Conflict-Resilient Multi-Agent Reasoning via Signed Graph Modeling
Pith reviewed 2026-05-20 05:42 UTC · model grok-4.3
The pith
SIGMA models inter-agent relations as a signed graph to suppress conflicts and improve multi-agent LLM reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
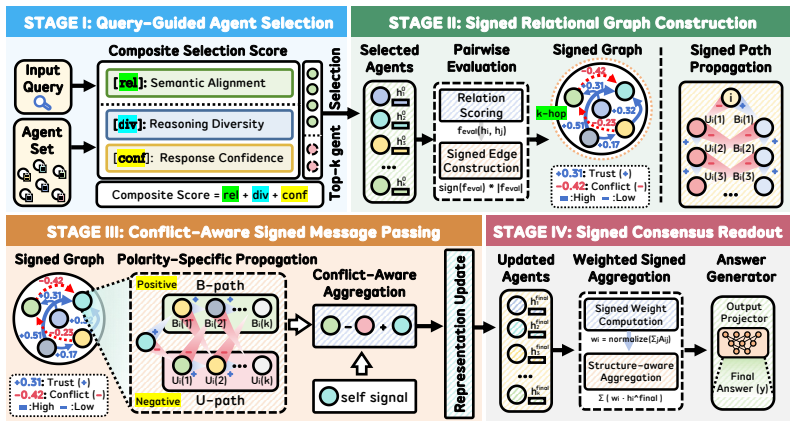
Given a query, SIGMA selects relevant and diverse agents, constructs a signed interaction graph with confidence-weighted edges that encode trust, conflict, and neutral relations, runs conflict-aware signed message passing to reinforce trustworthy agents while suppressing conflicting signals, and finishes with structure- and conflict-aware weighted aggregation that delivers globally consistent predictions.
What carries the argument
The signed relational graph with confidence-weighted edges, which enables conflict-aware signed message passing to distinguish and act on trust versus conflict relations among agents.
If this is right
- Accuracy improves on six standard benchmarks across varied LLM backbones.
- Conflict-resilient performance rises in multiple multi-agent configurations.
- The method identifies reliable interaction patterns that prior graph-based MAS frameworks miss.
- Globally consistent predictions emerge even when raw agent outputs contain opposing signals.
Where Pith is reading between the lines
- The same signed-graph construction could be tested on single-agent chain-of-thought traces by treating intermediate steps as conflicting nodes.
- Dynamic updates to the signed graph during multi-turn interactions might handle changing agent stances better than a static construction.
- Hybrid teams mixing LLMs with human experts could assign signed edges based on domain expertise to weight human input more heavily in conflicts.
Load-bearing premise
A structured signed interaction graph with confidence-weighted edges can be constructed from a query such that conflict-aware signed message passing reliably suppresses erroneous signals and yields globally consistent predictions.
What would settle it
On a benchmark dataset with deliberately injected agent conflicts where the true answer comes from the conflicting agents, if SIGMA's accuracy falls below that of simple majority or averaging baselines, the central claim would not hold.
Figures




read the original abstract
LLM-based multi-agent systems (MAS) have demonstrated strong reasoning and decision-making capabilities that consistently surpass those of single LLM agents. However, their performance often suffers from naive aggregation mechanisms that assume uniformly cooperative interactions. Upon close inspection, we observe that existing graph-based MAS frameworks (1) propagate errors when conflicting signals arise without control, and (2) lack explicit modeling of conflicting inter-agent relations as well as structural awareness, failing to identify reliable interaction patterns. To bridge this gap, we introduce SIGMA, a novel SIgned Graph-informed Multi-Agent reasoning framework that explicitly captures trust, conflict, and neutral relations among agents via a signed relational graph. Specifically, given a query, SIGMA first selects a set of relevant and diverse agents, then constructs a structured signed interaction graph with confidence-weighted edges. Reasoning proceeds through conflict-aware signed message passing, which reinforces information from trustworthy agents while suppressing conflicting signals, and terminates with a structure- and conflict-aware weighted aggregation to yield globally consistent and conflict-resilient predictions. Extensive experiments on six benchmark datasets, across multiple LLM backbones and diverse multi-agent configurations, demonstrate that SIGMA consistently outperforms state-of-the-art baselines, achieving notable gains in both accuracy and conflict-resilient performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce SIGMA, a SIgned Graph-informed Multi-Agent reasoning framework for LLM-based systems. It selects relevant agents, constructs a signed interaction graph with confidence-weighted edges to capture trust, conflict, and neutral relations, performs conflict-aware signed message passing to reinforce trustworthy information and suppress conflicts, and uses structure- and conflict-aware weighted aggregation for consistent predictions. Extensive experiments on six benchmark datasets across multiple LLM backbones and multi-agent configurations demonstrate consistent outperformance over state-of-the-art baselines in accuracy and conflict-resilient performance.
Significance. If the results are substantiated, SIGMA offers a promising approach to enhancing the reliability of multi-agent LLM reasoning by explicitly modeling conflicting inter-agent relations using signed graphs, addressing limitations in existing frameworks that propagate errors under conflicts. The framework's design provides a structured method for achieving globally consistent outputs, and the broad experimental evaluation across datasets and backbones adds to its potential impact. The work merits credit for identifying specific gaps in prior graph-based MAS approaches and proposing a targeted solution.
major comments (2)
- [Abstract] The abstract asserts 'notable gains in both accuracy and conflict-resilient performance' without providing any numerical values, standard deviations, or specific baseline comparisons. This omission is problematic as it is central to evaluating the empirical support for the outperformance claim.
- [Framework Description (likely §3)] The construction of the signed interaction graph depends on deriving edge signs and confidence weights from LLM responses or judgments. The manuscript does not include tests for robustness against variations or noise in these judgments, which could lead to incorrect conflict/trust relations and affect the reliability of the subsequent message passing and aggregation steps.
minor comments (2)
- [Abstract] The acronym SIGMA is introduced but its expansion is given as SIgned Graph-informed Multi-Agent; consider ensuring consistent capitalization.
- Some sentences in the abstract are long and could be split for improved readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment of SIGMA. We address each major comment point by point below, indicating where revisions have been made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts 'notable gains in both accuracy and conflict-resilient performance' without providing any numerical values, standard deviations, or specific baseline comparisons. This omission is problematic as it is central to evaluating the empirical support for the outperformance claim.
Authors: We agree that quantitative details strengthen the abstract's claims. In the revised manuscript we have updated the abstract to report concrete average accuracy gains of 5.3% over the strongest baselines across the six datasets (with standard deviations of 1.2-2.1% from five runs), while preserving conciseness. Full per-dataset numbers and baseline comparisons remain in Section 4 and Tables 1-3. revision: yes
-
Referee: [Framework Description (likely §3)] The construction of the signed interaction graph depends on deriving edge signs and confidence weights from LLM responses or judgments. The manuscript does not include tests for robustness against variations or noise in these judgments, which could lead to incorrect conflict/trust relations and affect the reliability of the subsequent message passing and aggregation steps.
Authors: We acknowledge this limitation in the original submission. While experiments across multiple LLM backbones and agent configurations provide indirect evidence of stability, we have added a dedicated sensitivity analysis (new Section 5.4) that injects controlled sign-flip noise into the LLM-derived judgments at rates of 10-30% and measures downstream impact. Results show graceful degradation with SIGMA still outperforming baselines; we also discuss this as a direction for future work. revision: yes
Circularity Check
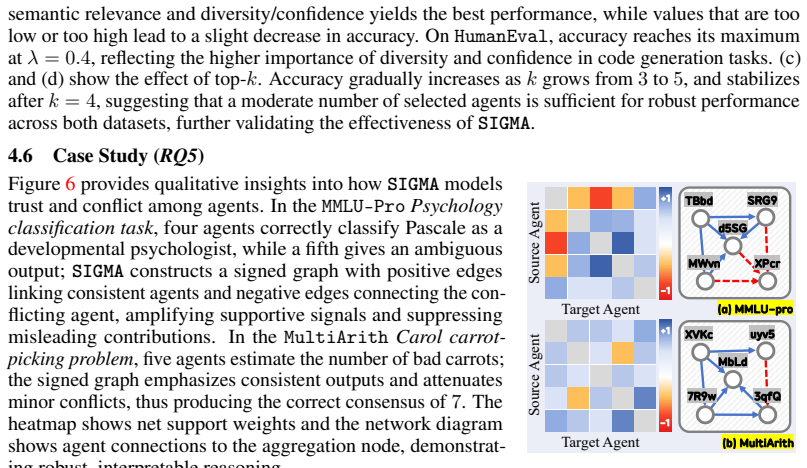
No significant circularity detected in SIGMA derivation chain
full rationale
The paper presents SIGMA as a novel construction: agent selection from a query, followed by building a signed interaction graph with confidence-weighted edges, then conflict-aware signed message passing, and finally structure-aware weighted aggregation. These steps are defined procedurally as new modeling choices rather than derived from or reduced to prior fitted parameters or self-referential definitions within the paper. Performance claims rest on empirical comparisons against external baselines across six independent benchmark datasets and multiple LLM backbones, with no equations or procedures shown to make the reported accuracy or conflict-resilience gains equivalent to quantities defined by construction inside the same work. The framework is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- edge confidence weights
axioms (2)
- domain assumption A set of relevant and diverse agents can be selected for any query
- domain assumption Signed relations (trust, conflict, neutral) among agents can be meaningfully assigned and used for message passing
invented entities (1)
-
Signed interaction graph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SIGMA constructs a structured signed interaction graph with confidence-weighted edges... conflict-aware signed message passing... reinforces information from trustworthy agents while suppressing conflicting signals
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Balance Theory... triad of nodes vi, vj, vk is balanced if the product of its edge signs = +1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
From LLM Reasoning to Autonomous AI Agents: A Comprehensive Review
Mohamed Amine Ferrag, Norbert Tihanyi, and Merouane Debbah. From llm reasoning to autonomous ai agents: A comprehensive review. arXiv preprint arXiv:2504.19678, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools
Junde Wu, Jiayuan Zhu, Yuyuan Liu, Min Xu, and Yueming Jin. Agentic reasoning: A streamlined framework for enhancing llm reasoning with agentic tools. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers) (ACL), pages 28489–28503, 2025
work page 2025
-
[3]
Beyond react: A planner-centric framework for complex tool- augmented llm reasoning
Xiaolong Wei, Yuehu Dong, Xingliang Wang, Xingyu Zhang, Zhejun Zhao, Dongdong Shen, Long Xia, and Dawei Yin. Beyond react: A planner-centric framework for complex tool- augmented llm reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 40, pages 33845–33853, 2026
work page 2026
-
[4]
Multi-Agent Collaboration Mechanisms: A Survey of LLMs
Khanh-Tung Tran, Dung Dao, Minh-Duong Nguyen, Quoc-Viet Pham, Barry O’Sullivan, and Hoang D Nguyen. Multi-agent collaboration mechanisms: A survey of llms. arXiv preprint arXiv:2501.06322, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Citysim: Modeling urban behaviors and city dynam- ics with large-scale llm-driven agent simulation
Nicolas Bougie and Narimawa Watanabe. Citysim: Modeling urban behaviors and city dynam- ics with large-scale llm-driven agent simulation. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track (EMNLP), pages 215–229, 2025
work page 2025
-
[6]
From words to actions: Unveiling the theoretical underpinnings of llm-driven autonomous systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, and Zhuoran Yang. From words to actions: Unveiling the theoretical underpinnings of llm-driven autonomous systems. In International Conference on Machine Learning (ICML), pages 17807–17841, 2024
work page 2024
-
[7]
Agents of change: Self-evolving llm agents for strategic planning
Nikolas Belle, Dakota Barnes, Alfonso Amayuelas, Ivan Bercovich, Xin Eric Wang, and William Wang. Agents of change: Self-evolving llm agents for strategic planning. arXiv preprint arXiv:2506.04651, 2025
-
[8]
Agentic llm framework for adaptive decision discourse
Antoine Dolant and Praveen Kumar. Agentic llm framework for adaptive decision discourse. arXiv preprint arXiv:2502.10978, 2025
-
[9]
Embodied agent interface: benchmarking llms for embodied decision making
Manling Li, Shiyu Zhao, Qineng Wang, Kangrui Wang, Yu Zhou, Sanjana Srivastava, Cem Gokmen, Tony Lee, Li Erran Li, Ruohan Zhang, et al. Embodied agent interface: benchmarking llms for embodied decision making. In Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS), pages 100428–100534, 2024
work page 2024
-
[10]
Automisty: a multi-agent llm framework for automated code generation in the misty social robot
Xiao Wang, Lu Dong, Sahana Rangasrinivasan, Ifeoma Nwogu, Srirangaraj Setlur, and Venu- gopal Govindaraju. Automisty: a multi-agent llm framework for automated code generation in the misty social robot. In 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 9194–9201. IEEE, 2025
work page 2025
-
[11]
A survey on large language models for code generation
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation. ACM Transactions on Software Engineering and Methodology (ACM TOSEM), 35(2):1–72, 2026
work page 2026
-
[12]
Data interpreter: An llm agent for data science
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, et al. Data interpreter: An llm agent for data science. In Findings of the Association for Computational Linguistics (ACL Findings), pages 19796– 19821, 2025
work page 2025
-
[13]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Improv- ing factuality and reasoning in language models through multiagent debate
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improv- ing factuality and reasoning in language models through multiagent debate. In International Conference on Machine Learning (ICML), 2024. 10
work page 2024
-
[15]
Junda He, Christoph Treude, and David Lo. Llm-based multi-agent systems for software engineering: Literature review, vision, and the road ahead. ACM Transactions on Software Engineering and Methodology (ACM TOSEM), 34(5):1–30, 2025
work page 2025
-
[16]
Haoyang Su, Renqi Chen, Shixiang Tang, Zhenfei Yin, Xinzhe Zheng, Jinzhe Li, Biqing Qi, Qi Wu, Hui Li, Wanli Ouyang, et al. Many heads are better than one: Improved scientific idea generation by a llm-based multi-agent system. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers) (ACL), pages 28...
work page 2025
-
[17]
LLM Multi-Agent Systems: Challenges and Open Problems
Shanshan Han, Qifan Zhang, Weizhao Jin, and Zhaozhuo Xu. Llm multi-agent systems: Challenges and open problems. arXiv preprint arXiv:2402.03578, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Cut the crap: An economical communication pipeline for llm-based multi-agent systems
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. Cut the crap: An economical communication pipeline for llm-based multi-agent systems. In International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[19]
Metagpt: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, et al. Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[20]
L2mac: Large language model automatic computer for extensive code generation
Samuel Holt, Max Ruiz Luyten, and Mihaela van der Schaar. L2mac: Large language model automatic computer for extensive code generation. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[21]
Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. Chatdev: Communicative agents for software development. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (volume 1: Long papers) (ACL), pages 15174–15186, 2024
work page 2024
-
[22]
Mixture-of- agents enhances large language model capabilities
Junlin Wang, WANG Jue, Ben Athiwaratkun, Ce Zhang, and James Zou. Mixture-of- agents enhances large language model capabilities. In International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[23]
Wenzhe Li, Yong Lin, Mengzhou Xia, and Chi Jin. Rethinking mixture-of-agents: Is mixing different large language models beneficial? arXiv preprint arXiv:2502.00674, 2025
-
[24]
Autogen: Enabling next-gen llm applications via multi-agent conversations
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. Autogen: Enabling next-gen llm applications via multi-agent conversations. In First Conference on Language Modeling (COLM), 2024
work page 2024
-
[25]
Gptswarm: Language agents as optimizable graphs
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and Jürgen Schmidhuber. Gptswarm: Language agents as optimizable graphs. In International Conference on Machine Learning (ICML), 2024
work page 2024
-
[26]
Graph-of-agents: A graph-based framework for multi-agent llm collaboration
Sukwon Yun, Jie Peng, Pingzhi Li, Wendong Fan, Jie Chen, James Zou, Guohao Li, and Tianlong Chen. Graph-of-agents: A graph-based framework for multi-agent llm collaboration. In International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[27]
G-designer: Architecting multi-agent communica- tion topologies via graph neural networks
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. G-designer: Architecting multi-agent communica- tion topologies via graph neural networks. In International Conference on Machine Learning (ICML), pages 76678–76692, 2025
work page 2025
-
[28]
Graphplanner: Graph memory-augmented agentic routing for multi-agent llms
Tao Feng, Haozhen Zhang, Zijie Lei, Peixuan Han, and Jiaxuan You. Graphplanner: Graph memory-augmented agentic routing for multi-agent llms. In International Conference on Learning Representations (ICLR), 2026
work page 2026
-
[29]
Large language model based multi-agents: a survey of progress and challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: a survey of progress and challenges. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), pages 8048–8057, 2024. 11
work page 2024
-
[30]
Learning distilled collaboration graph for multi-agent perception
Yiming Li, Shunli Ren, Pengxiang Wu, Siheng Chen, Chen Feng, and Wenjun Zhang. Learning distilled collaboration graph for multi-agent perception. InProceedings of the 35th International Conference on Neural Information Processing Systems (NeurIPS), pages 29541–29552, 2021
work page 2021
-
[31]
Thomas Zaslavsky. Signed graphs. Discrete Applied Mathematics (DAM), 4(1):47–74, 1982
work page 1982
-
[32]
Signed graph neural network with latent groups
Haoxin Liu, Ziwei Zhang, Peng Cui, Yafeng Zhang, Qiang Cui, Jiashuo Liu, and Wenwu Zhu. Signed graph neural network with latent groups. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining (SIGKDD), pages 1066–1075, 2021
work page 2021
-
[33]
Dropedge not foolproof: effective augmentation method for signed graph neural networks
Zeyu Zhang, Lu Li, Shuyan Wan, Sijie Wang, Zhiyi Wang, Zhiyuan Lu, Dong Hao, and Wanli Li. Dropedge not foolproof: effective augmentation method for signed graph neural networks. In Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS), pages 117041–117069, 2024
work page 2024
-
[34]
Signed graph convolutional networks
Tyler Derr, Yao Ma, and Jiliang Tang. Signed graph convolutional networks. In IEEE International Conference on Data Mining (ICDM), pages 929–934, 2018
work page 2018
-
[35]
Attitudes and cognitive organization
Fritz Heider. Attitudes and cognitive organization. The Journal of Psychology, 21(1):107–112, 1946
work page 1946
-
[36]
Structure balance and gradient matching-based signed graph condensation
Rong Li, Long Xu, Songbai Liu, Junkai Ji, Lingjie Li, Qiuzhen Lin, and Lijia Ma. Structure balance and gradient matching-based signed graph condensation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), volume 39, pages 12121–12129, 2025
work page 2025
-
[37]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. In Proceedings of the 34th International Conference on Neural Information Processing Systems (NeurIPS), pages 9459–9474, 2020
work page 2020
-
[38]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020
work page 2020
-
[39]
Di- versifying training pool predictability for zero-shot coordination: a theory of mind approach
Dung Nguyen, Hung Le, Kien Do, Sunil Gupta, Svetha Venkatesh, and Truyen Tran. Di- versifying training pool predictability for zero-shot coordination: a theory of mind approach. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), pages 166–174, 2024
work page 2024
-
[40]
Self-consistency improves chain of thought reasoning in language models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[41]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In International Conference on Machine Learning (ICML), pages 1050–1059, 2016
work page 2016
-
[42]
A unified theory of diversity in ensemble learning
Danny Wood, Tingting Mu, Andrew M Webb, Henry WJ Reeve, Mikel Lujan, and Gavin Brown. A unified theory of diversity in ensemble learning. Journal of Machine Learning Research (JMLR), 24(359):1–49, 2023
work page 2023
-
[43]
Multistrategy ensemble learning: Reducing error by com- bining ensemble learning techniques
Geoffrey I Webb and Zijian Zheng. Multistrategy ensemble learning: Reducing error by com- bining ensemble learning techniques. IEEE Transactions on Knowledge and Data Engineering (TKDE), 16(8):980–991, 2004
work page 2004
-
[44]
Weiqiang Jin, Hongyang Du, Biao Zhao, Xingwu Tian, Bohang Shi, and Guang Yang. A comprehensive survey on multi-agent cooperative decision-making: Scenarios, approaches, challenges and perspectives. arXiv preprint arXiv:2503.13415, 2025
-
[45]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations (ICLR), 2021. 12
work page 2021
-
[46]
Mmlu-pro: a more robust and chal- lenging multi-task language understanding benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: a more robust and chal- lenging multi-task language understanding benchmark. In Proceedings of the 38th International Conference on Neural Information Processing Systems (NeurIPS), pages 95266–95290, 2024
work page 2024
-
[47]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First Conference on Language Modeling (COLM), 2024
work page 2024
-
[48]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1743–1752, 2015
work page 2015
-
[50]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[51]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H Chi, Quoc V Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS), pages 24824–24837, 2022
work page 2022
-
[52]
Complexity-based prompting for multi-step reasoning
Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. Complexity-based prompting for multi-step reasoning. In International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[53]
Progressive-hint prompting improves reasoning in large language models
Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, and Yu Li. Progressive-hint prompt- ing improves reasoning in large language models. arXiv preprint arXiv:2304.09797, 2023
-
[54]
A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. Dynamic llm-agent net- work: An llm-agent collaboration framework with agent team optimization. arXiv preprint arXiv:2310.02170, 2023
work page internal anchor Pith review arXiv 2023
-
[55]
Chateval: Towards better llm-based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. In International Conference on Learning Representations (ICLR), 2024
work page 2024
-
[56]
Large language model as a policy teacher for training reinforcement learning agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, and Bin Liu. Large language model as a policy teacher for training reinforcement learning agents. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI), pages 5671–5679, 2024
work page 2024
-
[57]
Yoichi Ishibashi and Yoshimasa Nishimura. Self-organized agents: A llm multi-agent framework toward ultra large-scale code generation and optimization. arXiv preprint arXiv:2404.02183, 2024
-
[58]
Scaling large language model-based multi-agent collabora- tion
Chen Qian, Zihao Xie, YiFei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, et al. Scaling large language model-based multi-agent collabora- tion. In International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[59]
Masrouter: Learning to route llms for multi-agent systems
Yanwei Yue, Guibin Zhang, Boyang Liu, Guancheng Wan, Kun Wang, Dawei Cheng, and Yiyan Qi. Masrouter: Learning to route llms for multi-agent systems. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume1: Long Papers) (ACL), pages 15549–15572, 2025
work page 2025
-
[60]
Multi-agent reinforcement learning is a sequence modeling problem
Muning Wen, Jakub Grudzien Kuba, Runji Lin, Weinan Zhang, Ying Wen, Jun Wang, and Yaodong Yang. Multi-agent reinforcement learning is a sequence modeling problem. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS), pages 16509–16521, 2022. 13
work page 2022
-
[61]
Grandmaster level in starcraft ii using multi-agent reinforcement learning
Oriol Vinyals, Igor Babuschkin, Wojciech M Czarnecki, Michaël Mathieu, Andrew Dudzik, Jun- young Chung, David H Choi, Richard Powell, Timo Ewalds, Petko Georgiev, et al. Grandmaster level in starcraft ii using multi-agent reinforcement learning. Nature, 575(7782):350–354, 2019
work page 2019
-
[62]
Signal-to-noise ratios, performance criteria, and transformations
George Box. Signal-to-noise ratios, performance criteria, and transformations. Technometrics, 30(1):1–17, 1988
work page 1988
-
[63]
Minimization of functions having lipschitz continuous first partial derivatives
Larry Armijo. Minimization of functions having lipschitz continuous first partial derivatives. Pacific Journal of Mathematics (PJM), 16(1):1–3, 1966
work page 1966
-
[64]
Status-aware signed heterogeneous network embedding with graph neural networks
Wanyu Lin and Baochun Li. Status-aware signed heterogeneous network embedding with graph neural networks. IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 35(4):4580–4592, 2022
work page 2022
-
[65]
Renjie Sun, Yanping Wu, Xiaoyang Wang, Chen Chen, Wenjie Zhang, and Xuemin Lin. Clique identification in signed graphs: a balance theory based model.IEEE Transactions on Knowledge and Data Engineering (TKDE), 35(12):12513–12527, 2023
work page 2023
-
[66]
Ning Gong, Michael Korostelev, Qiangguo Ren, Li Bai, Saroj Biswas, and Frank Ferrese
Yoonhyuk Choi, Taewook Ko, Jiho Choi, and Chong-Kwon Kim. Beyond binary: Improving signed message passing in graph neural networks for multi-class graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2025. 14 Conflict-Resilient Multi-Agent Reasoning via Signed Graph Modeling Supplementary Materials Appendix Contents A Notations ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.