Self-Creative Text-to-Object Generation using Semantic-Aware Spatial Weighting
Pith reviewed 2026-05-20 05:59 UTC · model grok-4.3
The pith
A diffusion model generates more creative text-to-image objects by weighting central features and balancing semantic match against visual difference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
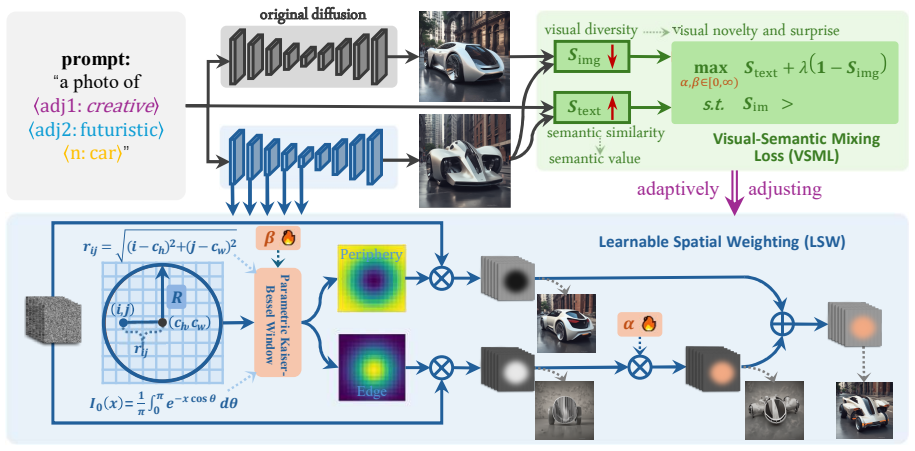
The Self-Creative Diffusion model consists of a learnable spatial weighting module that uses a parametric Kaiser-Bessel window to reinforce central image features and a visual-semantic mixing loss that combines a similarity term enforcing alignment with the text description and a diversity term that maximizes distinction from the original image, resulting in generations with improved creativity, semantic alignment, and visual coherence.
What carries the argument
Learnable spatial weighting module using a parametric Kaiser-Bessel window together with the visual-semantic mixing loss.
If this is right
- Generated images display greater visual novelty and surprise while remaining semantically aligned with the input text.
- The outputs avoid repetitive high-probability patterns typical of standard diffusion sampling.
- Central features receive amplified emphasis that drives unexpected yet coherent object arrangements.
- The approach supplies a simple add-on framework that can be applied to existing diffusion pipelines.
Where Pith is reading between the lines
- The same central-weighting idea could be tested in text-to-video or 3D generation to encourage novel motion or structure.
- Varying the strength of the diversity term would let users control how far the output departs from conventional interpretations.
- The method points toward lightweight modifications of loss functions as an alternative to retraining entire models for creative control.
Load-bearing premise
Reinforcing central features with the Kaiser-Bessel window and maximizing distinction from the original image will produce genuine creativity and artistic value without creating incoherence or artifacts.
What would settle it
Generate images from the same prompts with both the proposed model and a standard diffusion baseline, then have evaluators rate them for creativity, text alignment, and artifact presence; absence of measurable gains on creativity or coherence would refute the central claim.
Figures






















read the original abstract
Instilling creativity in text-to-image (T2I) generation presents a significant challenge, as it requires synthesized images to exhibit not only visual novelty and surprise, but also artistic value. Current T2I models, however, are largely optimized for literal text-image alignment with their data distribution, and their noise prediction networks constrain the generation to high-probability regions, consequently generating outputs that lack authentic creativity. To address this, we propose a Self-Creative Diffusion (SCDiff) model for meaningful T2I generations featuring two core modules: a learnable spatial weighting (LSW) module and a visual-semantic mixing loss (VSML). The LSW module designs a parametric Kaiser-Bessel window to reinforce central image features, fostering novel and surprising generation. The VSML module introduces a dual loss function: a similarity loss constrains that the new images align with its textual description, while a diversity loss maximizes its distinction from the original image, enhancing both semantic value and visual novelty. Extensive experiments demonstrate that our model substantially improves creativity, semantic alignment, and visual coherence, offering a simple yet powerful framework for generating creative objects.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Self-Creative Diffusion (SCDiff) model for text-to-image generation. It introduces a Learnable Spatial Weighting (LSW) module using a parametric Kaiser-Bessel window to reinforce central image features and a Visual-Semantic Mixing Loss (VSML) with a dual objective: a similarity loss to enforce text alignment and a diversity loss to maximize visual distinction from an original image. The authors claim that this combination yields generations with improved creativity, semantic alignment, and visual coherence, supported by extensive experiments.
Significance. If the empirical claims can be substantiated, the approach offers a lightweight way to inject creativity into diffusion-based T2I pipelines by combining spatial feature emphasis with a mixed visual-semantic objective, potentially addressing the tendency of standard models to remain in high-probability regions of the data distribution.
major comments (3)
- [Abstract] Abstract: the assertion that 'extensive experiments demonstrate that our model substantially improves creativity, semantic alignment, and visual coherence' supplies no quantitative metrics, baselines, datasets, or ablation tables, rendering the central empirical claim unverifiable from the provided description.
- [Method (VSML)] VSML module: the diversity term is defined relative to an 'original image' whose precise role during diffusion sampling is not specified (e.g., whether it is a fixed reference, a baseline generation, or an intermediate noisy latent); without this, it is impossible to confirm that the similarity and diversity losses remain compatible across the sampling trajectory and do not induce semantic drift or artifacts.
- [Method (LSW)] LSW module: the parametric Kaiser-Bessel window is introduced to reinforce central features for novelty, yet no analysis of parameter sensitivity, interaction with the VSML diversity weight, or failure modes (e.g., boundary artifacts or loss of global coherence) is supplied, leaving the load-bearing assumption about balanced creativity untested.
minor comments (1)
- [Title and Abstract] The title refers to 'Text-to-Object Generation' while the abstract and method consistently describe text-to-image synthesis; a brief clarification of scope would improve precision.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify key aspects of our Self-Creative Diffusion (SCDiff) approach. We address each major comment below with specific revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'extensive experiments demonstrate that our model substantially improves creativity, semantic alignment, and visual coherence' supplies no quantitative metrics, baselines, datasets, or ablation tables, rendering the central empirical claim unverifiable from the provided description.
Authors: We agree that the abstract, being a high-level summary, does not include specific quantitative details. The full manuscript reports these in the Experiments section, including metrics on creativity (e.g., via perceptual diversity scores), semantic alignment (CLIP similarity), visual coherence, baselines such as standard Stable Diffusion, and datasets like MS-COCO with ablations. To improve verifiability, we will revise the abstract to concisely reference key results, such as relative improvements in novelty while preserving alignment. revision: yes
-
Referee: [Method (VSML)] VSML module: the diversity term is defined relative to an 'original image' whose precise role during diffusion sampling is not specified (e.g., whether it is a fixed reference, a baseline generation, or an intermediate noisy latent); without this, it is impossible to confirm that the similarity and diversity losses remain compatible across the sampling trajectory and do not induce semantic drift or artifacts.
Authors: The original image serves as a fixed reference generated by the unmodified base diffusion model for the input text prompt; the diversity loss is computed in feature space against this reference during training and is incorporated into the sampling objective via a weighted combination with the similarity term. We will add explicit clarification in the revised Method section on its role as a static baseline (not an intermediate latent) and include analysis showing loss compatibility without inducing drift, supported by additional qualitative examples. revision: yes
-
Referee: [Method (LSW)] LSW module: the parametric Kaiser-Bessel window is introduced to reinforce central features for novelty, yet no analysis of parameter sensitivity, interaction with the VSML diversity weight, or failure modes (e.g., boundary artifacts or loss of global coherence) is supplied, leaving the load-bearing assumption about balanced creativity untested.
Authors: We acknowledge that the current manuscript lacks dedicated sensitivity analysis for the Kaiser-Bessel parameters and their interplay with the VSML diversity weight. In the revision, we will incorporate an ablation study varying the window parameters (e.g., shape factor and size) and diversity weighting coefficient, along with discussion of failure modes such as boundary effects, demonstrating through experiments that global coherence is preserved via the parametric design and central emphasis. revision: yes
Circularity Check
VSML diversity loss reduces to distinction from 'original image' by construction
specific steps
-
self definitional
[Abstract]
"The VSML module introduces a dual loss function: a similarity loss constrains that the new images align with its textual description, while a diversity loss maximizes its distinction from the original image, enhancing both semantic value and visual novelty."
The diversity loss is defined to maximize distinction from the original image, and the paper immediately presents this construction as 'enhancing ... visual novelty.' Novelty is thereby achieved by definition of the loss rather than derived or validated independently of the optimization target.
full rationale
The paper proposes SCDiff with LSW and VSML to instill creativity. The VSML diversity term is explicitly constructed to maximize distinction from an original image during generation, and the abstract directly equates this to enhanced novelty and creativity. This makes the core claim of improved visual novelty a direct consequence of the loss definition rather than an independent outcome. However, the LSW module and experimental claims retain some independent content, and no self-citation chain or mathematical derivation reduces the entire result to inputs. The paper remains largely self-contained via its empirical validation.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Learnable Spatial Weighting (LSW) module
no independent evidence
-
Visual-Semantic Mixing Loss (VSML)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Auto-encoding variational bayes,
D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” inICLR, 2014. 11
work page 2014
-
[2]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. Voss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inProceedings of the 38th International Conference on Machine Learning, 2021, pp. 8821–8831
work page 2021
-
[3]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” inCVPR, 2022, pp. 10674–10685
work page 2022
-
[4]
Texfusion: Synthesizing 3d textures with text-guided image diffusion models,
T. Cao, K. Kreis, S. Fidler, N. Sharp, and K. Yin, “Texfusion: Synthesizing 3d textures with text-guided image diffusion models,” inICCV, 2023, pp. 4146–4158
work page 2023
-
[5]
C.-W. Liao, H.-W. Chen, B.-S. Chen, I.-C. Wang, W.-S. Ho, and W.-L. Huang, “Exploring the application of text-to-image generation technology in art education at vocational senior high schools in taiwan,”Information, vol. 16, no. 5, 2025
work page 2025
-
[6]
Diffusion model for image generation - a survey,
X. Hu, Y. Jin, J. Liang, J. Liu, R. Luo, M. Li, and T. Peng, “Diffusion model for image generation - a survey,” in2023 2nd International Conference on Artificial Intelligence, Human-Computer Interaction and Robotics (AIHCIR), 2023, pp. 416–424
work page 2023
-
[7]
How does text-to-image ai affect indie game designers and artists?
J. Qin, “How does text-to-image ai affect indie game designers and artists?”Journal of Innovation and Development, pp. 107–111, 2023
work page 2023
-
[8]
Conceptlab: Creative concept generation using vlm-guided diffusion prior constraints,
E. Richardson, K. Goldberg, Y. Alaluf, and D. Cohen-Or, “Conceptlab: Creative concept generation using vlm-guided diffusion prior constraints,”ACM Transactions on Graphics(TOG), vol. 43, no. 3, 2024
work page 2024
-
[9]
Tp2o: Creative text pair-to-object generation using balance swap-sampling,
J. Li, Z. Zhang, and J. Yang, “Tp2o: Creative text pair-to-object generation using balance swap-sampling,” inECCV, 2024, pp. 92–111
work page 2024
-
[10]
Novel object synthesis via adaptive text-image harmony,
Z. Xiong, Z. Zhang, Z. Chen, S. Chen, X. Li, G. Sun, J. Yang, and J. Li, “Novel object synthesis via adaptive text-image harmony,” inProceedings of the 38th Conference on Neural Information Processing Systems, vol. 37, 2024, pp. 139085–139113
work page 2024
-
[11]
Can: Creative adversarial networks, generating
A. Elgammal, B. Liu, M. Elhoseiny, and M. Mazzone, “Can: Creative adversarial networks, generating "art" by learning about styles and deviating from style norms,” inInternational Conference on Innovative Computing and Cloud Computing, 2017
work page 2017
-
[12]
Enhancing creative generation on stable diffusion-based models,
J. Han, D. Kwon, G. Lee, J. Kim, and J. Choi, “Enhancing creative generation on stable diffusion-based models,” inCVPR, 2025, pp. 28609–28618
work page 2025
-
[13]
M. A. Boden,The creative mind-Myths and mechanisms. Taylor & Francis e-Library, 2004
work page 2004
-
[14]
Sdxl-lightning: Progressive adversarial diffusion distillation,
S. Lin, A. Wang, and X. Yang, “Sdxl-lightning: Progressive adversarial diffusion distillation,” 2024
work page 2024
-
[15]
Adversarial diffusion distillation,
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach, “Adversarial diffusion distillation,” in ECCV, 2024, p. 87–103
work page 2024
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inNeurIPS, vol. 33, 2020, pp. 6840–6851
work page 2020
-
[17]
SDXL: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rom- bach, “SDXL: Improving latent diffusion models for high-resolution image synthesis,” inICLR, 2024. 12
work page 2024
-
[18]
A taxonomy of prompt modifiers for text-to-image generation,
J. Oppenlaender, “A taxonomy of prompt modifiers for text-to-image generation,”Behaviour & Information Technology, pp. 3763–3776, 2024
work page 2024
-
[19]
Role bias in diffusion models: Diagnosing and mitigating through intermediate decomposition,
S. Malakouti and A. Kovashka, “Role bias in diffusion models: Diagnosing and mitigating through intermediate decomposition,” inAdvances in Neural Information Processing Systems, vol. 38, 2025, pp. 84668–84699
work page 2025
-
[20]
Z. Tan, M. Yang, L. Qin, H. Yang, Y. Qian, Q. Zhou, C. Zhang, and H. Li, “An empirical study andanalysis of text-to-image generation using large language model-powered textual representation,” inECCV, 2024, pp. 472–489
work page 2024
-
[21]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical image computing and computer-assisted intervention(MICCAI), 2015, pp. 234–241
work page 2015
-
[22]
R. N. Bracewell,The Fourier Transform and Its Applications. McGraw-Hill, 2000
work page 2000
-
[23]
R. C. Gonzalez and R. E. Woods,Digital Image Processing, 4th ed. Pearson, 2018
work page 2018
-
[24]
Nonrecursive digital filters: A new approach to filtering,
J. F. Kaiser, “Nonrecursive digital filters: A new approach to filtering,”IEEE Transactions on Audio and Electroacoustics, 1974
work page 1974
-
[25]
Advanced kaiser-bessel window function techniques,
P. Dobson and C. R. Cox, “Advanced kaiser-bessel window function techniques,”Journal of Sound and Vibration, 1994
work page 1994
-
[26]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gon- tijo Lopes, B. Karagol Ayan, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi, “Photorealistic text-to-image diffusion models with deep language understanding,” inAdvances in Neural Information Processing Systems, vol. 35, 2022, pp. 36479–36494
work page 2022
-
[27]
OpenAI, “Gpt-4o system card,” 2024. [Online]. Available: https://openai.com/index/ hello-gpt-4o/
work page 2024
-
[28]
An analytic theory of creativity in convolutional diffusion models,
M. Kamb and S. Ganguli, “An analytic theory of creativity in convolutional diffusion models,” inForty-second International Conference on Machine Learning, 2025
work page 2025
-
[29]
Concept decomposition for visual exploration and inspiration,
Y. Vinker, A. Voynov, D. Cohen-Or, and A. Shamir, “Concept decomposition for visual exploration and inspiration,”ACM Transactions on Graphics, vol. 42, no. 6, 2023
work page 2023
-
[30]
Conceptcraft: One-shot personalized text-to- image generation via object-background disentanglement,
H. Chen, Z. Zuo, L. Zhao, J. Li, and J. Yang, “Conceptcraft: One-shot personalized text-to- image generation via object-background disentanglement,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[31]
Trtst: Arbitrary high-quality text-guided style transfer with transformers,
H. Chen, Z. Wang, L. Zhao, J. Li, and J. Yang, “Trtst: Arbitrary high-quality text-guided style transfer with transformers,”IEEE Transactions on Image Processing, vol. 34, pp. 759–771, 2025
work page 2025
-
[32]
Redefining in dictionary: Towards an enhanced semantic understanding of creative generation,
F. Feng, Y. Xie, X. Yang, J. Wang, and X. Geng, “Redefining in dictionary: Towards an enhanced semantic understanding of creative generation,”2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 18444–18454, 2025
work page 2025
-
[33]
Partcraft: Crafting creative objects by parts,
K. W. Ng, X. Zhu, Y.-Z. Song, and T. Xiang, “Partcraft: Crafting creative objects by parts,” in ECCV, 2024, pp. 420–437. 13
work page 2024
-
[34]
Agswap: Overcoming category boundaries in object fusion via adaptive group swapping,
Z. Zhang, Y. ji Tai, J. Qian, J. Yang, and J. Li, “Agswap: Overcoming category boundaries in object fusion via adaptive group swapping,”Proceedings of the SIGGRAPH Asia 2025 Conference Papers, 2025
work page 2025
-
[35]
Dmfft: Improving the generation quality of diffusion models using fast fourier transform,
C. Yu, C. Han, and C. Zhang, “Dmfft: Improving the generation quality of diffusion models using fast fourier transform,”Scientific Reports, vol. 15, p. 10200, 2025
work page 2025
-
[36]
Procreate, don’t reproduce! propulsive energy diffusion for creative generation,
J. Lu, R. Teehan, and M. Ren, “Procreate, don’t reproduce! propulsive energy diffusion for creative generation,” inECCV, 2024
work page 2024
-
[37]
Searching for computational creativity,
G. A. Wiggins, “Searching for computational creativity,”New Generation Computing, vol. 24, no. 3, pp. 209–222, 2006
work page 2006
-
[38]
G. N. Watson,A treatise on the theory of Bessel functions. Cambridge university press, 1995
work page 1995
-
[39]
On the use of windows for harmonic analysis with the discrete fourier transform,
F. J. Harris, “On the use of windows for harmonic analysis with the discrete fourier transform,” Proceedings of the IEEE, vol. 66, no. 1, pp. 51–83, 1978
work page 1978
-
[40]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” inProceedings of the 38th International Conference on Machine Learning(ICML), 2021, pp. 8748–8763
work page 2021
-
[41]
Quantifying creativity in art networks,
A. Elgammal and B. Saleh, “Quantifying creativity in art networks,” inICCC, 2015
work page 2015
-
[42]
Practical bayesian optimization of machine learning algorithms,
J. Snoek, H. Larochelle, and R. P. Adams, “Practical bayesian optimization of machine learning algorithms,” inNeural Information Processing Systems, 2012
work page 2012
-
[43]
Implementationofthesimultaneousperturbationalgorithmforstochasticoptimization,
J.Spall, “Implementationofthesimultaneousperturbationalgorithmforstochasticoptimization,” IEEE Transactions on Aerospace and Electronic Systems, vol. 34, no. 3, pp. 817–823, 1998
work page 1998
-
[44]
H. Liu, C. Li, Q. Wu, and Y. J. Lee, “Visual instruction tuning,” inAdvances in Neural Information Processing Systems, 2023, pp. 34892–34916
work page 2023
-
[45]
Spectral distribution aware image generation,
S. Jung and M. Keuper, “Spectral distribution aware image generation,” inAAAI Conference on Artificial Intelligence, 2020
work page 2020
-
[46]
Assessing generative models via precision and recall,
M. S. M. Sajjadi, O. Bachem, M. Lucic, O. Bousquet, and S. Gelly, “Assessing generative models via precision and recall,” inProceedings of the 32nd International Conference on Neural Information Processing Systems, 2018, pp. 5234–5243
work page 2018
-
[47]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,”CVPR, pp. 586–595, 2018
work page 2018
-
[48]
Improving geo-diversity of generated images with contextualized vendi score guidance,
R. Askari Hemmat, M. Hall, A. Sun, C. Ross, M. Drozdzal, and A. Romero-Soriano, “Improving geo-diversity of generated images with contextualized vendi score guidance,” inECCV, 2024, pp. 213–229
work page 2024
-
[49]
Scaling rectified flow transformers for high-resolution image synthesis,
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, F. Boesel, D. Podell, T. Dockhorn, Z. English, and R. Rombach, “Scaling rectified flow transformers for high-resolution image synthesis,” inProceedings of the 41st International Conference on Machine Learning, vol. 235, 2024, pp. 12606–12633
work page 2024
-
[50]
B. F. Labs, “Flux.1-dev,” https://huggingface.co/black-forest-labs/FLUX.1-dev, 2024. 14 This supplementary material provides additional technical details and extended results to support the main paper. First, in Section A, we analyze the impact of feature enhancement across different U-Net blocks. Section B details the hierarchical Bayesian-SPSA optimizat...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.