Artifact-Bench: Evaluating MLLMs on Detecting and Assessing the Artifacts of AI-Generated Videos
Pith reviewed 2026-05-20 10:22 UTC · model grok-4.3
The pith
MLLMs struggle to detect artifacts in AI-generated videos, often performing near random levels and misaligning with human judgments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that current MLLMs have substantial limitations in artifact perception and reasoning for AI-generated videos. Using Artifact-Bench and its hierarchical taxonomy, the evaluation tasks reveal that model performance frequently approaches random guessing in challenging settings and shows significant misalignment with human judgments on realism.
What carries the argument
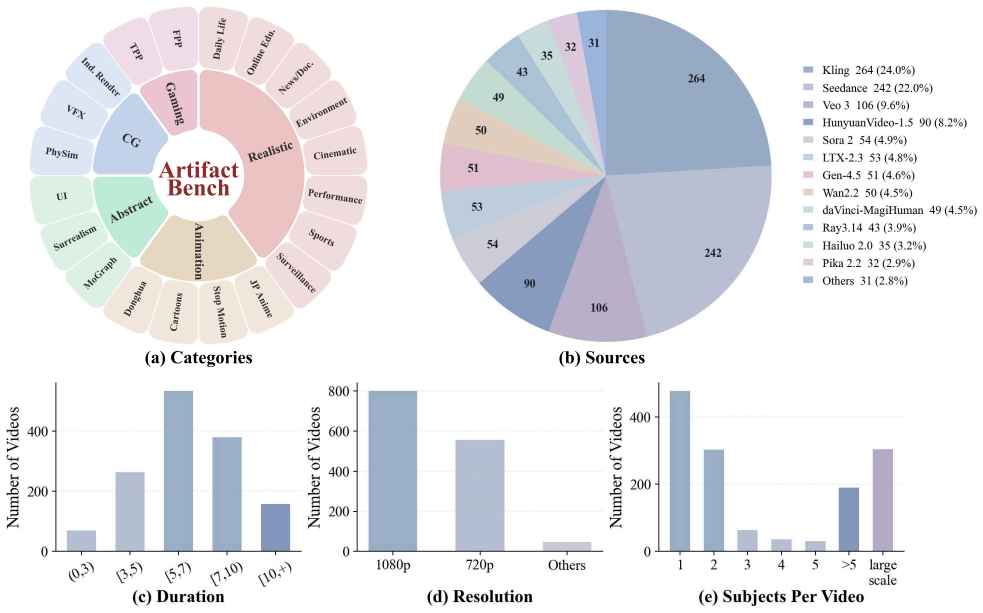
Artifact-Bench, a benchmark built on a three-level hierarchical taxonomy of realism artifacts that organizes evaluation into real-versus-generated classification, pairwise realism comparison, and fine-grained artifact identification.
If this is right
- MLLMs cannot yet serve as reliable general evaluators for AI-generated video realism.
- Artifact perception and fine-grained diagnostic reasoning remain weak points that future model development must address.
- The observed misalignment implies that current MLLM training does not adequately capture human perceptual cues for video flaws.
- The benchmark supplies a structured diagnostic tool for measuring progress across photorealistic, animated, and CG-style domains.
Where Pith is reading between the lines
- Video generation teams could adopt the benchmark to pinpoint recurring artifact patterns and guide targeted improvements in their models.
- Similar hierarchical taxonomies and multi-task setups might be applied to evaluate artifact detection in other generative media such as images or audio.
- Incorporating explicit human preference data during MLLM fine-tuning could narrow the gap between model judgments and perceptual reality.
- The benchmark's task design offers a template for creating automated metrics that better track realism advances without constant human review.
Load-bearing premise
The three-level hierarchical taxonomy of realism artifacts comprehensively captures the failure modes that matter for human perception of AI-generated video.
What would settle it
A follow-up test in which a new MLLM achieves consistently above-random accuracy on the pairwise comparison and fine-grained identification tasks while producing rankings that closely match aggregated human ratings on the same video set.
Figures






read the original abstract
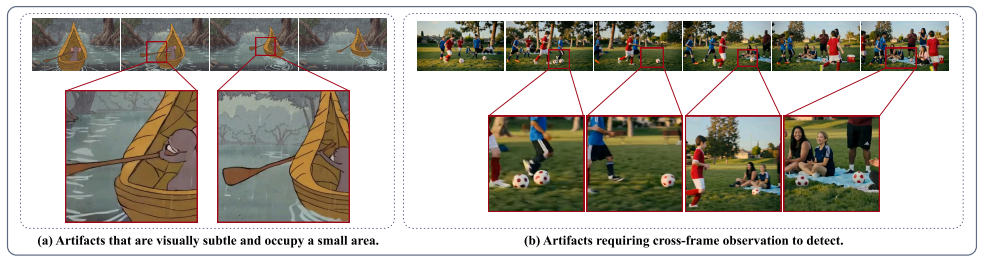
Recent video generative models have greatly improved the realism of AI-generated videos, yet their outputs still exhibit artifacts such as temporal inconsistencies, structural distortions, and semantic incoherence. While Multimodal Large Language Models (MLLMs) show strong visual understanding capabilities, their ability to perceive and reason about such artifacts remains unclear. Existing benchmarks often lack systematic evaluation of artifact-aware perception and fine-grained diagnostic reasoning, especially across diverse AI-generated video domains beyond photorealistic content. To address this gap, we introduce Artifact-Bench, a comprehensive benchmark for evaluating MLLMs on AI-generated video artifact detection and analysis. We first establish a three-level hierarchical taxonomy of realism artifacts, covering photorealistic, animated, and CG-style videos. Based on this taxonomy, Artifact-Bench defines three complementary tasks: real vs. AI-generated video classification, pairwise realism comparison, and fine-grained artifact identification. Experiments on 19 leading MLLMs reveal substantial limitations in artifact perception and reasoning, with many models approaching random or even below-random performance in challenging settings. We further observe significant misalignment between MLLM judgments and human perceptual preferences, highlighting their limited reliability as general evaluators for AI-generated video realism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Artifact-Bench, a benchmark for evaluating MLLMs on detecting and reasoning about artifacts in AI-generated videos. It defines a three-level hierarchical taxonomy of realism artifacts spanning photorealistic, animated, and CG-style videos, and defines three tasks: real vs. AI-generated classification, pairwise realism comparison, and fine-grained artifact identification. Experiments on 19 MLLMs are reported to show substantial limitations, with many models performing near or below random chance in challenging settings and exhibiting misalignment with human perceptual preferences.
Significance. If the benchmark construction and human-alignment claims hold after validation, the work would provide a useful diagnostic tool for video-generation evaluation beyond photorealistic domains and could guide improvements in MLLM perceptual reasoning. The structured taxonomy and multi-task design offer a concrete starting point for future artifact-aware benchmarks.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the claim that 19 MLLMs were evaluated with performance trends (including near/below-random results and human misalignment) is presented without any reported dataset size, number of videos per category, annotation protocol, inter-annotator agreement, statistical tests, or error bars. This directly undermines verifiability of the central empirical claims.
- [Taxonomy] Taxonomy section: the three-level hierarchy (photorealistic/animated/CG-style) is asserted to comprehensively capture relevant failure modes, yet no human-elicitation study, perceptual validation, or coverage analysis against human judgments is described. This assumption is load-bearing for the misalignment result, because low model scores could reflect taxonomy-perception mismatch rather than genuine MLLM deficits.
minor comments (2)
- [Conclusion] Add explicit release statement for the full dataset, annotations, and evaluation code to support reproducibility.
- [Task Definitions] Clarify the exact prompting templates and output parsing rules used for each of the three tasks so that results can be replicated.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which have helped us identify areas for improvement in the presentation of our work. Below, we provide point-by-point responses to the major comments and describe the revisions we plan to make.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the claim that 19 MLLMs were evaluated with performance trends (including near/below-random results and human misalignment) is presented without any reported dataset size, number of videos per category, annotation protocol, inter-annotator agreement, statistical tests, or error bars. This directly undermines verifiability of the central empirical claims.
Authors: We agree with the referee that the verifiability of our empirical claims would be strengthened by more explicit and consolidated reporting of these details. The current manuscript describes the benchmark construction and evaluation setup but does not provide a single summary of dataset sizes, category distributions, annotation protocols, inter-annotator agreement, or include error bars and statistical tests in a prominent way. We will revise the Experiments section to add a new subsection on 'Dataset and Annotation Details' that reports the total number of videos, breakdown per category and style, the annotation protocol, inter-annotator agreement scores, and we will ensure all performance metrics are accompanied by error bars and results of statistical significance tests. This will make the central claims fully verifiable. revision: yes
-
Referee: [Taxonomy] Taxonomy section: the three-level hierarchy (photorealistic/animated/CG-style) is asserted to comprehensively capture relevant failure modes, yet no human-elicitation study, perceptual validation, or coverage analysis against human judgments is described. This assumption is load-bearing for the misalignment result, because low model scores could reflect taxonomy-perception mismatch rather than genuine MLLM deficits.
Authors: We acknowledge the referee's concern that the taxonomy's comprehensiveness should be validated against human perceptions to support the misalignment findings. The taxonomy was derived from a systematic review of artifacts observed in AI-generated videos across different visual styles. However, the manuscript does not include a human-elicitation study or coverage analysis. To address this, we will conduct and report a small-scale perceptual validation study in the revised manuscript, where human participants categorize sample artifacts according to the proposed hierarchy and we measure agreement with the taxonomy. We will also discuss any observed mismatches and their implications for interpreting the MLLM results. This revision will help rule out taxonomy-perception mismatch as an alternative explanation for the observed model limitations. revision: yes
Circularity Check
No circularity: benchmark construction with independent empirical evaluation
full rationale
The paper introduces Artifact-Bench as a new evaluation framework consisting of a three-level taxonomy of artifacts across video styles and three tasks (classification, pairwise comparison, fine-grained identification). It then reports empirical results on 19 MLLMs showing performance limitations and human misalignment. No equations, parameter fits, or predictions are defined in terms of the outputs; the taxonomy and tasks are presented as author-defined constructs to address a gap, with results measured against them rather than derived from them. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The work is self-contained as an empirical benchmark study against external model evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A three-level hierarchical taxonomy covering photorealistic, animated, and CG-style videos adequately organizes all realism artifacts relevant to MLLM evaluation.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 1, 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Edit-Compass & EditReward-Compass: A Unified Benchmark for Image Editing and Reward Modeling
Xuehai Bai, Yang Shi, Yi-Fan Zhang, Xuanyu Zhu, Yuran Wang, Yifan Dai, Xinyu Liu, Yiyan Ji, Xiaoling Gu, and Yuanxing Zhang. Edit-compass & editreward-compass: A unified benchmark for image editing and reward modeling. arXiv preprint arXiv:2605.13062, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Avocado: An audiovisual video captioner driven by temporal orchestration,
Xinlong Chen, Yue Ding, Weihong Lin, Jingyun Hua, Linli Yao, Yang Shi, Bozhou Li, Yuanxing Zhang, Qiang Liu, Pengfei Wan, et al. Avocado: An audiovisual video cap- tioner driven by temporal orchestration.arXiv preprint arXiv:2510.10395, 2025. 2
-
[4]
Xinlong Chen, Yuanxing Zhang, Yushuo Guan, Bohan Zeng, Yang Shi, Sihan Yang, Pengfei Wan, Qiang Liu, Liang Wang, and Tieniu Tan. Versavid-r1: A versatile video understanding and reasoning model from question answering to captioning tasks.arXiv e-prints, pages arXiv–2506, 2025. 2
work page 2025
-
[5]
Opengpt-4o-image: A compre- hensive dataset for advanced image generation and editing
Zhihong Chen, Xuehai Bai, Yang Shi, Chaoyou Fu, Huanyu Zhang, Haotian Wang, Xiaoyan Sun, Zhang Zhang, Liang Wang, Yuanxing Zhang, et al. Opengpt-4o-image: A compre- hensive dataset for advanced image generation and editing. arXiv preprint arXiv:2509.24900, 2025. 3
-
[6]
3, 4 Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang
Zhili Cheng, Yuge Tu, Ran Li, Shiqi Dai, Jinyi Hu, Shengding Hu, Jiahao Li, Yang Shi, Tianyu Yu, Weize Chen, et al. Em- bodiedeval: Evaluate multimodal llms as embodied agents. arXiv preprint arXiv:2501.11858, 2025. 3
-
[7]
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, et al. Molmo2: Open weights and data for vision-language mod- els with video understanding and grounding.arXiv preprint arXiv:2601.10611, 2026. 7
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Google DeepMind. Gemini 3.1 pro. https://deepmind. google / models / model - cards / gemini - 3 - 1 - pro/, 2026. 1, 2, 5, 7
work page 2026
-
[9]
Google. Veo 3. https://aistudio.google.com/ models/veo-3, 2025. 1, 5
work page 2025
-
[10]
Google DeepMind. Gemini 3 flash. https://deepmind. google/models/gemini/flash/, 2025. 7
work page 2025
-
[11]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Ei- tan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning. arXiv preprint arXiv:2507.01006, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Kling ai: Video generation model
Kuaishou AI Team. Kling ai: Video generation model. https://klingai.com/, 2024. 1, 5
work page 2024
-
[14]
Aegis: Authen- ticity evaluation benchmark for ai-generated video sequences
Jieyu Li, Xin Zhang, and Joey Tianyi Zhou. Aegis: Authen- ticity evaluation benchmark for ai-generated video sequences. InProceedings of the 33rd ACM International Conference on Multimedia, page 13346 –13353. ACM, 2025. 2, 3
work page 2025
-
[15]
Skyra: Ai- generated video detection via grounded artifact reasoning,
Yifei Li, Wenzhao Zheng, Yanran Zhang, Runze Sun, Yu Zheng, Lei Chen, Jie Zhou, and Jiwen Lu. Skyra: Ai- generated video detection via grounded artifact reasoning,
-
[16]
Uve: Are mllms uni- fied evaluators for ai-generated videos?arXiv preprint arXiv:2503.09949, 2025
Yuanxin Liu, Rui Zhu, Shuhuai Ren, Jiacong Wang, Haoyuan Guo, Xu Sun, and Lu Jiang. Uve: Are mllms uni- fied evaluators for ai-generated videos?arXiv preprint arXiv:2503.09949, 2025. 2, 3
-
[17]
OpenAI. Gpt-4o. https://openai.com/index/ hello-gpt-4o/, 2024. 2
work page 2024
-
[18]
OpenAI. Gpt-4.1. https://platform.openai.com/ docs/models/gpt-4.1, 2025. 1
work page 2025
-
[19]
Mavors: Multi-granularity video representation for multimodal large language model
Yang Shi, Jiaheng Liu, Yushuo Guan, Zhenhua Wu, Yuanx- ing Zhang, Zihao Wang, Weihong Lin, Jingyun Hua, Zekun Wang, Xinlong Chen, et al. Mavors: Multi-granularity video representation for multimodal large language model. InPro- ceedings of the 33rd ACM International Conference on Multi- media, pages 10994–11003, 2025. 1, 2
work page 2025
-
[20]
Mme-videoocr: Eval- uating ocr-based capabilities of multimodal llms in video scenarios, 2025
Yang Shi, Huanqian Wang, Wulin Xie, Huanyao Zhang, Li- jie Zhao, Yi-Fan Zhang, Xinfeng Li, Chaoyou Fu, Zhuoer Wen, Wenting Liu, Zhuoran Zhang, Xinlong Chen, Bohan Zeng, Sihan Yang, Yushuo Guan, Zhang Zhang, Liang Wang, Haoxuan Li, Zhouchen Lin, Yuanxing Zhang, Pengfei Wan, Haotian Wang, and Wenjing Yang. Mme-videoocr: Eval- uating ocr-based capabilities o...
work page 2025
-
[21]
Speed by simplicity: A single-stream architecture for fast audio-video generative foundation model,
SII-GAIR and Sand.ai. Speed by simplicity: A single-stream architecture for fast audio-video generative foundation model,
-
[22]
Vf- eval: Evaluating multimodal llms for generating feedback on aigc videos
Tingyu Song, Tongyan Hu, Guo Gan, and Yilun Zhao. Vf- eval: Evaluating multimodal llms for generating feedback on aigc videos. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 21126–21146, 2025. 2, 3
work page 2025
-
[23]
Videoveritas: Ai-generated video detection via perception pretext reinforcement learning, 2026
Hao Tan, Jun Lan, Senyuan Shi, Zichang Tan, Zijian Yu, Hui- jia Zhu, Weiqiang Wang, Jun Wan, and Zhen Lei. Videoveri- tas: Ai-generated video detection via perception pretext rein- forcement learning.arXiv preprint arXiv:2602.08828, 2026. 1, 7
-
[24]
Kwai keye-vl 1.5 technical report, 2025
Kwai Keye Team. Kwai keye-vl 1.5 technical report, 2025. 7
work page 2025
-
[25]
Hunyuanvideo 1.5 technical report, 2025
Tencent Hunyuan Foundation Model Team. Hunyuanvideo 1.5 technical report, 2025. 1, 5
work page 2025
-
[26]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Di Wang, Haotian Wang, Zonghao Guo, Zefan Wang, Shan Boqi, Long Lan, Yulin Wang, et al. Geollava-8k: scaling remote-sensing multimodal large language models to 8k resolution.Ad- vances in Neural Information Processing Systems, 38:159185– 159218, 2026. 1
work page 2026
-
[28]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Yajie Yang, Yifan Zhang, Long Lan, Xue Yang, Hongda Sun, Yulin Wang, Di Wang, et al. Geoeyes: On-demand visual focusing for evidence-grounded understanding of ultra-high-resolution re- mote sensing imagery.arXiv preprint arXiv:2602.14201, 2026
-
[29]
Fengxiang Wang, Mingshuo Chen, Yueying Li, Yajie Yang, Yuhao Zhou, Di Wang, Yifan Zhang, Haoyu Wang, Haiyan Zhao, Hongda Sun, et al. Text before vision: Staged knowledge injection matters for agentic rlvr in ultra-high- resolution remote sensing understanding.arXiv preprint arXiv:2602.14225, 2026. 1
-
[30]
Monet: Reasoning in latent visual space beyond images and language,
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language,
-
[31]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265, 2025. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Haiquan Wen, Yiwei He, Zhenglin Huang, Tianxiao Li, Zihan Yu, Xingru Huang, Lu Qi, Baoyuan Wu, Xiangtai Li, and Guangliang Cheng. Busterx: Mllm-powered ai-generated video forgery detection and explanation.arXiv preprint arXiv:2505.12620, 2025. 2, 3
-
[33]
Haiquan Wen, Tianxiao Li, Zhenglin Huang, Yiwei He, and Guangliang Cheng. Busterx++: Towards unified cross-modal ai-generated content detection and explanation with mllm. arXiv preprint arXiv:2507.14632, 2025. 3, 7
-
[34]
Mimo-vl technical report, 2025
LLM-Core-Team Xiaomi. Mimo-vl technical report, 2025. 7
work page 2025
-
[35]
MiniCPM-V 4.5: Cooking Efficient MLLMs via Architecture, Data, and Training Recipe
Tianyu Yu, Zefan Wang, Chongyi Wang, Fuwei Huang, Wen- shuo Ma, Zhihui He, Tianchi Cai, Weize Chen, Yuxiang Huang, Yuanqian Zhao, et al. Minicpm-v 4.5: Cooking effi- cient mllms via architecture, data, and training recipe.arXiv preprint arXiv:2509.18154, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Debiasing multimodal large language models via penal- ization of language priors
YiFan Zhang, Yang Shi, Weichen Yu, Qingsong Wen, Xue Wang, Wenjing Yang, Zhang Zhang, Liang Wang, and Rong Jin. Debiasing multimodal large language models via penal- ization of language priors. InProceedings of the 33rd ACM International Conference on Multimedia, pages 4232–4241,
-
[37]
Mm-rlhf: The next step forward in multimodal llm alignment,
Yi-Fan Zhang, Tao Yu, Haochen Tian, Chaoyou Fu, Peiyan Li, Jianshu Zeng, Wulin Xie, Yang Shi, Huanyu Zhang, Junkang Wu, et al. Mm-rlhf: The next step forward in multimodal llm alignment.arXiv preprint arXiv:2502.10391, 2025. 2
-
[38]
When modalities conflict: How unimodal reasoning uncertainty governs preference dynamics in mllms,
Zhuoran Zhang, Tengyue Wang, Xilin Gong, Yang Shi, Hao- tian Wang, Di Wang, and Lijie Hu. When modalities conflict: How unimodal reasoning uncertainty governs preference dy- namics in mllms.arXiv preprint arXiv:2511.02243, 2025. 3
-
[39]
yes". Otherwise, classify it as
Xuanyu Zhu, Yuhao Dong, Rundong Wang, Yang Shi, Zhipeng Wu, Yinlun Peng, YiFan Zhang, Yihang Lou, Yuanx- ing Zhang, Ziwei Liu, et al. Vtc-bench: Evaluating agentic multimodal models via compositional visual tool chaining. arXiv preprint arXiv:2603.15030, 2026. 3 A. Experiment Details A.1. Experimental Setup For all evaluated models, we use a default video...
- [42]
-
[43]
Output exactly one valid answer without any additional text or explanation
-
[44]
If the response does not contain a clear final answer indicating whether the video is AI-generated, output: "Invalid" Prompt Template for Task 2: Pairwise Video Realism Comparison (PVRC) You are an answer extraction system. The original task is to compare two AI-generated videos, <Video A> and <Video B>, and determine which video has higher perceptual rea...
- [47]
-
[49]
If the response does not contain a clear final answer indicating which video is more realistic, output: "Invalid" Prompt Template for Task 3: Artifact Identification (AID) You are an answer extraction system. The original task is to identify all AIGC-specific artifacts that are clearly observable in a given AI-generated video. The candidate options are mu...
-
[50]
Ignore all reasoning, explanations, and intermedi- ate analysis
-
[51]
Focus only on the final conclusion
-
[52]
Extract only the selected option letters
-
[53]
If multiple options are selected, output them separated by commas (e.g., "A,C,E")
-
[54]
Do not output any additional text or explanation
-
[55]
Only output valid option letters that appear in the final answer
-
[56]
yes" if the video is AIGC, and
If the response does not contain a clear final answer, output: "Invalid" B. Benchmark Details B.1. Representative Examples from Artifact-Bench In order to comprehensively convey the characteristics of tasks in Artifact-Bench, two representative examples are presented for each task, as illustrated in Figures 6, 7, and 8. B.2. Task Distribution Table 3 show...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.