Retrieval-Augmented Linguistic Calibration
Pith reviewed 2026-05-20 05:43 UTC · model grok-4.3
The pith
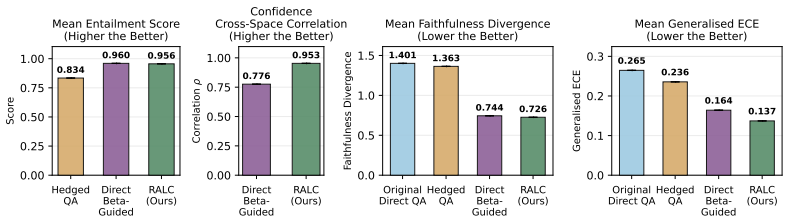
RALC improves in-domain faithfulness and calibration up to 66% and 58% by rewriting LLM outputs with retrieval-augmented calibrated linguistic expressions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling linguistic confidence as a distribution over plausible perceived probabilities and using retrieval to guide rewriting, calibrated signals can be propagated back into natural language outputs; this yields up to 66% better faithfulness and 58% better calibration than existing methods while preserving the original response style.
What carries the argument
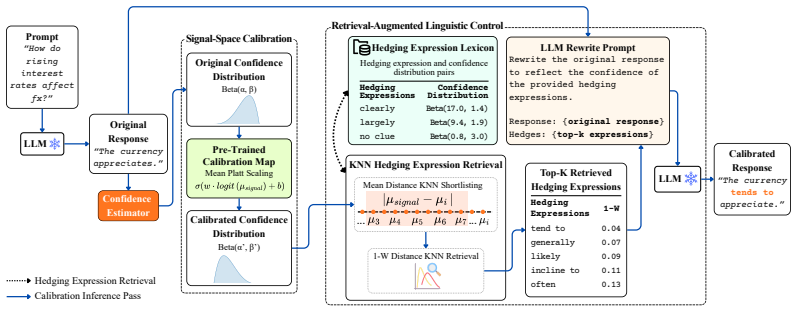
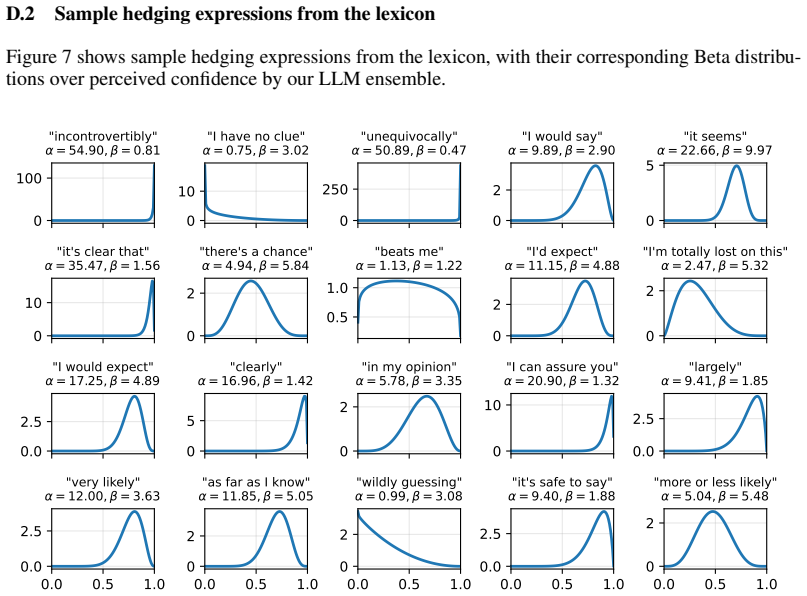
Retrieval-Augmented Linguistic Calibration (RALC), a lightweight post-hoc pipeline that retrieves relevant contexts and rewrites LLM responses to insert calibrated linguistic confidence expressions.
If this is right
- Linguistic expressions of uncertainty can be calibrated after generation without retraining or access to model internals.
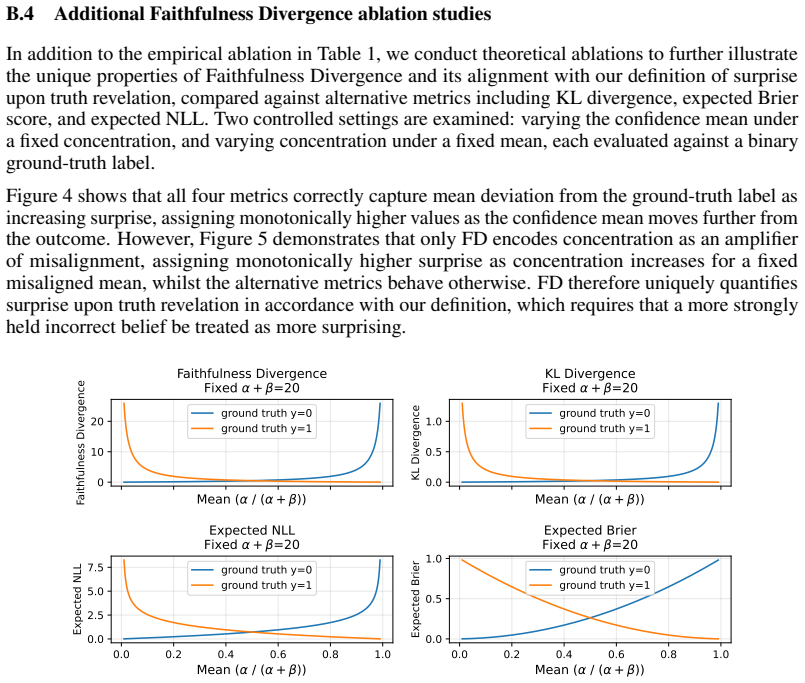
- Faithfulness Divergence supplies an evaluation axis that captures audience belief updating beyond standard expected calibration error.
- The same retrieval-rewriting pipeline outperforms both black-box and grey-box baselines on in-domain QA tasks.
- Improvements appear across multiple LLM families, indicating the approach does not depend on any single model architecture.
Where Pith is reading between the lines
- If the rewriting step can be made robust to noisy retrieval sources, the method could extend to open-domain generation where external knowledge is imperfect.
- Treating confidence as a distribution rather than a point estimate may help downstream systems that need to aggregate or compare uncertainty across multiple statements.
- The faithfulness lens could be applied to other uncertainty cues such as hedging in reasoning traces or disclaimers in long-form answers.
Load-bearing premise
Retrieval-augmented rewriting can reliably insert calibrated confidence signals without introducing new factual errors or semantic distortions that offset the reported gains.
What would settle it
If side-by-side human or automated evaluation on the same questions shows that RALC-rewritten answers contain more factual inaccuracies or altered meanings than the original LLM outputs, the net benefit of the calibration gains would be overturned.
Figures








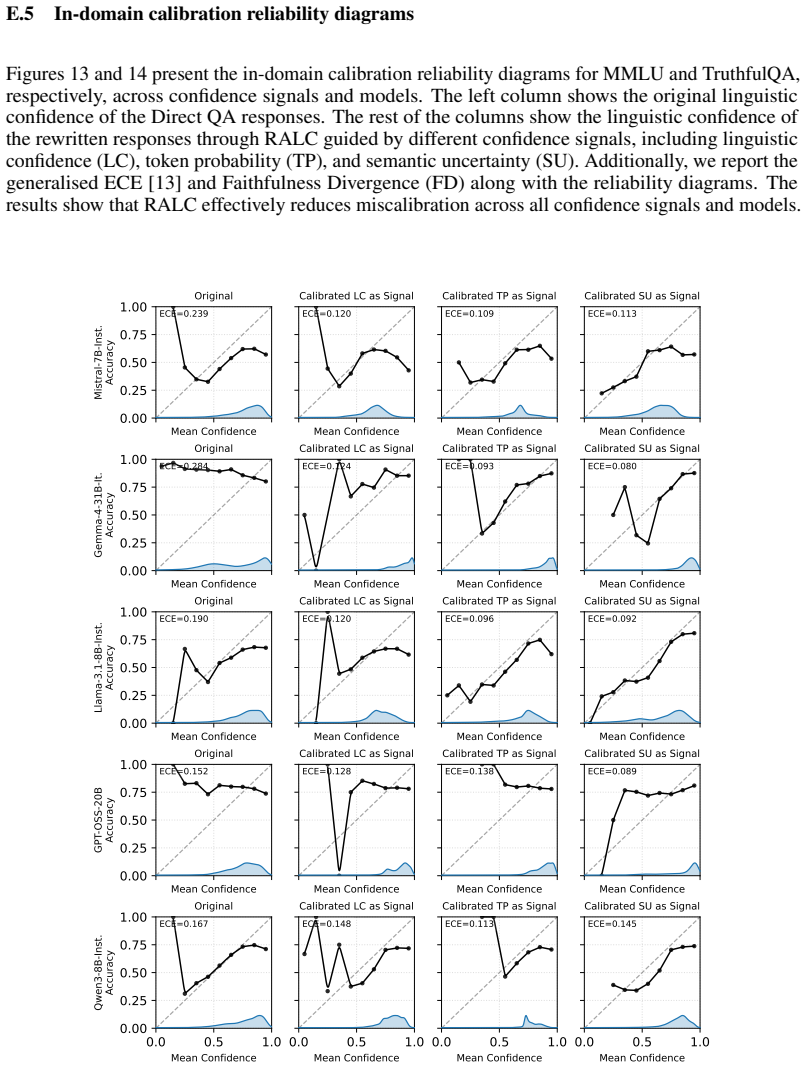

read the original abstract
Linguistic cues such as "I believe" and "probably" offer an intuitive interface for communicating confidence, yet a generalisable, principled calibration framework for linguistic confidence expressions remains underexplored. In particular, co-occurring linguistic cues, contextual variation, and subjective audience interpretation pose unique challenges. We therefore model linguistic confidence as a distribution over plausible perceived probability values that a statement is correct, capturing interpretation variability that scalar representations discard. Within this distributional framework, we introduce faithfulness as a complementary evaluation dimension and present Faithfulness Divergence (FD), an information-theoretic metric quantifying the surprise induced in audience beliefs upon truth revelation. Building on these foundations, we present Retrieval-Augmented Linguistic Calibration (RALC), a lightweight post-hoc pipeline that propagates calibrated confidence signals back into natural language via retrieval-augmented rewriting. Across three QA benchmarks and five LLM families, RALC improves in-domain faithfulness and calibration up to 66% and 58%, respectively, outperforming black-box and grey-box calibration baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a distributional framework for modeling linguistic confidence expressions in LLM outputs as distributions over perceived probabilities, capturing interpretive variability. It defines Faithfulness Divergence (FD) as an information-theoretic metric to quantify the surprise in audience beliefs upon truth revelation. Building on this, the paper proposes Retrieval-Augmented Linguistic Calibration (RALC), a lightweight post-hoc pipeline that employs retrieval-augmented rewriting to embed calibrated confidence signals into natural language statements. Experiments on three QA benchmarks across five LLM families report improvements in in-domain faithfulness and calibration of up to 66% and 58%, respectively, outperforming black-box and grey-box baselines.
Significance. If the central results hold after addressing the noted concerns, this work would contribute a principled approach to linguistic calibration that moves beyond scalar probabilities to handle co-occurring cues and audience interpretation. The introduction of FD provides a novel evaluation dimension, and RALC offers a practical, retrieval-based method for post-hoc improvement without retraining. The multi-benchmark, multi-model evaluation strengthens the empirical case for applicability in QA settings, potentially aiding more trustworthy human-AI interactions if semantic fidelity is confirmed.
major comments (2)
- [§4] §4 (RALC pipeline): The description of the retrieval-augmented rewriting step does not include quantitative controls or metrics for semantic and factual fidelity of the generated rewrites (e.g., no entailment scores, NLI checks, or human evaluations of meaning preservation). This is load-bearing for the central claim, as any introduced distortions or scope changes in the statements could artifactually inflate the reported Faithfulness Divergence reductions and calibration gains rather than reflecting genuine propagation of calibrated signals.
- [§5] §5 (Experiments): While headline improvements of up to 66% faithfulness and 58% calibration are reported, the section provides insufficient detail on baseline implementations (black-box and grey-box methods), including exact prompting strategies, hyperparameter settings, or statistical tests with error bars. This undermines assessment of whether the gains are robust and reproducible across the three QA benchmarks and five LLM families.
minor comments (2)
- [§3] Notation for the distributional confidence model in §3 could be clarified with an explicit example of how a sample statement maps to its probability distribution to aid reader comprehension.
- Figure captions in the experimental results section would benefit from more explicit descriptions of what each panel shows, particularly regarding in-domain vs. out-of-domain splits.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for highlighting the potential impact of our distributional framework and RALC pipeline. We address each major comment below and will incorporate revisions to enhance the manuscript's rigor and reproducibility.
read point-by-point responses
-
Referee: [§4] §4 (RALC pipeline): The description of the retrieval-augmented rewriting step does not include quantitative controls or metrics for semantic and factual fidelity of the generated rewrites (e.g., no entailment scores, NLI checks, or human evaluations of meaning preservation). This is load-bearing for the central claim, as any introduced distortions or scope changes in the statements could artifactually inflate the reported Faithfulness Divergence reductions and calibration gains rather than reflecting genuine propagation of calibrated signals.
Authors: We agree that explicit quantitative controls for semantic and factual fidelity are essential to substantiate that improvements arise from calibrated signals rather than meaning alterations. The RALC design retrieves from a curated corpus of verified statements to minimize drift, but the main text indeed omits NLI-based metrics or human evaluations of preservation. In the revised version, we will add a dedicated fidelity analysis subsection reporting entailment scores from a standard NLI model (e.g., average and distribution across rewrites), plus a small-scale human evaluation of meaning preservation on a sample of outputs. This will directly confirm that rewrites maintain core semantics while embedding calibrated expressions. revision: yes
-
Referee: [§5] §5 (Experiments): While headline improvements of up to 66% faithfulness and 58% calibration are reported, the section provides insufficient detail on baseline implementations (black-box and grey-box methods), including exact prompting strategies, hyperparameter settings, or statistical tests with error bars. This undermines assessment of whether the gains are robust and reproducible across the three QA benchmarks and five LLM families.
Authors: We concur that greater detail on baselines is needed for reproducibility and to demonstrate robustness. The original §5 and appendix describe the methods at a conceptual level with example prompts, but lack exhaustive templates, hyperparameter values, and statistical analysis. We will revise §5 to include: (i) verbatim prompting templates for all black-box and grey-box baselines, (ii) full hyperparameter specifications (e.g., generation temperature, retrieval k, model versions), and (iii) error bars from multiple seeds with paired statistical tests (e.g., t-tests or Wilcoxon) across the three benchmarks and five LLMs. These additions will enable independent verification of the reported gains. revision: yes
Circularity Check
No significant circularity; framework and empirical claims are self-contained
full rationale
The paper defines a distributional model of linguistic confidence, introduces Faithfulness Divergence as an information-theoretic metric, and describes RALC as a post-hoc retrieval-augmented rewriting pipeline. No equations, derivations, or fitted parameters are presented that reduce claimed improvements to inputs by construction. Reported gains (up to 66% faithfulness, 58% calibration) are positioned as empirical outcomes across benchmarks and LLM families rather than tautological predictions. No self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify core choices. The derivation chain therefore contains independent content and does not collapse to self-definition or fitted-input renaming.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We therefore model linguistic confidence as a distribution over plausible perceived probability values... introduce Faithfulness Divergence (FD), an information-theoretic metric... Retrieval-Augmented Linguistic Calibration (RALC)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.