes rather than artifacts of the measurement pairing.
minor comments (2)
- [Abstract] The abstract states 'three distinct findings' but the numbering and separation of the architecture-dependent distributional structure from the memory-pressure effects could be clarified for readability.
- [Abstract] Notation for run-mean SD (e.g., 'run-mean SD 15 us') is used without explicit definition of how runs are aggregated versus individual iteration statistics.
Simulated Author's Rebuttal
We thank the referee for their insightful and constructive comments on our manuscript. We address each of the major comments below and indicate the revisions we will make to improve the clarity and rigor of our empirical claims.
read point-by-point responses
-
Referee: Experimental methodology (storage-stress runs description): the claim that external GPIO intervals constitute an independent, uncorrupted ground truth is load-bearing for the central finding that software reports normal completion while external captures reveal failures. No control isolating the capture path (e.g., non-inference GPIO toggles under identical storage writeback) is described, leaving open the possibility that USB bus contention or GPIO controller delays on the Jetson could induce correlated artifacts in the Saleae captures rather than revealing independent observability corruption.
Authors: We agree that this is an important methodological point. Although our paired measurements in baseline and memory pressure conditions showed no evidence of capture artifacts, we did not explicitly test the GPIO/Saleae path in isolation under storage writeback. In the revised manuscript, we will include a control experiment with non-inference GPIO toggles under the same storage stress conditions to confirm that the external captures remain reliable and independent of the inference workload. revision: yes
-
Referee: Results on storage-stress runs (the three distinct external failure modes): while the paper reports complete software logs alongside external failures in all three TensorRT runs, the absence of statistical tests or controls for confounding variables (as noted in the abstract's sample counts) weakens the support for the claim that these are distinct, interference-specific failure modes rather than artifacts of the measurement pairing.
Authors: The three failure modes are presented as qualitatively distinct based on direct observation of the external capture traces across the three independent runs. We acknowledge that with only three runs and no formal statistical tests, the evidence for distinct modes is primarily descriptive. We will revise the manuscript to provide additional quantitative characterization of each mode (e.g., transition counts and timing deviations where measurable), explicitly discuss the small sample size as a limitation, and note that these observations are exploratory. This will better contextualize the findings without overstating their statistical support. revision: partial
Circularity Check
No circularity: purely empirical observations with no derivations or self-referential predictions
full rationale
The paper reports direct experimental comparisons of software-reported inference latencies against external GPIO interval captures under controlled interference conditions on a Jetson platform. No equations, fitted parameters, predictions, or derivation chains appear in the provided text. All claims rest on observed discrepancies across 35 paired runs and additional stress cases, with the central argument being that a single timing source can miss failure modes visible to an independent observer. This structure is self-contained against external benchmarks and contains none of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Saleae Logic Pro 8 GPIO captures provide an accurate independent timing reference unaffected by the software stack or deployment stress.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We pair software-reported timing with externally observable GPIO intervals captured by a Saleae Logic Pro 8 logic analyzer... three distinct external failure modes (post-marker collapse, ~40% transition loss, acquisition failure)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
timing observability is itself an interference-sensitive resource
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Malony, Allen D. and Reed, Daniel A. and Wijshoff, Harry A. G. , title =. IEEE Transactions on Parallel and Distributed Systems , volume =
- [2]
-
[3]
IEEE International Parallel and Distributed Processing Symposium , year =
Mytkowicz, Todd and Diwan, Amer and Hauswirth, Matthias , title =. IEEE International Parallel and Distributed Processing Symposium , year =
-
[4]
Ratul, I. J. and Zhou, Y. and Yang, K. , title =. Electronics , volume =
-
[5]
V. Don't Buy the Pig in a Poke: Benchmarking DNNs Inference Performance before Development , booktitle =
-
[6]
ACM Transactions on Embedded Computing Systems , volume =
Jeong, Eunjin and Kim, Jangryul and Ha, Soonhoi , title =. ACM Transactions on Embedded Computing Systems , volume =
-
[7]
Jeong, Eunjin and Kim, Jangryul and Tan, S. and Lee, J. and Ha, Soonhoi , title =. IEEE Embedded Systems Letters , volume =
- [8]
-
[9]
Fundamental Issues in Testing Distributed Real-Time Systems , journal =
Sch. Fundamental Issues in Testing Distributed Real-Time Systems , journal =
-
[10]
Proceedings of the ACM Applied Networking Research Workshop , year =
Mizrahi, Tal and Schapira, Michael and Moses, Yoram , title =. Proceedings of the ACM Applied Networking Research Workshop , year =
-
[11]
Per-Platform GPIO Overhead in Hardware-Validated Edge ML Inference Timing
Swami, Akul and Chougule, Nikhil , title =. 2026 , eprint =. doi:10.48550/arXiv.2605.02835 , note =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.02835 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.