Visualizing the Invisible: Generative Visual Grounding Empowers Universal EEG Understanding in MLLMs
Pith reviewed 2026-05-20 10:20 UTC · model grok-4.3
The pith
Generating proxy images from EEG signals lets MLLMs use visual priors to interpret brain activity more effectively than text alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
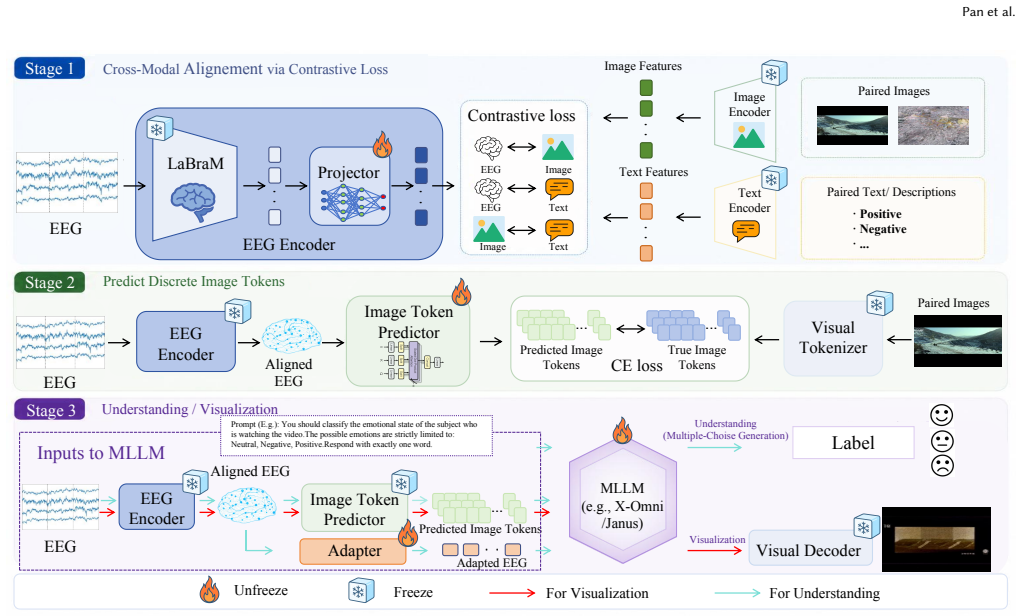
Generative Visual Grounding employs an EEG-to-image generative model as a visual translator to produce instance-specific proxy images for non-visual EEG. These proxies supply structured visual contexts that allow MLLMs to exploit their visual priors for clinical-state interpretation, delivering competitive results with image-only alignment and consistent improvements when extended to trimodal image-plus-text alignment.
What carries the argument
Generative Visual Grounding (GVG), the framework that uses an EEG-to-image generative model to create instance-specific proxy images serving as visual contexts for MLLM alignment.
If this is right
- Image-only alignment using the generated proxies matches the performance of larger text-aligned baselines while tuning only a small fraction of parameters on a frozen backbone.
- Trimodal alignment that adds the visual proxies to text supplies both categorical semantic anchors and perceptual details for richer neural representations.
- The method produces measurable gains in EEG understanding tasks as well as in visual generation from brain signals.
- Visual proxy grounding functions as a direct complement to textual alignment for building more capable EEG foundation models.
Where Pith is reading between the lines
- Similar proxy generation could extend visual grounding to other non-visual sensor data such as audio or wearable signals.
- The approach may support more interpretable brain-computer interfaces by linking raw neural activity to concrete visual outputs users can inspect.
- Testing whether the generated images recover specific perceptual experiences encoded in EEG would provide a direct check on information preservation.
- Combining this grounding with other modalities could produce more robust multimodal models for scarce brain-signal datasets.
Load-bearing premise
EEG-to-image generative models can accurately translate neural signals into meaningful visual representations that preserve fine-grained perceptual information without introducing misleading artifacts.
What would settle it
A controlled experiment showing that MLLMs achieve equal or lower accuracy on clinical-state prediction tasks when given the generated proxy images versus text-only alignments would falsify the central claim.
Figures


read the original abstract
Leveraging the universal representations of pre-trained LLMs and MLLMs offers a promising path toward brain foundation models. However, visually-evoked EEG datasets remain scarce, leading existing methods to align neural signals mainly with abstract text, a lossy translation that may discard fine-grained perceptual information encoded in brain activity. We propose Generative Visual Grounding (GVG), a framework that visualizes the invisible by using an EEG-to-image generative model as a visual translator. Instead of forcing EEG into text alone, GVG hallucinates instance-specific proxy images for non-visual EEG, providing structured visual contexts that allow MLLMs to exploit their visual priors for clinical-state interpretation. We validate this idea on two MLLM backbones, GVG-X-Omni and GVG-Janus. Image-only alignment is already competitive: the lightweight GVG-X-Omni matches 1.7B-parameter text-aligned baselines while tuning only 170M parameters on a frozen 7B backbone. We further extend GVG-Janus with trimodal Image+Text alignment, where text supplies categorical semantic anchors and visual proxies enrich neural representations with perceptual details. Experiments show consistent gains in EEG understanding and visual generation, suggesting visual proxy grounding as an effective complement to textual alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Generative Visual Grounding (GVG), a framework that uses an EEG-to-image generative model to hallucinate instance-specific proxy images from non-visual EEG signals. These proxies supply structured visual context to MLLMs, enabling them to leverage visual priors for clinical-state interpretation instead of relying solely on lossy text alignment. The approach is validated on two backbones (GVG-X-Omni and GVG-Janus), with claims that image-only alignment is competitive with larger text baselines using only 170M tunable parameters on a frozen 7B model, and that trimodal (Image+Text) alignment yields further gains in EEG understanding and visual generation.
Significance. If the generated visual proxies faithfully encode fine-grained perceptual details from EEG without introducing artifacts, the framework could meaningfully advance brain foundation models by complementing textual alignment with visual priors in MLLMs. The parameter-efficient tuning (170M parameters) and the explicit separation of categorical semantic anchors (text) from perceptual enrichment (images) are strengths. However, the absence of direct fidelity metrics or controls for non-visual EEG cases limits the assessed impact, as gains might stem from added modality capacity rather than meaningful neural-to-visual translation.
major comments (3)
- [Abstract / Experiments] Abstract and validation sections: The central claim that visual proxies 'enrich neural representations with perceptual details' and enable 'consistent gains' requires evidence that EEG-to-image outputs preserve fine-grained information rather than spurious features. No direct fidelity checks, image quality metrics, or comparisons against ground-truth perceptual content for non-visual EEG are described, leaving open whether reported improvements track proxy quality or simply reflect extra input capacity.
- [Validation on GVG-X-Omni] GVG-X-Omni description: The claim that the lightweight model 'matches 1.7B-parameter text-aligned baselines' while tuning only 170M parameters on a frozen 7B backbone is load-bearing for the efficiency argument, yet no specific baseline models, datasets, tasks, or numerical performance values (e.g., accuracy, F1) are provided to support the comparison.
- [GVG-Janus trimodal alignment] Trimodal extension: Extending GVG-Janus with Image+Text alignment is presented as yielding further gains, but without ablation isolating the contribution of the generated visual proxies versus text alone, or versus random visual inputs, it is unclear whether the perceptual enrichment is the operative factor.
minor comments (2)
- [Abstract] The abstract uses 'hallucinates' to describe the generative process; a more neutral term such as 'generates' would avoid unintended connotations in a scientific context.
- [Methods] Notation for the two backbones (GVG-X-Omni, GVG-Janus) is introduced without an explicit definition of how GVG is integrated into each architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below, clarifying our approach and outlining revisions to strengthen the evidence and presentation.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and validation sections: The central claim that visual proxies 'enrich neural representations with perceptual details' and enable 'consistent gains' requires evidence that EEG-to-image outputs preserve fine-grained information rather than spurious features. No direct fidelity checks, image quality metrics, or comparisons against ground-truth perceptual content for non-visual EEG are described, leaving open whether reported improvements track proxy quality or simply reflect extra input capacity.
Authors: We agree that direct fidelity evidence would be ideal. However, non-visual EEG inherently lacks ground-truth images, rendering standard metrics such as FID or LPIPS inapplicable without artificial references. Our primary validation relies on consistent downstream gains in EEG understanding and generation tasks, which serve as indirect but task-relevant indicators that the proxies capture meaningful perceptual structure rather than noise. In revision we will add a dedicated subsection discussing evaluation challenges for non-visual signals, include qualitative examples of generated proxies with corresponding model attention maps, and report correlation analysis between proxy characteristics and task performance to better address this concern. revision: yes
-
Referee: [Validation on GVG-X-Omni] GVG-X-Omni description: The claim that the lightweight model 'matches 1.7B-parameter text-aligned baselines' while tuning only 170M parameters on a frozen 7B backbone is load-bearing for the efficiency argument, yet no specific baseline models, datasets, tasks, or numerical performance values (e.g., accuracy, F1) are provided to support the comparison.
Authors: The experimental section of the full manuscript contains these comparisons, but we acknowledge that the high-level claim in the abstract and introduction would benefit from explicit anchoring. In the revised manuscript we will insert a concise table or paragraph that names the specific 1.7B-parameter text-aligned baselines, lists the EEG datasets and clinical interpretation tasks used, and reports the numerical results (accuracy and F1 scores) demonstrating that GVG-X-Omni remains competitive while tuning only 170M parameters on the frozen 7B backbone. revision: yes
-
Referee: [GVG-Janus trimodal alignment] Trimodal extension: Extending GVG-Janus with Image+Text alignment is presented as yielding further gains, but without ablation isolating the contribution of the generated visual proxies versus text alone, or versus random visual inputs, it is unclear whether the perceptual enrichment is the operative factor.
Authors: We have already compared text-only, image-only, and trimodal alignments and observed incremental gains for the trimodal setting. To more rigorously isolate the role of the generated proxies, we will add a new ablation experiment in the revision that replaces the EEG-conditioned proxies with random or noise-based images while keeping all other factors fixed. This control will clarify whether the observed improvements stem from semantically relevant visual content rather than simply the addition of an extra modality. revision: yes
Circularity Check
No circularity: new framework proposal validated via independent experiments
full rationale
The paper proposes Generative Visual Grounding (GVG) as a method that uses an EEG-to-image generative model to create instance-specific visual proxies for non-visual EEG signals, which are then fed into MLLMs for improved clinical-state interpretation. The derivation consists of describing this translator role, applying it to two specific backbones (GVG-X-Omni with 170M tunable parameters on a frozen 7B model, and trimodal GVG-Janus), and reporting empirical gains in alignment and generation tasks. No equations, fitted parameters renamed as predictions, or self-citation chains are invoked to force the central claims; the results are presented as outcomes of external validation on GVG-X-Omni and GVG-Janus rather than reducing tautologically to the inputs by construction. The approach remains self-contained against the described benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption EEG signals contain fine-grained perceptual information that can be translated into instance-specific visual images via generative models
invented entities (1)
-
Generative Visual Grounding (GVG) framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ an EEG-to-Image generative model (AVDE) as a visual translator to hallucinate instance-specific proxy images for non-visual EEG data... trimodal objective Ltri = λ_ei L_ei + λ_et L_et + λ_it L_it
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
mapping raw EEG signals into discrete image tokens... similarity-based prediction over codebook V
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.