D-CLING: Prior-Preserving Depth-Conditioned Fine-Tuning for Navigation Foundation Models
Pith reviewed 2026-05-20 05:40 UTC · model grok-4.3
The pith
Attaching a zero-initialized residual copy of a pre-trained navigation backbone lets models learn in-domain geometry without eroding general priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
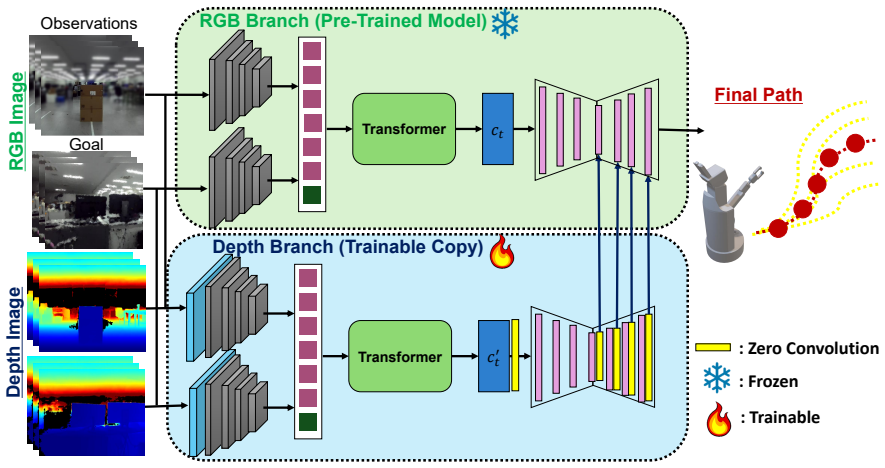
By freezing the original pre-trained weights and training only a parallel copy linked by zero-initialized residuals, the fine-tuning step adds depth-conditioned geometric adjustments that correct for new camera setups or environments while the preserved prior pathways keep the model from losing cross-domain navigation competence.
What carries the argument
Zero-initialized residual pathways that link a trainable duplicate of the pre-trained visual backbone to the frozen original network, enabling additive depth-conditioned learning.
If this is right
- Long-horizon navigation runs become feasible with fewer obstacles hit and less need for human overrides.
- Action prediction accuracy on held-out data stays stable or rises after the fine-tuning step.
- The same structure supports adaptation to changed camera placements or new indoor layouts without full retraining.
- Continual learning for navigation models becomes practical because prior knowledge is explicitly guarded during updates.
Where Pith is reading between the lines
- The residual-copy design may transfer to other visuomotor foundation models that need domain-specific calibration without catastrophic forgetting.
- Similar zero-init residual blocks could be tested on non-navigation tasks such as manipulation or locomotion to check whether the preservation effect generalizes.
- Measuring how the residual pathways evolve during training might reveal the exact balance between geometric specialization and retained generality.
- The method hints that explicit separation of prior and adaptation pathways could reduce the data needed for safe robot deployment in new sites.
Load-bearing premise
The copied backbone connected by zero-initialized residuals can absorb new geometric details without disrupting the behaviors already encoded in the pre-trained weights.
What would settle it
A head-to-head real-world trial in which the D-CLING model produces more collisions, more goal failures, or more human interventions than either the untouched pre-trained model or a conventionally fine-tuned version on the same novel setup.
Figures






read the original abstract
Navigation Foundation Models (NFMs) trained on large cross-embodied datasets have demonstrated powerful generalizability in various scenarios. Adopting in-domain fine-tuning for an NFM efficiently calibrates the visuomotor policy, promising further improvement even in a novel scenario. However, the fine-tuned models still suffer from poor obstacle avoidance or fail to properly reach the provided goals. Furthermore, model updates using a small subset of data typically erode the pre-trained prior, compromising the pre-training generalization. Consequently, fine-tuning deteriorates the capability of the model for robust and accurate navigation. In this work, we present a novel fine-tuning method that leverages large-scale pre-training while efficiently learning in novel setups, such as environments or camera configurations. In particular, inspired by ControlNet, we fine-tune an NFM by attaching a trainable copy of the pre-trained backbone using zero-initialized residual pathways, thereby learning geometric cues. This design enables the model to efficiently acquire in-domain geometry while preserving pre-trained knowledge across various behaviors. Despite its simplicity, our comprehensive evaluation of real-world navigation suggests that our proposal effectively enables robust long-horizon navigation with minimal collisions and human intervention. Additionally, our offline analysis shows that the proposed method maintains or further improves action prediction capabilities beyond the fine-tuned dataset, providing a key insight into continual learning for general navigation. The project page: https://toyotafrc.github.io/DCLING-Proj/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes D-CLING, a fine-tuning technique for Navigation Foundation Models (NFMs) that attaches a trainable copy of the pre-trained backbone via zero-initialized residual pathways, inspired by ControlNet. This design is intended to enable efficient acquisition of in-domain geometric cues (e.g., from depth conditioning) in novel environments or camera configurations while preserving pre-trained cross-behavior priors. The authors claim that the resulting models achieve robust real-world long-horizon navigation with minimal collisions and human intervention, and that offline analysis shows the method maintains or improves action-prediction performance beyond the fine-tuned dataset.
Significance. If the central claims are substantiated, the work would provide a simple architectural safeguard for continual learning in visuomotor navigation policies, addressing the common tension between domain adaptation and retention of large-scale pre-training generalization. The emphasis on depth-conditioned fine-tuning and the ControlNet-style residual attachment could be a practical contribution for deploying NFMs across diverse robotic setups.
major comments (2)
- [Abstract] Abstract: The claims of 'robust long-horizon navigation with minimal collisions and human intervention' and 'maintains or further improves action prediction capabilities beyond the fine-tuned dataset' are asserted without any quantitative metrics, baselines, ablation studies, or error analysis. This absence makes it impossible to evaluate whether the data support the central claims.
- [Method] Method section (ControlNet-inspired attachment): The key assumption that zero-initialized residual pathways preserve pre-trained generalization on out-of-domain behaviors lacks supporting controls. No before/after comparisons on held-out pre-training distributions, no ablation removing the zero-init or residual structure, and no direct contrast to standard fine-tuning (which the paper states erodes priors) are provided. Without these, it remains possible that any robustness derives from the fine-tuning data distribution rather than the architectural choice.
minor comments (2)
- [Abstract] The project page URL is given but no statement on code or model release appears in the manuscript; adding this would aid reproducibility.
- [Method] Notation for the residual pathways and depth conditioning could be clarified with a diagram or explicit equations in the method description.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive feedback on our manuscript. We address each major comment below and outline revisions that will strengthen the presentation of our results and the supporting evidence for the architectural design.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims of 'robust long-horizon navigation with minimal collisions and human intervention' and 'maintains or further improves action prediction capabilities beyond the fine-tuned dataset' are asserted without any quantitative metrics, baselines, ablation studies, or error analysis. This absence makes it impossible to evaluate whether the data support the central claims.
Authors: We agree that the abstract would benefit from explicit quantitative support. The full manuscript reports real-world navigation results across multiple environments and camera setups, including success rates, collision counts, and human intervention frequency relative to the pre-trained baseline and standard fine-tuning. Offline action-prediction accuracy is also evaluated on held-out sequences. We will revise the abstract to include the key numerical outcomes (e.g., success rate, average collisions per episode) so that the central claims are directly substantiated by the reported metrics. revision: yes
-
Referee: [Method] Method section (ControlNet-inspired attachment): The key assumption that zero-initialized residual pathways preserve pre-trained generalization on out-of-domain behaviors lacks supporting controls. No before/after comparisons on held-out pre-training distributions, no ablation removing the zero-init or residual structure, and no direct contrast to standard fine-tuning (which the paper states erodes priors) are provided. Without these, it remains possible that any robustness derives from the fine-tuning data distribution rather than the architectural choice.
Authors: This is a fair observation. While the current offline analysis shows that D-CLING maintains or improves action prediction on sequences outside the fine-tuning distribution, we did not include explicit before/after evaluations on the original pre-training corpus or systematic ablations of the zero-initialization and residual structure. We will add these controls to the revised manuscript: (1) action-prediction accuracy on held-out pre-training data before and after D-CLING fine-tuning, (2) an ablation removing zero-initialization, and (3) a direct comparison against standard fine-tuning without the residual pathways. These additions will isolate the contribution of the architectural choice. revision: yes
Circularity Check
No circularity; method is a design choice grounded in external ControlNet inspiration
full rationale
The paper describes a fine-tuning architecture that attaches a trainable copy of the pre-trained backbone via zero-initialized residual pathways, explicitly inspired by ControlNet. This is presented as an engineering choice to acquire in-domain geometric cues while preserving cross-behavior priors from large-scale pre-training. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. Claims rest on real-world navigation trials and offline action-prediction analysis rather than reducing by construction to inputs defined within the paper itself. The approach is therefore self-contained against external benchmarks and pre-trained models.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained navigation foundation models contain generalizable visuomotor knowledge that remains useful after targeted fine-tuning.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
attaching a trainable copy of the pre-trained backbone using zero-initialized residual pathways, thereby learning geometric cues
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
D-CLING ... prior-preserving dense-depth conditioning
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Target-driven visual navigation in indoor scenes using deep reinforcement learning
Y . Zhu, R. Mottaghi, E. Kolve, J. J. Lim, A. Gupta, L. Fei-Fei, and A. Farhadi, “Target-driven visual navigation in indoor scenes using deep reinforcement learning.” InProc. of the ICRA, 2017, pp. 3357–3364
work page 2017
-
[2]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,
E. Wijmans, A. Kadian, A. Morcos, S. Lee, I. Essa, D. Parikh, M. Savva, and D. Batra, “Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,”arXiv, 2019
work page 2019
-
[3]
L. Tai, J. Zhang, M. Liu, and W. Burgard, “Socially compliant navigation through raw depth inputs with generative adversarial imitation learning.” InProc. of the ICRA, 2018, pp. 1111–1117
work page 2018
-
[4]
Habitat-web: Learning embodied object-search strategies from human demonstra- tions at scale
R. Ramrakhya, E. Undersander, D. Batra, and A. Das, “Habitat-web: Learning embodied object-search strategies from human demonstra- tions at scale.” InProc. of the CVPR, 2022, pp. 5173–5183
work page 2022
-
[5]
Vint: A foundation model for visual navigation,
D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine, “Vint: A foundation model for visual navigation,”arXiv, 2023
work page 2023
-
[6]
Nomad: Goal masked diffusion policies for navigation and exploration
A. Sridhar, D. Shah, C. Glossop, and S. Levine, “Nomad: Goal masked diffusion policies for navigation and exploration.” InProc. of the ICRA, 2024, pp. 63–70
work page 2024
-
[7]
Data scaling for navigation in unknown envi- ronments,
L. Suomela, N. Takahata, S. K. Arachchige, H. Edelman, and J.-K. K ¨am¨ar¨ainen, “Data scaling for navigation in unknown envi- ronments,”arXiv, 2026
work page 2026
-
[8]
Pig-nav: Key insights for pretrained image goal navigation models,
J. Wan, C. Zhou, J. Liu, X. Huang, X. Chen, X. Yi, Q. Yang, B. Zhu, X.-Q. Cai, L. Liu, et al., “Pig-nav: Key insights for pretrained image goal navigation models,”arXiv, 2025
work page 2025
-
[9]
Sacson: Scalable autonomous control for social navigation,
N. Hirose, D. Shah, A. Sridhar, and S. Levine, “Sacson: Scalable autonomous control for social navigation,”IEEE RA-L, vol. 9, no. 1, pp. 49–56, 2023
work page 2023
-
[10]
Rapid exploration for open-world navigation with latent goal models,
D. Shah, B. Eysenbach, G. Kahn, N. Rhinehart, and S. Levine, “Rapid exploration for open-world navigation with latent goal models,”arXiv, 2021
work page 2021
-
[11]
Deep visual mpc-policy learning for navigation,
N. Hirose, F. Xia, R. Mart ´ın-Mart´ın, A. Sadeghian, and S. Savarese, “Deep visual mpc-policy learning for navigation,”IEEE RA-L, vol. 4, no. 4, pp. 3184–3191, 2019
work page 2019
-
[12]
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone, “Socially compliant navigation dataset (scand): A large-scale dataset of demonstrations for social navigation,”IEEE RA-L, vol. 7, no. 4, pp. 11 807–11 814, 2022
work page 2022
-
[13]
Adding conditional control to text-to-image diffusion models
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models.” InProc. of the CVPR, 2023, pp. 3836–3847
work page 2023
-
[14]
Flownav: Combining flow matching and depth priors for efficient navigation,
S. Gode, A. Nayak, D. N. Oliveira, M. Krawez, C. Schmid, and W. Burgard, “Flownav: Combining flow matching and depth priors for efficient navigation,”arXiv, 2024
work page 2024
-
[15]
Mapping, localization and path planning for image-based naviga- tion using visual features and map
J. Thoma, D. P. Paudel, A. Chhatkuli, T. Probst, and L. V . Gool, “Mapping, localization and path planning for image-based naviga- tion using visual features and map.” InProc. of the CVPR, 2019, pp. 7383–7391
work page 2019
-
[16]
Orb-slam: A versatile and accurate monocular slam system,
R. Mur-Artal, J. M. M. Montiel, and J. D. Tardos, “Orb-slam: A versatile and accurate monocular slam system,”IEEE transactions on robotics, vol. 31, no. 5, pp. 1147–1163, 2015
work page 2015
-
[17]
WayFAST: Navigation With Predictive Traversability in the Field,
M. V . Gasparino, A. N. Sivakumar, Y . Liu, A. E. B. Velasquez, V . A. H. Higuti, J. Rogers, H. Tran, and G. Chowdhary, “WayFAST: Navigation With Predictive Traversability in the Field,”IEEE RA-L, vol. 7, no. 4, pp. 10 651–10 658, 2022
work page 2022
-
[18]
Learning to explore using active neural slam
D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, and R. Salakhutdinov, “Learning to explore using active neural slam.” InProc. of the ICLR, 2020
work page 2020
-
[19]
Lifelong autonomous improvement of navigation foundation models in the wild
K. Stachowicz, L. Ignatova, and S. Levine, “Lifelong autonomous improvement of navigation foundation models in the wild.” InProc. of the CoRL, 2024
work page 2024
-
[20]
Learning hierarchical relationships for object-goal navigation
Y . Qiu, A. Pal, and H. I. Christensen, “Learning hierarchical relationships for object-goal navigation.” InProc. of the CoRL, 2020
work page 2020
-
[21]
Creste: Scalable mapless navigation with internet scale priors and counterfactual guidance
A. Zhang, H. Sikchi, A. Zhang, and J. Biswas, “Creste: Scalable mapless navigation with internet scale priors and counterfactual guidance.” InProc. of the RSS, 2025
work page 2025
-
[22]
Citywalker: Learning embodied urban navigation from web-scale videos
X. Liu, J. Li, Y . Jiang, N. Sujay, Z. Yang, J. Zhang, J. Abanes, J. Zhang, and C. Feng, “Citywalker: Learning embodied urban navigation from web-scale videos.” InProc. of the CVPR, 2025, pp. 6875–6885
work page 2025
-
[23]
Image-goal navigation using refined feature guidance and scene graph enhancement,
Z. Feng, X. Chen, C. Shi, L. Luo, Z. Chen, Y .-H. Liu, and H. Lu, “Image-goal navigation using refined feature guidance and scene graph enhancement,”arXiv, 2025
work page 2025
-
[24]
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S¨underhauf, I. Reid, S. Gould, and A. Van Den Hengel, “Vision- and-language navigation: Interpreting visually-grounded navigation instructions in real environments.” InProc. of the CVPR, 2018, pp. 3674–3683
work page 2018
-
[25]
A. Kamath, P. Anderson, S. Wang, J. Y . Koh, A. Ku, A. Waters, Y . Yang, J. Baldridge, and Z. Parekh, “A new path: Scaling vision- and-language navigation with synthetic instructions and imitation learning.” InProc. of the CVPR, 2023, pp. 10 813–10 823
work page 2023
-
[26]
Lelan: Learning a language-conditioned navigation policy from in- the-wild videos,
N. Hirose, C. Glossop, A. Sridhar, D. Shah, O. Mees, and S. Levine, “Lelan: Learning a language-conditioned navigation policy from in- the-wild videos,”arXiv, 2024
work page 2024
-
[27]
Vlm-social-nav: Socially aware robot navigation through scoring using vision-language models,
D. Song, J. Liang, A. Payandeh, A. H. Raj, X. Xiao, and D. Manocha, “Vlm-social-nav: Socially aware robot navigation through scoring using vision-language models,”IEEE RA-L, 2024
work page 2024
-
[28]
Diagnosing the environment bias in vision-and-language navigation
Y . Zhang, H. Tan, and M. Bansal, “Diagnosing the environment bias in vision-and-language navigation.” InProc. of the IJCAI, 2020, pp. 890–897
work page 2020
-
[29]
X. Y . Tianqi Tang Heming Du and Y . Yang, “Monocular camera- based point-goal navigation by learning depth channel and cross- modality pyramid fusion.” InProc. of the AAAI, 2022, 36(5), 5422–5430
work page 2022
-
[30]
Navdp: Learning sim-to-real navigation diffusion policy with privileged information guidance,
W. Cai, J. Peng, Y . Yang, Y . Zhang, M. Wei, H. Wang, Y . Chen, T. Wang, and J. Pang, “Navdp: Learning sim-to-real navigation diffusion policy with privileged information guidance,”arXiv, 2025
work page 2025
-
[31]
X-nav: Learning end-to-end cross-embodiment navigation for mobile robots,
H. Wang, A. H. Tan, A. Fung, and G. Nejat, “X-nav: Learning end-to-end cross-embodiment navigation for mobile robots,”arXiv, 2025
work page 2025
-
[32]
A careful examination of large behavior models for multitask dexterous manipulation,
T. L. Team, “A careful examination of large behavior models for multitask dexterous manipulation,”arXiv, 2025
work page 2025
-
[33]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0.” InProc. of the ICRA, IEEE, 2024, pp. 6892–6903
work page 2024
-
[34]
π0.5: A vision-language- action model with open-world generalization,
K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al., “π0.5: A vision-language- action model with open-world generalization,”arXiv, 2025
work page 2025
-
[35]
Gr00t n1: An open foundation model for generalist humanoid robots,
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al., “Gr00t n1: An open foundation model for generalist humanoid robots,”arXiv, 2025
work page 2025
-
[36]
Tail: Task-specific adapters for imitation learning with large pretrained models
Z. Liu, J. Zhang, K. Asadi, Y . Liu, D. Zhao, S. Sabach, and R. Fakoor, “Tail: Task-specific adapters for imitation learning with large pretrained models.” InProc. of the ICLR, 2024
work page 2024
-
[37]
Learning generalizable manipulation policy with adapter-based parameter fine-tuning
K. Lu, K. T. Ly, W. Hebberd, K. Zhou, I. Havoutis, and A. Markham, “Learning generalizable manipulation policy with adapter-based parameter fine-tuning.” InProc. of the IROS, 2024
work page 2024
-
[38]
Lossless adaptation of pretrained vision models for robotic manipulation,
M. Sharma, C. Fantacci, Y . Zhou, S. Koppula, N. Heess, J. Scholz, and Y . Aytar, “Lossless adaptation of pretrained vision models for robotic manipulation,”arXiv, 2023
work page 2023
-
[39]
Robocat: A self- improving generalist agent for robotic manipulation,
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauz ´a, T. Davchev, Y . Zhou, A. Gupta, A. Raju, et al., “Robocat: A self- improving generalist agent for robotic manipulation,”arXiv, 2023
work page 2023
-
[40]
J. Kim, J. Sim, W. Kim, K. Sycara, and C. Nam, “Enhancing safety of foundation models for visual navigation through collision avoidance via repulsive estimation,”arXiv, 2025
work page 2025
-
[41]
Gsplatvnm: Point-of-view synthesis for visual navigation models using gaussian splatting,
K. Honda, T. Ishita, Y . Yoshimura, and R. Yonetani, “Gsplatvnm: Point-of-view synthesis for visual navigation models using gaussian splatting,”arXiv, 2025
work page 2025
-
[42]
Development of Human Support Robot as the research platform of a domestic mobile manipulator,
T. Yamamoto, K. Terada, A. Ochiai, F. Saito, Y . Asahara, and K. Murase, “Development of Human Support Robot as the research platform of a domestic mobile manipulator,”ROBOMECH J., vol. 6, no. 1, p. 4, 2019
work page 2019
-
[43]
A learned stereo depth system for robotic manipulation in homes,
K. Shankar, M. Tjersland, J. Ma, K. Stone, and M. Bajracharya, “A learned stereo depth system for robotic manipulation in homes,” IEEE RA-L, vol. 7, no. 2, pp. 2305–2312, 2022
work page 2022
-
[44]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,”arXiv, 2017
work page 2017
-
[45]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao, “Depth anything v2,”NeurIPS, vol. 37, pp. 21 875–21 911, 2024
work page 2024
-
[46]
General evaluation for instruction conditioned navigation using dynamic time warping,
G. Ilharco, V . Jain, A. Ku, E. Ie, and J. Baldridge, “General evaluation for instruction conditioned navigation using dynamic time warping,”arXiv, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.