MetaRA: Metamorphic Robustness Assessment for Multimodal Large Language Model-based Visual Question Answering Systems
Pith reviewed 2026-05-20 07:05 UTC · model grok-4.3
The pith
MetaRA applies metamorphic relations to input variations in order to surface robustness failures in MLLM-based VQA systems that accuracy scores leave undetected.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MetaRA generates new test cases by applying predefined metamorphic relations to original image-question pairs, then measures whether the model produces logically consistent answers across the original and transformed inputs. When applied to multiple MLLM-based VQA systems, the method uncovers sensitivities to linguistic rephrasing, dependence on irrelevant visual details, and breakdowns in cross-modal reasoning that remain invisible under conventional accuracy metrics on static benchmarks.
What carries the argument
Metamorphic Relations that systematically transform image-question pairs while preserving expected answer consistency, used to generate and evaluate new test cases.
If this is right
- Models exhibit measurable sensitivity to small linguistic changes even when the underlying visual content is unchanged.
- Performance drops when questions target relations between objects rather than single-object attributes.
- Over-reliance on background or low-level visual statistics becomes detectable once inputs are varied.
- The same framework can be reused across different VQA tasks without retraining or modifying the models under test.
Where Pith is reading between the lines
- If metamorphic relations can be automatically learned rather than hand-written, the approach could scale to new domains with less manual effort.
- The diagnostic patterns might be used to guide targeted data augmentation during fine-tuning to reduce the observed weaknesses.
- Similar relations could be defined for other multimodal tasks such as image captioning or visual reasoning benchmarks.
Load-bearing premise
The selected metamorphic relations must be valid and representative probes that do not themselves create artificial inconsistencies or biases in the observed failure patterns.
What would settle it
Run MetaRA on a model whose answers remain fully consistent across all chosen relations; if the set of detected failures is no larger than the set found by standard accuracy evaluation on the same original inputs, the claim that MetaRA supplies richer diagnostics would be contradicted.
Figures




read the original abstract
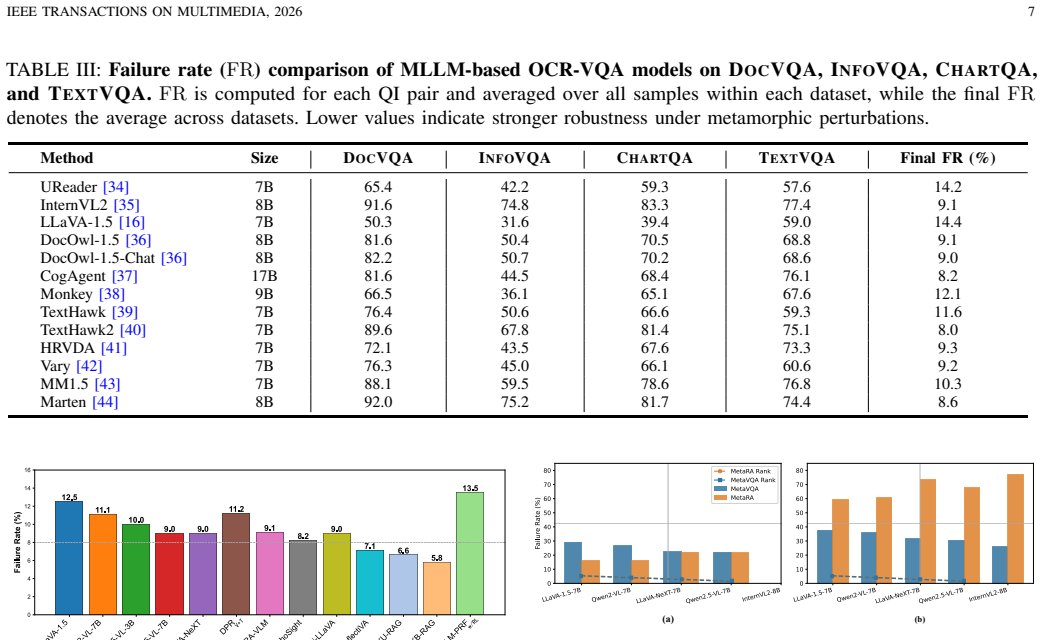
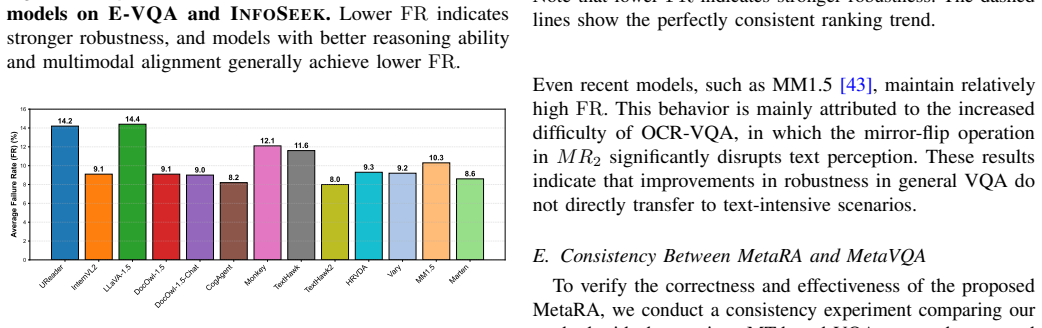
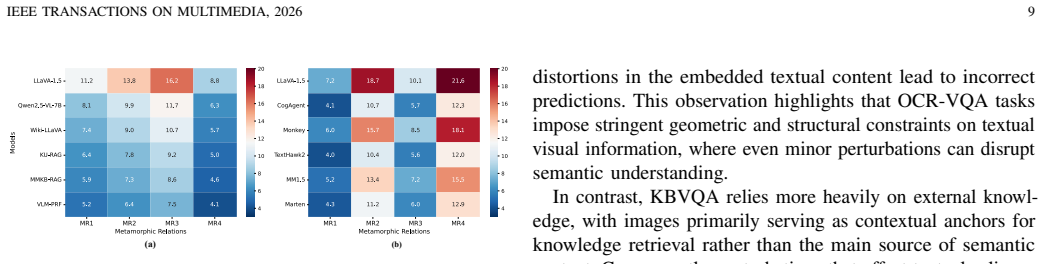
Visual Question Answering (VQA), as the representative multimodal task, serves as a key benchmark for evaluating the reasoning capabilities of Multimodal Large Language Models (MLLMs). However, existing evaluations largely rely on static datasets and accuracy-based metrics, which fail to capture robustness, consistency, and generalization. Inspired by Metamorphic Testing (MT), we propose Metamorphic Robustness Assessment (MetaRA), a testing framework that employs Metamorphic Relations (MRs) to systematically probe vulnerabilities in MLLM-based VQA systems. MetaRA generates controlled variations of image-question inputs based on specific MRs and evaluates models across diverse conditions. Applying MetaRA to multiple MLLM-based VQA models across different tasks reveals nuanced failure patterns, including sensitivity to linguistic perturbations, over-reliance on superficial visual cues, and deeper weaknesses in multimodal reasoning. Experimental results demonstrate that MetaRA provides richer diagnostic insights than conventional accuracy metrics, exposing failure modes that remain hidden under standard benchmarks. Overall, this work highlights the need for systematic robustness evaluation in VQA and positions metamorphic assessment as a scalable, model-agnostic approach toward trustworthy multimodal AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MetaRA, a framework inspired by metamorphic testing, to assess robustness in MLLM-based VQA systems. It defines metamorphic relations (MRs) to generate controlled variations of image-question inputs, applies them to multiple models across tasks, and reports that this exposes nuanced failure patterns (e.g., sensitivity to linguistic perturbations, over-reliance on superficial visual cues, and multimodal reasoning weaknesses) that standard accuracy metrics on static datasets miss. The central claim is that MetaRA yields richer diagnostic insights and is a scalable, model-agnostic approach for trustworthy multimodal AI.
Significance. If the experimental demonstration holds, the work supplies a practical, relation-driven testing method that addresses a recognized gap in VQA evaluation—namely, the inability of accuracy-only benchmarks to reveal consistency or generalization failures. The model-agnostic framing and focus on controlled input variations are positive features that could be adopted more broadly if the chosen MRs prove reliable.
major comments (2)
- [§4] §4 (Experimental Results): The manuscript asserts that MetaRA reveals failure modes hidden under standard benchmarks, yet the reported results lack quantitative comparison (e.g., number or rate of additional failures detected versus accuracy baselines) or statistical validation of the observed patterns. This weakens the load-bearing claim that the framework provides 'richer diagnostic insights.'
- [§3.2] §3.2 (Metamorphic Relations): The validity of the selected MRs as unbiased probes is assumed rather than demonstrated; without explicit checks that each transformation preserves the ground-truth answer or does not introduce its own visual/linguistic artifacts, the reported failure patterns risk being confounded by the MRs themselves.
minor comments (3)
- [Figure 2, Table 1] Figure 2 and Table 1: axis labels and legend entries are too small for readability; increase font size and add a caption that explicitly links each MR to the failure mode it is intended to expose.
- [§3.3] Notation: the definition of 'robustness score' in §3.3 is introduced without a formal equation; adding Eq. (X) would clarify how pass/fail counts are aggregated across MRs.
- [§2.2] Related work: the discussion of prior metamorphic testing applications in NLP (§2.2) omits recent VQA-specific robustness papers (e.g., on adversarial perturbations); a brief comparison would strengthen positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation of minor revision. We address each major comment point by point below, with plans to strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results): The manuscript asserts that MetaRA reveals failure modes hidden under standard benchmarks, yet the reported results lack quantitative comparison (e.g., number or rate of additional failures detected versus accuracy baselines) or statistical validation of the observed patterns. This weakens the load-bearing claim that the framework provides 'richer diagnostic insights.'
Authors: We agree that the current presentation would benefit from explicit quantitative comparisons and statistical support. In the revised version, we will add tables and figures that report the number and rate of additional failures uncovered by MetaRA relative to standard accuracy baselines across the evaluated models and tasks. We will also include statistical validation (e.g., paired significance tests or confidence intervals) on the observed differences in failure patterns to substantiate the claim of richer diagnostic insights. revision: yes
-
Referee: [§3.2] §3.2 (Metamorphic Relations): The validity of the selected MRs as unbiased probes is assumed rather than demonstrated; without explicit checks that each transformation preserves the ground-truth answer or does not introduce its own visual/linguistic artifacts, the reported failure patterns risk being confounded by the MRs themselves.
Authors: We acknowledge the value of explicit validation. Although the MRs were constructed following metamorphic testing conventions to preserve semantic equivalence (e.g., linguistic paraphrases that retain the original question intent and visual perturbations that do not alter the answer-relevant content), we agree that documenting this more rigorously would address potential concerns. In the revision, we will add a dedicated subsection with validation procedures, including manual inspection of a sample of transformed instances and automated checks confirming that ground-truth answers remain unchanged and no confounding artifacts are introduced. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper proposes MetaRA as an independent metamorphic testing framework that applies chosen relations to generate controlled input variations and then reports observed failure patterns in MLLM-based VQA models. The central claims rest on experimental outcomes rather than any equations or derivations that reduce reported insights to quantities fitted from the same evaluation data. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the framework definition and its diagnostic results remain separable and externally falsifiable.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Metamorphic relations can be formulated for multimodal VQA inputs such that expected output behavior is well-defined and independent of any particular model.
Reference graph
Works this paper leans on
-
[1]
StoryLLaV A: Enhancing visual storytelling with multi-modal large language models,
L. Yang, Z. Xiao, W. Huang, and X. Zhong, “StoryLLaV A: Enhancing visual storytelling with multi-modal large language models,” inProc. Int. Conf. Comput. Linguistics, pp. 3936–3951, 2025
work page 2025
-
[2]
Refined semantic enhancement towards frequency diffusion for video captioning,
X. Zhong, Z. Li, S. Chen, K. Jiang, C. Chen, and M. Ye, “Refined semantic enhancement towards frequency diffusion for video captioning,” inProc. AAAI Conf. Artif. Intell., pp. 3724–3732, 2023
work page 2023
-
[3]
Action-aware linguistic skeleton optimization network for non-autoregressive video captioning,
S. Chen, X. Zhong, Y . Zhang, L. Zhu, P. Li, X. Yang, and B. Sheng, “Action-aware linguistic skeleton optimization network for non-autoregressive video captioning,”ACM Trans. Multimedia Comput. Commun. Appl., vol. 20, no. 10, pp. 326:1–326:24, 2024
work page 2024
-
[4]
VQA: Visual question answering,
S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “VQA: Visual question answering,” inProc. IEEE/CVF Int. Conf. Comput. Vis., pp. 2425–2433, 2015
work page 2015
-
[5]
Making the V in VQA matter: Elevating the role of image understanding in visual question answering,
Y . Goyal, T. Khot, A. Agrawal, D. Summers-Stay, D. Batra, and D. Parikh, “Making the V in VQA matter: Elevating the role of image understanding in visual question answering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 6904–6913, 2017
work page 2017
-
[6]
Robust visual question answering: Datasets, methods, and future challenges,
J. Ma, P. Wang, D. Kong, Z. Wang, J. Liu, H. Pei, and J. Zhao, “Robust visual question answering: Datasets, methods, and future challenges,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 8, pp. 5575–5594, 2024
work page 2024
-
[7]
Metamorphic testing: a new approach for generating next test cases,
T. Y . Chen, S. Cheung, and S. Yiu, “Metamorphic testing: A new approach for generating next test cases,”arXiv preprint arXiv:2002.12543, 2002
-
[8]
KVQA: Knowledge- aware visual question answering,
S. Shah, A. Mishra, N. Yadati, and P. P. Talukdar, “KVQA: Knowledge- aware visual question answering,” inProc. AAAI Conf. Artif. Intell., pp. 8876–8884, 2019
work page 2019
-
[9]
OCR-VQA: Visual question answering by reading text in images,
A. Mishra, S. Shekhar, A. K. Singh, and A. Chakraborty, “OCR-VQA: Visual question answering by reading text in images,” inProc. Int. Conf. Document Anal. Recognit., pp. 947–952, 2019
work page 2019
-
[10]
Metamorphic testing: A review of challenges and opportunities,
T. Y . Chen, F. Kuo, H. Liu, P. Poon, D. Towey, T. H. Tse, and Z. Q. Zhou, “Metamorphic testing: A review of challenges and opportunities,” ACM Comput. Surv., vol. 51, no. 1, pp. 4:1–4:27, 2018
work page 2018
-
[11]
Perception matters: Detecting perception failures of VQA models using metamorphic testing,
Y . Yuan, S. Wang, M. Jiang, and T. Y . Chen, “Perception matters: Detecting perception failures of VQA models using metamorphic testing,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 16908– 16917, 2021
work page 2021
-
[12]
Metamorphic testing of image captioning systems via image-level reduction,
X. Xie, X. Li, and S. Chen, “Metamorphic testing of image captioning systems via image-level reduction,”IEEE Trans. Softw. Eng., vol. 50, no. 11, pp. 2962–2982, 2024
work page 2024
-
[13]
L. Wang, Y . Yuan, A. Sun, Z. Li, P. Ma, D. Wu, and S. Wang, “How multi- modal LLMs reshape visual deep learning testing? A comprehensive study through the lens of image mutation,”arXiv preprint arXiv:2404.13945, 2024
-
[14]
CLIP in mirror: Disentangling text from visual images through reflection,
T. Wang, Y . Yang, L. Yang, S. Lin, J. Zhang, G. Guo, and B. Zhang, “CLIP in mirror: Disentangling text from visual images through reflection,” inAdv. Neural Inf. Process. Syst., 2024
work page 2024
-
[15]
Order matters: Exploring or- der sensitivity in multimodal large language models,
Z. Tan, X. Chu, W. Li, and T. Mo, “Order matters: Exploring or- der sensitivity in multimodal large language models,”arXiv preprint arXiv:2410.16983, 2024
-
[16]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 26286–26296, 2024
work page 2024
-
[17]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
S. Bai, K. Chen, X. Liu, J. Wang, W. Ge, S. Song, K. Dang, P. Wang, S. Wang, J. Tang,et al., “Qwen2.5-VL technical report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
F. Li, R. Zhang, H. Zhang, Y . Zhang, B. Li, W. Li, Z. Ma, and C. Li, “LLaV A-NeXT-InterleaveTackling multi-image, video, and 3D in large multimodal models,”arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Cross-modal retrieval for knowledge-based visual question answering,
P. Lerner, O. Ferret, and C. Guinaudeau, “Cross-modal retrieval for knowledge-based visual question answering,” inProc. Eur. Conf. Inf. Retrieval, pp. 421–438, 2024
work page 2024
-
[21]
RoRA-VLM: Robust retrieval-augmented vision language models,
J. Qi, Z. Xu, R. Shao, Y . Chen, J. Di, Y . Cheng, Q. Wang, and L. Huang, “RoRA-VLM: Robust retrieval-augmented vision language models,”arXiv preprint arXiv:2410.08876, 2024
-
[22]
EchoSight: Advancing visual-language models with wiki knowledge,
Y . Yan and W. Xie, “EchoSight: Advancing visual-language models with wiki knowledge,” inFindings Conf. Empirical Methods Natural Lang. Process., pp. 1538–1551, 2024
work page 2024
-
[23]
Wiki-LLaV A: Hierarchical retrieval-augmented generation for multimodal LLMs,
D. Caffagni, F. Cocchi, N. Moratelli, S. Sarto, M. Cornia, L. Baraldi, and R. Cucchiara, “Wiki-LLaV A: Hierarchical retrieval-augmented generation for multimodal LLMs,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops, pp. 1818–1826, 2024
work page 2024
-
[24]
F. Cocchi, N. Moratelli, M. Cornia, L. Baraldi, and R. Cucchiara, “Augmenting multimodal LLMs with self-reflective tokens for knowledge- based visual question answering,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 9199–9209, 2025
work page 2025
-
[25]
Fine-grained retrieval- augmented generation for visual question answering,
Z. Zhang, Y . Wu, Y . Luo, and N. Tang, “Fine-grained retrieval- augmented generation for visual question answering,”arXiv preprint arXiv:2502.20964, 2025
-
[26]
MMKB-RAG: A multi-modal knowledge-based retrieval-augmented generation framework,
Z. Ling, Z. Guo, Y . Huang, Y . An, S. Xiao, J. Lan, X. Zhu, and B. Zheng, “MMKB-RAG: A multi-modal knowledge-based retrieval-augmented generation framework,”arXiv preprint arXiv:2504.10074, 2025
-
[27]
Knowledge-based visual question answering with multimodal processing, retrieval, and filtering,
Y . Hong, J. Gu, Q. Yang, L. Fan, Y . Wu, Y . Wang, K. Ding, S. Xiang, and J. Ye, “Knowledge-based visual question answering with multimodal processing, retrieval, and filtering,”arXiv preprint arXiv:2510.14605, 2025
-
[28]
Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories,
T. Mensink, J. Uijlings, L. Castrejon, A. Goel, F. Cadar, H. Zhou, F. Sha, A. Araujo, and V . Ferrari, “Encyclopedic VQA: Visual questions about detailed properties of fine-grained categories,” inProc. IEEE/CVF Int. Conf. Comput. Vis., pp. 3090–3101, 2023
work page 2023
-
[29]
Can pre-trained vision and language models answer visual information- seeking questions?,
Y . Chen, H. Hu, Y . Luan, H. Sun, S. Changpinyo, A. Ritter, and M. Chang, “Can pre-trained vision and language models answer visual information- seeking questions?,” inProc. Conf. Empirical Methods Natural Lang. Process., pp. 14948–14968, 2023
work page 2023
-
[30]
DocVQA: A dataset for VQA on document images,
M. Mathew, D. Karatzas, and C. V . Jawahar, “DocVQA: A dataset for VQA on document images,” inProc. IEEE/CVF Winter Conf. Appl. Comput. Vis., pp. 2199–2208, 2021
work page 2021
-
[31]
M. Mathew, V . Bagal, R. Tito, D. Karatzas, E. Valveny, and C. V . Jawahar, “InfographicVQA,” inProc. IEEE/CVF Winter Conf. Appl. Comput. Vis., pp. 2582–2591, 2022
work page 2022
-
[32]
ChartQA: A benchmark for question answering about charts with visual and logical reasoning,
A. Masry, D. X. Long, J. Q. Tan, S. R. Joty, and E. Hoque, “ChartQA: A benchmark for question answering about charts with visual and logical reasoning,” inFindings Annu. Meeting Assoc. Comput. Linguistics, pp. 2263–2279, 2022
work page 2022
-
[33]
Towards VQA models that can read,
A. Singh, V . Natarajan, M. Shah, Y . Jiang, X. Chen, D. Batra, D. Parikh, and M. Rohrbach, “Towards VQA models that can read,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 8317–8326, 2019
work page 2019
-
[34]
J. Ye, A. Hu, H. Xu, Q. Ye, M. Yan, G. Xu, C. Li, J. Tian, Q. Qian, J. Zhang, Q. Jin, L. He, X. Lin, and F. Huang, “UReader: Universal OCR-free visually situated language understanding with multimodal large language model,” inFindings Conf. Empirical Methods Natural Lang. Process., pp. 2841–2858, 2023
work page 2023
-
[35]
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y . Qiao, and J. Dai, “InternVL: Scaling up vision foundation models and aligning for generic visual- linguistic tasks,”arXiv preprint arXiv:2312.14238, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
mPLUG-DocOwl 1.5: Unified structure learning for OCR-free document understanding,
A. Hu, H. Xu, J. Ye, M. Yan, L. Zhang, B. Zhang, J. Zhang, Q. Jin, F. Huang, and J. Zhou, “mPLUG-DocOwl 1.5: Unified structure learning for OCR-free document understanding,” inFindings Conf. Empirical Methods Natural Lang. Process., pp. 3096–3120, 2024
work page 2024
-
[37]
CogAgent: A visual language model for GUI agents,
W. Hong, W. Wang, Q. Lv, J. Xu, W. Yu, J. Ji, Y . Wang, Z. Wang, Y . Dong, M. Ding, and J. Tang, “CogAgent: A visual language model for GUI agents,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 14281–14290, 2024
work page 2024
-
[38]
Monkey: Image resolution and text label are important things for large multi-modal models,
Z. Li, B. Yang, Q. Liu, Z. Ma, S. Zhang, J. Yang, Y . Sun, Y . Liu, and X. Bai, “Monkey: Image resolution and text label are important things for large multi-modal models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 26753–26763, 2024
work page 2024
-
[39]
Texthawk: Exploring efficient fine- grained perception of multimodal large language models
Y . Yu, M. Liao, J. Wu, Y . Liao, X. Zheng, and W. Zeng, “TextHawk: Exploring efficient fine-grained perception of multimodal large language models,”arXiv preprint arXiv:2404.09204, 2024
-
[40]
Y . Yu, M. Liao, J. Zhang, and J. Wu, “TextHawk2: A large vision- language model excels in bilingual OCR and grounding with 16 × fewer tokens,”arXiv preprint arXiv:2410.05261, 2024
-
[41]
HRVDA: High-resolution visual document assistant,
C. Liu, K. Yin, H. Cao, X. Jiang, X. Li, Y . Liu, D. Jiang, X. Sun, and L. Xu, “HRVDA: High-resolution visual document assistant,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 15534–15545, 2024
work page 2024
-
[42]
Vary: Scaling up the vision vocabulary for large vision- language models,
H. Wei, L. Kong, J. Chen, L. Zhao, Z. Ge, J. Yang, J. Sun, C. Han, and X. Zhang, “Vary: Scaling up the vision vocabulary for large vision- language models,” inProc. Eur. Conf. Comput. Vis., pp. 408–424, 2024
work page 2024
-
[43]
MM1.5: Methods, analysis & insights from multimodal LLM fine-tuning,
H. Zhang, M. Gao, Z. Gan, P. Dufter, N. Wenzel, F. Huang, D. Shah, X. Du, B. Zhang, Y . Li, S. Dodge, K. You, Z. Yang, A. Timofeev, M. Xu, H. Chen, J. Fauconnier, Z. Lai, H. You, Z. Wang, A. Dehghan, P. Grasch, and Y . Yang, “MM1.5: Methods, analysis & insights from multimodal LLM fine-tuning,” inProc. Int. Conf. Learn. Represent., 2025
work page 2025
-
[44]
Marten: Visual question answering with mask generation for multi-modal document understanding,
Z. Wang, T. Guan, P. Fu, C. Duan, Q. Jiang, Z. Guo, S. Guo, J. Luo, W. Shen, and X. Yang, “Marten: Visual question answering with mask generation for multi-modal document understanding,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., pp. 14460–14471, 2025. IEEE TRANSACTIONS ON MULTIMEDIA, 2026 1 SUPPLEMENTARYMATERIALS FOR MetaRA: Metamorphic Robus...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.