Asking Grok: AI-Assisted Sensemaking in Social Media Conversations
Pith reviewed 2026-05-20 01:51 UTC · model grok-4.3
The pith
AI assistants like Grok on social media act as an early complementary sensemaking layer rather than replacing crowd fact-checking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
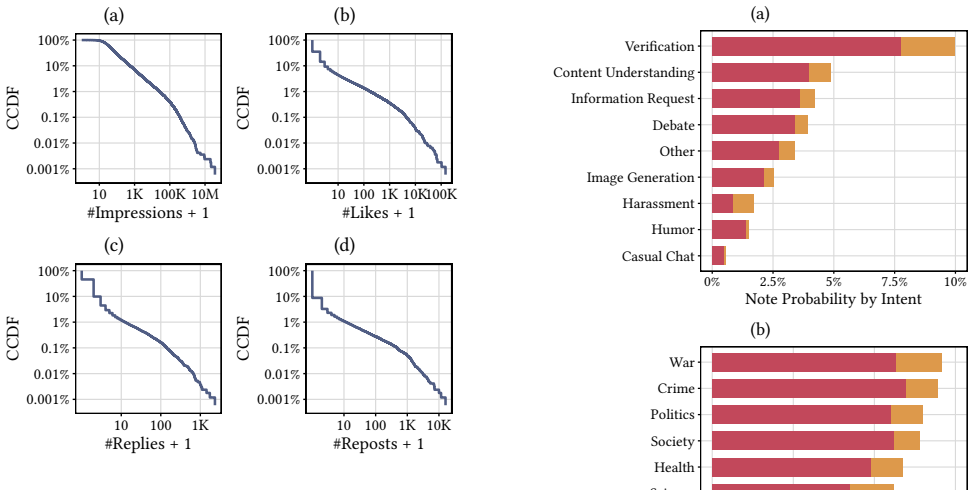
In an analysis of 169,137 posts invoking Grok, the assistant is primarily used to obtain or verify information within conversation threads. Responses generate quickly but reach small audiences, adoption is widespread yet shallow with 76.8 percent of users invoking it only once, and overlap with Community Notes concentrates on verification-oriented high-visibility content where Grok interactions occur earlier and do not predict later correction activity.
What carries the argument
Large-scale empirical analysis of user invocation requests, response reach, adoption frequency, and temporal comparison to Community Notes activity across the collected Grok-invoking posts.
If this is right
- Grok is invoked mainly to obtain or verify information in ongoing social media threads.
- Responses reach audiences quickly but typically remain small in scale.
- Adoption spreads widely yet stays shallow, with most users engaging only once.
- Overlap with Community Notes remains limited and focuses on verification of visible content.
- Grok activity occurs earlier than community corrections and shows no predictive link to them.
Where Pith is reading between the lines
- Platforms could surface AI responses more prominently to increase their reach beyond small initial audiences.
- Design choices that encourage repeated AI use might deepen sensemaking without displacing community systems.
- Testing AI prompts focused on high-visibility threads could reveal whether earlier intervention reduces later misinformation spread.
Load-bearing premise
The 169,137 posts that invoke Grok give a representative and unbiased sample of how users interact with the assistant in typical contexts on the platform.
What would settle it
Finding a different sample of Grok interactions where most uses are proactive rather than reactive or where Grok activity strongly predicts later Community Notes corrections would undermine the claim of a distinct early complementary layer.
Figures






read the original abstract
LLM-powered AI assistants (e.g., Grok) are increasingly integrated into social media platforms, where they help explain content, provide context, and verify claims directly within conversation threads. While prior research has examined the accuracy of LLMs for fact-checking, little is known about how people interact with such systems in real-world social media environments. In this study, we empirically analyze user interactions with the AI assistant Grok on the social media platform X. Using a large-scale dataset consisting of 169,137 posts invoking Grok, we examine the types of requests directed at the AI assistant and the contexts in which it is used. We find that Grok is primarily invoked reactively to obtain or verify information. Although responses appear quickly, they typically only reach small audiences. Adoption is widespread but shallow, with 76.8% of users invoking Grok just once. We further examine how these interactions relate to Community Notes, X's community-based fact-checking system. While overlap between both systems is limited, it concentrates on verification-oriented and high-visibility content. Grok interactions typically occur earlier and do not predict subsequent correction activity. Together, these findings suggest that AI assistants function as an early complementary layer of sensemaking on social media rather than a replacement for crowd-based fact-checking systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes user interactions with the Grok AI assistant on the X platform using a dataset of 169,137 posts that invoke Grok. It categorizes request types (primarily reactive information-seeking and verification), reports on response timing, audience reach, and adoption patterns (76.8% of users invoke it only once), and compares these to X's Community Notes system. The authors find limited overlap concentrated on verification-oriented and high-visibility content, with Grok interactions occurring earlier and showing no predictive effect on later corrections, leading to the conclusion that AI assistants function as an early complementary sensemaking layer rather than a replacement for crowd-based fact-checking.
Significance. If the central patterns hold after addressing sampling concerns, the work provides a large-scale empirical description of real-world AI assistant usage in social media threads. Strengths include the dataset scale supporting broad descriptive claims about request distributions and the direct comparison to an existing community mechanism, which helps distinguish reactive AI sensemaking from post-hoc correction systems. This contributes to understanding platform-integrated LLMs as a distinct layer in online information environments.
major comments (2)
- [Data and Methods] Data collection and sampling: The analysis is conditioned exclusively on the 169,137 posts that mention or invoke Grok. This selection frame may introduce bias toward tech-savvy or event-driven users, undermining generalizability of the shallow adoption finding (76.8% single-use) and the temporal precedence claim relative to Community Notes. The manuscript should include explicit checks for platform API coverage, temporal sampling windows, or comparisons to a control set of non-invoking posts.
- [Results and Discussion] Overlap and predictive analysis with Community Notes: The claim of limited overlap and no predictive effect on subsequent corrections rests on observed patterns in verification-oriented content. However, without reported details on content-matching procedures, statistical controls for audience size/timing, or inter-rater reliability for classifying request types, the complementarity inference remains sensitive to unobserved selection effects. This is load-bearing for the central claim in the discussion.
minor comments (2)
- [Abstract] Abstract: Add a brief statement on the request classification taxonomy and any validation steps (e.g., inter-rater reliability) to support the reported patterns of reactive use.
- [Results] Figures/tables: Ensure that any visualizations of temporal precedence or overlap percentages include confidence intervals or sample sizes to aid interpretation of the limited overlap finding.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the work.
read point-by-point responses
-
Referee: [Data and Methods] Data collection and sampling: The analysis is conditioned exclusively on the 169,137 posts that mention or invoke Grok. This selection frame may introduce bias toward tech-savvy or event-driven users, undermining generalizability of the shallow adoption finding (76.8% single-use) and the temporal precedence claim relative to Community Notes. The manuscript should include explicit checks for platform API coverage, temporal sampling windows, or comparisons to a control set of non-invoking posts.
Authors: We thank the referee for highlighting this important consideration regarding our sampling strategy. Our dataset and analyses are intentionally focused on posts that invoke Grok, as the primary research objective is to characterize the nature and patterns of user interactions with the AI assistant in situ. The finding that 76.8% of users invoke Grok only once is a description of usage frequency within the population of users who have chosen to invoke it at least once; it does not claim to represent adoption rates across all X users. Similarly, the temporal precedence relative to Community Notes is observed within threads where Grok is invoked. To address concerns about generalizability, we will add a new subsection in the Discussion explicitly discussing the limitations of the invocation-conditioned sample, including potential biases toward users familiar with Grok. We will also include checks for temporal sampling windows and API coverage in the Methods section. However, constructing a full control set of non-invoking posts for direct comparison is not feasible with our current data collection approach, which targeted Grok mentions; we will note this as a direction for future work. revision: partial
-
Referee: [Results and Discussion] Overlap and predictive analysis with Community Notes: The claim of limited overlap and no predictive effect on subsequent corrections rests on observed patterns in verification-oriented content. However, without reported details on content-matching procedures, statistical controls for audience size/timing, or inter-rater reliability for classifying request types, the complementarity inference remains sensitive to unobserved selection effects. This is load-bearing for the central claim in the discussion.
Authors: We agree that providing more granular details on our analytical procedures will enhance the transparency and replicability of our findings. In the revised manuscript, we will expand the Methods section to describe: the exact procedure for identifying overlap between Grok invocations and Community Notes (including how threads were matched and any similarity metrics used); the regression models for the predictive analysis, with explicit mention of controls for audience size, post timing, visibility, and other covariates; and the request type classification process, including the coding scheme and any measures of reliability (such as Cohen's kappa if multiple annotators were used, or rationale for the approach taken). These additions should mitigate concerns about unobserved selection effects by allowing readers to better evaluate the robustness of the complementarity conclusion. We will also discuss potential limitations in the interpretation of the predictive results. revision: yes
Circularity Check
No significant circularity: purely observational empirical study
full rationale
The paper presents an empirical analysis of user interactions with Grok based on a collected dataset of 169,137 posts. All reported statistics (e.g., 76.8% single-use adoption, limited overlap with Community Notes, earlier timing) are direct counts and comparisons computed from the observed posts without any mathematical derivations, fitted parameters, or predictions that reduce to the inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify core claims; the complementarity inference follows from the data patterns themselves. This matches the default expectation for non-circular observational work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Posts invoking Grok on X accurately capture real user requests and contexts for AI-assisted sensemaking
Reference graph
Works this paper leans on
-
[1]
Science Advances, 7(36): eabf4393
Scaling up fact-checking using the wisdom of crowds. Science Advances, 7(36): eabf4393. Augenstein, I.; Baldwin, T.; Cha, M.; Chakraborty, T.; Ciampaglia, G. L.; Corney, D.; DiResta, R.; Ferrara, E.; Hale, S.; Halevy, A.; et al. 2024. Factuality challenges in the era of large language models and opportunities for fact- checking.Nature Machine Intelligence...
-
[2]
Supernotes: Driving consensus in crowd-sourced fact- checking. InWWW. de Carvalho Souza, M. E.; and Weigang, L. 2025. Grok, Gemini, ChatGPT and DeepSeek: Comparison and applica- tions in conversational artificial intelligence.Inteligencia Artificial, 2(1). Drolsbach, C. P.; and Pr¨ollochs, N. 2023. Believability and harmfulness shape the virality of misle...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A survey on the use of large language models (LLMs) in fake news.Future Internet, 16(8): 298. Pennycook, G.; and Rand, D. G. 2019. Fighting misinforma- tion on social media using crowdsourced judgments of news source quality.PNAS, 116(7): 2521–2526. Pentina, I.; and Tarafdar, M. 2014. From “information” to “knowing”: Exploring the role of social media in ...
-
[4]
For most authors... (a) Would answering this research question advance sci- ence without violating social contracts, such as violat- ing privacy norms, perpetuating unfair profiling, exac- erbating the socio-economic divide, or implying disre- spect to societies or cultures? Yes (b) Do your main claims in the abstract and introduction accurately reflect t...
-
[5]
Additionally, if your study involves hypotheses testing... (a) Did you clearly state the assumptions underlying all theoretical results? Yes (b) Have you provided justifications for all theoretical re- sults? Yes (c) Did you discuss competing hypotheses or theories that might challenge or complement your theoretical re- sults? Yes (d) Have you considered ...
-
[6]
Additionally, if you are including theoretical proofs... (a) Did you state the full set of assumptions of all theoret- ical results? NA (b) Did you include complete proofs of all theoretical re- sults? NA
-
[7]
Additionally, if you ran machine learning experiments... (a) Did you include the code, data, and instructions needed to reproduce the main experimental results (ei- ther in the supplemental material or as a URL)? NA (b) Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? NA (c) Did you report error bars (e....
-
[8]
Additionally, if you are using existing assets (e.g., code, data, models) or curating/releasing new assets, without compromising anonymity... (a) If your work uses existing assets, did you cite the cre- ators? Yes (b) Did you mention the license of the assets? No, all datasets are open source and publicly available. (c) Did you include any new assets in t...
-
[9]
Additionally, if you used crowdsourcing or conducted research with human subjects, without compromising anonymity... (a) Did you include the full text of instructions given to participants and screenshots? NA (b) Did you describe any potential participant risks, with mentions of Institutional Review Board (IRB) ap- provals? NA (c) Did you include the esti...
-
[10]
If unclear, re- turn ‘[unknown]‘
Language ISO 639-1 code (e.g., ‘en‘, ‘de‘, ‘fr‘, ‘es‘). If unclear, re- turn ‘[unknown]‘
-
[11]
•Verification: asks if a claim/story is true, wants fact- check/evidence/sources
Intent Exactly one must be ‘true‘; all others ‘false‘. •Verification: asks if a claim/story is true, wants fact- check/evidence/sources. •Information Request: asking for general knowl- edge/information about topics (what is X? who is Y? how does Z work?). •Content Understanding: help understanding/working with specific provided content (explain THIS, what...
-
[12]
If no other topic is ‘true‘, set ‘Other‘=‘true‘
Topic Set ‘true‘ only if the topic is a substantial focus of the post. If no other topic is ‘true‘, set ‘Other‘=‘true‘. Possible topics are ‘Politics‘, ‘Entertainment‘, ‘Science‘, ‘Economy‘, ‘Society‘, ‘Health‘. Summary Statistics This section reports descriptive statistics supplementing the main analysis. Table S1 and Figure S1 characterize users and usa...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.