Fine-tuning language encoding models on slow fMRI improves prediction for fast ECoG
Pith reviewed 2026-05-20 06:44 UTC · model grok-4.3
The pith
Fine-tuning language models on fMRI data improves predictions for ECoG recordings
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
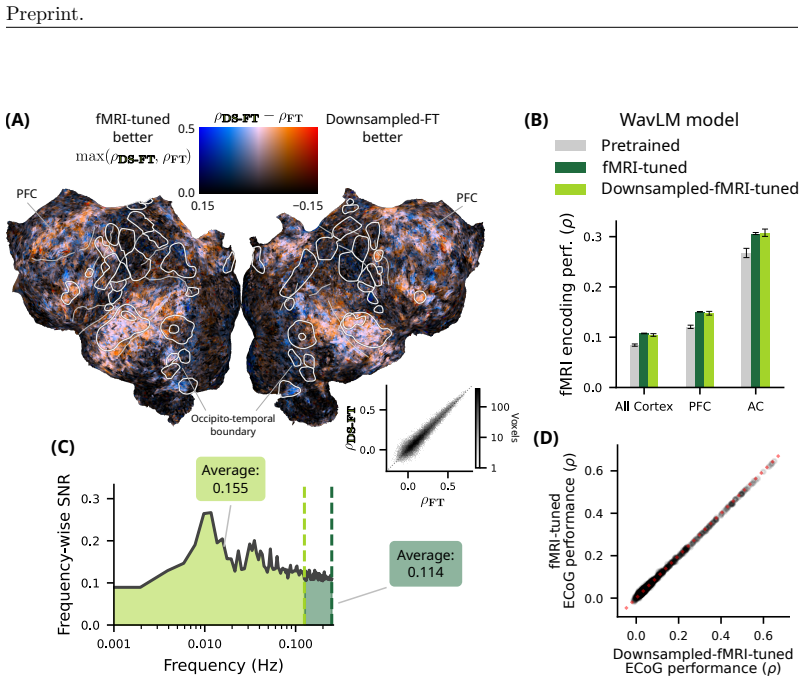
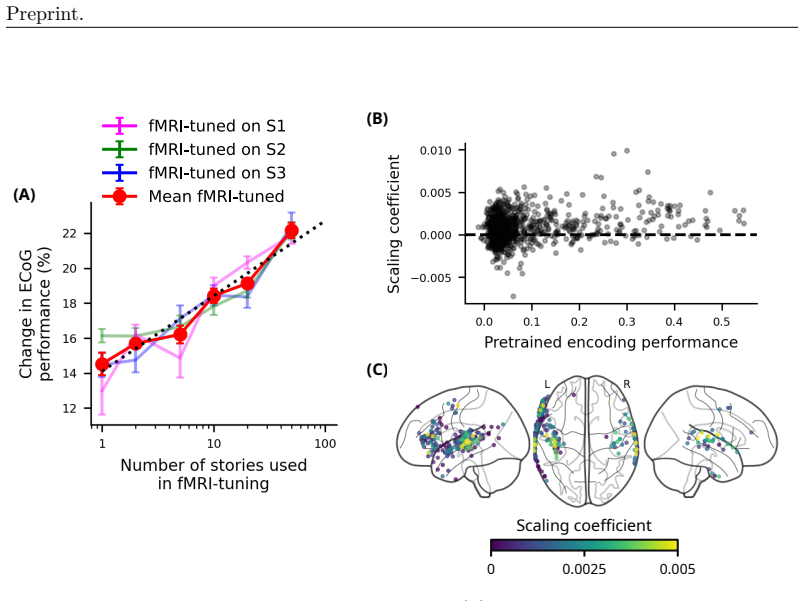
Using spoken language representations fine-tuned on fMRI, we build encoding models of ECoG. These representations showed improved prediction performance in ECoG, even though the temporal resolution of fMRI is two orders of magnitude worse. Prediction improved in frequency bands well beyond what is directly measured in fMRI. Next, to test the procedure's generalization ability, we fine-tuned models on fMRI responses that were temporally downsampled by a factor of 2. Despite the loss in resolution, these models were able to predict fMRI and ECoG responses at levels comparable to the original fMRI-tuned models. Finally, we showed that ECoG performance steadily scales with the amount of fMRI-tun
What carries the argument
Spoken language encoding models fine-tuned on fMRI responses and then applied to predict ECoG signals
If this is right
- ECoG encoding models gain accuracy from fMRI fine-tuning even for signal components faster than fMRI measures.
- The transfer remains effective after fMRI data is downsampled by a factor of two in time.
- ECoG prediction performance increases as the amount of fMRI tuning data grows.
- Combining slow and fast recording methods may support improved brain decoding applications.
Where Pith is reading between the lines
- Large public fMRI datasets could be repurposed to improve models for scarce high-resolution modalities like ECoG.
- The same fine-tuning strategy might transfer to other pairs of slow and fast brain recording techniques.
- If the scaling relationship holds, targeted collection of fMRI data for tuning could become routine for ECoG language studies.
Load-bearing premise
Fine-tuning on fMRI data produces representations that generalize to ECoG without overfitting to the slower temporal structure or introducing modality-specific biases.
What would settle it
A controlled test showing that non-fine-tuned models match or exceed the prediction accuracy of fMRI-tuned models on held-out ECoG data would falsify the central claim.
Figures







read the original abstract
Neuroscientists have recently turned to intracranial brain recording methods, like electrocorticography (ECoG), for human experiments because of the fine spatial and temporal resolution that they afford. Models trained on this data, however, are fundamentally restricted by the patient populations that can receive the implants necessary for recording. We propose using non-invasive fMRI to bridge the gap in training data. Using spoken language representations fine-tuned on fMRI, we build encoding models of ECoG. These representations showed improved prediction performance in ECoG, even though the temporal resolution of fMRI is two orders of magnitude worse. Prediction improved in frequency bands well beyond what is directly measured in fMRI. Next, to test the procedure's generalization ability, we fine-tuned models on fMRI responses that were temporally downsampled by a factor of 2. Despite the loss in resolution, these models were able to predict fMRI and ECoG responses at levels comparable to the original fMRI-tuned models. Finally, we showed that ECoG performance steadily scales with the amount of fMRI-tuning data. Our results show that "slow" data like fMRI can be a valuable resource for building better models of "fast" brain data like ECoG. In the future, integrating across multiple recording methods may further improve performance in other applications, like decoding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that fine-tuning language encoding models on fMRI data improves prediction performance for ECoG responses, despite fMRI's temporal resolution being two orders of magnitude slower. Evidence includes better ECoG predictions in high-frequency bands, comparable performance after temporally downsampling fMRI by a factor of 2, and monotonic scaling of ECoG performance with increasing volumes of fMRI tuning data.
Significance. If the central results hold, the work shows that abundant slow non-invasive data can enhance models for scarce fast invasive recordings by capturing shared semantic structure rather than modality-specific timing. The explicit downsampling and data-volume scaling controls directly test and mitigate concerns about overfitting to hemodynamics, strengthening the generalization claim. This approach could enable better multi-modal integration in language neuroscience and brain-computer interface applications.
major comments (1)
- Abstract and Results sections: the reported ECoG performance improvements lack specific quantitative metrics (e.g., Pearson r or R² values with confidence intervals), statistical tests, and baseline comparisons, which are required to evaluate whether the gains are practically meaningful and exceed what would be expected from random variation.
minor comments (2)
- Methods: provide the exact language model architecture, fine-tuning hyperparameters, and how ECoG frequency bands were aligned to the fMRI-tuned representations.
- Figure captions and Results: clarify the number of subjects, cross-validation scheme, and whether the downsampling test preserved the same fMRI voxels or used a matched subset.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address the major comment below and will strengthen the quantitative reporting in the revised manuscript.
read point-by-point responses
-
Referee: Abstract and Results sections: the reported ECoG performance improvements lack specific quantitative metrics (e.g., Pearson r or R² values with confidence intervals), statistical tests, and baseline comparisons, which are required to evaluate whether the gains are practically meaningful and exceed what would be expected from random variation.
Authors: We agree that explicit quantitative metrics, statistical tests, and baseline comparisons are necessary for rigorous evaluation. In the revised manuscript we will add Pearson r values with 95% confidence intervals for the ECoG prediction improvements in both the Abstract and Results sections. We will also report the outcomes of appropriate statistical tests (e.g., paired permutation tests) comparing the fMRI-fine-tuned models against non-fine-tuned baselines and will include these baseline results directly in the text and figures to demonstrate that the observed gains exceed what would be expected from random variation. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's derivation chain is self-contained: language representations are fine-tuned on independent fMRI datasets and then used to build encoding models evaluated on separate ECoG recordings from different subjects and modalities. Explicit controls (temporal downsampling of fMRI by a factor of 2 yielding comparable performance, and monotonic scaling of ECoG prediction with fMRI tuning data volume) directly probe and rule out overfitting to slow hemodynamics or modality-specific artifacts. No step reduces a prediction to a fitted input by construction, invokes a self-citation as a uniqueness theorem, or renames a known result; the central claim of cross-modal improvement rests on empirical generalization tests rather than definitional equivalence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brains and algorithms partially converge in natural language processing , volume =
ISSN 2399-3642. doi: 10.1038/s42003-022-03036-1. Edward F. Chang. Towards Large-Scale, Human-Based, Mesoscopic Neurotechnologies. Neuron, 86(1):68–78, April
-
[2]
doi: 10.1016/j.neuron.2015.03.037
ISSN 0896-6273. doi: 10.1016/j.neuron.2015.03.037. Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, and Furu Wei. WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing.arXiv:2...
-
[3]
doi: 10.1016/j.neuroimage.2010.06.010
ISSN 1053-8119. doi: 10.1016/j.neuroimage.2010.06.010. Abdulkadir Gokce and Martin Schrimpf. Scaling Laws for Task-Optimized Models of the Primate Visual Ventral Stream. InForty-Second International Conference on Machine Learning, June
-
[4]
doi: 10.1038/s41562-025-02105-9
ISSN 2397-3374. doi: 10.1038/s41562-025-02105-9. Liberty S. Hamilton, Erik Edwards, and Edward F. Chang. A Spatial Map of Onset and Sustained Responses to Speech in the Human Superior Temporal Gyrus.Current Biology, 28(12):1860–1871.e4, June
-
[5]
doi: 10.1016/j.cub.2018.04.033
ISSN 0960-9822. doi: 10.1016/j.cub.2018.04.033. Anne Hsu, Alexander Borst, and Frédéric E Theunissen. Quantifying variability in neural responses and its application for the validation of model predictions.Network: Computation in Neural Systems, 15(2):91–109, January
-
[6]
doi: 10.1088/ 0954-898X_15_2_002
ISSN 0954-898X, 1361-6536. doi: 10.1088/ 0954-898X_15_2_002. Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhut- dinov, and Abdelrahman Mohamed. HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units.arXiv:2106.07447 [cs, eess], June
- [7]
-
[8]
doi: 10.1523/JNEUROSCI.1779-15.2016
ISSN 0270-6474, 1529-2401. doi: 10.1523/JNEUROSCI.1779-15.2016. Shailee Jain and Alexander Huth. Incorporating Context into Language Encoding Models for fMRI. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (eds.),Advances in Neural Information Processing Systems 31, pp. 6628–6637. Curran Associates, Inc.,
-
[9]
doi: 10.1016/j.neuron.2018.03.044
ISSN 0896-6273. doi: 10.1016/j.neuron.2018.03.044. Menoua Keshishian, Gavin Mischler, Samuel Thomas, Brian Kingsbury, Stephan Bickel, Ashesh D. Mehta, and Nima Mesgarani. Parallel hierarchical encoding of linguistic representations in the human auditory cortex and recurrent automatic speech recognition systems.Nature Machine Intelligence, 8(2):257–269, February
-
[10]
Adam: A Method for Stochastic Optimization
ISSN 2522-5839. doi: 10.1038/s42256-026-01185-0. Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. arXiv:1412.6980 [cs], January
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s42256-026-01185-0
-
[11]
ISSN 2052-4463. doi: 10.1038/s41597-023-02437-z. Yuanning Li, Gopala K. Anumanchipalli, Abdelrahman Mohamed, Junfeng Lu, Jinsong Wu, and Edward F. Chang. Dissecting neural computations of the human auditory pathway using deep neural networks for speech, March
-
[12]
doi: 10.1038/ s41597-022-01645-3
ISSN 2052-4463. doi: 10.1038/ s41597-022-01645-3. Kaylo T. Littlejohn, Cheol Jun Cho, Jessie R. Liu, Alexander B. Silva, Bohan Yu, Vanessa R. Anderson, Cady M. Kurtz-Miott, Samantha Brosler, Anshul P. Kashyap, Irina P. Hallinan, Adit Shah, Adelyn Tu-Chan, Karunesh Ganguly, David A. Moses, Edward F. Chang, and Gopala K. Anumanchipalli. A streaming brain-to...
work page 2052
-
[13]
doi: 10.1038/s41593-025-01905-6
ISSN 1546-1726. doi: 10.1038/s41593-025-01905-6. Nikos K. Logothetis, Jon Pauls, Mark Augath, Torsten Trinath, and Axel Oeltermann. Neurophysiological investigation of the basis of the fMRI signal.Nature, 412(6843): 150–157, July
-
[14]
ISSN 1476-4687. doi: 10.1038/35084005. Jeremy R. Manning, Joshua Jacobs, Itzhak Fried, and Michael J. Kahana. Broadband Shifts in Local Field Potential Power Spectra Are Correlated with Single-Neuron Spiking in Humans.Journal of Neuroscience, 29(43):13613–13620, October
-
[15]
doi: 10.1523/JNEUROSCI.2041-09.2009
ISSN 0270-6474, 1529-2401. doi: 10.1523/JNEUROSCI.2041-09.2009. Takuya Matsuyama, Kota S Sasaki, and Shinji Nishimoto. Applicability of scaling laws to vision encoding models, August
-
[16]
doi: 10.1016/j.neuroimage.2022.119438
ISSN 1053-8119. doi: 10.1016/j.neuroimage.2022.119438. N. Mesgarani, C. Cheung, K. Johnson, and E. F. Chang. Phonetic Feature Encoding in Human Superior Temporal Gyrus.Science, 343(6174):1006–1010, February
-
[17]
ISSN 0036-8075, 1095-9203. doi: 10.1126/science.1245994. Juliette Millet, Charlotte Caucheteux, Pierre Orhan, Yves Boubenec, Alexandre Gramfort, Ewan Dunbar, Christophe Pallier, and Jean-Remi King. Toward a realistic model of speech processing in the brain with self-supervised learning, June
-
[18]
doi: 10.1126/science.1110913. Thomas Naselaris, Kendrick N. Kay, Shinji Nishimoto, and Jack L. Gallant. Encoding and decoding in fMRI.NeuroImage, 56(2):400–410, May
-
[19]
Kay, Shinji Nishimoto, and Jack L
ISSN 1053-8119. doi: 10.1016/j.neuroimage.2010.07.073. Anuja Negi, Subba Reddy Oota, Anwar O. Nunez-Elizalde, Manish Gupta, and Fatma Deniz. Brain-Informed Fine-Tuning for Improved Multilingual Understanding in Language Models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, October
-
[20]
doi: 10.1038/s41562-021-01261-y
ISSN 2397-3374. doi: 10.1038/s41562-021-01261-y. Subba Reddy Oota, Emin Çelik, Fatma Deniz, and Mariya Toneva. Speech language models lack important brain-relevant semantics. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.),Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 8503–8528...
-
[21]
doi: 10.18653/v1/2024.acl-long
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long
-
[22]
ISSN 1546-1726. doi: 10.1038/nn.4021. Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust Speech Recognition via Large-Scale Weak Supervision,
-
[23]
ISSN 1546-1726. doi: 10.1038/s41593-023-01304-9. 12 Preprint. Greta Tuckute, Jenelle Feather, Dana Boebinger, and Josh H. McDermott. Many but not all deep neural network audio models capture brain responses and exhibit correspondence between model stages and brain regions.PLOS Biology, 21(12):e3002366, December
-
[24]
PLOS Biology21(2023) https://doi
ISSN 1545-7885. doi: 10.1371/journal.pbio.3002366. Aditya R. Vaidya, Shailee Jain, and Alexander Huth. Self-Supervised Models of Audio Effectively Explain Human Cortical Responses to Speech. InProceedings of the 39th International Conference on Machine Learning, pp. 21927–21944. PMLR, June
-
[25]
doi: 10.1038/s41597-025-05462-2
ISSN 2052-4463. doi: 10.1038/s41597-025-05462-2. A Per-subject change in ECoG performance after fMRI-tuning In Figure 6, we visualize the per-electrode effect of fMRI-tuning separately for each subject in the “Podcast” dataset. 13 Preprint. Pretrained better fMRI-tuned better 0.1 −0.1 0.0 Figure 6: Improvement in encoding performance for all electrodes (F...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.