A No-Defense Defense Against Gradient-Based Adversarial Attacks on ML-NIDS: Is Less More?
Pith reviewed 2026-05-20 13:12 UTC · model grok-4.3
The pith
Simpler DNN architectures with fewer features and ReLU activations inherently reduce vulnerability to gradient-based attacks on ML-based network intrusion detection without added defenses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
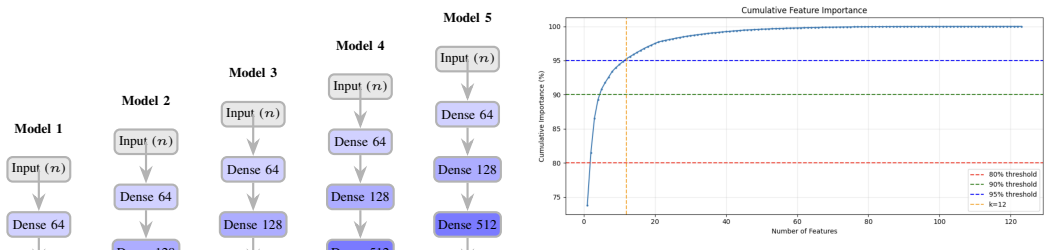
Through thousands of experiments varying network depth, feature dimensionality, activation functions, and dropout across FGSM, PGD, and BIM attacks, shallower networks, reduced feature sets, and ReLU activation consistently and jointly reduce adversarial vulnerability. Moreover, a simple model following this recipe outperforms deeper, fully-featured adversarially trained models, while maintaining near-perfect clean-traffic detection and lower training times.
What carries the argument
The joint reduction of network depth, feature-set size, and use of ReLU activations as an implicit defense mechanism against gradient-based perturbations in DNN-based ML-NIDS.
If this is right
- Architectural simplicity can deliver higher robustness than explicit adversarial training for this task.
- Fewer input features can lower attack success rates while preserving near-perfect accuracy on clean traffic.
- ReLU activations contribute measurably to the observed reduction in vulnerability compared with other functions tested.
- Training time decreases as models become shallower and use smaller feature sets, without loss of clean-data performance.
- The right combination of reductions matters more than any single reduction taken alone.
Where Pith is reading between the lines
- Security-critical ML systems may benefit from starting with minimal architectures rather than adding defenses after the fact.
- Feature selection criteria for NIDS should weigh robustness against attacks in addition to clean accuracy.
- The same recipe could be checked on non-gradient attacks or on datasets from different network environments to test broader reach.
Load-bearing premise
The specific ranges of depth, feature counts, activation choices, and dropout values tested, along with the three gradient attacks examined, are representative of the conditions that matter in real ML-NIDS deployments.
What would settle it
A new experiment on a different traffic dataset or against an adaptive attack in which the deeper or fully featured models show higher robustness or the simple recipe loses its advantage would falsify the central claim.
Figures














read the original abstract
Gradient-based adversarial attacks subtly manipulate inputs of Machine Learning (ML) models to induce incorrect predictions. This paper investigates whether careful architectural choices alone can yield an inherently robust Deep Neural Network (DNN)-based Network Intrusion Detection Systems (NIDS), without any additional explicit defenses. Through thousands of experiments, around 2200, varying network depth, feature dimensionality, activation functions, and dropout across FGSM, PGD, and BIM attacks, we show that shallower networks, reduced feature sets, and ReLU activation consistently and jointly reduce adversarial vulnerability. Moreover, a simple model following this recipe outperforms deeper, fully-featured adversarially trained models, while maintaining near-perfect clean-traffic detection and lower training times. Nevertheless, while less is more, the selection of the right less is what truly matters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that careful architectural choices alone—specifically shallower networks, reduced feature sets, and ReLU activations—can yield inherent robustness in DNN-based ML-NIDS against gradient-based attacks (FGSM, PGD, BIM) without explicit defenses. Supported by ~2200 experiments varying depth, feature dimensionality, activations, and dropout, a simple model following this recipe is reported to outperform deeper, fully-featured adversarially trained models while preserving near-perfect clean-traffic detection and lower training times.
Significance. If the central empirical claims hold under matched conditions, the work offers a practical insight for ML-NIDS: that 'less' in architecture and features can be more effective for robustness than adding adversarial training, with benefits in training efficiency. The scale of the experimental campaign (~2200 runs) is a clear strength, providing broad coverage of the tested hyperparameters and attacks. However, the result's significance depends on whether the outperformance generalizes beyond the specific datasets and attack configurations used.
major comments (2)
- [Abstract] Abstract and experimental results: the load-bearing claim that the simple shallow ReLU reduced-feature model outperforms deeper fully-featured adversarially trained models requires that the adversarial-training baselines were performed with comparable perturbation strengths, the same reduced feature mask, and equivalent clean-accuracy targets. The description of the ~2200 experiments does not clarify these matching conditions, raising the possibility that observed outperformance is confounded by mismatched baselines rather than attributable to architectural choices alone.
- [Experimental Setup] Experimental design: the variations tested (depth, features, activations, dropout) against FGSM/PGD/BIM are presented as representative, yet the weakest assumption—that these suffice for robustness claims to generalize to real-world ML-NIDS deployments—remains unaddressed without additional validation on diverse datasets or stronger/transfer attacks.
minor comments (2)
- Ensure that all attack parameters (e.g., epsilon, number of iterations for PGD/BIM) and the exact feature-selection procedure are reported with sufficient detail for reproducibility.
- Clarify the statistical analysis used to support 'consistently and jointly reduce adversarial vulnerability' across the many configurations; include confidence intervals or significance tests where appropriate.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments on our manuscript. We have addressed each major point below and revised the paper to improve clarity on experimental conditions and the scope of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental results: the load-bearing claim that the simple shallow ReLU reduced-feature model outperforms deeper fully-featured adversarially trained models requires that the adversarial-training baselines were performed with comparable perturbation strengths, the same reduced feature mask, and equivalent clean-accuracy targets. The description of the ~2200 experiments does not clarify these matching conditions, raising the possibility that observed outperformance is confounded by mismatched baselines rather than attributable to architectural choices alone.
Authors: We appreciate this observation and agree that explicit documentation of baseline conditions is necessary to support the central claim. The adversarial-training baselines were run with identical perturbation budgets (the same ε values for FGSM, PGD, and BIM) as the attack evaluations. These baselines used the complete feature set (i.e., fully-featured), while the proposed shallow ReLU model applied the reduced feature mask identified in our ablation study. We further restricted reported comparisons to model pairs whose clean-data accuracy differed by at most 0.5 percentage points. We have revised both the abstract and the experimental-results section to state these matching criteria explicitly, including the precise ε values and clean-accuracy tolerance used. revision: yes
-
Referee: [Experimental Setup] Experimental design: the variations tested (depth, features, activations, dropout) against FGSM/PGD/BIM are presented as representative, yet the weakest assumption—that these suffice for robustness claims to generalize to real-world ML-NIDS deployments—remains unaddressed without additional validation on diverse datasets or stronger/transfer attacks.
Authors: The referee is correct that our experiments are confined to the datasets and gradient-based attacks examined. The ~2200 runs were designed to isolate the effects of depth, feature count, activation, and dropout rather than to exhaustively cover all possible ML-NIDS settings. We have added a dedicated limitations paragraph in the discussion section that explicitly acknowledges the need for future validation on additional traffic corpora and against transfer or adaptive attacks. Within the present scope, the work demonstrates that the identified architectural recipe reduces vulnerability to the tested attacks while preserving clean performance; we do not assert broader generalization. revision: partial
Circularity Check
No circularity in empirical experimental study
full rationale
The paper is an empirical study reporting results from ~2200 experiments that vary network depth, feature sets, activation functions, and dropout against FGSM/PGD/BIM attacks. Claims about shallower ReLU models with reduced features reducing adversarial vulnerability are direct observations from these controlled comparisons, not a derivation that reduces to its own inputs by construction. No mathematical equations, fitted parameters renamed as predictions, or self-citation chains are used to justify the central results; the outperformance versus adversarially trained baselines is presented as an experimental outcome rather than a tautological restatement. This is a standard non-circular empirical finding.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
shallower networks, reduced feature sets, and ReLU activation consistently and jointly reduce adversarial vulnerability
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a simple model following this recipe outperforms deeper, fully-featured adversarially trained models
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Explaining and Harnessing Adversarial Examples
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[2]
Adversarial examples in the physical world,
A. Kurakin, I. J. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” inArtificial intelligence safety and security. Chapman and Hall/CRC, 2018, pp. 99–112
work page 2018
-
[3]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,”arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
A novel perturb-ability score to mitigate evasion adversarial attacks on flow-based ml-nids,
M. ElShehaby and A. Matrawy, “A novel perturb-ability score to mitigate evasion adversarial attacks on flow-based ml-nids,”Journal of Information Security and Applications, vol. 99, p. 104409, 2026
work page 2026
-
[5]
Distillation as a defense to adversarial perturbations against deep neural networks,
N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami, “Distillation as a defense to adversarial perturbations against deep neural networks,” in 2016 IEEE Symposium on Security and Privacy (SP). IEEE, 2016, pp. 582–597
work page 2016
-
[6]
Adaptive continuous adver- sarial training (acat) to enhance ml-nids robustness,
M. elShehaby, A. Kotha, and A. Matrawy, “Adaptive continuous adver- sarial training (acat) to enhance ml-nids robustness,” inICC 2025 - IEEE International Conference on Communications, 2025, pp. 1091–1096
work page 2025
-
[7]
Defense strategies for adversarial machine learning: A survey,
P. Bountakas, A. Zarras, A. Lekidis, and C. Xenakis, “Defense strategies for adversarial machine learning: A survey,”Computer Science Review, vol. 49, p. 100573, 2023
work page 2023
-
[8]
Learning activation functions for adversarial attack resilience in cnns,
M. Salimi, M. Loni, and M. Sirjani, “Learning activation functions for adversarial attack resilience in cnns,” inInternational Conference on Artificial Intelligence and Soft Computing. Springer, 2023, pp. 203– 214
work page 2023
-
[9]
Architectural adversarial robustness: The case for deep pursuit,
G. Cazenavette, C. Murdock, and S. Lucey, “Architectural adversarial robustness: The case for deep pursuit,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 7150– 7158
work page 2021
-
[10]
Exploring architectural ingredients of adversarially robust deep neural networks,
H. Huang, Y . Wang, S. Erfani, Q. Gu, J. Bailey, and X. Ma, “Exploring architectural ingredients of adversarially robust deep neural networks,” Advances in neural information processing systems, vol. 34, pp. 5545– 5559, 2021
work page 2021
-
[11]
First-order adversarial vulnerability of neural networks and input dimension,
C.-J. Simon-Gabriel, Y . Ollivier, L. Bottou, B. Sch ¨olkopf, and D. Lopez- Paz, “First-order adversarial vulnerability of neural networks and input dimension,” inInternational conference on machine learning. PMLR, 2019, pp. 5809–5817
work page 2019
-
[12]
Exploring the effect of dnn depth on adversarial attacks in network intrusion detection systems,
M. ElShehaby and A. Matrawy, “Exploring the effect of dnn depth on adversarial attacks in network intrusion detection systems,”arXiv preprint arXiv:2510.19761, 2025
-
[13]
Hyper-parameter tuning for adversarially robust models,
P. Mendes, P. Romano, and D. Garlan, “Hyper-parameter tuning for adversarially robust models,”arXiv preprint arXiv:2304.02497, 2023
-
[14]
M. elShehaby and A. Matrawy, “Evasion adversarial attacks remain impractical against ml-based network intrusion detection systems, especially dynamic ones,” 2026. [Online]. Available: https://arxiv.org/ abs/2306.05494
-
[15]
Toward generating a new intrusion detection dataset and intrusion traffic characterization
I. Sharafaldin, A. H. Lashkari, and A. A. Ghorbani, “Toward generating a new intrusion detection dataset and intrusion traffic characterization.” ICISSp, vol. 1, pp. 108–116, 2018
work page 2018
-
[16]
Error prevalence in nids datasets: A case study on cic-ids-2017 and cse-cic-ids-2018,
L. Liu, G. Engelen, T. Lynar, D. Essam, and W. Joosen, “Error prevalence in nids datasets: A case study on cic-ids-2017 and cse-cic-ids-2018,” in 2022 IEEE Conference on Communications and Network Security (CNS). IEEE, 2022, pp. 254–262
work page 2017
-
[17]
“ipapi,” https://pypi.org/project/ipapi/, 2024, accessed: 2024-10-10
work page 2024
-
[18]
Dos and don’ts of machine learning in computer security,
D. Arp, E. Quiring, F. Pendlebury, A. Warnecke, F. Pierazzi, C. Wress- negger, L. Cavallaro, and K. Rieck, “Dos and don’ts of machine learning in computer security,” in31st USENIX Security Symposium (USENIX Security 22), 2022, pp. 3971–3988
work page 2022
-
[19]
Dealing with class imbalance in classifier chains via random undersampling,
B. Liu and G. Tsoumakas, “Dealing with class imbalance in classifier chains via random undersampling,”Knowledge-Based Systems, vol. 192, p. 105292, 2020
work page 2020
-
[20]
M.-I. Nicolae, M. Sinn, M. N. Tran, B. Buesser, A. Rawat, M. Wistuba, V . Zantedeschi, N. Baracaldo, B. Chen, H. Ludwiget al., “Adversarial robustness toolbox v1. 0.0,”arXiv preprint arXiv:1807.01069, 2018
-
[21]
R. Abou Khamis and A. Matrawy, “Evaluation of adversarial training on different types of neural networks in deep learning-based idss,” in2020 international symposium on networks, computers and communications (ISNCC). IEEE, 2020, pp. 1–6
work page 2020
-
[22]
R. Abou Khamis, M. O. Shafiq, and A. Matrawy, “Investigating re- sistance of deep learning-based ids against adversaries using min-max optimization,” inICC 2020-2020 IEEE International Conference on Communications (ICC). IEEE, 2020, pp. 1–7
work page 2020
-
[23]
Towards more practical threat models in artificial intelligence security,
K. Grosse, L. Bieringer, T. R. Besold, and A. M. Alahi, “Towards more practical threat models in artificial intelligence security,” in33rd USENIX Security Symposium (USENIX Security 24), 2024, pp. 4891–4908
work page 2024
-
[24]
Position:“real attackers don’t compute gradients
G. Apruzzese, H. Anderson, S. Dambra, D. Freeman, F. Pierazzi, and K. Roundy, “Position:“real attackers don’t compute gradients”: Bridging the gap between adversarial ml research and practice,” inIEEE Confer- ence on Secure and Trustworthy Machine Learning. IEEE, 2022
work page 2022
-
[25]
When adversarial perturbations meet concept drift: an exploratory analysis on ml-nids,
G. Apruzzese, A. Fass, and F. Pierazzi, “When adversarial perturbations meet concept drift: an exploratory analysis on ml-nids,” inProceedings of the 2024 Workshop on Artificial Intelligence and Security, 2024, pp. 149–160
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.