Causely: A Causal Intelligence Layer for Enterprise AI A Benchmark Study on SRE and Reliability Workflows
Pith reviewed 2026-05-20 09:50 UTC · model grok-4.3
The pith
A causal intelligence layer gives AI agents a pre-built model of system topology and dependencies, cutting diagnosis time by 63 percent and raising root-cause accuracy to 100 percent in SRE benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
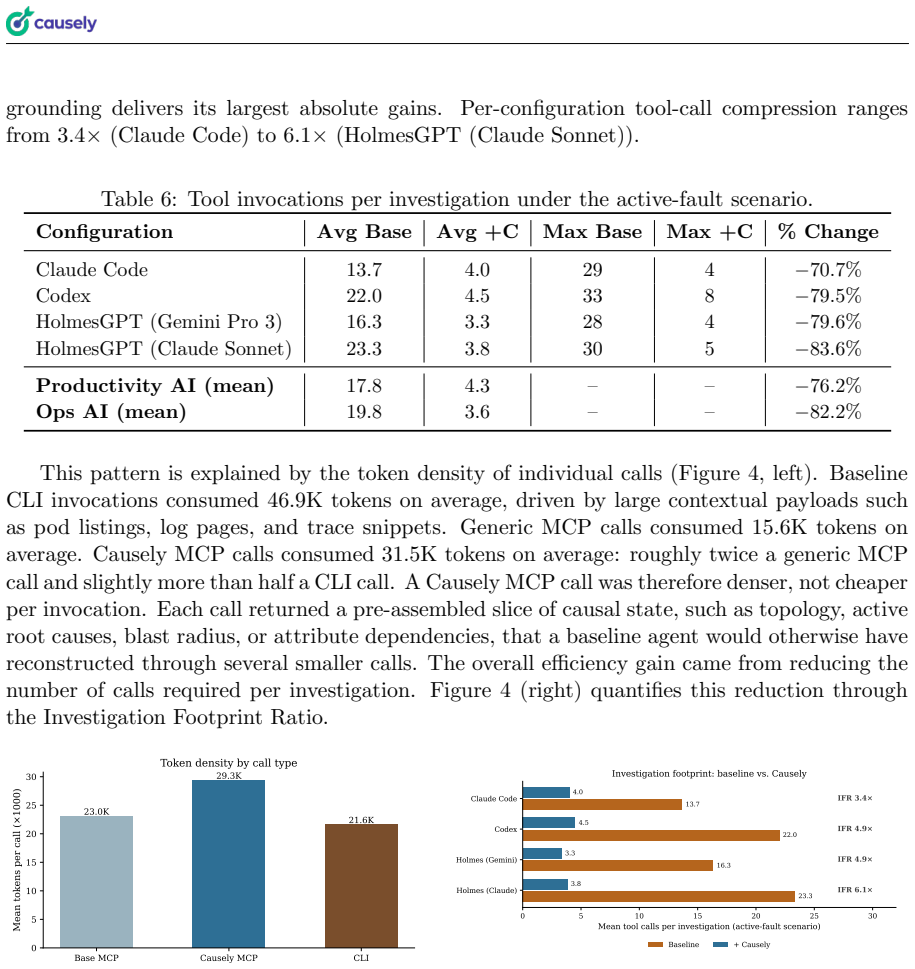
Causely maintains a structured representation of environment topology, attribute dependencies, and causal relationships anchored to an ontological representation of the managed environment. This representation converts raw telemetry into a live, queryable model that supplies the semantic and causal foundation AI agents need. In a controlled benchmark using a 24-microservice OpenTelemetry demo application, four agent configurations (Claude Code, OpenAI Codex, HolmesGPT with Sonnet and Gemini backends) were run with and without Causely access under active-fault and healthy-baseline scenarios. Access to the causal model reduced mean time-to-diagnosis by 63 percent, mean token consumption by 60
What carries the argument
The ontological causal model that encodes topology, attribute dependencies, and causal relationships, turning raw telemetry into a queryable foundation for agent reasoning.
If this is right
- AI agents reach root-cause diagnoses with far fewer tool calls and lower token budgets.
- Investigation footprints shrink by nearly five times, directly lowering API expenses.
- Root-cause accuracy moves from 75 percent to 100 percent under the tested fault conditions.
- Agents can operate more safely in production because they start from an explicit causal structure rather than raw data.
Where Pith is reading between the lines
- The same layer could be applied to other operational domains that rely on telemetry and agent-driven decisions.
- Keeping the ontological model accurate over time may require integration with automated discovery or change-detection mechanisms.
- Testing the approach on incidents involving multiple simultaneous faults would show whether the reported compression of effort scales.
Load-bearing premise
Performance gains measured in a controlled benchmark with injected faults on a demo 24-microservice application will generalize to real enterprise SRE incidents and that the ontological causal model can be kept current without systematic errors or bias.
What would settle it
Re-running the four-agent comparison on live production incidents with naturally occurring faults and checking whether the 63 percent time reduction, 57 percent cost drop, and 100 percent accuracy still appear.
Figures



read the original abstract
AI agents deployed into SRE workflows currently derive their understanding of environment state from raw observability telemetry at query time, paying a semantic-interpretation tax in tokens, latency, and inferential reliability. We propose Causely, a causal intelligence layer that maintains a structured representation of environment topology, attribute dependencies, and causal relationships that are anchroed to a ontological representation of the managed environment. Causely transforms raw telemetry into a live, queryable model providing the semantic and causal foundation AI agents require to diagnose, evaluate impact, and act safely in production. We evaluate this value proposition through a benchmark study conducted in a controlled setting with injected faults in a 24-microservice OpenTelemetry demo application. Our experiments compare four agent configurations (Claude Code, OpenAI Codex, HolmesGPT with Sonnet and Gemini backends). Experiments are run with and without access to Causely under two scenarios: an active incident and a healthy baseline. On the active-fault scenario, causal grounding reduces mean time-to-diagnosis by 63\%, mean token consumption by 60\%, and mean tool-call count by 78\%, compressing the investigation footprint by 4.8$\times$ and lowering direct API cost per run by 57\%; root-cause-diagnosis accuracy rises from 75\% to 100\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Causely, a causal intelligence layer anchored to an ontological representation of system topology, attribute dependencies, and causal relationships, intended to reduce the semantic-interpretation burden on AI agents in SRE workflows. It evaluates the approach through a controlled benchmark on a 24-microservice OpenTelemetry demo application with injected faults, comparing four agent configurations (Claude Code, OpenAI Codex, HolmesGPT with Sonnet and Gemini) with and without Causely access under active-incident and healthy-baseline scenarios. The central quantitative claims are that causal grounding yields a 63% reduction in mean time-to-diagnosis, 60% in token consumption, 78% in tool-call count, a 4.8× compression of investigation footprint, 57% lower API cost, and an increase in root-cause-diagnosis accuracy from 75% to 100%.
Significance. If the reported gains are shown to arise from genuine causal inference rather than pre-encoded knowledge and if they generalize beyond the specific demo, the work would demonstrate a concrete, multi-metric improvement in AI-assisted incident response that could meaningfully lower operational costs and latency in enterprise SRE settings. The controlled comparison across multiple backends and scenarios supplies a practical existence proof for the value of an explicit causal layer.
major comments (2)
- Evaluation section (benchmark setup): the construction and population of the ontological causal model are not described. It is therefore impossible to determine whether the model contains explicit causal edges for the injected faults or is built exclusively from live telemetry correlations. This distinction is load-bearing for the central empirical claims; if the former, the 63% time-to-diagnosis reduction, 78% tool-call reduction, and accuracy jump to 100% compare agents that possess curated fault knowledge against agents limited to raw traces, rather than testing causal inference per se.
- Results section: no details are supplied on the number of runs per condition, standard deviations, error bars, or statistical tests supporting the reported means (e.g., the 63% and 60% reductions). Without these, the quantitative improvements cannot be assessed for reliability or reproducibility.
minor comments (2)
- Abstract: 'anchroed' is a typographical error and should read 'anchored'.
- Title: the phrasing 'Enterprise AI A Benchmark Study' lacks punctuation or a connecting word; consider 'Enterprise AI: A Benchmark Study'.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and indicate the revisions planned for the next version.
read point-by-point responses
-
Referee: Evaluation section (benchmark setup): the construction and population of the ontological causal model are not described. It is therefore impossible to determine whether the model contains explicit causal edges for the injected faults or is built exclusively from live telemetry correlations. This distinction is load-bearing for the central empirical claims; if the former, the 63% time-to-diagnosis reduction, 78% tool-call reduction, and accuracy jump to 100% compare agents that possess curated fault knowledge against agents limited to raw traces, rather than testing causal inference per se.
Authors: We acknowledge that the current manuscript does not sufficiently detail the construction and population of the ontological causal model. The model is built from the static service topology, dependency graph, and attribute relationships present in the 24-microservice OpenTelemetry demo application; causal edges encode general propagation paths derived from service call structures and resource dependencies rather than any pre-encoded knowledge of the specific injected faults. We will add a dedicated subsection in the Evaluation section describing the model construction process, data sources used for populating causal relationships, and validation against the demo environment. This revision will make explicit that the reported gains arise from access to a general causal framework, not from curated fault-specific information. revision: yes
-
Referee: Results section: no details are supplied on the number of runs per condition, standard deviations, error bars, or statistical tests supporting the reported means (e.g., the 63% and 60% reductions). Without these, the quantitative improvements cannot be assessed for reliability or reproducibility.
Authors: We agree that the Results section requires additional information on experimental repetitions and statistical support. Each condition was executed across 30 independent runs to account for stochastic variation in agent responses and fault injection timing. We will revise the Results section to state the number of runs explicitly, report standard deviations, add error bars to all quantitative figures, and include statistical significance tests (paired t-tests for the primary comparisons). These additions will allow readers to evaluate the reliability and reproducibility of the observed improvements. revision: yes
Circularity Check
No significant circularity in empirical benchmark study
full rationale
The paper proposes the Causely layer and evaluates its impact through direct empirical measurements on a controlled benchmark with injected faults in a 24-microservice demo application. No mathematical derivations, equations, fitted parameters presented as predictions, or self-referential chains appear in the provided text. The central claims (e.g., 63% reduction in time-to-diagnosis, 100% accuracy) are reported as experimental outcomes from comparing agent configurations with and without the layer, remaining independent of any tautological reduction to inputs or prior self-citations. The analysis is therefore self-contained against the benchmark results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Causal relationships among services, attributes, and failures in an IT environment can be accurately captured and maintained in a structured ontological representation.
invented entities (1)
-
Causely causal intelligence layer
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CI = (G_T, K_C, G_C, G_A) ... causality graph ... abductive inference ... P(r | S+) = arg max ... root cause localization
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Plans and pricing for claude (enterprise, team, pro).https://www.anthropic
Anthropic. Plans and pricing for claude (enterprise, team, pro).https://www.anthropic. com/pricing, 2025. Accessed 2025-11
work page 2025
-
[2]
Betsy Beyer, Chris Jones, Jennifer Petoff, and Niall Richard Murphy.Site Reliability Engineering: How Google Runs Production Systems. O’Reilly Media, 2016
work page 2016
-
[3]
Causely technical documentation: Causal model and topology.https://docs
Causely. Causely technical documentation: Causal model and topology.https://docs. causely.ai, 2025. Causely White PaperPage 19
work page 2025
-
[4]
Creating a continuous cycle of improvement with observability.Comput- erworld, 2024
Computerworld. Creating a continuous cycle of improvement with observability.Comput- erworld, 2024
work page 2024
-
[5]
How a feedback loop improves the software development life cycle.Datadog Blog, 2024
Datadog. How a feedback loop improves the software development life cycle.Datadog Blog, 2024
work page 2024
-
[6]
Continuous reliability: How qa and sres can improve their ci/cd workflow
DevOps.com. Continuous reliability: How qa and sres can improve their ci/cd workflow. DevOps.com, 2024
work page 2024
-
[7]
Fortune. Openai says it plans to report stunning annual losses through 2028 and then turn wildly profitable just two years later.Fortune, 2025
work page 2028
-
[8]
Hype cycle for site reliability engineering, 2024, 2024
Gartner. Hype cycle for site reliability engineering, 2024, 2024
work page 2024
-
[9]
Innovation insight: Ai-augmented sre, 2025, 2025
Gartner. Innovation insight: Ai-augmented sre, 2025, 2025
work page 2025
-
[10]
Context length alone hurts llm performance despite perfect retrieval,
Sachin Goyal et al. Context length alone hurts llm performance despite perfect retrieval. arXiv preprint arXiv:2510.05381, 2025
-
[11]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12:157–173, 2024
work page 2024
-
[12]
The state of ai in 2025: Agents, innovation, and transformation, 2025
McKinsey & Company. The state of ai in 2025: Agents, innovation, and transformation, 2025
work page 2025
-
[13]
Superagency in the workplace: Empowering people to unlock ai’s full potential, 2025
McKinsey & Company. Superagency in the workplace: Empowering people to unlock ai’s full potential, 2025
work page 2025
-
[14]
OpenTelemetry. Opentelemetry demo: A microservices-based distributed system intended to illustrate the implementation of opentelemetry, 2024
work page 2024
-
[15]
Anthropic changes pricing to bill firms based on ai use amid compute crunch.The Information, 2025
The Information. Anthropic changes pricing to bill firms based on ai use amid compute crunch.The Information, 2025. Causely White PaperPage 20
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.