StableGrad: Backward Scale Control without Batch Normalization
Pith reviewed 2026-05-20 06:45 UTC · model grok-4.3
The pith
StableGrad rescales weight gradients after backpropagation to fix scale imbalances in deep networks without touching the forward model or using batch normalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
StableGrad is an optimizer-level scale-control mechanism that corrects layer-wise weight-gradient imbalances without modifying the forward model. Because the normalization is applied only after backpropagation and before the optimizer update, the network output, its derivatives, and the physical residual remain unchanged. Analysis of the resulting training dynamics shows that this post-backprop rescaling stabilizes optimization in deep PINNs and in BatchNorm-free convolutional architectures under standard training settings.
What carries the argument
StableGrad: post-backpropagation rescaling of weight gradients to enforce balanced layer-wise magnitudes before the optimizer step.
If this is right
- Deeper PINNs achieve higher solution accuracy on standard benchmarks while keeping the physical residual exactly as defined.
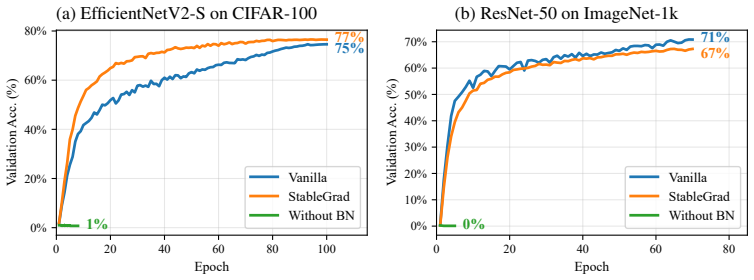
- ResNet and EfficientNet models train to completion without Batch Normalization and without any other architectural modifications.
- Network outputs and input derivatives stay identical to the unscaled case, preserving the meaning of the loss for physics-informed objectives.
- The approach works as a drop-in replacement at the optimizer level for any gradient-based training loop.
Where Pith is reading between the lines
- The same post-backprop correction could be combined with other optimizer choices such as Adam or SGD variants to further tune effective learning rates per layer.
- Because no change occurs to the forward computation graph, StableGrad might extend to settings where the model must remain a pure function of its inputs, such as certain scientific computing or differentiable physics pipelines.
- If the rescaling rule can be made adaptive to the current gradient statistics, it might reduce sensitivity to the choice of initial learning rate in very deep stacks.
Load-bearing premise
That applying scale correction only to the gradients after they are computed will reliably improve convergence without creating new instabilities or changing the optimization path in harmful ways.
What would settle it
Training the same deep PINN or BatchNorm-removed ResNet with and without StableGrad and finding that the version with StableGrad shows equal or worse accuracy and higher failure rates on the benchmark tasks.
Figures




read the original abstract
Training very deep neural networks requires controlling the propagation of magnitudes across depth. Without such control, activations and gradients may vanish, explode, or enter unstable regimes that make optimization fail. Modern architectures often mitigate this problem through Batch Normalization, residual connections, or other normalization layers, which repeatedly re-scale or bypass intermediate representations. However, these mechanisms are not always appropriate. In Physics-Informed Neural Networks (PINNs), the network represents a continuous physical field and its input derivatives define the training objective, making batch-dependent normalization problematic because it can introduce non-local dependencies into the predicted field and its derivatives. We propose StableGrad, an optimizer-level scale-control mechanism that corrects layer-wise weight-gradient imbalances without modifying the forward model. Because the normalization is applied only after backpropagation and before the optimizer update, the network output, its derivatives, and the physical residual remain unchanged. We analyze the effective training dynamics induced by this rescaling and evaluate StableGrad on deep PINNs as the target application, with BatchNorm-free convolutional networks serving as a diagnostic stress test. On PINN benchmarks, StableGrad improves matched-depth solution accuracy and makes deeper models more reliable under standard optimization. On ResNet and EfficientNet architectures, where removing Batch Normalization normally leads to training collapse, StableGrad stabilizes optimization without introducing any other architectural change. These results show that optimizer-level control of weight-gradient scale can provide a practical alternative when forward normalization is unavailable or undesirable.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces StableGrad, an optimizer-level mechanism that rescales layer-wise weight gradients after backpropagation and before the parameter update. This corrects magnitude imbalances across depth while leaving the forward network, its derivatives, and any physical residual (in PINNs) unchanged. The authors analyze the induced effective dynamics and report empirical gains in solution accuracy for deep PINNs together with stabilization of BatchNorm-free ResNet and EfficientNet models under standard optimization.
Significance. If validated, the approach supplies a practical route to stable deep training when forward normalization layers are unavailable or undesirable, especially in physics-informed settings where batch-dependent operations would compromise derivative consistency. The strict post-backprop placement guarantees invariance of the model output and residual by construction, which is a clear technical strength. The stress-test results on convolutional architectures without BatchNorm further indicate that optimizer-level scale control can serve as a lightweight alternative to architectural modifications.
major comments (2)
- [§4] §4 (Analysis of effective dynamics): the derivation of the modified update rule assumes that per-layer gradient norms are the dominant source of scale imbalance; a concrete counter-example or sensitivity study is needed to show that the rescaling does not inadvertently alter the relative learning rates across layers in a way that changes the optimization trajectory for non-convex PINN losses.
- [§5.2] §5.2 (BatchNorm-free conv-net experiments): the claim that StableGrad prevents collapse on ResNet/EfficientNet without any other change is load-bearing for the broader applicability argument, yet the section reports only final accuracy and does not include gradient-norm histograms or training-curve statistics across multiple random seeds to rule out post-hoc hyper-parameter tuning.
minor comments (3)
- [Eq. (3)] The notation for the per-layer scaling factor (Eq. (3)) uses an ambiguous norm symbol; please specify whether it is the Euclidean or Frobenius norm and whether any small epsilon is added for numerical stability.
- [Figure 2] Figure 2 (gradient-norm evolution) would be clearer if error bands from at least three independent runs were added and if the y-axis were log-scaled to highlight the stabilization effect.
- [§3] The abstract states that the physical residual remains unchanged, but the main text does not explicitly restate this invariance when discussing the PINN loss; a short reminder paragraph would improve readability for the target audience.
Simulated Author's Rebuttal
We thank the referee for the constructive review and the recommendation for minor revision. We address each major comment below and will incorporate the requested analyses into the revised manuscript to strengthen the presentation.
read point-by-point responses
-
Referee: [§4] §4 (Analysis of effective dynamics): the derivation of the modified update rule assumes that per-layer gradient norms are the dominant source of scale imbalance; a concrete counter-example or sensitivity study is needed to show that the rescaling does not inadvertently alter the relative learning rates across layers in a way that changes the optimization trajectory for non-convex PINN losses.
Authors: We agree that additional verification is warranted. Section 4 derives the effective dynamics under the premise that gradient-norm imbalances dominate scale issues in deep networks, which is consistent with the placement of the correction after backpropagation. To directly address concerns about non-convex PINN losses, we will add a sensitivity study in the revision. This will include both a brief theoretical note on how the per-layer rescaling preserves the sign and relative direction of updates while equalizing magnitudes, and empirical results on a representative non-convex PINN benchmark showing that the optimization trajectory remains stable without introducing adverse changes to relative learning rates across layers. revision: yes
-
Referee: [§5.2] §5.2 (BatchNorm-free conv-net experiments): the claim that StableGrad prevents collapse on ResNet/EfficientNet without any other change is load-bearing for the broader applicability argument, yet the section reports only final accuracy and does not include gradient-norm histograms or training-curve statistics across multiple random seeds to rule out post-hoc hyper-parameter tuning.
Authors: We acknowledge that the current §5.2 focuses on final accuracy metrics. To provide stronger evidence that stabilization occurs consistently and is not the result of post-hoc tuning, we will revise the section to include gradient-norm histograms throughout training and training curves reporting mean and standard deviation across at least five random seeds for both ResNet and EfficientNet architectures. These additions will directly support the claim that StableGrad enables stable optimization without other architectural modifications. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces StableGrad as an optimizer-level post-backpropagation rescaling of layer-wise weight gradients, applied strictly after the backward pass and before the parameter update. This placement ensures by explicit construction that the forward network output, its autodiff derivatives, and the PINN residual remain identical to the unscaled case, with the claimed invariance following directly from the timing rather than from any fitted parameter or self-referential definition. The subsequent analysis of induced effective dynamics and the empirical results on deep PINNs and BatchNorm-free networks are presented as separate, externally verifiable contributions without reducing to renamed known results, self-citation chains, or uniqueness theorems imported from prior author work. The derivation chain is therefore self-contained and independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Rescaling gradients after backpropagation leaves the forward pass, network outputs, and derivatives unchanged.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
egℓ = σout / (σℓ + ε) gℓ … KSG = J P J⊤ … Theorem 1 (Local decrease under StableGrad)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
StableGrad … applied only after backpropagation and before the optimizer update … leaves the forward model … unchanged
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Principled Weight Initialization for Hypernetworks , author=. International Conference on Learning Representations , year=
-
[2]
Bengio, Y. and Simard, P. and Frasconi, P. , journal=. Learning long-term dependencies with gradient descent is difficult , year=
-
[3]
Saxe, Andrew M. and McClelland, James L. and Ganguli, Surya , biburl =. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks , url =
-
[4]
Pennington, Jeffrey and Schoenholz, Samuel S. and Ganguli, Surya , title =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =. 2017 , isbn =
work page 2017
-
[5]
International Conference on Learning Representations , year=
Deep Information Propagation , author=. International Conference on Learning Representations , year=
-
[6]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[7]
Sifan Wang and Yujun Teng and Paris Perdikaris , title =. CoRR , volume =. 2020 , url =. 2001.04536 , timestamp =
-
[8]
When and why PINNs fail to train: A neural tangent kernel perspective , journal =
Sifan Wang and Xinling Yu and Paris Perdikaris , keywords =. When and why PINNs fail to train: A neural tangent kernel perspective , journal =. 2022 , issn =. doi:https://doi.org/10.1016/j.jcp.2021.110768 , url =
-
[9]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[10]
A Regularized Limited Memory BFGS method for Large-Scale Unconstrained Optimization and its Efficient Implementations , author=. 2021 , eprint=
work page 2021
-
[11]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
work page 2009
-
[12]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
The Road Less Scheduled , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[13]
PINNacle: A Comprehensive Benchmark of Physics-Informed Neural Networks for Solving PDEs , url =
Hao, Zhongkai and Yao, Jiachen and Su, Chang and Su, Hang and Wang, Ziao and Lu, Fanzhi and Xia, Zeyu and Zhang, Yichi and Liu, Songming and Lu, Lu and Zhu, Jun , booktitle =. PINNacle: A Comprehensive Benchmark of Physics-Informed Neural Networks for Solving PDEs , url =. doi:10.52202/079017-2442 , editor =
-
[14]
Mingxing Tan and Quoc V. Le , title =. CoRR , volume =. 2021 , url =. 2104.00298 , timestamp =
-
[15]
Deep Residual Learning for Image Recognition
Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun , title =. CoRR , volume =. 2015 , url =. 1512.03385 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[16]
Understanding the difficulty of training deep feedforward neural networks , author =. 2010 , editor =
work page 2010
-
[17]
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification , year=
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , booktitle=. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification , year=
-
[18]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =. 2015 , editor =
work page 2015
-
[19]
Wu, Yuxin and He, Kaiming , title =. 2018 , isbn =. doi:10.1007/978-3-030-01261-8_1 , booktitle =
-
[20]
2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Deep Residual Learning for Image Recognition , author=. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2016
- [21]
-
[22]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Sinusoidal Initialization, Time for a New Start , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[23]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , journal =. 2019 , issn =. doi:https://doi.org/10.1016/j.jcp.2018.10.045 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.