Presupposition and Reasoning in Conditionals: A Theory-Based Study of Humans and LLMs
Pith reviewed 2026-05-20 11:42 UTC · model grok-4.3
The pith
LLMs that best match human ratings on conditional presuppositions often lack coherent pragmatic reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
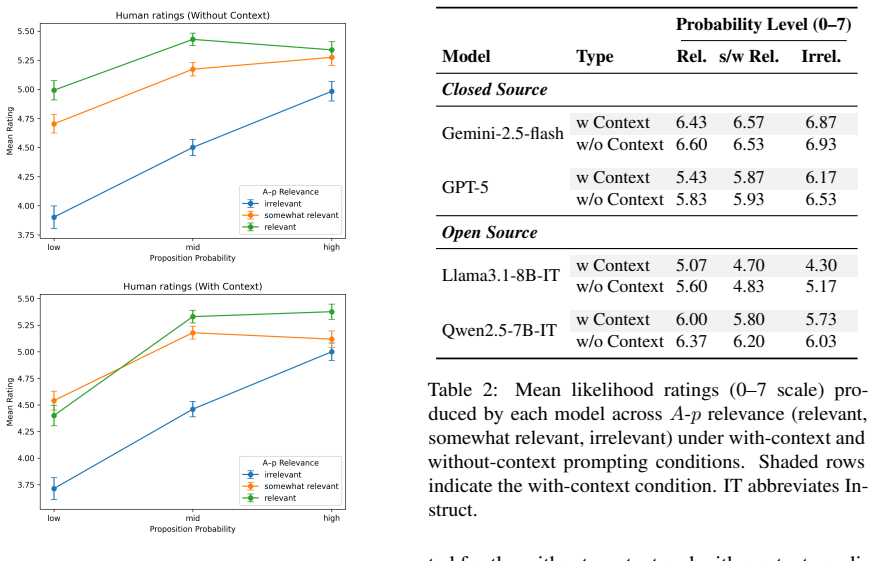
Humans integrate probabilistic and pragmatic cues in their judgments of presupposition projection in conditionals, whereas LLMs show variable alignment with these patterns. Models that best match human ratings often lack coherent pragmatic reasoning when evaluated with a linguistically motivated checklist, while models with stronger reasoning produce less human-like judgments. These findings indicate that LLM performance on such tasks may result from surface pattern matching rather than pragmatic competence.
What carries the argument
A linguistically motivated checklist applied within an LLM-as-a-Judge framework to evaluate the presence and coherence of pragmatic reasoning in model responses to conditional sentences.
If this is right
- Theory-grounded benchmarks are required to distinguish surface-level matching from actual pragmatic competence in language models.
- Human-like output on presupposition tasks does not imply that models employ the same underlying reasoning processes as people.
- LLM performance on linguistic judgment tasks may fail to generalize to novel cases outside patterns seen during training.
Where Pith is reading between the lines
- The observed mismatch between rating alignment and reasoning quality may extend to other pragmatic phenomena such as implicature calculation.
- Model training that rewards explicit reasoning steps could shift the trade-off between human-like outputs and genuine pragmatic competence.
- Separate evaluation tracks for output similarity and for traceable reasoning would give clearer signals about where current models fall short.
Load-bearing premise
The normed dataset successfully isolates the relation between the antecedent and the projected presupposition without unmeasured confounds that could drive both human and model responses.
What would settle it
Testing whether models given explicit pragmatic reasoning instructions or modules produce more coherent reasoning traces while simultaneously reducing their alignment with human likelihood ratings on the same conditional items.
Figures




read the original abstract
Presupposition projection in conditionals is central to theories of meaning and pragmatics, yet it remains largely unevaluated in large language models. We address this gap through a parallel behavioral study comparing human judgments and LLM predictions on a normed dataset of conditional sentences that controls the relation between the antecedent and the projected presupposition. We collect likelihood ratings from 120 participants and four LLMs under matched contextual conditions. Results show that humans integrate probabilistic and pragmatic cues in their judgment, whereas LLMs show variable alignment with human patterns. Using a linguistically motivated checklist within an LLM-as-a-Judge framework, we further evaluate model reasoning. We observe models that best match human ratings often lack coherent pragmatic reasoning, while models with stronger reasoning produce less human-like judgments. These findings suggest that LLMs' performance on such tasks may result from surface pattern matching rather than pragmatic competence. Our findings highlight the importance of benchmarks grounded in linguistic theory for comparing humans and models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a parallel behavioral study on presupposition projection in conditionals, using a normed dataset that controls the relation between antecedent and projected presupposition. It collects likelihood ratings from 120 human participants and four LLMs under matched conditions, then applies a linguistically motivated checklist inside an LLM-as-Judge framework to evaluate reasoning. The central claim is that models best matching human ratings often lack coherent pragmatic reasoning while stronger reasoners produce less human-like judgments, suggesting LLM performance arises from surface pattern matching rather than pragmatic competence.
Significance. If the dissociation holds after verification, the work is significant for providing a theory-grounded benchmark that distinguishes pattern matching from pragmatic competence in LLMs. The parallel human-LLM design with controlled conditions and the explicit use of linguistic theory for the checklist are strengths that could guide future evaluations of pragmatic abilities.
major comments (2)
- [§4.2] §4.2 (LLM-as-Judge checklist): The manuscript does not specify whether the judge model is held out from the set of rated models or detail the exact scoring procedure for checklist items. This is load-bearing for the central claim because if checklist items can be satisfied by the model echoing its own likelihood rating or by surface pattern completion, the observed mismatch no longer isolates pragmatic competence from the cues driving the ratings.
- [§3.1 and §4.1] §3.1 and §4.1: No statistical tests, effect sizes, confidence intervals, or participant exclusion criteria are reported for the human likelihood ratings or the LLM-human alignment comparisons. This undermines verification of the claim that humans integrate probabilistic and pragmatic cues while LLMs show variable alignment.
minor comments (2)
- [Figure 2] Figure 2 or 3 (whichever shows the rating distributions): axis labels and error bars should be clarified to allow direct visual comparison of human vs. model variance.
- [Introduction] The abstract and introduction could add one sentence explicitly stating the number of checklist items and their linguistic motivation to improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify two areas where additional clarity and reporting will strengthen the manuscript's claims about the dissociation between human-like ratings and pragmatic reasoning in LLMs. We address each point below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4.2] §4.2 (LLM-as-Judge checklist): The manuscript does not specify whether the judge model is held out from the set of rated models or detail the exact scoring procedure for checklist items. This is load-bearing for the central claim because if checklist items can be satisfied by the model echoing its own likelihood rating or by surface pattern completion, the observed mismatch no longer isolates pragmatic competence from the cues driving the ratings.
Authors: We agree that the current description in §4.2 is insufficient to fully isolate pragmatic competence. The judge model (GPT-4) was in fact held out from the four evaluated models, and checklist items were scored on independent binary judgments of the reasoning trace rather than the likelihood rating itself. However, these details were not stated explicitly. In the revision we will add: (1) explicit confirmation that the judge is held out, (2) the full prompt template used for each checklist item, and (3) a description of the scoring procedure showing that items target coherence of pragmatic inference (e.g., recognition of accommodation vs. projection) rather than restatement of the rating. We will also include example traces in the appendix to demonstrate the distinction from surface pattern matching. revision: yes
-
Referee: [§3.1 and §4.1] §3.1 and §4.1: No statistical tests, effect sizes, confidence intervals, or participant exclusion criteria are reported for the human likelihood ratings or the LLM-human alignment comparisons. This undermines verification of the claim that humans integrate probabilistic and pragmatic cues while LLMs show variable alignment.
Authors: We accept that the lack of inferential statistics weakens the evidential support for the reported patterns. In the revised manuscript we will add, in §3.1, the participant exclusion criteria (failed attention checks or completion time <5 min; final N=120), and report mixed-effects models or appropriate non-parametric tests comparing likelihood ratings across the controlled antecedent-presupposition relations, together with effect sizes and 95% confidence intervals. In §4.1 we will report Pearson or Spearman correlations between human and LLM ratings per model, with bootstrap confidence intervals and statistical tests for differences in alignment across models. These additions will allow readers to verify the integration of probabilistic and pragmatic cues in humans versus the variable alignment in LLMs. revision: yes
Circularity Check
Empirical behavioral comparison with independent human benchmark shows no circular derivation
full rationale
The paper reports a parallel study collecting human likelihood ratings from 120 participants on a normed dataset of conditionals and comparing them to outputs from four LLMs under matched conditions. It then applies a linguistically motivated checklist inside an LLM-as-Judge framework to assess reasoning. Human ratings function as an external benchmark independent of model outputs; the observed dissociation between rating alignment and checklist-based reasoning coherence is presented as an empirical result rather than a quantity derived from fitted parameters, self-definitions, or self-citation chains. No equations, uniqueness theorems, or ansatzes appear in the provided text that reduce the central claims to the inputs by construction. The derivation chain is therefore self-contained against the external human data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A normed dataset can control the relation between antecedent and projected presupposition so that human judgments reflect probabilistic and pragmatic cues.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Presupposition projection in conditionals... Using a linguistically motivated checklist within an LLM-as-a-Judge framework... models that best match human ratings often lack coherent pragmatic reasoning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Measuring bias and agreement in large lan- guage model presupposition judgments. InFind- 9 ings of the Association for Computational Linguis- tics: ACL 2025, pages 2096–2107, Vienna, Austria. Association for Computational Linguistics. Tara Azin, Daniel Dumitrescu, Diana Inkpen, and Raj Singh. 2025. Let’s confer: A dataset for evalu- ating natural language...
-
[2]
ClaimDB: A Fact Verification Benchmark over Large Structured Data
PUB: A pragmatics understanding benchmark for assessing LLMs’ pragmatics capabilities. InFind- ings of the Association for Computational Linguistics: ACL 2024, pages 12075–12097, Bangkok, Thailand. Association for Computational Linguistics. Robert Stalnaker. 1973. Presuppositions.Journal of Philosophical Logic, 2(4):447–457. Robert Stalnaker. 1998. On the...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Educational backgrounds ranged from high school to graduate degrees. Participants completed 90 items, each consist- ing of a conditional statement and a corresponding target statement, and rated the likelihood of the target statement on a 0–7 Likert scale. In the with- context condition, participants were additionally provided with brief identifying backg...
-
[4]
The cor- responding API documentation is avail- able at https://platform.openai.com/ docs/models
GPT-5is provided by OpenAI. The cor- responding API documentation is avail- able at https://platform.openai.com/ docs/models
-
[5]
Rel:If Alex uses social media, he will post a photo to his Instagram account
Gemini-2.5-flashis provided by Google 13 Background Statement 1 (Conditional) Target having an Instagram account (High-Probability Example) Alex works at the airport in your town. Rel:If Alex uses social media, he will post a photo to his Instagram account. Alex has an Instagram account. Maya works at the airport in your town. S-Rel:If Maya is over 50, sh...
-
[6]
The corresponding API documentation is available at https: //platform.claude.com/docs/en/intro
Claude-haiku-4is provided by An- thropic. The corresponding API documentation is available at https: //platform.claude.com/docs/en/intro
-
[7]
Qwen2.5-7B-Instruct6 andLlama3.1-8B- Instruct7 are open-source base model weights obtained from Hugging Face ( https:// huggingface.co/). For large proprietary models (e.g., GPT-5 and Gemini-2.5-Flash), a single run on 360 samples costs approximately $14 CAD for explanation gen- eration. For the judge model, Claude-Haiku-4, eval- uating approximately 40,0...
-
[10]
How does the conditional relationship affect the likelihood of the target statement? After your reasoning, provide your final answer in the format: "Final Rating: [0--7]" --- Speaker's statement: {statement_1} Question: How likely is it that the following statement is true? Statement: {statement_2} With-Context Condition Prompt In this task, imagine you a...
-
[11]
What does the speaker's conditional statement imply about the subject?
-
[12]
What background assumptions or world knowledge are relevant?
-
[13]
How does the conditional relationship affect the likelihood of the target statement? After your reasoning, provide your final answer in the format: "Final Rating: [0--7]" --- background: {background} Speaker's statement: {statement_1} Question: How likely is it that the following statement is true? Statement: {statement_2} Figure 4: System prompts used fo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.