FedMental: Evaluating Federated Learning for Mental Health Detection from Social Media Data
Pith reviewed 2026-05-20 12:59 UTC · model grok-4.3
The pith
Federated learning achieves nearly the same accuracy as centralized training for detecting depression from social media posts, but adding differential privacy causes major drops in performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
While federated learning achieves comparable performance to centralized training on depression identification from X posts, differentially private federated learning suffers a large performance-privacy trade-off due to the distortion of highly informative yet sparse mental health linguistic markers such as health topics and emotion words.
What carries the argument
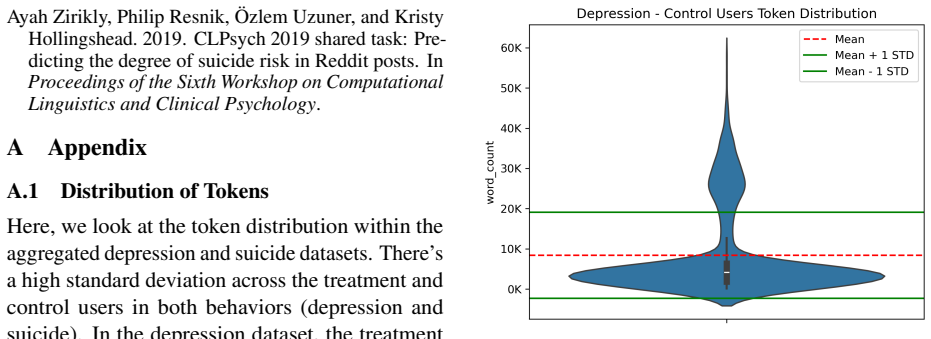
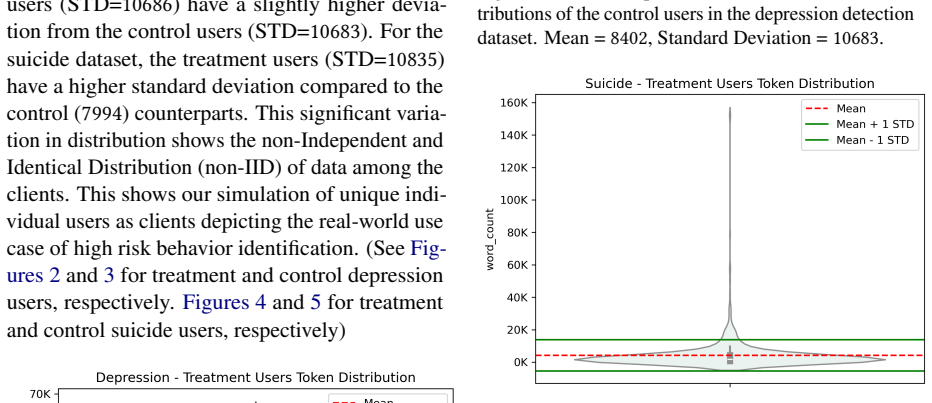
Treating each user as a client in a non-IID data partition, with differential privacy noise added to model updates during federated aggregation.
If this is right
- Standard federated learning can support mental health model training with minimal accuracy loss compared to centralized approaches.
- Differentially private federated learning introduces substantial accuracy costs for tasks that rely on sparse linguistic features.
- The sparse nature of mental health indicators in text makes them vulnerable to privacy-preserving noise.
- Evaluation across varying client fractions and privacy budgets reveals consistent patterns in performance trade-offs for these tasks.
Where Pith is reading between the lines
- Similar performance issues may arise in other prediction tasks that depend on rare but diagnostic text features, such as certain types of content moderation.
- Practitioners might need to explore privacy methods that better preserve sparse signals or combine federated learning with other protections.
- Testing on additional mental health datasets could clarify how much the observed drops depend on the specific characteristics of Twitter and Reddit data.
Load-bearing premise
That modeling each user as an isolated client in a non-IID partition reflects realistic privacy-preserving data sharing for mental health inference and that the results extend to other datasets and client settings.
What would settle it
Running the same differentially private federated learning experiments on a mental health detection task where the key predictive features are dense rather than sparse, and observing no significant performance drop.
Figures



read the original abstract
Social media text data are often used to train Machine Learning (ML) models to identify users exhibiting high-risk mental health behaviors. However, sharing this sensitive data poses privacy risks and limits the growth of benchmark datasets. We comprehensively evaluate whether privacy-preserving ML techniques can enable safer data sharing while preserving performance. Specifically, we apply federated learning (FL) and Differentially Private FL for two widely-studied mental health prediction tasks: depression detection on X (Twitter) and suicide crisis detection on Reddit. We simulate realistic data-sharing scenarios by treating each user as a client in a non-IID setting, evaluating across different client fractions, aggregation strategies, and privacy budgets. While FL achieves comparable performance to centralized training (centralized F1 = 85.63; best FL model F1 = 83.16) on depression identification, we find that Differentially Private FL has a large performance-privacy trade-off (up to F1 = 27.01 drop) even with low levels of noise (epsilon = 50). This is due to the distortion of highly informative yet sparse mental health linguistic markers related to mental health, like health topics and emotion words. This research empirically demonstrates the potential and limitations of current privacy preservation techniques for mental health inference tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates federated learning (FL) and differentially private FL (DP-FL) for mental health detection tasks on social media data: depression identification on X and suicide crisis detection on Reddit. By simulating each user as an independent client under non-IID partitions and testing varying client fractions, aggregation methods, and privacy budgets, the authors report that FL achieves near-centralized performance (best FL F1=83.16 vs centralized 85.63) while DP-FL incurs large drops (up to 27 F1 points) even at ε=50, which they attribute to distortion of sparse but informative linguistic markers such as health topics and emotion words.
Significance. If the empirical results prove robust, the work usefully quantifies the performance-privacy tension for DP-FL on sparse-feature mental-health tasks and could guide more targeted privacy research or deployment decisions in sensitive social-media inference settings.
major comments (3)
- [§4 Experimental Setup] §4 (Experimental Setup): The reported F1 scores (e.g., centralized 85.63, best FL 83.16, DP-FL down to 27.01) are given as point estimates without error bars, standard deviations, or results across multiple random seeds or data shuffles. This weakens the ability to assess whether the claimed 27-point DP-FL degradation is statistically reliable or sensitive to partitioning stochasticity.
- [§3.2 Data Partitioning] §3.2 (Data Partitioning and Client Simulation): The central performance-privacy conclusion rests on treating each user as a client in a non-IID split. No sensitivity analysis or alternative partitioning schemes (e.g., incorporating temporal posting correlations or platform-specific activity rates) are presented, leaving open whether the observed DP-FL drops are intrinsic or artifacts of this particular simulation.
- [§5 Results and Discussion] §5 (Results and Discussion): The attribution of DP-FL degradation specifically to “distortion of highly informative yet sparse mental health linguistic markers” is stated qualitatively. No supporting quantitative evidence—such as pre-/post-DP feature importance rankings, marker frequency shifts, or ablation on marker subsets—is provided to substantiate the causal link.
minor comments (2)
- [Abstract] Abstract: Specify the exact configuration (client fraction, aggregation strategy, task) that produces the maximum reported F1 drop of 27.01.
- Figure and table captions should explicitly state the number of runs or seeds used so readers can interpret variance.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help improve the clarity and robustness of our empirical evaluation. We address each major point below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [§4 Experimental Setup] The reported F1 scores (e.g., centralized 85.63, best FL 83.16, DP-FL down to 27.01) are given as point estimates without error bars, standard deviations, or results across multiple random seeds or data shuffles. This weakens the ability to assess whether the claimed 27-point DP-FL degradation is statistically reliable or sensitive to partitioning stochasticity.
Authors: We agree that single-run point estimates limit assessment of statistical reliability. In the revised manuscript we will report means and standard deviations over at least five independent random seeds for the main centralized, FL, and DP-FL configurations, and we will add error bars to the primary result tables and figures. revision: yes
-
Referee: [§3.2 Data Partitioning] The central performance-privacy conclusion rests on treating each user as a client in a non-IID split. No sensitivity analysis or alternative partitioning schemes (e.g., incorporating temporal posting correlations or platform-specific activity rates) are presented, leaving open whether the observed DP-FL drops are intrinsic or artifacts of this particular simulation.
Authors: The per-user client model directly reflects the privacy constraint that each individual’s posts cannot be shared. We will add a limitations paragraph acknowledging that alternative groupings (e.g., by posting frequency or temporal windows) could be explored in future work; however, re-running the full experimental suite under new partitions is beyond the scope of the current revision. revision: partial
-
Referee: [§5 Results and Discussion] The attribution of DP-FL degradation specifically to “distortion of highly informative yet sparse mental health linguistic markers” is stated qualitatively. No supporting quantitative evidence—such as pre-/post-DP feature importance rankings, marker frequency shifts, or ablation on marker subsets—is provided to substantiate the causal link.
Authors: We accept that the current explanation is qualitative. In the revision we will add a short quantitative subsection that reports (i) the top-20 features ranked by importance before and after noise injection and (ii) the change in frequency of health- and emotion-related tokens, thereby providing concrete support for the claimed mechanism. revision: yes
Circularity Check
No circularity: empirical measurements of FL vs. DP-FL performance
full rationale
The paper is a pure empirical evaluation study. It reports measured F1 scores from running centralized training, standard FL, and DP-FL on fixed Reddit/X datasets under explicit non-IID user-as-client partitions. The key numbers (centralized F1 = 85.63, best FL F1 = 83.16, DP-FL drops up to 27.01 at ε=50) are direct experimental outputs, not quantities derived from fitted parameters, self-referential definitions, or prior self-citations. No equations, uniqueness theorems, or ansatzes are invoked; the attribution to “sparse mental health linguistic markers” is a post-hoc interpretation of observed results rather than a load-bearing derivation. The non-IID simulation is a methodological choice whose consequences are measured, not presupposed.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption User-level data partitions produce realistic non-IID distributions that reflect privacy constraints in social media mental health data
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.