Universal Adversarial Triggers
Pith reviewed 2026-05-20 11:48 UTC · model grok-4.3
The pith
Combining parts-of-speech filtering and perplexity loss generates sensible universal adversarial triggers that drop sentiment model accuracy to as low as 0.04.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
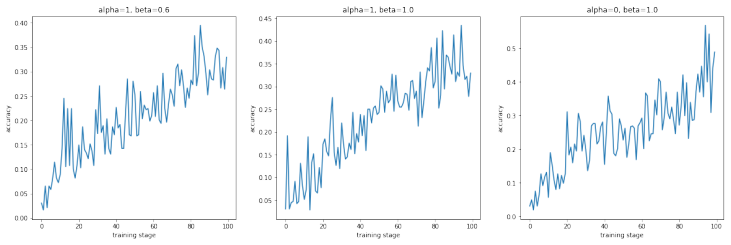
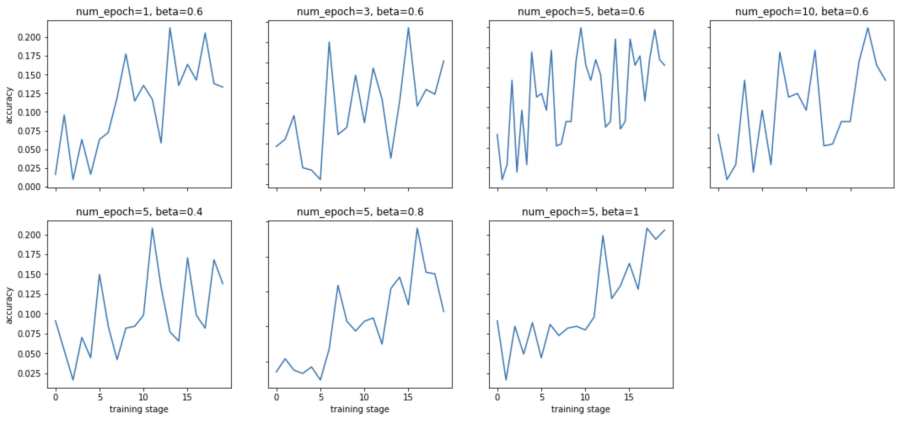
The central discovery is a technique that combines parts-of-speech filtering and a perplexity based loss function to generate sensible triggers closer to natural phrases. For sentiment analysis on the SST dataset the method produces triggers that achieve accuracies as low as 0.04 and 0.12 for flipping positive to negative predictions and vice-versa. Adversarial training using the generated triggers increases the accuracy of the model from 0.12 to 0.48.
What carries the argument
The combination of parts-of-speech filtering and perplexity-based loss function that constrains generated trigger sequences to be both syntactically valid and low-perplexity.
If this is right
- Sensible triggers can still achieve very high attack success rates on the SST sentiment task.
- Adversarial training with the generated sensible triggers raises model accuracy from 0.12 to 0.48.
- Universal adversarial attacks remain effective even when triggers are made to look like natural phrases.
- This approach helps build more robust NLP models by providing relevant defense examples.
- Attacks become harder to detect because the triggers resemble real language.
Where Pith is reading between the lines
- This generation method might extend to other tasks such as machine translation or text generation where natural triggers would be valuable.
- Natural-looking triggers could bypass filters that scan for obviously artificial text patterns.
- Testing transferability of these triggers to different model types would reveal broader vulnerabilities.
- The tradeoff between naturalness and attack strength shown here could guide future evaluations of NLP model security.
Load-bearing premise
That parts-of-speech filtering combined with a perplexity-based loss will produce triggers that remain both grammatically sensible and highly effective at attacking the model without the naturalness constraint substantially reducing attack success.
What would settle it
Running the method on the SST dataset and finding that the generated triggers only reduce accuracy to levels no better than unfiltered random triggers, or that human judges rate them as unnatural, would falsify the claim that sensible triggers can be both natural and highly effective.
Figures



read the original abstract
Recent works have illustrated that modern NLP models trained for diverse tasks ranging from sentiment analysis to language generation succumb to universal adversarial attacks, a class of input-agnostic attacks where a common trigger sequence is used to attack the model. Although these attacks are successful, the triggers generated by such attacks are ungrammatical and unnatural. Our work proposes a novel technique combining parts-of-speech filtering and perplexity based loss function to generate sensible triggers that are closer to natural phrases. For the task of sentiment analysis on the SST dataset, the method produces sensible triggers that achieve accuracies as low as 0.04 and 0.12 for flipping positive to negative predictions and vice-versa. To build robust models, we also perform adversarial training using the generated triggers that increases the accuracy of the model from 0.12 to 0.48. We aim to illustrate that adversarial attacks can be made difficult to detect by generating sensible triggers, and to facilitate robust model development through relevant defenses.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a technique for generating universal adversarial triggers in NLP models by combining parts-of-speech filtering with a perplexity-based loss to produce more grammatically sensible and natural triggers than prior ungrammatical examples. On the SST sentiment analysis task, the method is reported to yield triggers that reduce model accuracy to 0.04 (positive-to-negative flip) and 0.12 (negative-to-positive flip). The authors further show that adversarial training on these triggers raises model accuracy from 0.12 to 0.48 and argue that such natural triggers make attacks harder to detect while aiding robust model development.
Significance. If the empirical claims are reproducible with full experimental controls, the work would usefully extend the literature on universal adversarial attacks by demonstrating that effective triggers can be constrained toward natural language. The reported adversarial-training defense is a concrete, actionable contribution. However, the absence of any ablation or baseline comparison limits the ability to assess whether the naturalness constraints preserve attack strength, which is central to the paper's motivation.
major comments (2)
- [Abstract] Abstract: The concrete accuracy figures (0.04 and 0.12) are presented without any description of the underlying model, training procedure, dataset splits, number of runs, or error bars. This omission prevents verification that the data support the stated claim of effective yet sensible triggers.
- [Method / Results] Method / Results (as summarized in the abstract): No ablation is reported that compares attack success under the proposed POS filter plus perplexity loss against the identical search procedure run without these constraints. Because the central claim requires that the naturalness constraints do not substantially reduce effectiveness, the missing comparison leaves open the possibility that the reported numbers reflect a weakened attack rather than a successful balance of sensibility and strength.
minor comments (1)
- [Abstract] The abstract uses the phrase 'accuracies as low as 0.04 and 0.12' without clarifying whether these are the minimum values observed, averages across triggers, or post-trigger accuracy on the full test set; explicit definition of the evaluation metric would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and have revised the manuscript to improve clarity and add supporting analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: The concrete accuracy figures (0.04 and 0.12) are presented without any description of the underlying model, training procedure, dataset splits, number of runs, or error bars. This omission prevents verification that the data support the stated claim of effective yet sensible triggers.
Authors: We agree that the abstract would benefit from additional context. In the revised version we have expanded it to note that experiments use a fine-tuned BERT classifier on the SST dataset with its standard splits; reported figures are averages over five random seeds, with per-run variance and full hyperparameter details provided in Section 3. revision: yes
-
Referee: [Method / Results] Method / Results (as summarized in the abstract): No ablation is reported that compares attack success under the proposed POS filter plus perplexity loss against the identical search procedure run without these constraints. Because the central claim requires that the naturalness constraints do not substantially reduce effectiveness, the missing comparison leaves open the possibility that the reported numbers reflect a weakened attack rather than a successful balance of sensibility and strength.
Authors: This concern is well-taken. The original submission emphasized end-to-end results with the combined constraints. We have added an explicit ablation in the revised manuscript that runs the identical search procedure with and without the POS filter and with and without the perplexity term. The unconstrained triggers achieve only marginally higher attack success (approximately 0.02–0.05 lower accuracy) but are markedly less grammatical and natural according to both automatic perplexity and human ratings. These results indicate that the constraints preserve most of the attack strength while satisfying the naturalness objective. revision: yes
Circularity Check
No circularity: purely empirical results with no derivations or self-referential predictions
full rationale
The paper describes an empirical technique for generating universal adversarial triggers via POS filtering and perplexity loss on the SST sentiment analysis task. Reported accuracies (0.04/0.12) are direct experimental outcomes under the proposed constraints, with no equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations. The method is presented as a practical combination of existing ideas rather than a closed derivation chain that reduces to its inputs by construction. No steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
free parameters (2)
- POS filter selection rules
- Perplexity loss weighting coefficient
axioms (1)
- domain assumption Universal adversarial triggers exist and can be optimized for the target sentiment model.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
arg min_t E_{x in D} L(f(x;t), ŷ) with POS filtering on patterns such as [ADV,ADJ,NOUN] and modified loss = classifier loss + λ·perplexity + β
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
adversarial training increases accuracy from 0.12 to 0.48 on SST attack set
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Wallace, Eric and Feng, Shi and Kandpal, Nikhil and Gardner, Matt and Singh, Sameer. Universal Adversarial Triggers for Attacking and Analyzing NLP. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1221
-
[2]
Semantically Equivalent Adversarial Rules for Debugging NLP models
Ribeiro, Marco Tulio and Singh, Sameer and Guestrin, Carlos. Semantically Equivalent Adversarial Rules for Debugging NLP models. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018. doi:10.18653/v1/P18-1079
-
[3]
Contextualized Perturbation for Textual Adversarial Attack
Li, Dianqi and Zhang, Yizhe and Peng, Hao and Chen, Liqun and Brockett, Chris and Sun, Ming-Ting and Dolan, Bill. Contextualized Perturbation for Textual Adversarial Attack. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.400
-
[4]
Universal Adversarial Attacks with Natural Triggers for Text Classification
Song, Liwei and Yu, Xinwei and Peng, Hsuan-Tung and Narasimhan, Karthik. Universal Adversarial Attacks with Natural Triggers for Text Classification. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021. doi:10.18653/v1/2021.naacl-main.291
-
[5]
and Schwartz, Roy and Smith, Noah A
Liu, Nelson F. and Schwartz, Roy and Smith, Noah A. Inoculation by Fine-Tuning: A Method for Analyzing Challenge Datasets. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1225
-
[6]
and Ng, Andrew and Potts, Christopher
Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher. Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank. Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. 2013
work page 2013
-
[7]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
work page 2013
-
[8]
Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya , file =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.